作者:阿里云智能技术专家 周康,StarRocks Active Contributor 郑志铨(本文为作者在 StarRocks Summit Asia 2022 上的分享)
为了能够满足更多用户对于极速分析数据的需求,同时让 StarRocks 强大的分析能力应用在更加广泛的数据集上,阿里云EMR OLAP 团队与 StarRocks 社区在 2021 年就开始合作。
双方联手增强 StarRocks 的数据湖分析能力,使其不仅能够分析存储在 StarRocks 本地的数据,还能够以同样出色的表现分析存储在 Apache Hive(以下简称 Hive)、Apache Iceberg(以下简称 Iceberg)和 Apache Hudi(以下简称 Hudi)等开源数据湖或数据仓库的数据。
阿里云EMR StarRocks 正是 StarRocks 授权阿里云的一款开源 OLAP 产品,致力于构建极速统一分析体验,满足企业用户的多种数据分析场景。本文将主要阐释阿里云EMR StarRocks 在数据湖方向已经做过的工作、实际的效果体现,以及 StarRocks 在数据湖分析方向的规划。
#01
阿里云EMR StarRocks 整体架构
—

在存储层,有阿里云的对象存储 OSS 作为数据湖的统一存储,可以存储常见的 Parquet/ORC/CSV 等文件格式。
在湖管理与优化层,EMR 会通过数据湖构建(DLF),去进行整体数据湖的元数据管理和一体化构建。同时在数据湖分析实践过程中,对象存储相对于传统的 Apache Hadoop(以下简称 Hadoop),HDFS 会存在一些性能问题。为了解决这个问题,在阿里云EMR,我们自研了 Jindo FS 系统,以便对数据湖存储层访问进行加速和优化。
同时针对常见的数据湖存储格式,包括 Parquet、ORC 的格式。比如像 Hudi、Iceberg,在索引统计版本信息、版本维护、小文件合并以及生命周期等方面,都做了优化和增强。有了存储以及针对数据库管理的优化等工作,就可以在这之上去构建分析层,也就是数据开发与治理层。
