目录
一、系统环境和软件要求
二、软件说明
三、定义文本抽取管道(pipeline)
四、建立索引设置文档结构映射
五、插入文档
六、查询文档
需求是将本地邮件内容以及PDF,EXCEL,WORD等附件内容进行处理,保存到ES数据库,实现邮件内容及附件内容的全文检索。
一、系统环境和软件要求
系统:CentOS7.3
elasticsearch版本:7.13.3
kibana版本:7.16.3
ingest-attachment插件版本:7.13.3
二、软件说明
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。当前我们的用途主要是在kibana的开发工具dev tools中执行一些命令。
Ingest-Attachment是一个开箱即用的插件。可以将常用格式的文件作为附件写入Index。ingest attachment插件通过使用Apache Tika来提取文件,支持的文件格式有TXT、DOC、PPT、XLS和PDF等。 可以进行文本抽取及自动导入。注意:源字段必须是base64编码的二进制。
缺点:在处理xls和xlsx格式的时候,无法将sheet分开索引,只能将整个文件当做一个文档插入es中。
三、安装插件
我这里采用离线方式安装Ingest-Attachment,通过wget方式直接下载跟elasticsearch版本相同的离线文件。
wget https://artifacts.elastic.co/downloads/elasticsearch-plugins/ingest-attachment/ingest-attachment-7.13.3.zip上传到服务器 目录
/home/es/install/ingest-attachment-7.13.3.zip
进入ES_HOME的主目录,执行下面的命令进行安装
cd /home/elasticsearch/
./bin/elasticsearch-plugin install file:///home/es/install/ingest-attachment-7.13.3.zip安装完成后重启elasticsearch服务
插件安装完成!
三、定义文本抽取管道(pipeline)
在kibana的dev tool执行
我这里邮件可能是多个附件,所以定义文本抽取管道(多附件),我这里是设置 处理后移除base64的二进制数据。
需要注意的是,多附件的情况下,field和target_field必须要写成_ingest._value.*,否则不能匹配正确的字段。
PUT _ingest/pipeline/multiple_attachment
{
"description" : "Extract attachment information from arrays",
"processors" : [
{
"foreach" : {
"field" : "attachments",
"processor" : {
"attachment" : {
"target_field" : "_ingest._value.attachment",
"field" : "_ingest._value.content"
}
}
}
},
{
"foreach" : {
"field" : "attachments",
"processor" : {
"remove" : {
"field" : "_ingest._value.content"
}
}
}
}
]
}插件ingest attachment的pipeline参数含义
| Name | 是否必须 | Default | Description |
