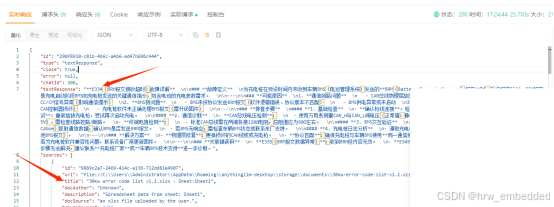
目录列表
- 过程分析
- 代码实现
过程分析
第一题比较简单,直接抓包即可,没有任何反爬(好像头都不用加。。。)
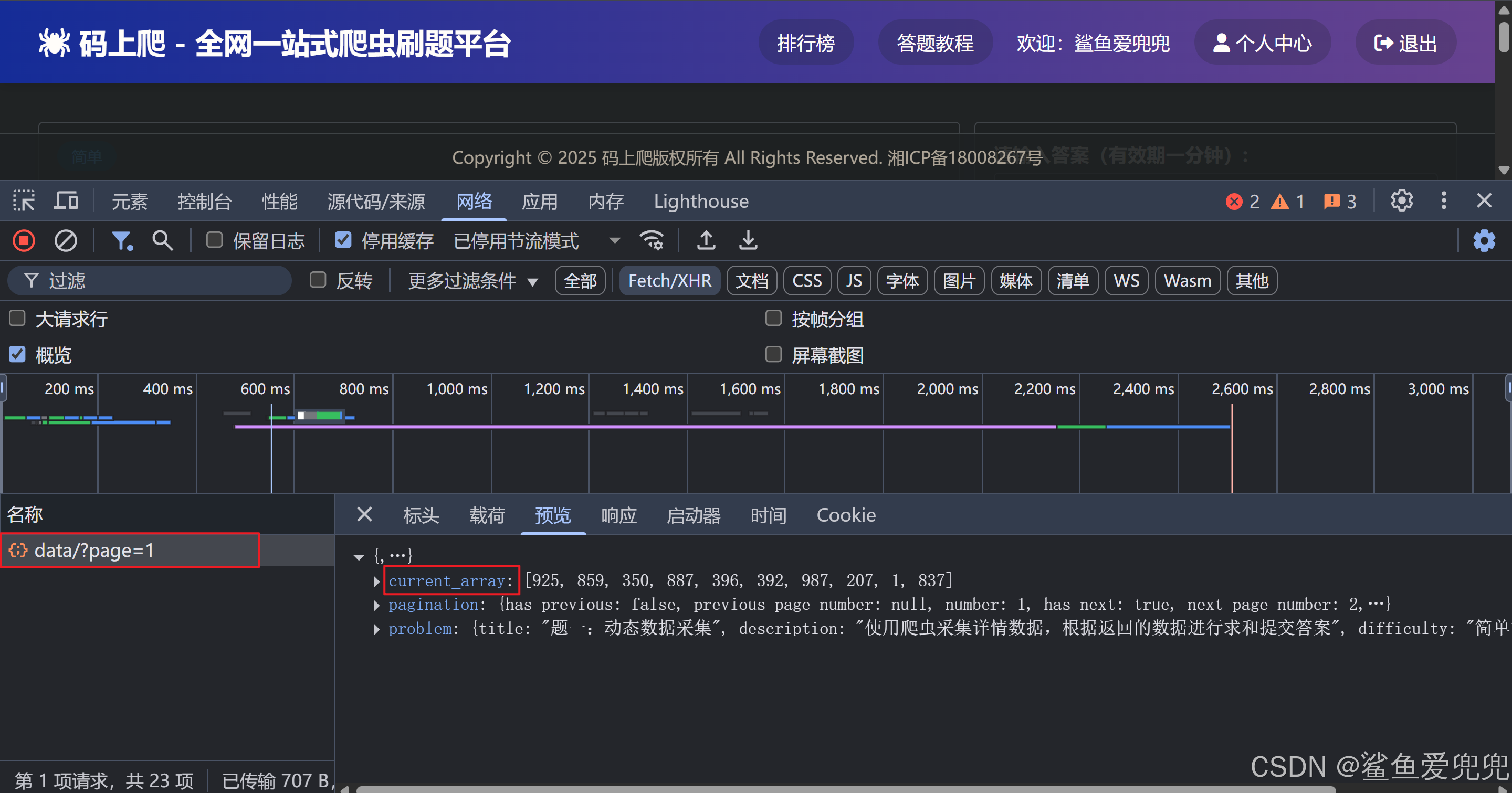
代码实现
答案代码如下:
"""
-*- coding: utf-8 -*-
@File : .py
@author : @鲨鱼爱兜兜
@Time : 2025/04/05 20:54
"""
import requests
# 替换成你的cookie
cookies = {
'Hm_lvt_b5d072258d61ab3cd6a9d485aac7f183': '1743857254',
'HMACCOUNT': '你的值',
'sessionid': '你的值',
'Hm_lpvt_b5d072258d61ab3cd6a9d485aac7f183': '1743857506',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://stu.tulingpyton.cn/problem-detail/1/',
'sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Google Chrome";v="134"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36',
}
s = 0
for page in range(1, 21):
params = {
'page': f'{page}',
}
response = requests.get('https://stu.tulingpyton.cn/api/problem-detail/1/data/', params=params, cookies=cookies,
headers=headers)
response.encoding = 'utf-8'
response.raise_for_status()
print(response.json())
s += sum(response.json()['current_array'])
print(s)
直接计算结果即可,如下图所示:
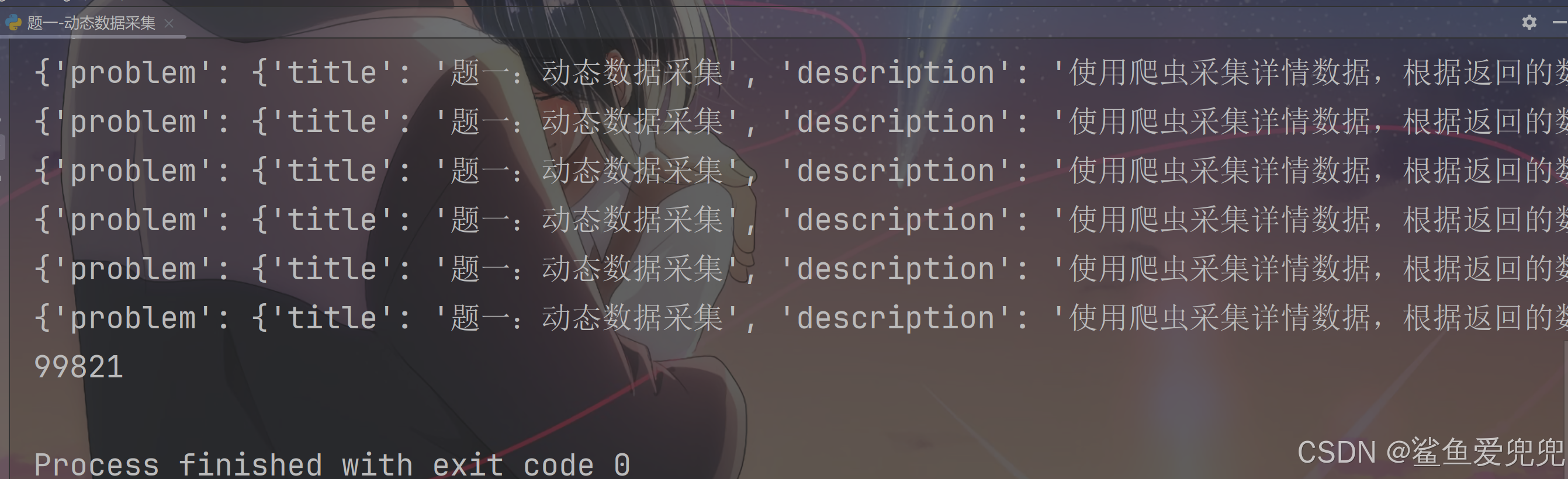
第一题秒了[doge]。。。
@鲨鱼爱兜兜