bloom算法(布隆过滤器)
原理
先说一下什么是布隆过滤器,Bloom Filter是1970年由布隆提出的,它实际上是一个很长的二进制向量,和一系列随机值映射的函数,主要用于判断一个元素是否在一个集合中。
通常判断一个元素是否在一个集合中,一般是将元素和所有集合中的元素进行对比,当前元素和集合中元素某个元素完全一致的时候,就认为当前元素在该集合中,这时常借助树、散列表、链表以及数组等先存储对应的元素,然后在进行对比。这种情况下时间复杂度为O(logn) , O(1), O(n)
当元素数量比较小时,使用这些数据接口进行比对没有什么问题,但是随着元素个数的增加,对比的时间最低也是线性增长的,为了解决这个问题Bloom Filter就应运而生了。
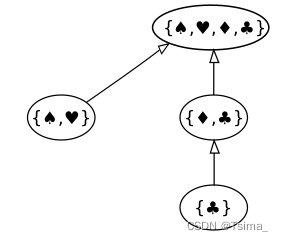
布隆过滤器由一个固定大小的二进制向量或者位图和一系列映射函数组成,在初始化状态下所有状态都会被置为零。

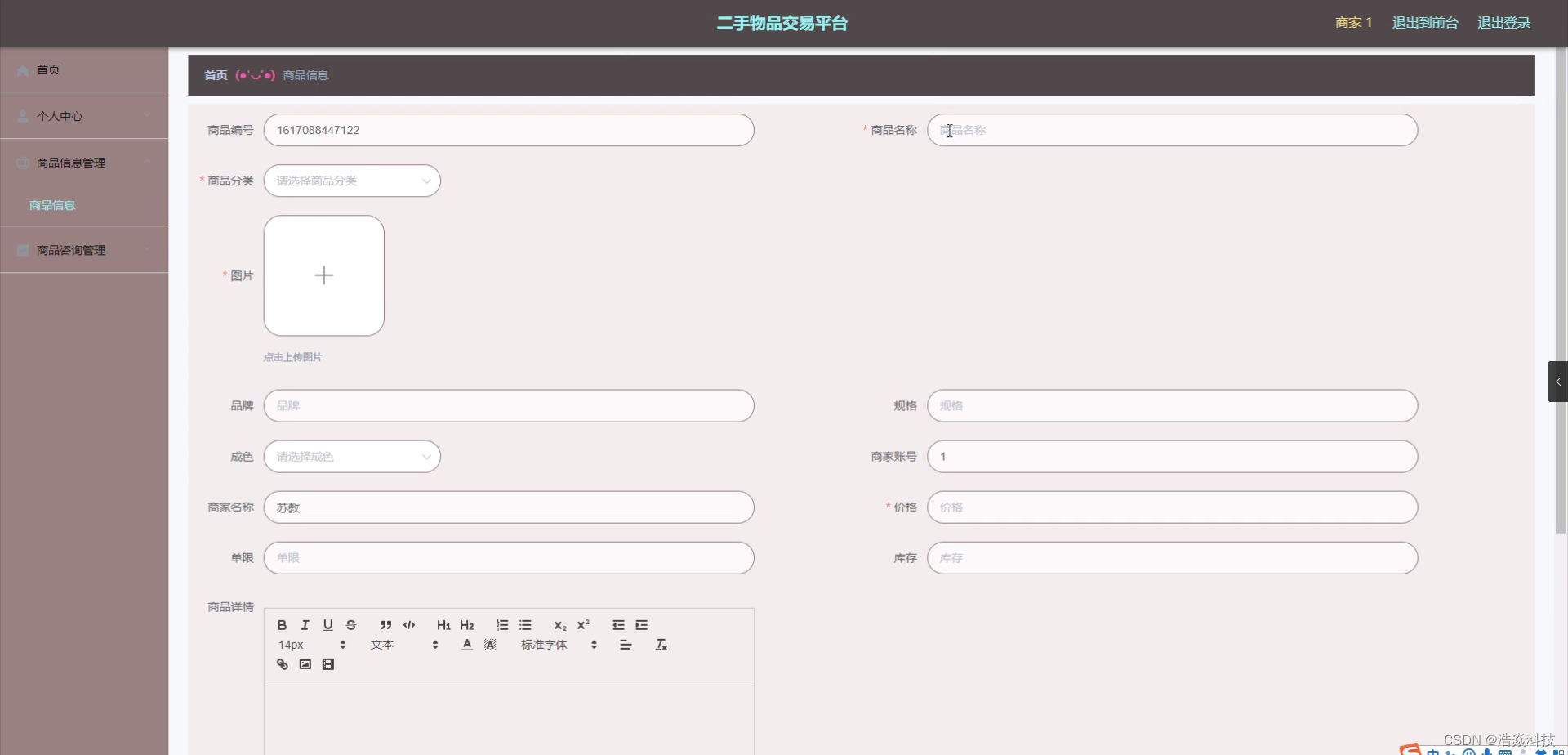
创建过滤器的过程中,将集合中的所有值,通过k个映射函数,映射为过滤器中对应的点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C24IJIpu-1669952236125)(https://ny5odfilnr.feishu.cn/space/api/box/stream/download/asynccode/?code=OTU4NWY1ZmExODNlZmExODJjZjk0NmVkODcyMTc4YTFfaFYxckNkREFYRHVDU0dFRTVWSmoxd1RrV1dPMGZJZnJfVG9rZW46Ym94Y25LRWJGcm5qZTNZdHVpM0xyTmNhUExjXzE2Njk5NTIxMDg6MTY2OTk1NTcwOF9WNA)]](https://img-blog.csdnimg.cn/09b85677ae5546399f71a6f7d26412c4.png)
当查询某个变量是否存在时,只需要按照同样的操作步骤,然后看对应的对应位置上是否全部为1,来判断集合中是否有这个值。
-
如果集合中有任意一个k映射出来的值不符合,说明被查询的标量一定不存在集合中
-
如果k映射的所有值都是存在的,则说明被查询的值有可能在集合中。
误判性
为什么可能存在? 当hash函数生成的散列值发生碰撞时,就有可能发生两个不同的值生成的散列值缺失相同的,还有就是经过多个元素映射的布隆过滤器,某个值的散列值经过k的映射刚好全部为1,但是这些1是多个元素一起映射的结果,而不是由单个元素映射在布隆过滤器上的。
特性
-
一个元素被判断存在的时候不一定存在,但是被判断结果为不存在的时候一定不存在
-