| field | yes | - | 从这个字段中获取base64编码 |
| target_field | no | attachment | 用于保留attachment信息,主要用于多附件的情况 |
| indexed_chars | no | 100000 | 限制字段的最大保存字符数。-1为无限制。 |
| indexed_chars_field | no | - | 可以从数据中设定的字段取到indexed_chars限制的值。 |
| properties | no | 全属性 | 选择需要存储的属性。例如 content, title, name, author, keywords, date, content_type, content_length, language |
| ignore_missing | no | FALSE | 如果使用true,并且 field 不存在, 则会忽略附件直接写入doc;否则则会报错。 |
四、建立索引设置文档结构映射
PUT mail
{
"settings": {
"index": {
"max_result_window": 100000000
},
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"mfrom": {
"type": "keyword"
},
"mto": {
"type": "keyword"
},
"mcc": {
"type": "keyword"
},
"mbcc": {
"type": "keyword"
},
"rcvtime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"subject": {
"type": "keyword"
},
"importance": {
"type": "keyword"
},
"savepath": {
"type": "keyword"
},
"mbody": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"attachments": {
"properties": {
"attachment": {
"properties": {
"content": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"filename": {
"type": "keyword"
},
"type": {
"type": "keyword"
}
}
}
}
}
}
}
}创建成功会返回
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "mail"
}五、插入文档
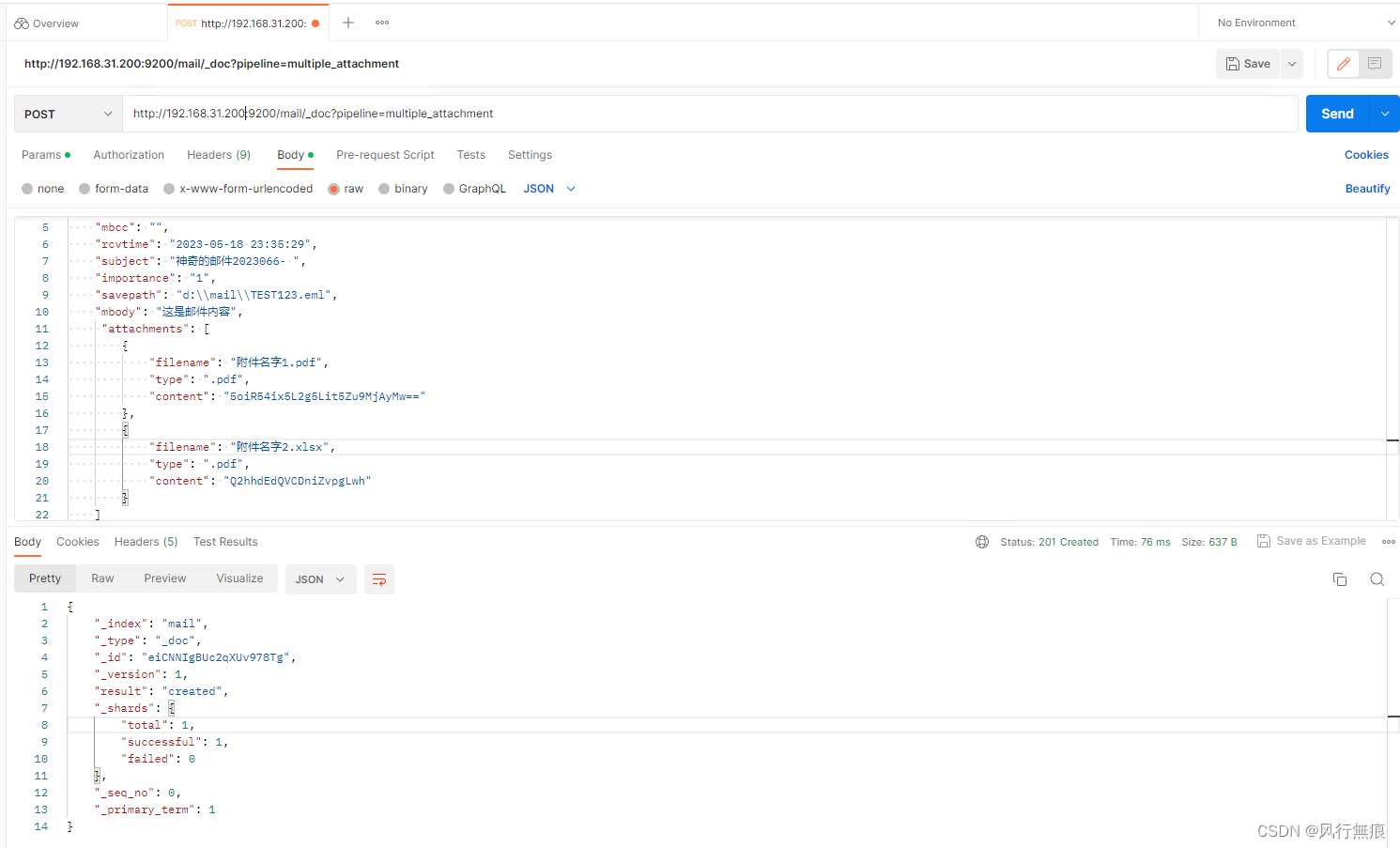
可以使用Postman来调用elasticsearch的rest full接口完成文档插入或者更新。
请求类型:POST
请求地址:http://192.168.31.200:9200/mail/_doc?pipeline=multiple_attachment
请求地址中mail是索引名,pipeline=multiple_attachment指定需要使用的管道(pipeline)是multiple_attachment
请求body内容是JSON格式:
{
"mfrom": "microsoft.teams@outlook.com",
"mto": "network@163.com",
"mcc": "",
"mbcc": "",
"rcvtime": "2023-05-18 23:35:29",
