文章目录
- 前言
- 1. 发现问题
- 2. 复盘
- 2.1 上面试一次错误的问题记录
- 2.2 flask使用clickhouse
- 2.2.1 配置
- 2.2.2 orm
- 2.3 如何插入数据
前言
使用clickhouse有一段时间了,现在要重构一个项目,重度依赖clickhouse,现在终于理顺了,记录一下。
1. 发现问题
from clickhouse_driver import Client
host = '172.18.43.134' # 22.2.2.1
host = '172.18.43.121' # 22.8.1.2097
client = Client(host=host, port=9900)
# 输入 ClickHouse SQL 查询语句并执行
result = client.execute('SELECT * FROM default.cl_grid_fwi_forecast_hourly_data limit 1')
# 打印查询结果
print(result)
两个clickhouse的数据库,一个能连接一个不能,
报错如下:
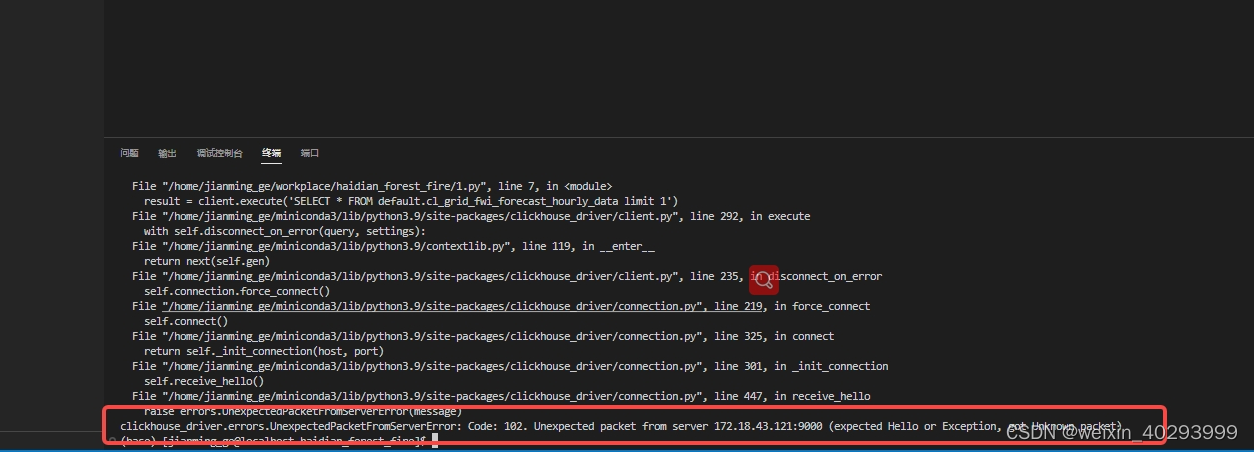
诡异的是,telnet 172.18.43.121:9000 是通的, 于是查了一下版本
SELECT version();
134 的clickhouse 是22.2.2.1
121 的clickhouse 是22.8.1.2097
报错指引ref:https://github.com/mymarilyn/clickhouse-driver/issues/242
到这里,我就联系运维要重新装clichouse,换成134的那个版本就行了。
2. 复盘
2.1 上面试一次错误的问题记录
真实原因是,9000端口被其它程序占了。 121 的9000 端口跟不上clickhouse的服务,所以报错上说,expect hello but exception.
正常的途径是, 我要到121 服务器上, lsof -i:9000
看一下是否启动的是clickhouse的客户端才行!
