歌唱评价是K歌系统中核心技术之一。近年来,歌唱评价领域也发生着多元化和深度化的变革。本次LiveVideoStackCon 2022 北京站邀请到腾讯音乐天琴实验室高级研究员——江益靓,为大家介绍全民K歌的多维度评价技术和深度歌唱评价技术的实践,以及优质内容挖掘中使用的音频品鉴系统。
文/江益靓
编辑/LiveVideoStack
各位同行朋友们,大家好,很高兴和大家一起分享交流,本次分享的主题是音频品鉴与歌唱评价——音频内容理解的一些技术实践。我是来自天琴实验室的益靓。

接下来将从四个方面展开介绍:歌唱评价概览、算法的探索以及落地的实践,最后会为大家介绍智能品鉴系统。
-01-
歌唱评价概览
歌唱评价是评价用户演唱是否动听,是否符合审美的一项任务。但在实际应用中还会分析更多维度,例如音色种类、音域范围、好听在哪里,哪个方面还有提升空间等等。
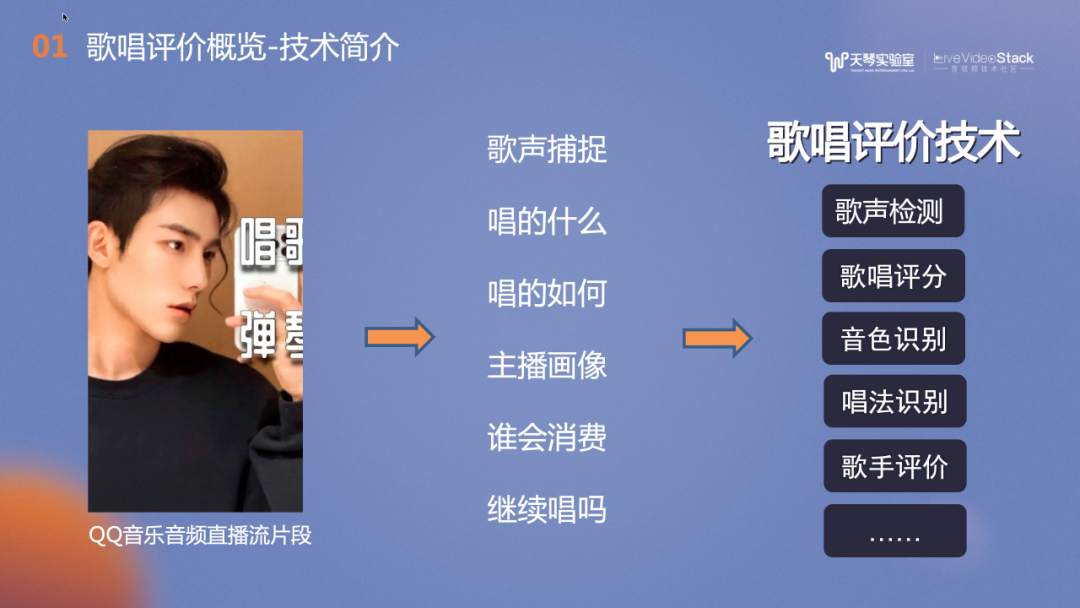
