数据库管理 2023-05-23
- 第七十七期 再探分布式
- 1 单机分布式
- 2 分布式改造
- 3 尝试改造一个订单系统
- 3.1 表类型和分片键选择
- 3.2 扩展分片
- 3.3 业务扩展
- 总结
第七十七期 再探分布式
上一次系统探讨分布式数据库还是在第三十六期,经过大半年的“进步”加上中间参加了不少国产数据库的研讨会或者交流,对分布式数据库的理解还是有了些许进步。
1 单机分布式
最近出现了所谓的“新词”:单机分布式,简言之就是一台服务器运行多个数据库实例,通过spanner框架等技术,通过服务器本机内存而不是网络实现数据库实例之间的数据交互。同时分片也能分布在不同服务器上,并实现跨服务器跨机房跨区域的副本。
在我看来单机分布式的出现有以下几个原因:
- 高性能服务器性能卓越,CPU核心巨多、内存巨大、NVMe SSD巨快
- 单个数据库实例无法完全使用高性能服务器的硬件性能资源(数据库本身差距或一些系统原因影响)
- 环境网络能力不足,10GE网络无法满足大量数据库实例间的网络交互
第三十六期也讲过,分布式数据库的很多操作对内存和网络开销是灾难性的,所以单机分布式也是为了减少这方面的影响。同时更少的服务器也能极大减轻维护压力。
但是单机分布式本身又会带来一些其他的问题,比如各个数据库实例对CPU、内存、IO的争用,当然对于CPU和内存可以使用类似于Cgroup之类的技术实现隔离,IO则只能通过把不同实例分别部署在不同的物理磁盘上实现资源隔离。
2 分布式改造
正如我第六十九期讲的一样,各个使用分布式架构的国产数据库厂商基本上都在有意无意的避开分布式改造这件事情,其中需要涉及的代码改造、业务逻辑改造、数据逻辑改造要么不提要么就一笔带过,更有甚者直接说,我们的数据库不需要分布式改造。我还是那句话,就算是用单机分布式,原来使用集中式数据库向分布式数据库迁移,不进行分布式改造都是放屁和耍流氓。