在数据开发与治理层,StarRocks 在阿里云EMR 分为两个角色,一部分是固定节点,一部分是弹性节点。有了 StarRocks 数据湖分析引擎之后,就可以去对接 EMR 上开源的 Apache Airflow(以下简称 Airflow)以及 Jupyter 等,也可以对接阿里云的 Dataworks,来做数据开发和调度。
1、StarRocks 在 Iceberg 的实现
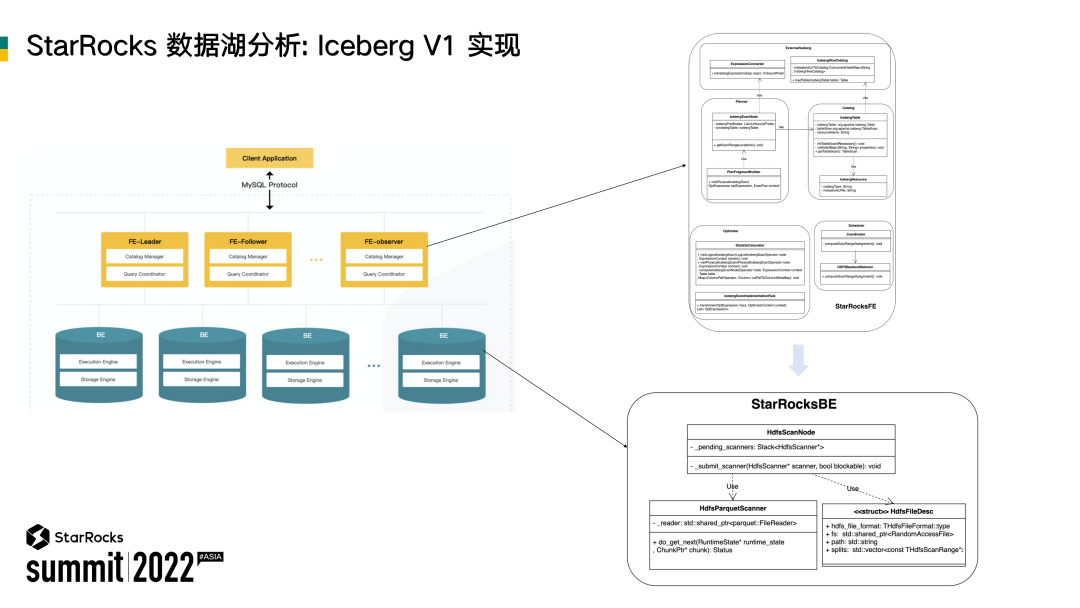
StarRocks 主要包含 FE 和 BE 两个组件,两者之间再通过 RPC 进行通信,以实现查询的调度和分发、结果汇总等一系列工作。
为了支持 Iceberg 的数据湖分析,我们在 FE 侧以及 BE 侧都做了大量的改造。首先是 FE 侧,增加了外表类型 IcebergTable;在执行计划生成之后,通过修改 RPC 协议(Thrift 协议),把执行计划相关信息发送给 BE;在 BE 侧,再通过通过 HDFS scanner 来支持实际的数据扫描。
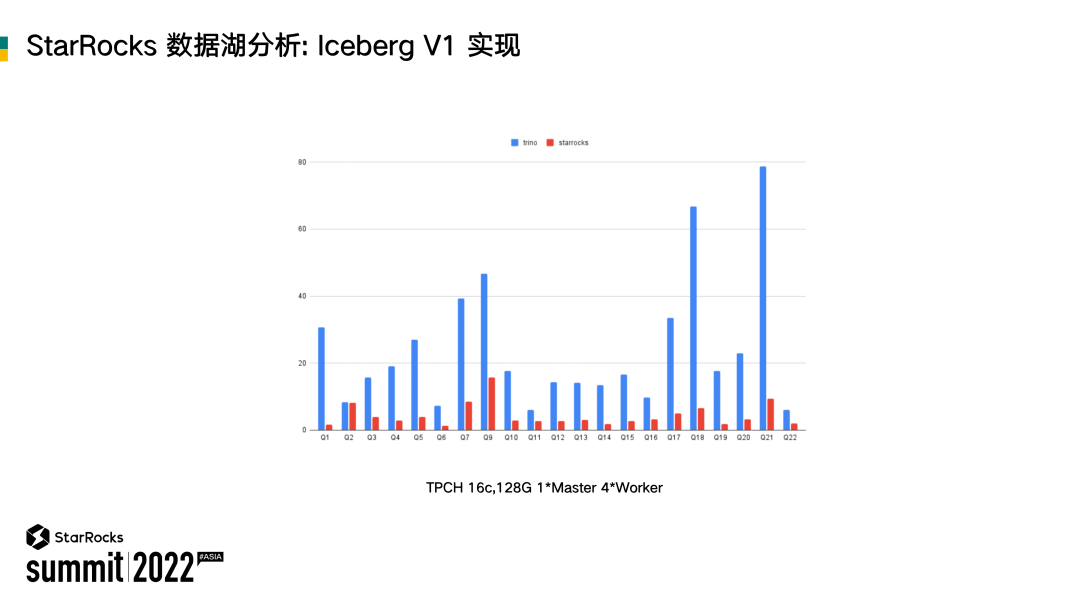
在做了上面这一系列的研发工作之后,我们基于 TPCH 和 Trino 做了性能对比测试。可以看到,StarRocks 相对于 Trino 性能表现非常突出。
那么为什么 StarRocks 相比 Trino 的性能要好这么多?
2、StarRocks 的性能分析
借助 StarRocks 已有的全面向量化执行引擎、全新的 CBO 优化器等,这些能力能够极大地提升我们在单表以及多表层面的性能表现。在这个基础之上,针对数据湖分析的场景,我们也增加了新的优化规则。
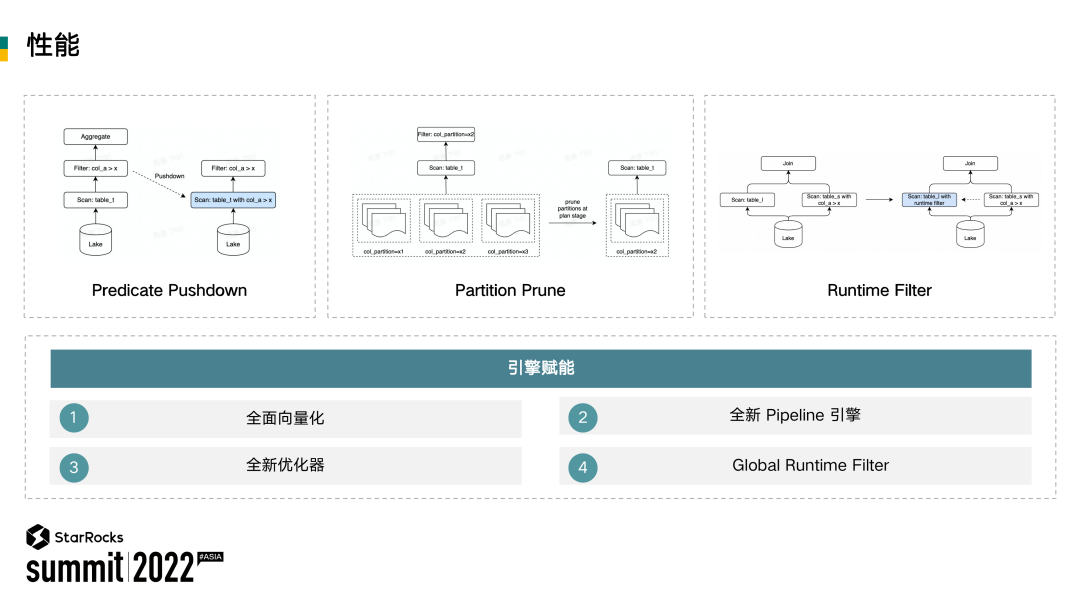
首先在优化规则的方面,举几个简单的例子,比如常见的谓词下推,通过支持谓词下推,能够把 col_a>x 等谓词条件下推到 scan 算子。这样实际在扫描数据时,就能够减少扫描的数据量。