以QQ音乐的音频直播流片段为例。一位QQ音乐音频主播,直播了一小时。获取到直播流后,我们通过歌声检测技术捕捉了音频主播直播中的歌声片段,并使用音频指纹匹配歌曲,判断主播的演唱曲目。接下来,歌唱评价技术会结合主播演唱的音准、节奏、气息、技巧及情感进行分析,并通过声线的分析建模主播的画像,同时实时向主播提供歌唱反馈。还可以使用算法预测可能会喜欢这类声音的用户。这里会运用到很多歌唱评价的相关技术,例如歌声检测、歌唱评分、音色识别、唱法识别,歌手评价等。

歌唱评价最基础的能力是歌唱评分,TME的全民K歌、Wesing和酷狗唱唱使用了多维打分功能, 公司外的软件如Pokekara、StarMaker都有歌唱评分功能。Apple Music在去年12月推出了Apple Music Sing,提供了用户跟唱功能,暂时还不支持打分。歌唱评分在线下也有很多落地项目,例如去年的央视节目《唱出我新声》使用了多维打分SDK,综合专业评委评价以及机器AI评价为选手打分。此外,全民K歌的《校园新歌声》、《主播新声代》等线下赛事也引入了AI打分。
直播歌唱场景中,主播可以在音乐平台点伴奏,跟着旋律线唱歌,并和粉丝互动。主播可以以打分为依据,进行PK连麦。全民K歌中还有实时的歌唱竞技游戏——“K歌王者”。