布隆过滤器可以添加元素,但是不能删除元素,因为删除元素会导致判断误判性增加,除非重新映射一遍
优势
相比于其他数据结构,布隆过滤器在空间和时间方面都有巨大的优势,插入和查询的时间空间复杂度都是常数O(K)
劣势
误算率比较高,随着元素的增加误算率也会随之增加,但是元素太少时,还不如直接使用散列表,因此要把握好元素的度。
不能在布隆过滤器中删除元素
代码实现
接口定义
class LEVELDB_EXPORT FilterPolicy {
public:
virtual ~FilterPolicy();
// Return the name of this policy. Note that if the filter encoding
// changes in an incompatible way, the name returned by this method
// must be changed. Otherwise, old incompatible filters may be
// passed to methods of this type.
virtual const char* Name() const = 0;
// keys[0,n-1] contains a list of keys (potentially with duplicates)
// that are ordered according to the user supplied comparator.
// Append a filter that summarizes keys[0,n-1] to *dst.
//
// Warning: do not change the initial contents of *dst. Instead,
// append the newly constructed filter to *dst.
virtual void CreateFilter(const Slice* keys, int n,
std::string* dst) const = 0;
// "filter" contains the data appended by a preceding call to
// CreateFilter() on this class. This method must return true if
// the key was in the list of keys passed to CreateFilter().
// This method may return true or false if the key was not on the
// list, but it should aim to return false with a high probability.