如果没有做谓词下推(如上图左上角),通过整体扫描,会把数据先扫上来,然后再通过引擎本身上游的一些 Filter 算子去做数据的过滤。这会带来很大的 IO 开销。
为了进一步减少扫描数据量,我们也支持了分区裁剪,详见上图中间区域。在没有做优化之前,需要去扫描三个分区。通过分区裁剪的优化,在 FE 侧就可以把不需要的两个分区裁剪掉。只需要告诉 BE 扫剩余一个分区的数据。在 BE 我们也支持了 Global Runtime Filter,针对 Join 这种场景,能够有比较大的性能提升。借助于 StarRocks 优异的执行引擎,就能够在 CPU 密集型的数据湖分析场景下有很好的性能表现。但在一些实际场景落地过程中,基于 FE 侧的一些优化规则,或者是前面提到的全局 Runtime Filter 还不能够完全减少 IO开销。
如何降低 IO 开销非常关键。在大部分情况下,数据湖中需要分析的数据和计算节点,基本上不会在同一台物理机器上。那么在分析过程中,我们就面临着非常大的网络 IO 挑战,为此 StarRocks 社区针对 IO 方面做了非常多的优化,包括延迟物化、IO 合并、支持 Native Parquet/Orc Reader、针对对象存储的 SDK 优化等工作。
接下来,我通过两个例子展开介绍实际的优化细节是怎么实现的。
(1)IO 合并
在没有 IO 合并以前,若要读取一个 Parquet 文件相关的数据,首先需要基于 FE 侧发给 BE 的扫描数据路径去构建针对文件级别的 File Reader,在 FE 侧规划的时候,也能告知实际扫哪几列数据。在实际客户落地过程中遇到小文件导致 IO 耗时高的问题。
针对于 ColumnReader,假设一个 SQL 同时要读取三列,有可能有两列的数据量会比较小。这个时候可以对这两列 IO 合并。比如以前要通过两次的网络 IO,现在可以一次就把这两列的数据读取。针对于 Row Group ,也可以对小的 Row Group 做 IO 的合并,从而减少 IO 的次数。

对于文件本身,如果这个文件特别小,我们也支持一次把文件加载到内存中。实际在测试过程中,在这种小 IO 特别多的场景下,会有一个非常明显的提升。