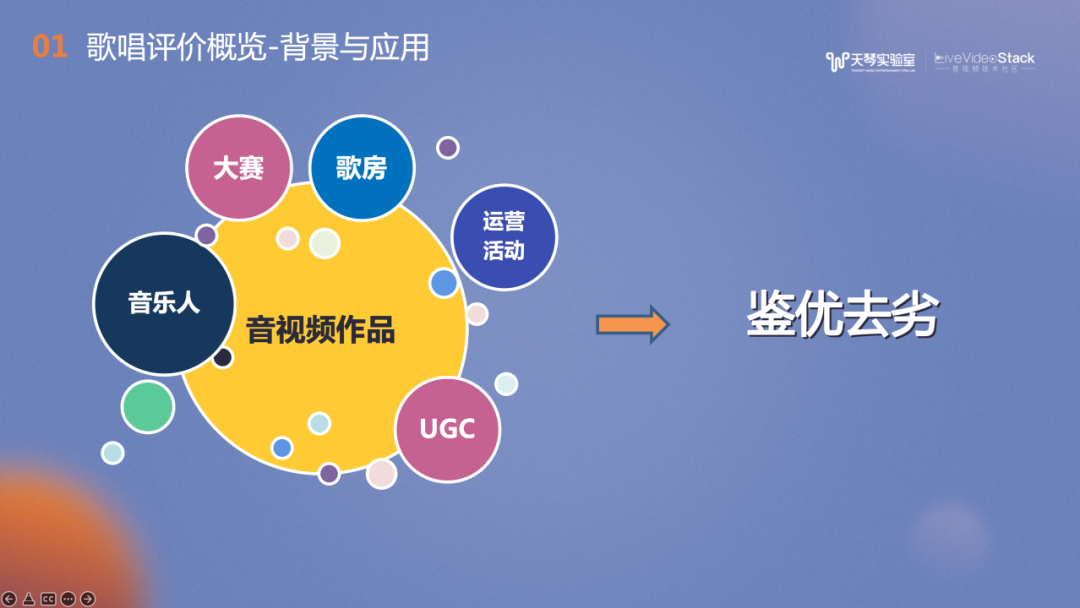
歌唱评价还可应用在优质作品筛选方面,如全民K歌的大赛、高质歌房筛选、运营活动中低质作品的过滤和高质作品的分发。此外,在QQ音乐中,也可以通过品鉴技术检测曲库中的低质作品,或者对入库作品的质量进行把关。总结来说,歌唱评价是一个鉴优去劣,或者说是品鉴的过程。
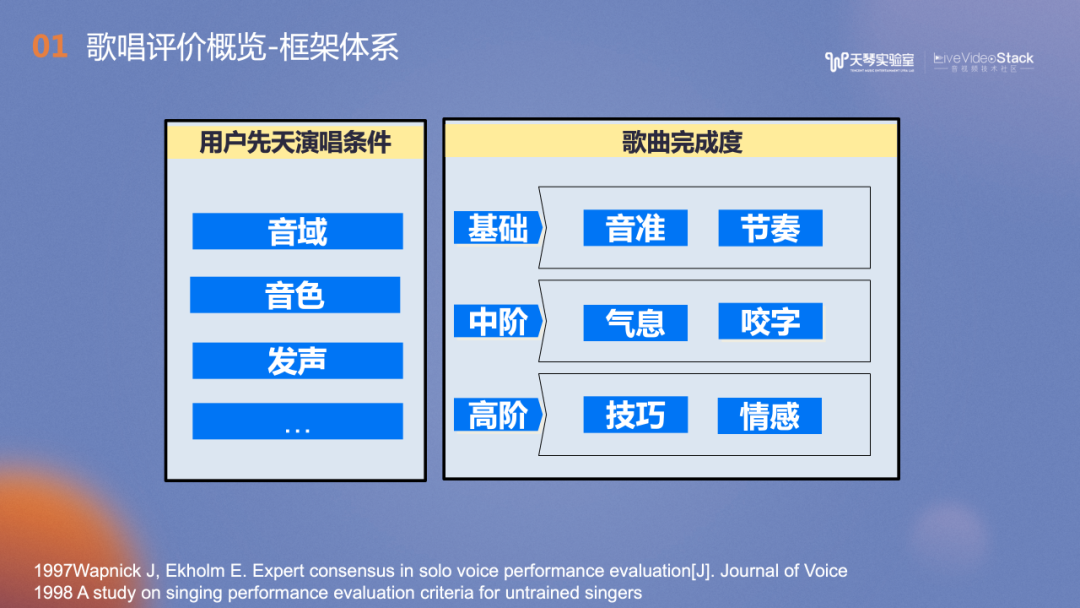
上图展示了我们参考文献和实际经验,搭建的歌唱评价体系。分为两个方面,一个是用户维度,一个是歌曲维度。用户维度和用户本身的特性相关,如音域、音色及发声,是相对稳定的评价维度,通过日常练习可以得到改善。歌曲维度则更偏向于歌曲本身,和用户本次演唱的表现有关,例如如基础的音准、节奏;中阶的气息、咬字以及高阶的技巧、情感。我们也逐一进行了技术实践。

歌唱评价分可分为有参考评价和无参考评价。有参考评价是指通过对比用户演唱特征与模板的匹配度来评分。例如对比用户演唱的基频和歌曲伴奏或者曲谱模板MID进行匹配,或者用户的时域,频域特征同分离原唱的时域、频域特征进行匹配。