"subject": "神奇的邮件2023066- ",
"importance": "1",
"savepath": "d:\\mail\\TEST123.eml",
"mbody": "这是邮件内容",
"attachments": [
{
"filename": "附件名字1.pdf",
"type": ".pdf",
"content": "5oiR54ix5L2g5Lit5Zu9MjAyMw=="
},
{
"filename": "附件名字2.xlsx",
"type": ".xlsx",
"content": "Q2hhdEdQVCDniZvpgLwh"
}
]
}attachments是JSON数组,里面放2个附件的信息。filename是附件名字,content是附件解析出来的base64编码字符串。插入时通过管道处理,会自动识别内容,剩下的跟操作普通的索引一样。
下面是执行成功返回的内容:
{
"_index": "mail",
"_type": "_doc",
"_id": "eiCNNIgBUc2qXUv978Tg",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
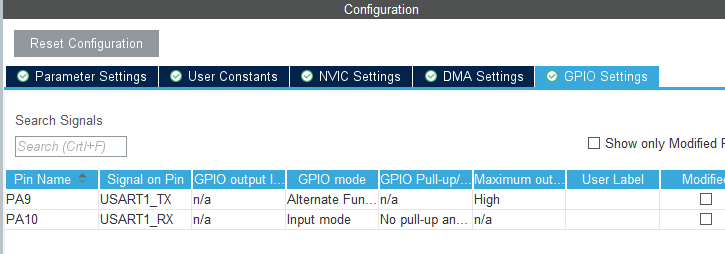
}Postman截图
六、查询文档
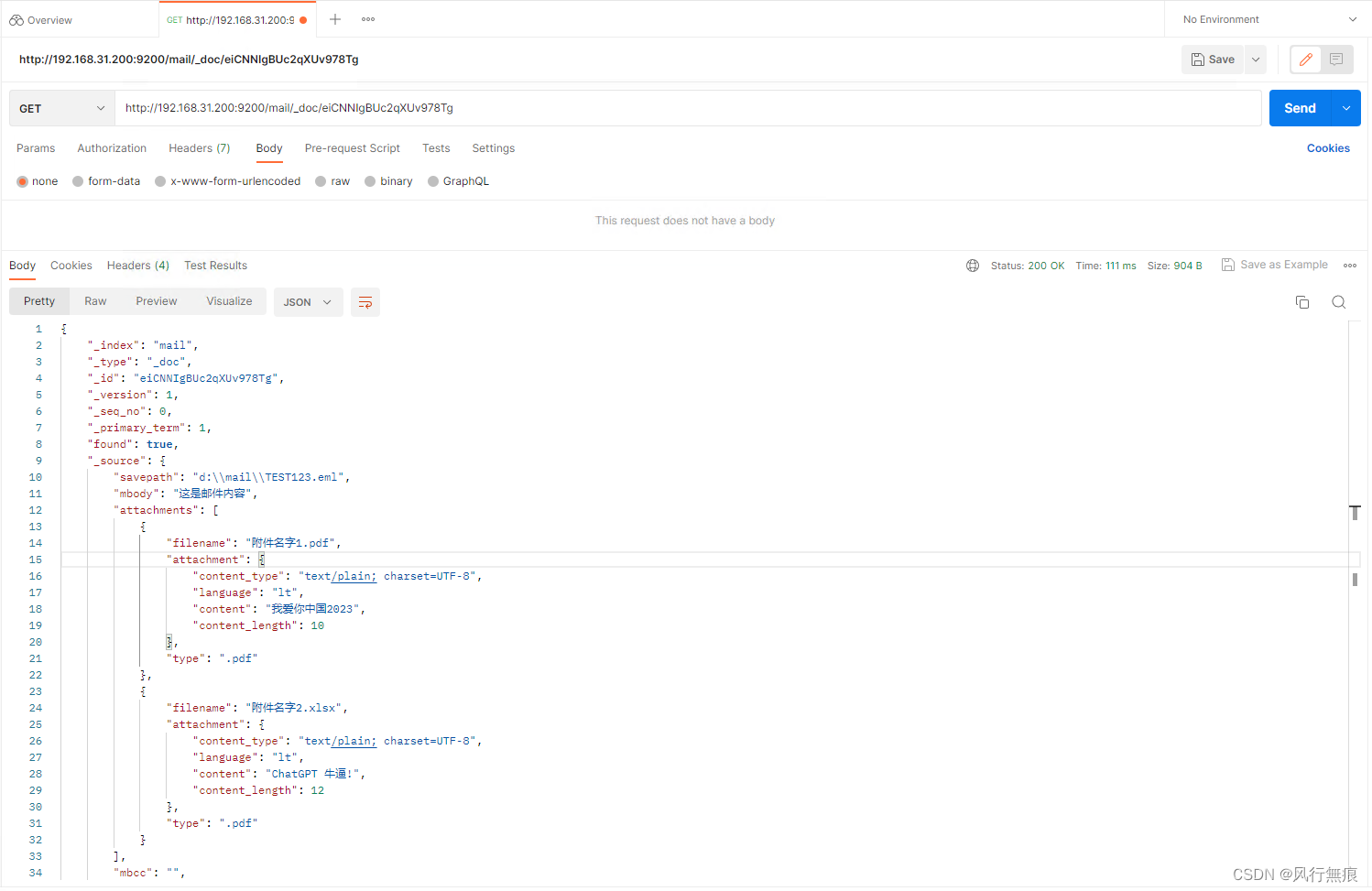
6.1 根据_id查看文档
GET请求地址 http://192.168.31.200:9200/mail/_doc/eiCNNIgBUc2qXUv978Tg
参数和内容无
其中eiCNNIgBUc2qXUv978Tg为文档_id,mail为需要查询的索引名
返回结果:
{
"_index": "mail",
"_type": "_doc",
"_id": "eiCNNIgBUc2qXUv978Tg",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"savepath": "d:\\mail\\TEST123.eml",
"mbody": "这是邮件内容",
"attachments": [
{
"filename": "附件名字1.pdf",
"attachment": {
"content_type": "text/plain; charset=UTF-8",
"language": "lt",
"content": "我爱你中国2023",
"content_length": 10
},
"type": ".pdf"
},
{
"filename": "附件名字2.xlsx",
"attachment": {
"content_type": "text/plain; charset=UTF-8",
"language": "lt",
"content": "ChatGPT 牛逼!",
"content_length": 12
},
"type": ".pdf"
}
],
"mbcc": "",
"subject": "神奇的邮件2023066- ",
"importance": "1",
"mfrom": "microsoft.teams@outlook.com",
"mto": "network@163.com",
"mcc": "",
"rcvtime": "2023-05-18 23:35:29"
}
}Postman截图
6.2 模糊查询附件名字
Post请求地址 http://192.168.31.200:9200/mail/_search
请求内容是JSON字符串,attachments.filename.keyword是附件名字(不分词)