(2)延迟物化
什么是延迟物化?延迟物化需要解决什么问题?
在没有延迟物化之前,回到 Parquet 的实现原理,比如要读取三列,就需要把这三列同时给读上来,然后再去运用一些谓词,再返回给上游算子。这里可以看到一个明显的问题,就是假设没有针对第三列的谓词,那其实第三列不需要把所有数据都读进来。
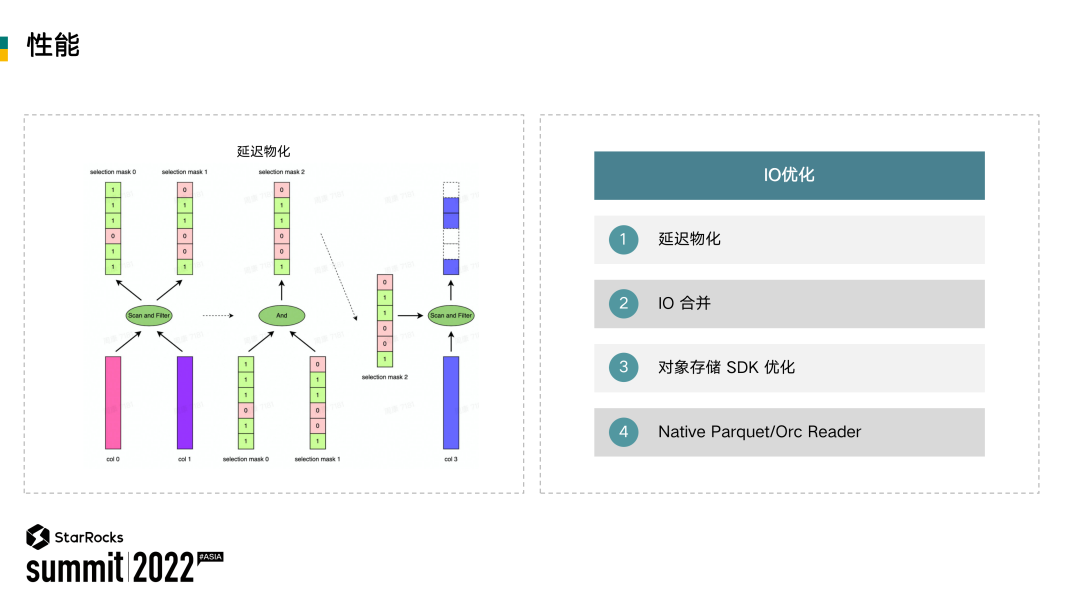
可以看上图左边部分,因为 SQL 针对于前两列 c0 和 c1 是有谓词的。这个时候会先把这两列数据读取到内存。然后基于这两列构建 Selection mask,这两个 Mask 叫标记数组。有了这两个标记数组之后,会把第三列定义为一个 Lazy column。
拿到了前两列的标记数组之后,基于这两个标记数组去构建一个新的过滤标记数组。然后再基于这个新的过滤标记数组读取 Lazy column。那在实际使用过程中,Lazy column 里边可能会有多列,这样能够极大地减少很多不必要的 IO 读取。因为有了前面的引擎赋能,包括全面向量化、CBO 优化器以及针对 IO 本身的优化数据湖分析,在测试和实际落地的过程中已经有一个很好的性能表现。
在实践过程中,另外一个问题就是元数据访问。在数据湖场景之下,对文件的 List 操作可能会成为整个网络访问的瓶颈。为了解决这个问题,在 StarRocks 的 FE 侧设计了一套完整的细粒度智能缓存方案,能够缓存 Hive 的分区信息,以及文件信息。
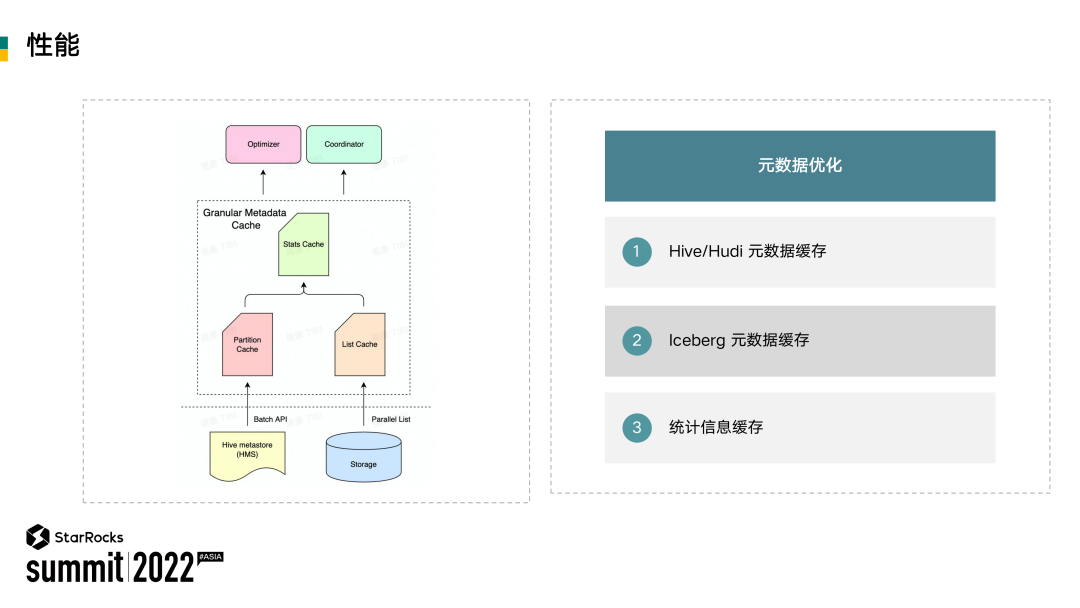
在设计缓存中,缓存更新是一个比较大的挑战。基于事件驱动的模式,能够解决缓存更新的问题,在保证用户查询的性能基础之上,也能够有非常好的使用体验,而不需要手动更新缓存。同时,为了加速查询的规划和调度,也支持了统计信息的缓存。
3、StarRocks的生态分析
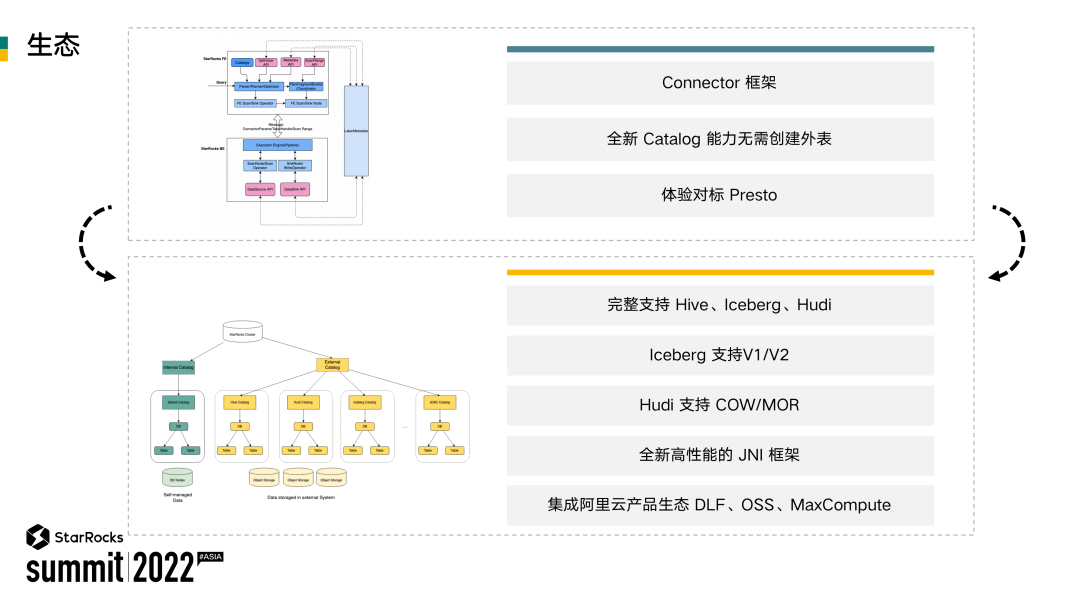