有参考评价更注重用户演唱和模版的一致性以及完成度的评价。无参考评价是指不依赖模版对用户演唱做出的评价,比较流行的做法是用数据驱动,拟合专家评分训练模型,使用神经网络学习“好声音”。
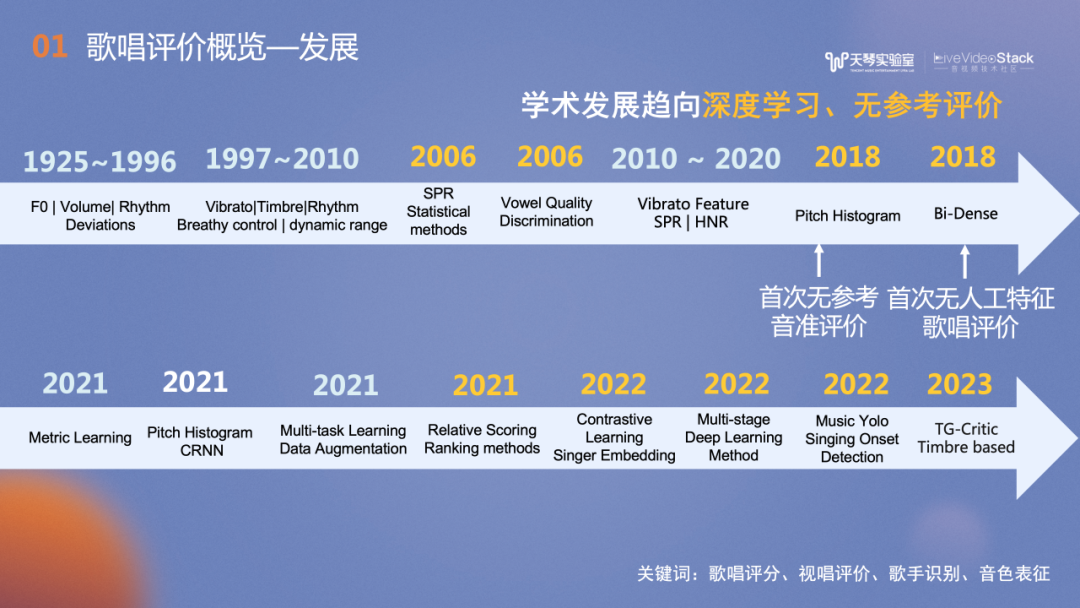
在学术研究领域,与其相关的关键词包含歌唱评分、视唱评价、歌手识别及音色表征等,都是音频/音乐内容理解相关子领域。纵观歌唱评价技术发展,最初的研究常常使用基频、响度及颤音等特征,随着时间的发展,无参考评价、深度学习技术使用的越来越多。
最终我们结合平台的实际情况,选择了有参考评价和无参考评价相结合的方案,目标是提供维度最全面,最公允的实时歌唱评价算法。
-02-
歌唱评价探索
第二部分我们介绍下歌唱评价的一系列探索。
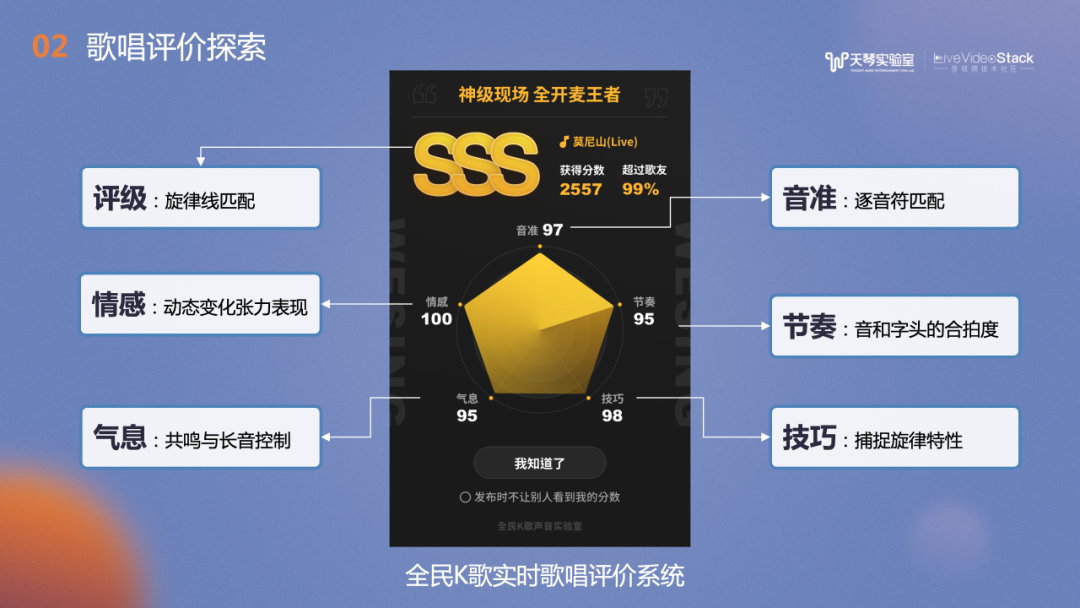
图中是全民K歌的打分面板,分为两部分:上方的“SSS”是评分等级,是全民K歌打分1.0的算法,主要是用户演唱旋律线与模版的匹配度评级,受到广大用户的喜爱。