为啥不提或隐去分布式改造需求,我认为有以下几点:
- 可以卖更多的数据库实例license(向钱看,可能还能顺便帮助客户进行服务器换代)
- 可以深度绑定数据库厂商(跑不动就给优化)
- 可以更加便捷的入场(反正坑的是业务开发方)
总而言之,只要上船了,就可能任人宰割了。
3 尝试改造一个订单系统
这里我自己“编”了一套基于Oracle数据库架构的商城订单系统的数据库表设计:
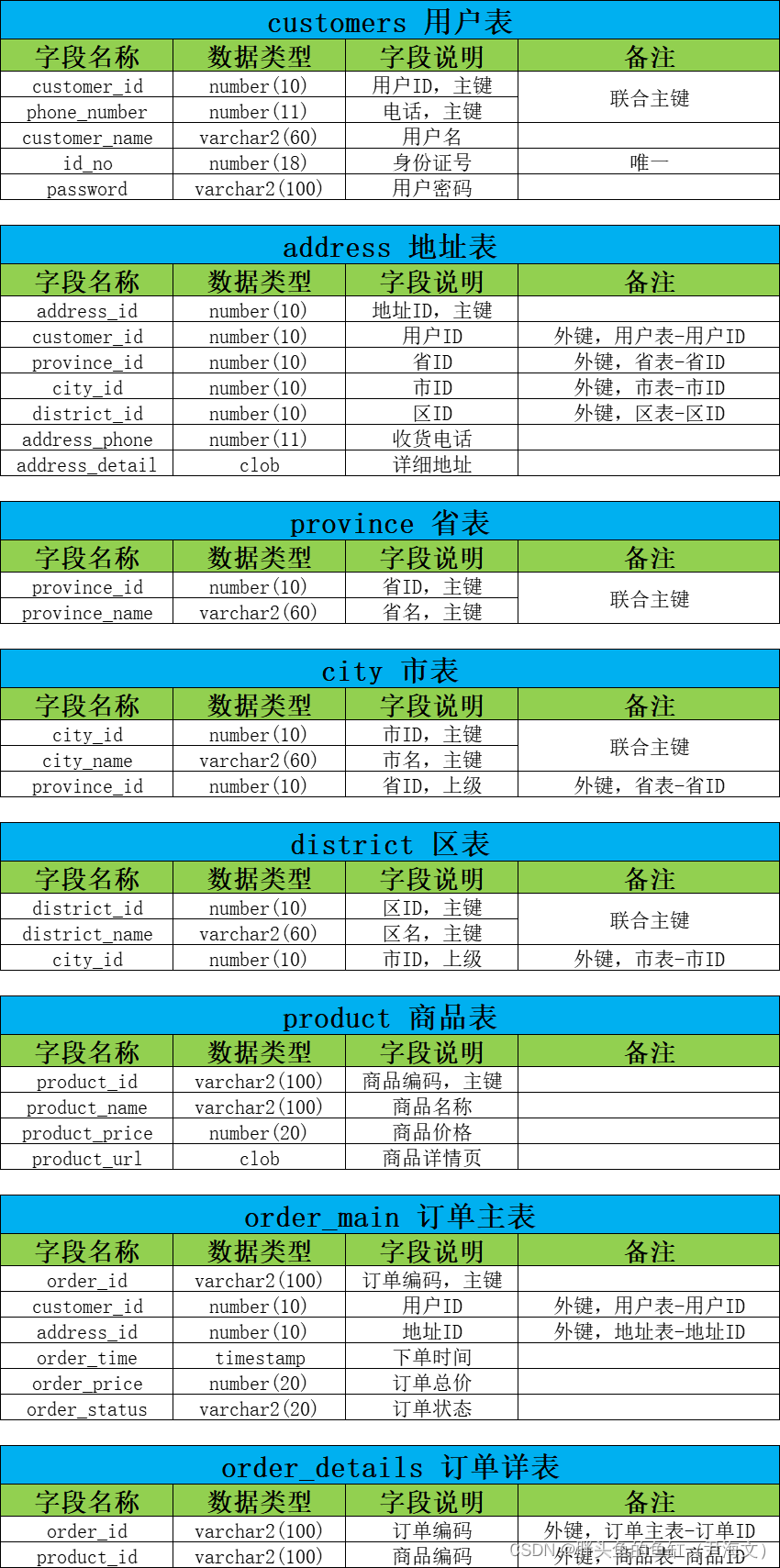
这里的设计并非涉及订单系统的方方面面,主要还是涉及订单的主要内容:其中备注中的外面标识仅表示有主外键关系并非一定建立外键;表类型涉及基础数据、生产数据;各表按照范式要求进行设计。
接下来我们以5个分片为例,尝试对这个系统的数据库设计进行分布式改造,这里不考虑分片内是多副本还是主备,也不考虑高可用等因素:
3.1 表类型和分片键选择
表的类型(单表、复制表、分片表)和分片键的选择其实是相关联的,如何选择分片键也就选择了表的类型。首先我们可以判定本次涉及的表不会涉及到使用单表(当然如果加上一些系统配置信息是可以使用单表的);那么在分片键的选择就是重中之重。
下面以黄色指代复制表,以红色指代分片表。
-
以用户进行划分
这里我认为没有必要根据用户进行划分,因为人的消费能力、消费习惯是千差万别的,通过用户进行划分,即便是通过hash方式打散都很难做到最终涉及订单分片的跨分片数据平衡。 -
以商品类型进行划分
同和用户划分类似,商品的销售量也是千差万别的,涉及国计民生的商品销量可能很大,而奢侈品销量则可能很小,而这里又无法以自然划分的方式像地域那样进行划分,更可能的是某些大类需要拆成几种小类到多几个分片(甚至出现小类也需要分片或分片内分区),而某些大类则可能需要合并在一起到一个或少数几个分片。 -
根据地域进行划分