早期版本中,如果要支持新的数据源需要做很多冗余的开发,开发者需要对很多其他模块有深入的理解,用于使用的时候也需要去创建外表。如何解决这个问题呢?我们的解决思路是设计一套全新的 Connector 框架。
在以前的版本中,假设用户有一个库包含一两百张表,需要在 StarRocks 上去分析,那么他需要手动创建 100 多张的外表,然后通过 FE 管理元数据,再让用户去使用。如果说用户做了一些 Schema change,外表可能又得重建,就极大增加了使用负担。
在 Connector 框架设计中我们引入了 Catalog 的概念,用户不在需要手动创建外表。比如说现在有 Hive Catalog、Iceberg Catalog,用户不需要去创建外表,只需要创建一个 Catalog,就能实时地获取到表的元数据信息。我们已经对 Hive、Iceberg、Hudi 做了完整的支持。同时在 EMR 产品生态里也已经集成好了前面提到的元数据管理的 DLF 以及 OSS、 Max Compute 等产品。
4、StarRocks的弹性分析
前面在做产品整体介绍的时候,提到了我们有一个比较关键的产品特性是弹性。弹性是怎么实现的呢?其实最核心的解决方案就是在 StarRocks 支持了 Compute Node(以下简称 CN)。下图左边部分就是一个固定的 StarRocks 集群,这些固定的 BE 节点都有实际的 SSD 存储。
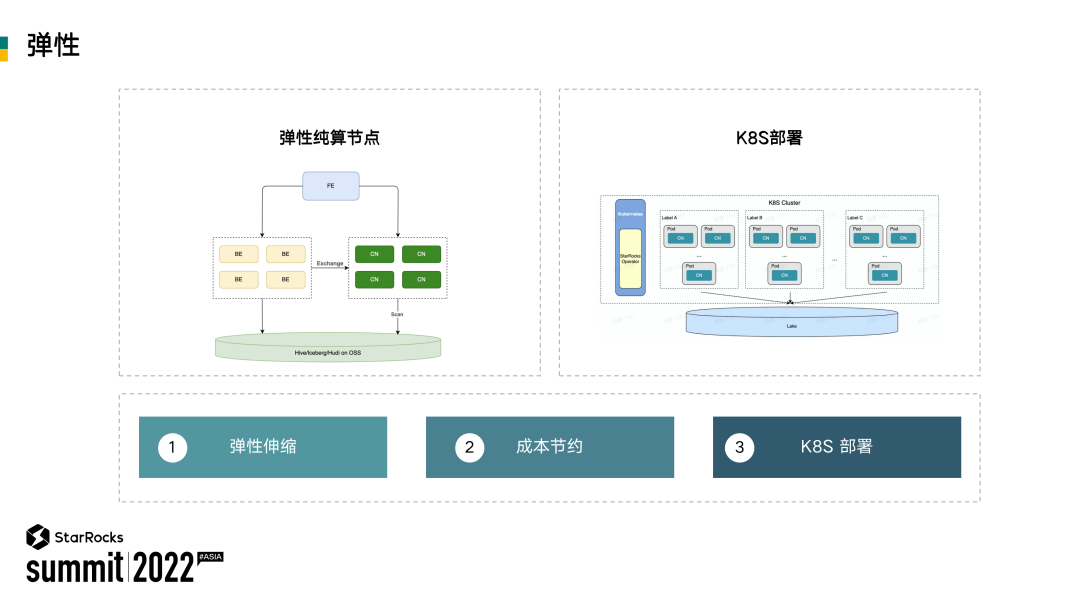
绿色部分是 CN。CN 和 BE 共享同一套执行引擎代码,是一个无状态的节点。CN 可以部署在 K8S 上,数据可以存储在对象存储或 HDFS 上。通过 K8S HPA 的能力,在集群负载高的时候动态扩容 CN,在集群负载低的时候缩容。
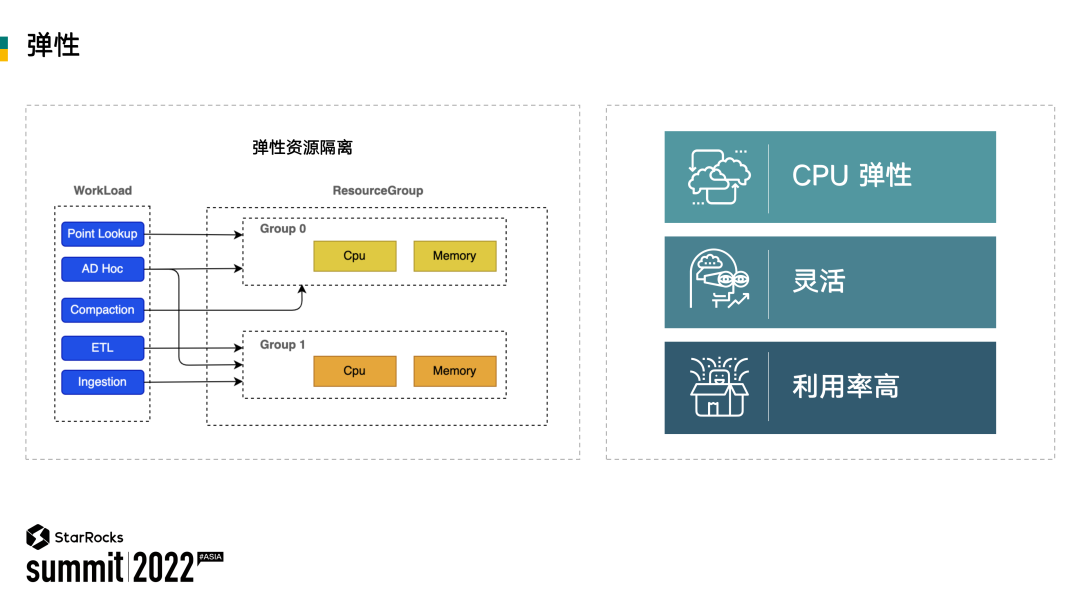