下方的五边形是2.0算法的五维打分图,每个顶点是各个维度的评分,包括音准、节奏、技巧,气息和情感,都是实时计算完成的。各个维度都是主要基于有参考评分的思路实现的。

在音准评价,我们提取用户演唱的旋律线——基频,并和曲谱模板MIDI进行匹配与评分。在设计算法时需要考虑许多细节,例如音和音之间的过渡的滑音及字尾的颤音。虽然这些细节可能与模板不匹配,但它们是演唱风格的体现之一,也是用户演唱能力的表现。右侧的节奏评价较常见的做法是旋律线与MIDI的动态规划匹配,我们也实现了用歌声ASR技术判断歌手唱的每个唱字时间点是否与歌词匹配。
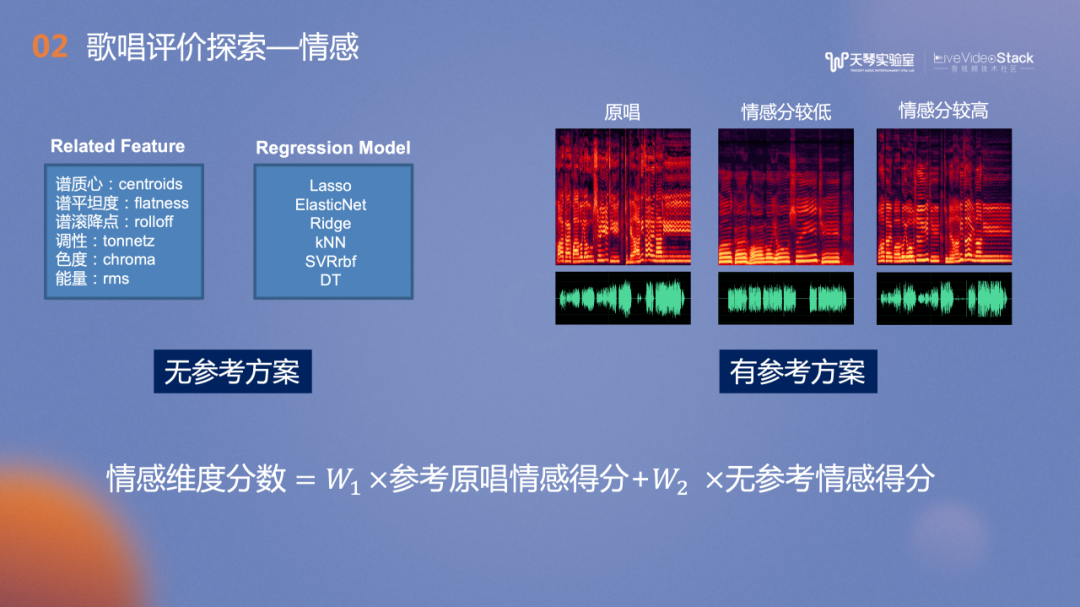
情感评价的相关的研究大多是关于情感分类和情感表征。那么如何给情感打分呢?歌唱的动态是一个很重要的特征。然而,动态越大并不意味着分数越高。例如,在K歌场景中,如果一首歌的旋律比较平稳,那么演唱者的情感也应该是平稳的才能得到高分;而在一首旋律起伏比较大的歌曲中,用户需要用较大的动态来演唱才能拿到高分。