本文目录
- 一、线程 bug
- 二、解决方案
- 2.1 加停顿
- 2.2 单线程
- 2.3 多 Token
- 三、一点花絮
很久没有写业务实战记录了,实际工作过程中其实遇到了挺多问题的,但是要通过 CSDN 记录下来,还是比较难的,因为场景和目标比较难说清楚,为了降低业务壁垒和脱敏,通常需要花更多的时间进行整理,可能还需要反复修改。
一、线程 bug
今天讲一个多线程的东西,由于我之前对这个不是很理解,所以处理起来还是比较棘手,所以想着记录一下,可能你也会有同样的困惑,希望能够帮上忙。
不知道大家有没有用过或者听说过多维表,维格表简单讲就是一款多维表。
目前飞书表格也可以使用多维表,如果只是使用的话,还是停舒服的,但是如果涉及到数据传输,比如说数据入库,或者将一些数据同步到飞书表格上,会有一定的限制,首先需要企业版,再者需要企业管理员创建应用,或者个人创建应用给企业管理员审批。
维格表就好在这一点,数据处理来去自由,通过 API 接口可以轻松获取、更新、新增、删除数据。
可以比较自由地使用。【打住,这不是广告文】
说说最近遇到的一个问题:之前的同事写了一个 Python 脚本,用于往维格表更新和插入数据,之前跑得挺顺畅,但是最近一段时间发现同步任务经常出现了一定的数据缺失。之前跑一次就可以完成,现在需要跑几次才可以。
前阵子由于忙其他的项目,没有去修 bug,这些天得空了,挖一挖,顺便把它改一改适配 ODPS Python,把手工任务放到阿里云上自动调度,省得手工跑(虽然不是我负责跑,哈哈哈)。
之前没有问题,但是现在有问题了,有可能是多维表最近有更新导致,不过,看了更新日志,简单到一下子看完了三年的更新,没有什么有价值信息。
直接去看 API 手册,发现了一些比较有价值的信息点:
同一个用户对同一张表的 API 请求频率上限为 5 次/秒。
获取记录接口:一次最多获取 1000 行记录。
比如想批量获取 10000 行记录,至少需要调用 10 次获取记录接口。
创建记录接口:一次最多创建 10 行记录。
比如想批量创建 1000 行记录,至少需要调用 100 次创建记录接口。
更新记录接口:一次最多更新 10 行记录。
比如想批量更新 1000 行记录,至少需要调用 100 次更新记录接口。

结合源码,源码采用了多线程(开启 3 个线程)更新和写入的方式,基本可以定位到具体的问题,就是多线程在 1 秒内请求同一张表的频率超过了 5 次,导致 5 次内的任务没问题,超过 5 次的任务失败了。
简化之后的代码如下:
import concurrent.futures
import time
def task(index):
# 执行任务的代码,这里是更新或新增数据的任务
print(f"任务 {index} 开始")
time.sleep(0.1) # 模拟执行时间
print(f"任务 {index} 完成")
return F"result:任务{index} 完成"
# 创建线程池
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
# 提交多个任务到线程池
tasks = [executor.submit(task, i) for i in range(5)]
# 输出任务执行结果
for future in tasks:
print(future.result())
二、解决方案
2.1 加停顿
为了不改动源码太多内容,我减少了1个线程,并添加了停顿时间,每 0.5 秒跑一个任务,1 秒跑 4 个任务,结果是没有问题的,能够将所有的数据都完整更新或插入。新增第 4 行和第 16 行,修改第11行,max_workers 改为 2。
import concurrent.futures
import time
def task(index):
time.sleep(0.5) # 增加 0.5 秒的停顿
# 执行任务的代码,这里是更新或新增数据的任务
print(f"任务 {index} 开始")
time.sleep(0.1) # 模拟执行时间
print(f"任务 {index} 完成")
return F"result:任务{index} 完成"
