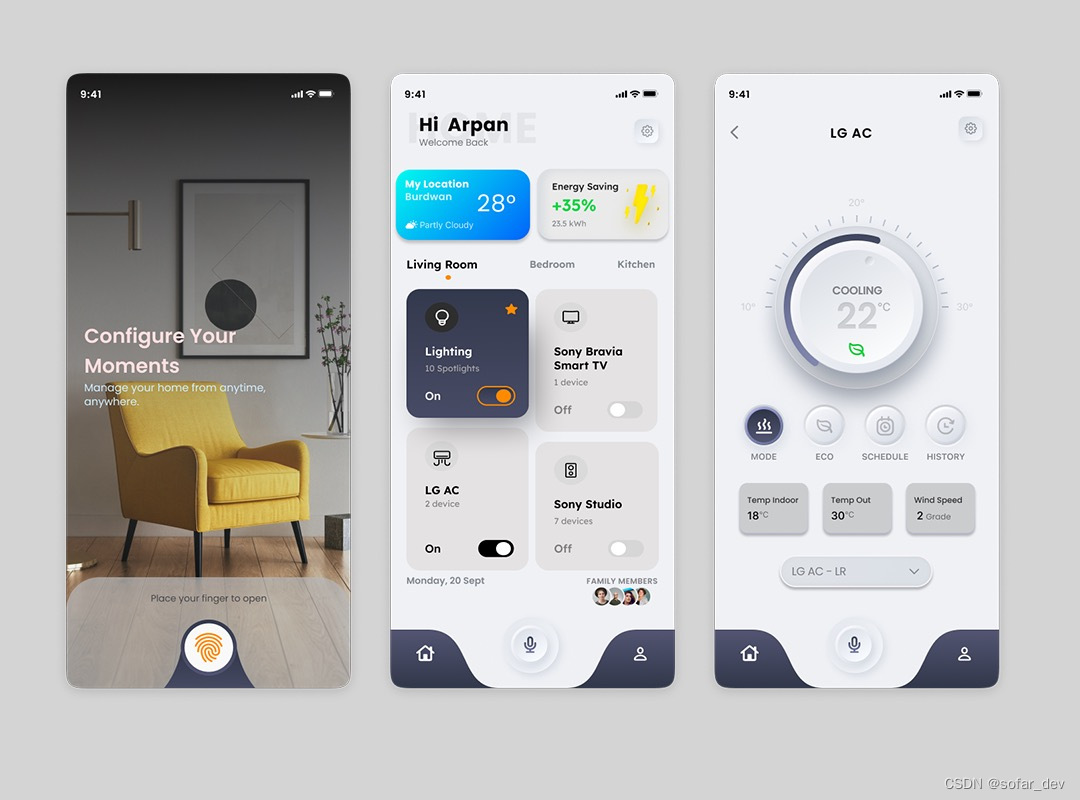
对比 Hashtable、HashMap、TreeMap 有什么不同?
典型回答
- Hashtable、HashMap、TreeMap 都是最常见的⼀些 Map 实现,是以键值对的形式存储和操作数据的容器类型。
- Hashtable 是早期 Java 类库提供的⼀个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
- HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。
- TreeMap 则是基于红黑树的⼀种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
考点分析
- 面试官钟爱考察 HashMap 的设计和实现细节:
- 理解 Map 相关类似整体结构,尤其是有序数据结构的⼀些要点。
- 从源码去分析 HashMap 的设计和实现要点,理解容量、负载因子等,为什么需要这些参数,如何影响 Map 的性能,实践中如何取舍等。
- 理解树化改造的相关原理和改进原因。
知识扩展
- Map 整体结构
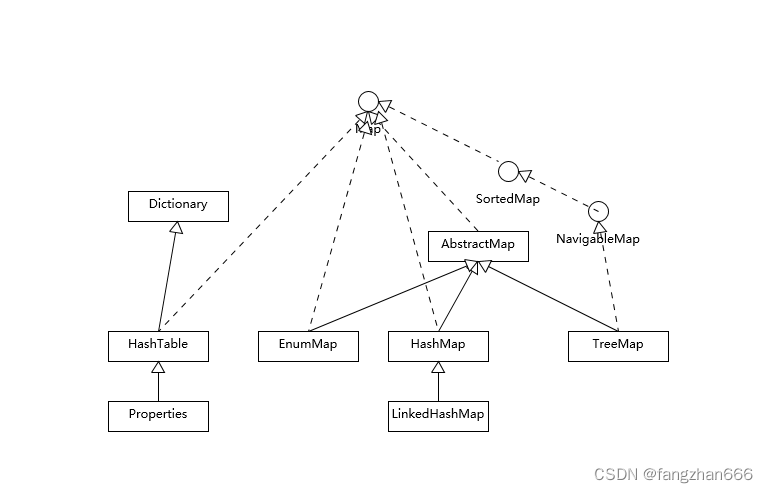
- Hashtable 比较特别,作为类似 Vector、Stack 的早期集合相关类型,它是扩展了 Dictionary 类的,类结构上与 HashMap 之类明显不同。
- HashMap 等其他 Map 实现则是都扩展了 AbstractMap,大部分使用 Map 的场景,通常就是放入、访问或者删除,而对顺序没有特别要求,HashMap 在这种情况下基本是最好的选择。
- HashMap 的性能表现非常依赖于哈希码的有效性,请务必掌握 hashCode 和 equals 的一些基本约定:
- equals 相等,hashCode 一定要相等。
- 重写了 hashCode 也要重写 equals。
- hashCode 需要保持一致性,状态改变返回的哈希值仍然要一致。
- equals 的对称、反射、传递等特性。
- LinkedHashMap 通常提供的是遍历顺序符合插入顺序,它的实现是通过为条目(键值对)维护一个双向链表。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所谓的 put、get、compute 等,都算作“访问”。
- 对于 TreeMap,它的整体顺序是由键的顺序关系决定的,通过 Comparator 或 Comparable(自然顺序)来决定。
- HashMap 构造分析
- HashMap 内部的结构,它可以看作是数组和链表结合组成的复合结构,数组被分为⼀个个桶(bucket),通过哈希值决定了键值对在这个 数组的寻址;
- 哈希值相同的键值对,则以链表形式存储,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),链表就会被改造为 树形结构。
- 容量和负载系数决定了可用的桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。
- 在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取性能。




![Midjourney|文心一格prompt教程[技巧篇]:生成多样性、增加艺术风格、图片二次修改、渐进优化、权重、灯光设置等17个技巧等你来学](https://img-blog.csdnimg.cn/img_convert/b9ee15357e16366663432430ccb883c7.png)