2.2 flask使用clickhouse
2.2.1 配置
flask 使用clickhouse,自然想借助sqlalchemy以orm的方式使用,而不是原生的方式,否则没有意义。
那么就涉及到了多库,mysql 库和 clickhouse库的配置
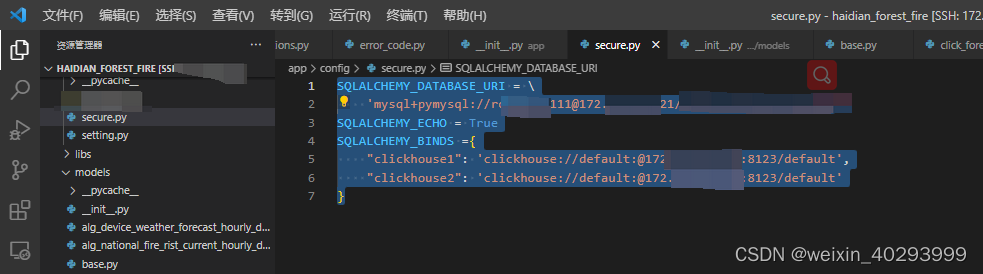
SQLALCHEMY_DATABASE_URI = \
'mysql+pymysql://root:xxx@172.18.43.xxx/forest_fxxxx'
SQLALCHEMY_ECHO = True
SQLALCHEMY_BINDS ={
"clickhouse1": 'clickhouse://default:@172.1xxx:8123/default',
"clickhouse2": 'clickhouse://default:@172.18xxx:8123/default'
}
mysql 走SQLALCHEMY_DATABASE_URI (默认)
clickhouse走的时候 clickhouse1,clickhouse2, 注意不设账密的写法是如上,而且走的是8123的port。
这里要插一句,8123和9000的端口
8123走的是jdbc的方式连接的数据库, java爱用这个。
9000是tcp的方式连接,python的拓展库用tcp的方式。
2.2.2 orm
from sqlalchemy import Column, PrimaryKeyConstraint, String, Boolean, Integer, ForeignKey,DateTime,Float
from sqlalchemy.orm import relationship
from app.models.base import Base
class Forecast_grid_hourly_weather_168h(Base):
__bind_key__ = 'clickhouse1'
grid_id = Column(String)
record_time = Column(DateTime)
data_time = Column(DateTime)
data_date = Column(DateTime)
temperature = Column(Float)
humidity = Column(Float)
weather = Column(String)
iconcode = Column(String)
wind_speed = Column(Float)
wind_degree = Column(Float)
wind_trend = Column(String)
wind_level = Column(String)
rain_fail = Column(Float)
rain_probability = Column(Float)
pressure = Column(Float)
cloud = Column(Float)
dew_weather = Column(Float)
__table_args__ = (
PrimaryKeyConstraint('grid_id', 'data_date','data_time'),
)
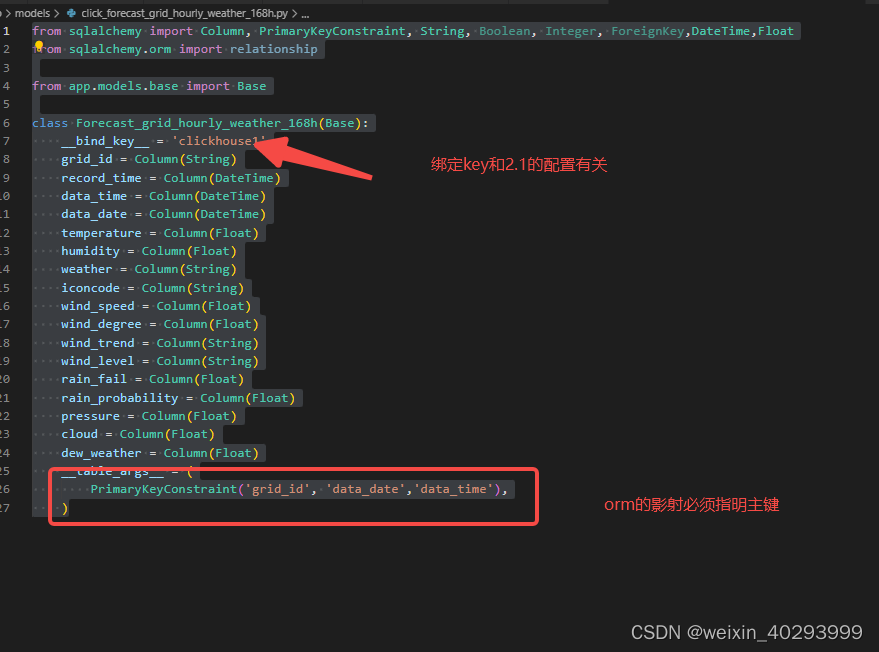
要注意__bind_key__ = ‘clickhouse1’ 和 table_args = (
PrimaryKeyConstraint(‘grid_id’, ‘data_date’,‘data_time’),
)
这两个设置。
2.3 如何插入数据
from sqlalchemy import and_
from app import create_app
from app.models.base import db
from app.models.click_forecast_grid_hourly_weather_168h import Forecast_grid_hourly_weather_168h
from app.models.click_cl_grid_fwi_forecast_hourly_data import Cl_grid_fwi_forecast_hourly_data
from app.models.grid import Grid
from app.models.plant import Plant
from app.models.grid_land_info import Gridlandinfo
from app.models.sys_risk_point import Sysriskpoint
from app.models.grid_plant_bind import Gridplantbind
from sqlalchemy.orm import aliased
import datetime
from app.spider.CEFDRS import CEFDRS
from clickhouse_driver.client import Client as clientclickhouse
if __name__ == '__main__':