首先我们需要考虑一点,每个省根据人口、消费水平,各省的订单数量差距是有点大的,为了确保每个分片所涉及的数据量保持一致,所以需要在省表之上建立一个片区表,根据订单数量对片区进行划分,同时对省表、订单表和地址表还要做一些调整:
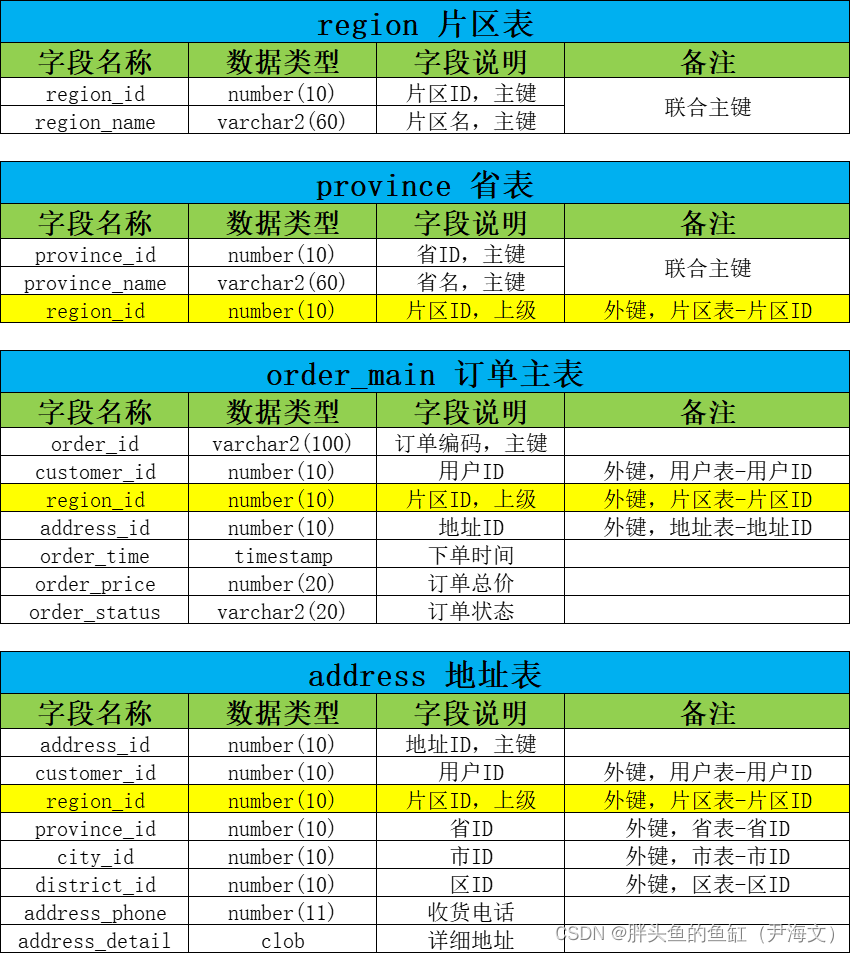
分片情况如下:
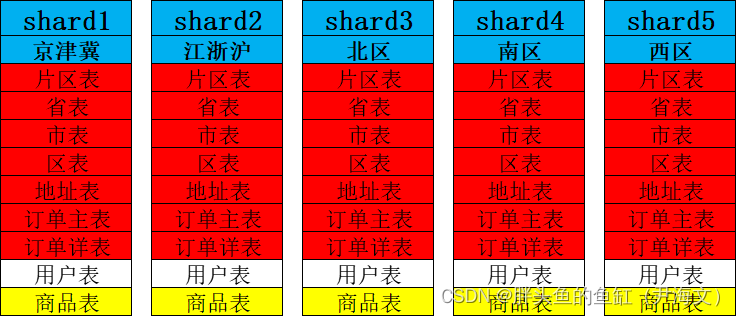
这里订单主表通过与片区表的主外键关系确保订单信息和地址相关信息都会存放在一个分片内;订单主表与详表之间的关联数据也通过主外键保持在一个分片内;而由于商品信息是全国化的,所以商品表是全局保持一致的复制表。这里需要考虑下面几个问题:
– 商品表也可能出现数据量过大的问题,甚至会因为相同的商品在不同店铺(本次未涉及)之间而出现更加庞大的数据量维护,这就可能出现分片内关联查询数据比较大的问题。因此在涉及商品数据查询时,要把SQL语句写好,或者换一种方式获取商品信息(列存、全局搜索等)。
– 用户表数据量可能非常庞大,如果按照片区进行关联分片则需要考虑用户跨片区下单和用户变更片区的问题,主要是跨分片查询;如果作为复制表则可能每个分片都要维护一个贼大的用户表,分片内关联查询则可能出现一些性能问题。但用户跨片区购买和片区变更毕竟是少数,因此用户表仍然可以考虑使用分片表。但还是建议根据更加详细的数据模型进行判断,并需要考虑用户相关的业务逻辑、语句书写。
– 如果地域相关表完全分片有两个问题,首先是地域表数据量是非常小的其实没必要分片,第二是在跨分片查询时需要上升到元数据获取分片信息,因此其实可以数据还是按照地域进行划分,而地域相关的表则配置为复制表。
综上进行一些变更:
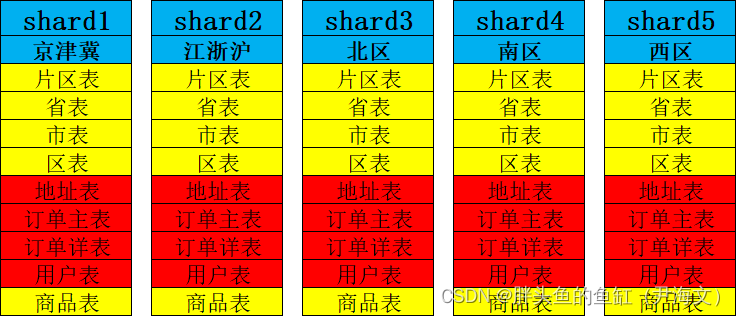
我认为这样的设计就当前涉及范围是相对比较合理的。
3.2 扩展分片