经过上面的改造,EMR StarRocks 能够支持弹性伸缩,从而支持最大程度地降本。有了弹性之后,我们还需要解决另一个问题,那就是资源隔离。数据湖上的查询 workload 通常多种多样,有直接对接 BI 出报表的,也有分析师查询明细的 Ad-Hoc 等等。通常用户都希望通过软性的隔离,而不是物理隔离,来实现小租户资源的弹性隔离。例如在集群资源空闲的时候,允许查询充分利用集群资源,但是当集群资源紧张时,各个租户按照自己的资源限制使用资源。因此 StarRocks 还实现了基于 ResourceGroup 的资源隔离,这样用户可以从用户、查询和 IP 等层面,限制其对 CPU/MEM/IO 等资源的使用。
通过对性能优化、生态整合弹性等几方面的介绍,我们知道阿里云EMR StarRocks 在数据湖分析场景具体是怎么做的、做到了什么程度。归纳起来,阿里云EMR StarRocks 数据分析的核心就是“极速”、“统一”两个关键词。
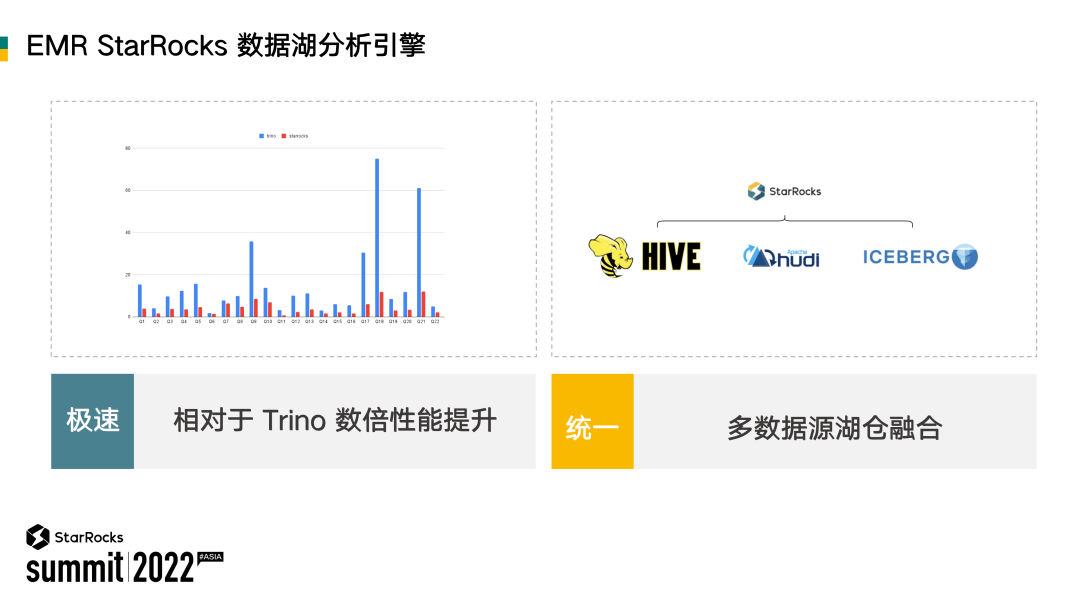
极速:相对于 Trino 有数倍的性能提升,上图这一页的测试数据是针对于 Hudi。
统一:支持多种多样的数据源,包括上图没有提到的 JDBC 数据源。目前从 Trino 迁移到 StarRocks 已经有不少落地实践,基本可以实现无痛的迁移。
#03
阿里云EMR StarRocks数据湖规划
—
通过不断与用户交流探讨,我们认为,数据湖分析至少达到以下四点要求,才能成为一项大众化的数据分析技术:

1. Single Source of Truth 。只有一份数据,用户无需显示地进行数据流转。
2. 高性能。接近秒级别,甚至亚秒级的查询延时。
3. 弹性。分解存储和计算架构。
4. 经济高效。按需扩展和扩展。

当前阻碍数据湖分析达到上述四点要求的情况有以下三种:
1. 数据湖存储系统普遍存在 IO 性能差的问题,无法满足用户对于低延迟查询的要求。
2. 数据湖、数据仓界限分明。通常为了加速数据湖查询,我们还需要在其上去搭一层数据仓,破坏了 Single Source of Truth 的原则。
3. 复杂的数据栈结构使我们无法保证弹性、高性价比以及易用性。
经过多次思考、开放讨论以及仔细论证,我们提出了数据湖分析的新方式,希望通过数据湖分析的新方式攻克以上难题、达到理想的数据湖分析状态。

