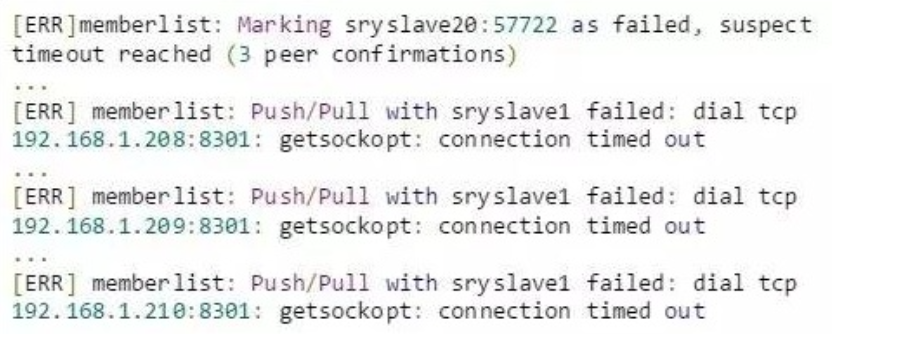
个人阅读笔记,如有错误欢迎指出
Arxiv 2022 [2201.09441] Federated Unlearning with Knowledge Distillation (arxiv.org)
问题:
法律要求客户端有随时要求将其贡献从训练中消除的权利
让全局模型忘记特定客户的贡献的一种简单方法是从头开始对模型进行重新训练,但已有的联邦消除方法增加了时间和能量的损耗
挑战:
全局模型的更新是一个增量过程,每一次更新都依赖上次的更新结果。若需要消除某一客户端的影响,单单在其退出的轮次消除是不够的,需要从头训练才能完全抹除该客户端对全局的贡献。
由于参与训练的客户端是随机选取的。每个客户端的局部训练过程中存在很多随机性,比如随机抽样的小批数据和批次的排序。所以,即使从头开始重新训练模型,也可能导致全局模型每次都收敛到不同的局部极小值。
边缘客户端存储空间可能有限,在训练完毕后很有可能会将数据删除。所以,要求客户通过再训练模型来校准历史更新,只在理论上有效。
创新:
知识蒸馏训练完全在服务器端,不需要标记的数据集,因此不会在客户端侧有时间和能量的消耗,同时也没有网络传输。
后门特征并不会从教师模型转移到遗忘模型,因为这些特征如果不出现后门模式就不会被激活。
蒸馏方法阻止了模型与数据的拟合太紧密,有助于更好地泛化训练点,从而有助于提高模型的鲁棒性,并在训练后进一步提高模型的性能。
方法:
核心思想:消除攻击者的历史参数更新,并通过知识蒸馏的方法恢复损害
FL知识蒸馏
(1)在服务器上使用知识蒸馏且不需要标记数据集,因此没有客户端的时间和能量损耗,也没有网络故障
(2)由于没有触发器,后门特征无法从教师模型转移到消除模型上
(3)知识蒸馏防止模型过拟合,有更好的泛化性
消除历史更新
若用表示第
轮更新,最终的全局模型
可以看作是初始模型权重
和第1轮到第F-1轮更新的组合
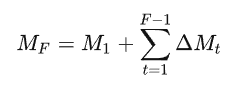
假设共个客户端且第
个为要消除的目标客户端。由此可以将问题简化为从全局模型更新
中消除目标客户端
的

计算第轮新的全局模型更新
,
方法一:假设在第轮时只有
个客户端参与训练。
在这种情况下我们可以得到聚合的全局更新
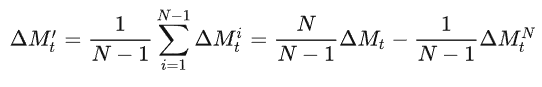
由于FL的增量学习的性质,该方法不能直接计算累计更新以重构消除模型
对每轮全局模型进行修正,使用来表示在每一轮中对全局模型的必要修正
但是因为联邦学习增量学习过程的特点, 随着通信轮数增加而增加,即使客户端在某轮通信中贡献较小,也会对全局模型造成较大的改变,并且该改变将在后续迭代中放大
方法二:鉴于方法一,使用懒学习消除客户端影响,
假设目标客户端仍然参与训练,但是模型更新为0,即

根据上式推导,可得到最终的全局模型
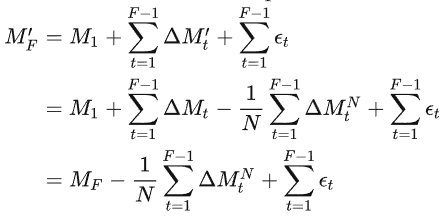
只需要从最终的全局模型中减去来自目标客户端
的所有历史平均的更新,然后使用
修正了因为联邦学习增量学习过程引起的偏差
结合知识蒸馏
动机:
当前没有方法能够通过不重新训练更新模型来得到偏差。
知识蒸馏在训练过程中获得的知识不仅被编码在权重中,还可以从模型的类概率中反映出来,可以提高模型的泛化性和鲁棒性。
方法:
将原始的全局模型作为教师模型,将其输出作为lable
服务器使用无标签的数据训练消除模型,并纠正补救偏差。若有带标签的数据,可以结合软标签和硬标签进行训练,且为了获得更多知识,需要给硬标签更少的权重
具体来说,原始的全局模型通过一个转换logit的softmax输出层产生类预测概率,为每个类计算成一个概率
。下式为原始全局模型计算软分类
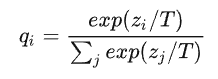
为温度,在softmax层中共享,温度越高概率分布越平均
输出层的logit
整体算法

总结:
相比FedEraser,本文先在全局模型上减去中毒更新,再利用知识蒸馏恢复模型性能。
后门特征不会从教师模型转移到遗忘模型,因为在知识蒸馏的训练过程中没有后门模式的出现,这些特征就不会被激活。
减少了额外的通信量,但是对服务器的存储量有较高的要求,并且需要服务器已知恶意客户端是哪一个,需要结合检测方法共同作用。

![Midjourney|文心一格prompt教程[技巧篇]:生成多样性、增加艺术风格、图片二次修改、渐进优化、权重、灯光设置等17个技巧等你来学](https://img-blog.csdnimg.cn/img_convert/b9ee15357e16366663432430ccb883c7.png)