{
"query": {
"bool": {
"should": [{
"wildcard": {
"attachments.filename.keyword": "*附件*"
}
}]
}
}
}返回结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "mail",
"_type": "_doc",
"_id": "eiCNNIgBUc2qXUv978Tg",
"_score": 1.0,
"_source": {
"savepath": "d:\\mail\\TEST123.eml",
"mbody": "这是邮件内容",
"attachments": [
{
"filename": "附件名字1.pdf",
"attachment": {
"content_type": "text/plain; charset=UTF-8",
"language": "lt",
"content": "我爱你中国2023",
"content_length": 10
},
"type": ".pdf"
},
{
"filename": "附件名字2.xlsx",
"attachment": {
"content_type": "text/plain; charset=UTF-8",
"language": "lt",
"content": "ChatGPT 牛逼!",
"content_length": 12
},
"type": ".pdf"
}
],
"mbcc": "",
"subject": "神奇的邮件2023066- ",
"importance": "1",
"mfrom": "microsoft.teams@outlook.com",
"mto": "network@163.com",
"mcc": "",
"rcvtime": "2023-05-18 23:35:29"
}
}
]
}
}6.3 模糊查询附件内容
POST请求地址 http://192.168.31.200:9200/mail/_search
请求内容为JSON格式,attachments.attachment.content是附件内容(不加密)
{
"size":"10000",
"_source" :[
"_id",
"seqnbr",
"subject",
"eml"
],
"query": {
"match": {
"attachments.attachment.content":"*ChatGPT*"
}
}
}返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "mail",
"_type": "_doc",
"_id": "eiCNNIgBUc2qXUv978Tg",
"_score": 0.2876821,
"_source": {
"subject": "神奇的邮件2023066- "
}
}
]
}
}七、其他说明
下面是单独说明的定义文本抽取的管道single_attachment
在kibana的dev tool执行
PUT _ingest/pipeline/single_attachment
{
"description" : "Extract single attachment information",
"processors" : [
{
"attachment" : {
"field": "data",
"indexed_chars" : -1,
"ignore_missing" : true
}
}
]
}剩下的就是代码集成的问题了。关于中文分词IK插件的使用,后期需要再详细说明。