我们认为,数据湖分析的新方式等于缓存+物化视图。
由于数据湖存储系统包括 OSS 等,通常 IO 性能都比较差,导致数据湖分析的瓶颈通常落在 Scan 数据上。
为了能够进一步提升数据湖分析的性能,我们希望能够利用本地磁盘或内存缓存这些数据加速 IO 性能,使远端存储不再成为性能的瓶颈。引入缓存对于用户来说是透明的,用户无需额外的运维工作就能够享受到缓存加速的好处。
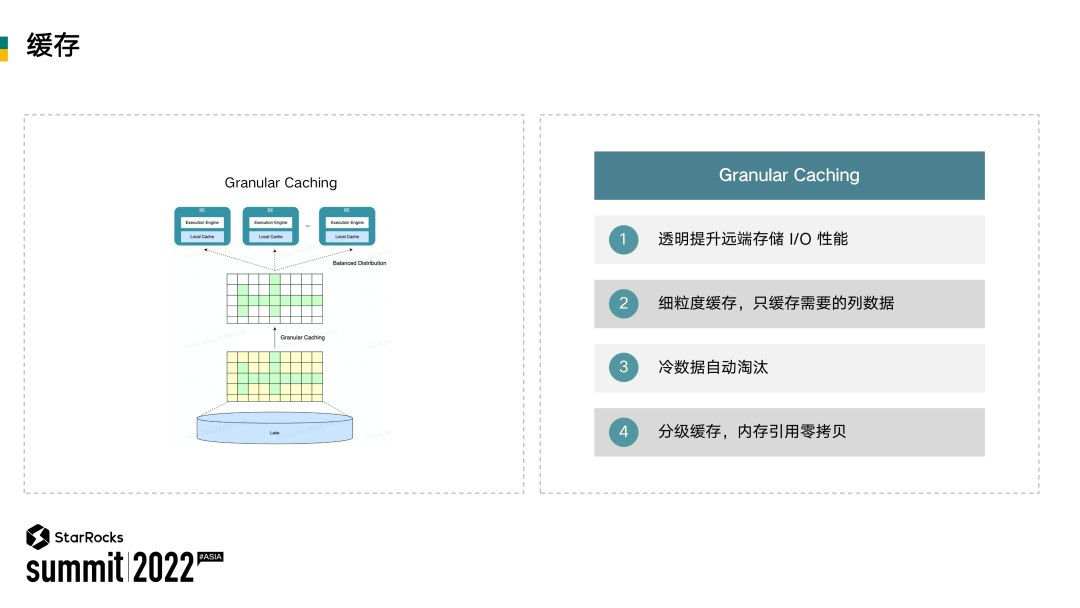
相比于远端存储,本地磁盘或内存的价格一般都比较昂贵。我们希望好钢用在刀刃上:只有用户分析所需要用到的列数据才会进入到缓存当中来,并且对于逐渐变冷的数据,我们会将其自动淘汰掉,从而提高缓存的空间利用率。
类似于 CPU 的缓存架构,我们也采用分级缓存的策略。第一级是内存,第二级是本地磁盘,对于缓存到内存的极热数据,所有的读取都能够直接引用缓存本身的内存,无需进行内存拷贝,在数据不断更新的场景下,新增数据通常会导致 Cache miss,从而导致查询延迟出现抖动。
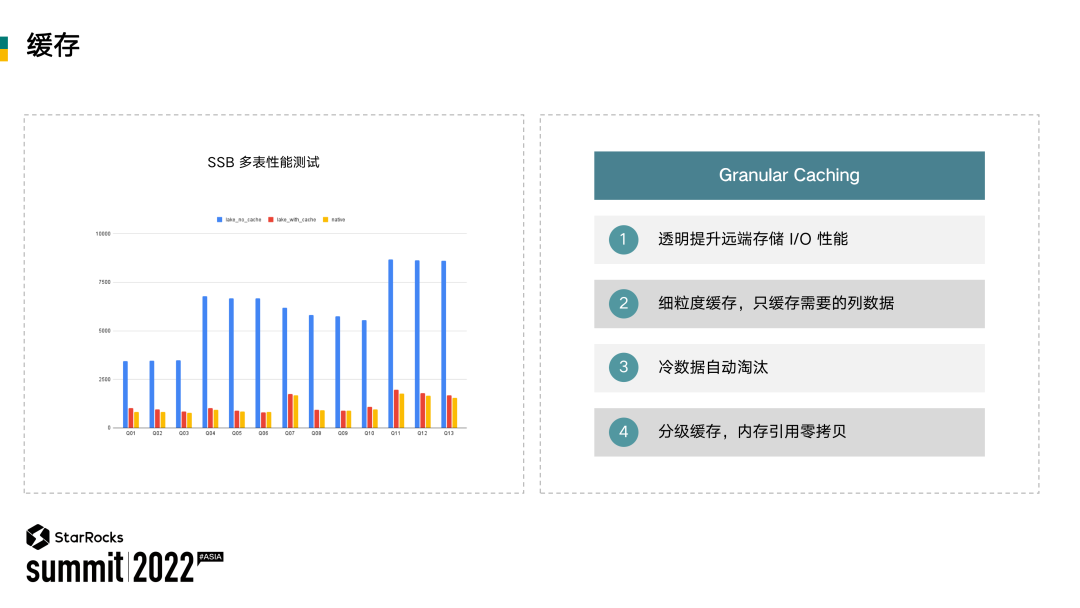
目前我们已经做了一些 POC。POC 显示,在 SSB 多表性能测试的情况下,缓存的性能比不缓存快了三倍以上,并且已经基本接近 StarRocks 本地表。缓存帮助我们保证 Single Source of Truth 的同时达到高性能,由于缓存的特性,用户可以真正做到弹性伸缩、cost effective。对于延迟敏感的场景,提高缓存空间来降低查询延迟。对于延迟不敏感的场景,减少或不使用缓存,从而节约成本。
用户通常希望对数据进一步加工、预聚合或建模,使其进一步满足业务对数据分析的性能和质量要求,同时也能够节省重复计算的开销。然而不管是 Lambda 架构还是 Kappa 架构,用户都需要搭建复杂的数据栈,用于进一步加工数据湖上的数据。同时用户还需要分别维护元数据和加工后的多份数据,处理数据之间的一致性问题。
为了满足用户对数据加工、建模的需求,进一步融合湖和仓,我们将为用户带来更加强大的物化视图能力解决上述问题。