virtual bool KeyMayMatch(const Slice& key, const Slice& filter) const = 0;
};
hash函数,levelDB中使用的hash函数不是stl中标准的Hash函数是自己实现的一个hash函数
uint32_t BloomHash(const Slice &key) {
return Hash(key.data(), key.size(), 0xbc9f1d34);
}
uint32_t Hash(const char *data, size_t n, uint32_t seed) {
// Similar to murmur hash
const uint32_t m = 0xc6a4a793;
const uint32_t r = 24;
const char *limit = data + n;
uint32_t h = seed ^(n * m);
// Pick up four bytes at a time
while (data + 4 <= limit) {
uint32_t w = DecodeFixed32(data);
data += 4;
h += w;
h *= m;
h ^= (h >> 16);
}
// Pick up remaining bytes
switch (limit - data) {
case 3:
h += static_cast<uint8_t>(data[2]) << 16;
FALLTHROUGH_INTENDED;
case 2:
h += static_cast<uint8_t>(data[1]) << 8;
FALLTHROUGH_INTENDED;
case 1:
h += static_cast<uint8_t>(data[0]);
h *= m;
h ^= (h >> r);
break;
}
return h;
}
函数实现
class BloomFilterPolicy : public FilterPolicy {
public:
explicit BloomFilterPolicy(int bits_per_key) : bits_per_key_(bits_per_key) {
// We intentionally round down to reduce probing cost a little bit
// 按照计算公式 k = m/n * (ln2)来计算hash函数个数, m bit个数,n插入元素个数
// leveldb 中简单处理了,一般这里会直接传入 bits_per_key 为 10进行计算
k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
// 保证K_是处于 [1,30] 之间
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;
}
const char *Name() const override { return "leveldb.BuiltinBloomFilter2"; }
// 将传入的n个 key 存储到bloomfilter 中,bloomfilter结果使用string存储。
void CreateFilter(const Slice *keys, int n, std::string *dst) const override {
// Compute bloom filter size (in both bits and bytes)
// bloomfilter需要多少bit bits_per_key_ = (m/n) m bit个数,n插入元素个数
size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it
// by enforcing a minimum bloom filter length.
// 当bits太小的时候,会导致过滤器一直虚报错误,这里保证bits不小于64就可以了
if (bits < 64) bits = 64;
// 这里只是保证bits能够按照8位对齐
size_t bytes = (bits + 7) / 8;
bits = bytes * 8;
// 在string中分配空间
const size_t init_size = dst->size();
dst->resize(init_size + bytes, 0);
// string最后一个元素存储使用的 hash函数的个数
dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
// 获取string 内部的char型数组,数组指向多申请出来的内存,多申请出来的内存,用来存放Bloom hash映射值
char *array = &(*dst)[init_size];
for (int i = 0; i < n; i++) {
// 通过一次hash计算 一次delta计算,循环K_次将对应的 key在bits上进行置位
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
// leveldb使用一个hash函数,每次对hash值向右移位17bit来模拟实现多个hash函数
uint32_t h = BloomHash(keys[i]);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
// 多次重新计算hash模仿多个 hash函数,这里换成多个hash函数也是一样的
for (size_t j = 0; j < k_; j++) {
// 保证h 的长度不大于bloom过滤器的长度
const uint32_t bitpos = h % bits;
// 对对应位置进行置位
array[bitpos / 8] |= (1 << (bitpos % 8));
// 更新获得一个新的hash数值
h += delta;
}
}
}
bool KeyMayMatch(const Slice &key, const Slice &bloom_filter) const override {
const size_t len = bloom_filter.size();
if (len < 2) return false;
const char *array = bloom_filter.data();
// 最后一个byte代表了使用多少hash函数
// 除最后一个byte之外代表bit数组,详情将CreateFilter函数
const size_t bits = (len - 1) * 8;
// Use the encoded k so that we can read filters generated by
// bloom filters created using different parameters.
// 存储的是hash函数的个数
const size_t k = array[len - 1];
if (k > 30) {
// Reserved for potentially new encodings for short bloom filters.
// Consider it a match.
return true;
}
uint32_t h = BloomHash(key);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k; j++) {
const uint32_t bitpos = h % bits;
// (array[bitpos / 8] & (1 << (bitpos % 8)))
// 查找对应的bit位是否为0 若为0说明肯定不存在,就直接返回
if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) return false;
h += delta;
}
// 只是说明可能存在
return true;
}
private:
// 平均每个key拥有的bit数目
size_t bits_per_key_;
// hash func的个数
size_t k_;
};
![[附源码]计算机毕业设计JAVA学生考试成绩分析系统](https://img-blog.csdnimg.cn/3760c73c2deb4787ac40f1881b905df7.png)

![[附源码]Python计算机毕业设计Django基于VUE的网上订餐系统](https://img-blog.csdnimg.cn/6a15efb3e5be4b6bae628b111c2e33f4.png)