# 创建线程池
executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)
# 提交多个任务到线程池
tasks = [executor.submit(task, i) for i in range(10)]
# 等待每一批次所有任务完成,再开始下一批
concurrent.futures.wait(tasks)
# 输出任务执行结果
for future in tasks:
print(future.result())
2.2 单线程
如果采用单线程,控制每 0.2 秒跑一次也是可以的,开启线程反而有点大材小用了, 反正都快不了,最快只能 5 次/秒,单线程也够用。这个代码就是将所有多线程相关的代码全部删掉或注释掉,然后,通过一个简单循环,并控制每个循环停顿 0.2 秒,将数据直接更新或插入多维表中即可。
2.3 多 Token
当然,也可以有更加骚的操作,搞多几个用户的 Token,交替使用,需要评估下速度,避免速度太快导致数据缺失。这个代码应该挺有意思的,就是将配置一个 Token 池,然后每次任务分别给不同的 Token 跑数,一个 Token 可以请求 5 次,示例使用 3 个 Token 便可请求 15 次。当然,这样是否会存在数据任务丢失,还是需要评估一下,如何还出现丢失,可以考虑加 Token 或者加停顿时间。
import concurrent.futures
import time
def task(task_num, token):
# time.sleep(0.5) # 停顿 0.5 秒
# 执行任务的代码,这里可以是你自己的任务逻辑
print(f"任务 {task_num} 开始,使用{token}")
time.sleep(0.1) # 模拟执行时间,停顿 0.1 秒
print(f"任务 {task_num} 完成,使用{token}")
return F"result:任务{task_num} 完成"
# 创建线程池
executor = concurrent.futures.ThreadPoolExecutor(max_workers=4)
# 假设有 3 个 token,10 组数据,需要循环 4 次
token_pool = ['token1','token2','token3'] # Token 池
groups_num = 10 # 数据组数(任务数),用于多维表的更新或新增,每组上限10条
token_num = len(token_pool) # Token 数
loop_times = groups_num // token_num + 1 # 循环使用 Token 池次数
tasks = []
for times in range(loop_times):
for index in range(token_num):
task_num = token_num*times+index # 任务数
token = token_pool[index]
# 最后一次循环跑完数据便停止,以免报错
if task_num == groups_num:
break
# 提交多个任务到线程池
tasks.append(executor.submit(task, task_num, token))
# 等待每一批次所有任务完成,再开始下一批
concurrent.futures.wait(tasks)
# 输出任务执行结果
for future in tasks:
print(future.result())
三、一点花絮
聊点花絮(不喜勿喷):
在 debug 的过程中,还是比较艰难的,也经历过了好一段时间的探索。
一开始图方便,让国内知名大模型帮忙支招,但似乎它并不能理解【停顿时间】,还和超时时间混淆,还有一个明显的解释错误,就是submit()的第二个参数并不是设置超时时间的,而是传参用的。当然,也提了改进反馈给官方。

后面让国外知名大模型试试,停顿时间理解对了,也给了可行的解决办法。
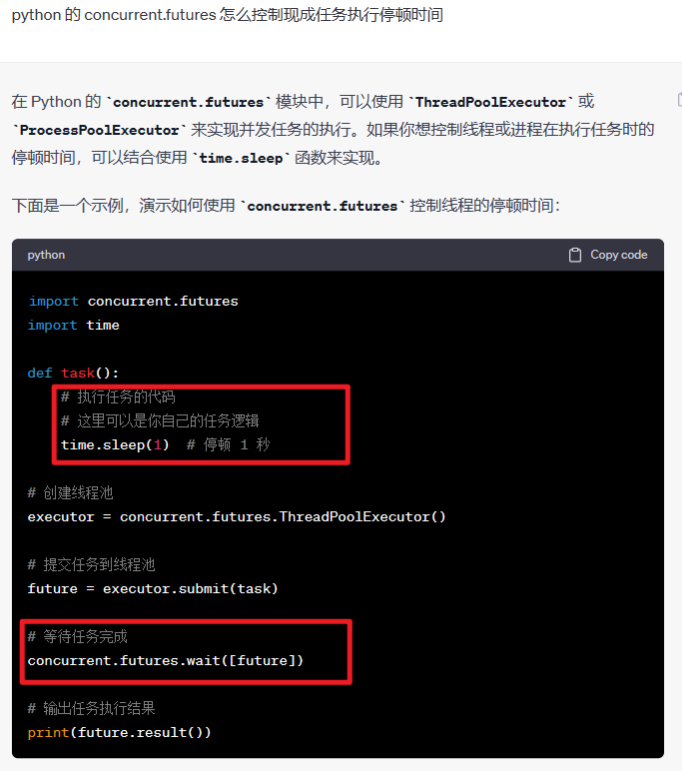
这里没有贬低和抬高的意思,只是国内知名大模型仍需努力,毕竟国外的,有诸多限制,不仅仅是使用限制,还有安全层面的考量,这几年的断芯是前车之鉴,值得深思。可以依赖但不能过度依赖。