首先,物化视图通过 SQL 定义,数据的加工和建模变得极其简单。其次,物化视图能够融合不同数据的元数据,对外提供一个统一的视图,用户无需改写查询 SQL 即可做到查询自动路由透明加速。StarRocks 的视图支持实时增量更新,为用户提供更实时的分析能力。最后,物化视图作为 StarRocks 的原生能力,极大地降低了运维成本。通过物化视图,数据湖能够真正做到 Single Source of Truth,帮助用户更加简单地在数据湖上进行数据的加工建模,打破了湖和仓的次元壁,简化整个数据栈的架构。
#04
总结和展望
—
StarRocks 数据湖分析的核心是:极速、统一、简单、易用。
通过 Connector、数据 Catalogs,数据源的接入变得极其简单。通过缓存,数据湖存储系统的 IO 性能将不再成为瓶颈。通过物化视图,湖、仓数据的流转更加自然,湖、仓视图一致,查询可以透明加速,数据栈的架构变得更加简约。最后借助云上和 K8S 的弹性能力,StarRocks 数据湖分析能够做到真正的弹性、cost effective。
关于 StarRocks
面世两年多来,StarRocks 一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
2021 年 9 月,StarRocks 源代码开放,在 GitHub 上的星数已超 3600 个。StarRocks 的全球社区飞速成长,至今已有超百位贡献者,社群用户突破 7000 人,吸引几十家国内外行业头部企业参与共建。
![[附源码]计算机毕业设计影院管理系统Springboot程序](https://img-blog.csdnimg.cn/c8b2003fe12c44ac9ad73dfba894c23b.png)




![[附源码]计算机毕业设计springboot小区疫情事件处理系统](https://img-blog.csdnimg.cn/4cf0b48c124541e8a614837c783291b9.png)