app = create_app()
with app.app_context():
# grid_code = "130733100201"
# results = Gridplantbind.query.filter_by(grid_code=grid_code).all()
# plant_list = [dict(plantType = row.plant.plant_type, plant_name = row.plant.plant_name, proportion=row.proportion) for row in results]
# # for row in results:
# # print("-------------")
# # print(row.proportion)
# # print(row.plant.plant_name)
# # print(row.plant.plant_type)
# # exit("--===")
# print(plant_list)
cefdrs = CEFDRS()
import json
post_json_data = json.load(open("aaa.json"))
# print(post_json_data)
res = cefdrs.get_cefdrs(post_json_data)
# print(res['data']['cefgrds'][0])
# print(res['data']['fwi_reason'])
session = db.session
list1 = [res['data']['cefgrds'][0]]
# # print(list1)
# cl_1 = Cl_grid_fwi_forecast_hourly_data()
# models = [cl_1.set_attrs(attrs_dict = d).__dict__ for d in list1]
# for row in models:
# row.pop('_sa_instance_state')
# print(models)
# session.add_all(models)
# session.commit()
session.bulk_save_objects([Cl_grid_fwi_forecast_hourly_data(**data) for data in list1])
session.commit()
# insert_db_click_house(models)
这里用的是批量插入的方式。 session.bulk_save_objects([Cl_grid_fwi_forecast_hourly_data(**data) for data in list1])
bulk_save_objects(objects, *, return_defaults=False, update_changed_only=True)
batchsize 可以划分块,避免一次性插入太多:
chunks = [objects[i:i+100] for i in range(0, len(objects), 100)]
for chunk in chunks:
session.bulk_save_objects(chunk, chunksize=100)
session.commit()
···
SQLAlchemy 提供了一个 slice() 函数,用于将插入数据分成多个块进行批量插入,以避免一次性插入数据过多。slice() 函数的定义如下:
slice(start, stop, step=None)
slice() 函数接受三个参数:start、stop、step,表示生成一个类似切片的对象,用于将数据分成多个块进行插入。
我们可以通过将 slice() 函数返回的对象作为 mappings 参数的切片来实现分块插入数据。例如,如果我们有一个包含 1000 条记录的列表 data,想要将数据分成每页 100 条的块来逐个插入,可以这样使用 bulk_insert_mappings() 方法:
chunk_size = 100
total = len(data)
for i in slice(0, total, chunk_size):
mappings = data[i:i+chunk_size]
session.bulk_insert_mappings(MyModel, mappings)
session.commit()
session.add_all(models)
也会完成这件事,但都不会切块。
我怀疑是sqlalchemy自身内部完成了从 jdbc的连接转到了tcp的连接方式,而转换过程中,是能够查到clickhouse的客户端是以那个端口开放的,因为并没有手动设置9000或者9900端口的位置。
而且要下载sqlalchemy的 clickhouse的插件才能使用,指引在这里:
clickhouse-sqlalchemy的api网址:
https://github.com/xzkostyan/clickhouse-sqlalchemy
clickhouse-driver的api网址:
https://github.com/mymarilyn/clickhouse-driver