这里我们考虑一个情况,咱们东边的(原属于北区和南区的部分区域)业务量增长比较迅速,导致分片3和4有点扛不住了,需要通过增加一个分片的方式把东区(江浙沪)以外给划分出去,这里就会涉及部分分片数据变更的问题:
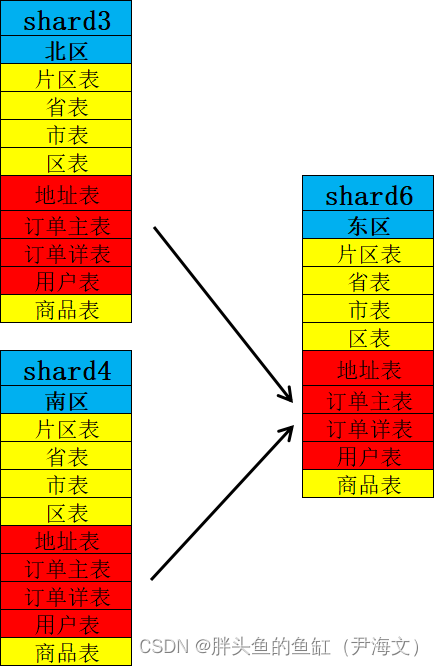
之前也讲过,这样的操作对集群压力还是挺大的,这里需要将原来在分片3和4上的部分数据查出来并传输到分片6上(按照很多厂商的说法这个是业务无感的),如果业务仍然在运行还需要考虑迁移过程中的数据一致性;迁移完成校验数据后还需要在分片3和4上删除移走的数据。这一系列操作会对服务器性能以及网络的极大占用,是大概率影响数据库性能的,还有就是集群元数据更新的压力;另一方面如果分片是使用的副本,那么操作成本更大。
这里薛老师也补充了一下,如果某些业务按照hash分片是一次性从10个分片扩展至20个分片,那么还是停机吧,数据重新平衡的过程数据库是几乎不可用的。
3.3 业务扩展
根据精细化、网格化要求需要添加街道表:

同时还要在地址表添加相关内容:
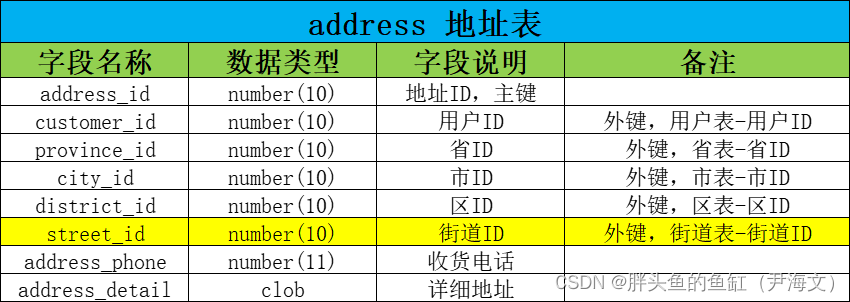
以上两个操作在集中式数据库中仅需增加一个表、变更一个表(操作也不小就是了)。而在6个分片上总共相当于要增加6个表并变更6个表,同时至少增加6个新增表的元数据维护,并增加集群间复制表的同步压力。
这只是一个简单的需求增加,如果涉及复杂的需求变更在分布式数据库上要考虑的更多的东西,做更多的操作(原谅我想不出来复杂的变更,欢迎大佬添加)。
总结
我不是一个开发,也不是架构师,加上上面的一个例子也没有完全覆盖对应的业务场景,所以大家看看就好。
我觉得上分布式还是很难的,而且根据当前的硬件发展水平来看也是没有必要的,当然也提到过用不完硬件资源这个问题,就完全是很尴尬的为了分布式而分布式了。
老规矩,不知道写了些啥。