因此经过实验,我们选择有参考的评价方案,将音源分离后的原唱作为参考,并以动态信息和时频域特征信息为标杆,对比用户是否达到原唱的幅度及特征。当用户出现超离模板的表现力时,此时会引入无参考的情感得分,并对两项进行加权求和,最终得到情感分数。
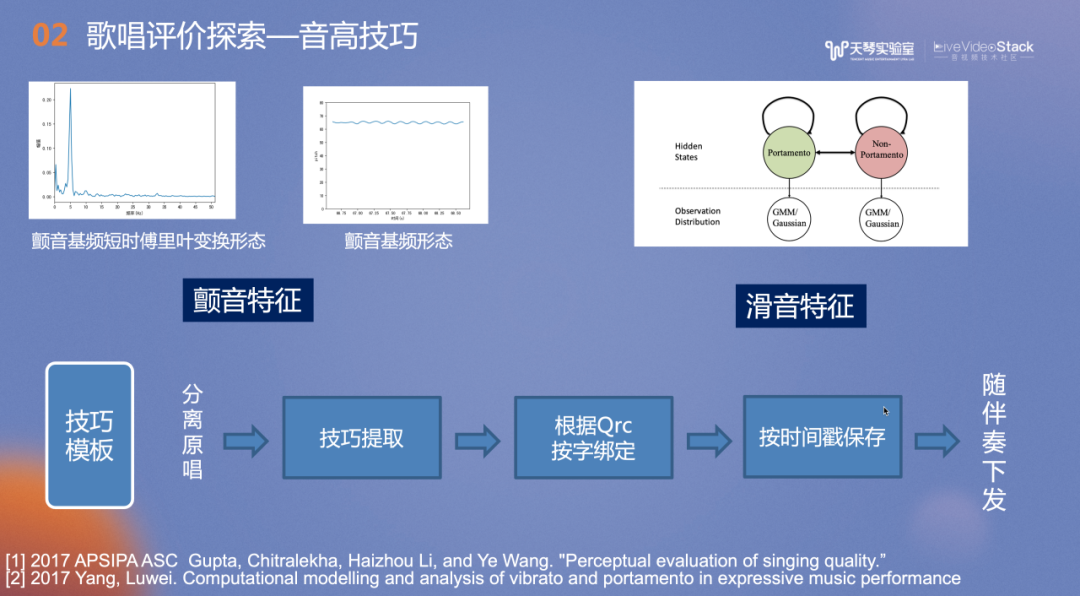
技巧评价的范围比较广,我们主要实现了音高和发声技巧的评价,接下来将重点介绍音高方面的技巧。我们会捕捉用户在演唱过程中的旋律特性,如旋律中的颤音及滑音特征。如何评价用户的技巧水平?颤音是否越多越好?类似的,我们会参考原唱进行评分。提前对分离的原唱进行技巧特征的提取,再根据歌词按字绑定,在唱歌教学场景,系统会提示用户原唱的某些字需要颤音或滑音,然后按照时间戳进行保存,随着伴奏下发。当用户在歌曲特定时间点演唱出了技巧,他会得到相应的分数。

上文主要介绍了通过有参考评价,使用到的方法主要包括特征提取、统计学习以及机器学习。除此之外,我们还尝试了度量学习方案,通过控制训练过程,帮助更好地捕捉“好声音”。
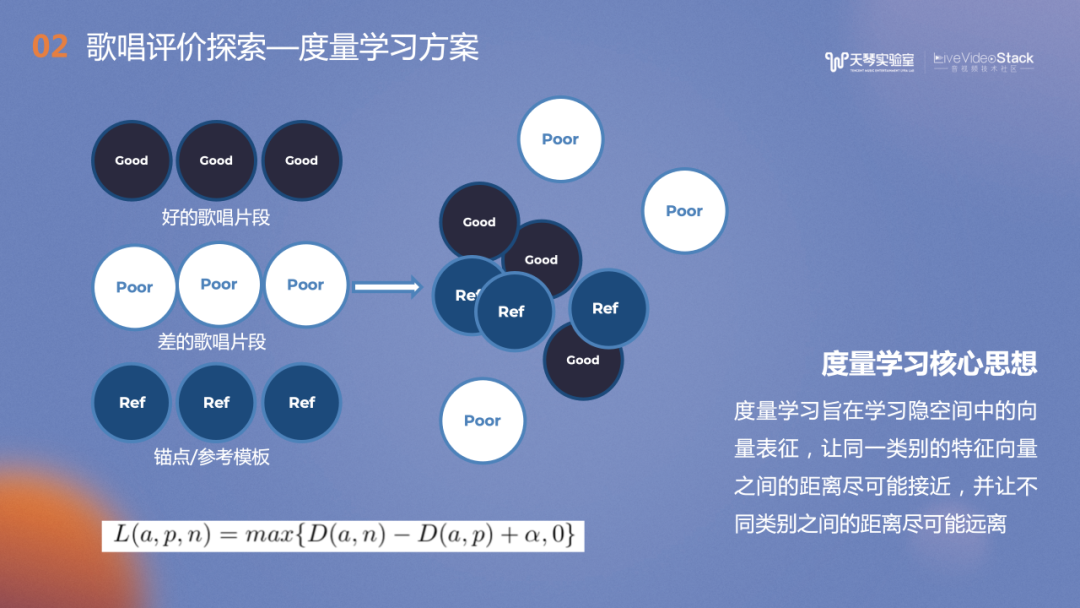
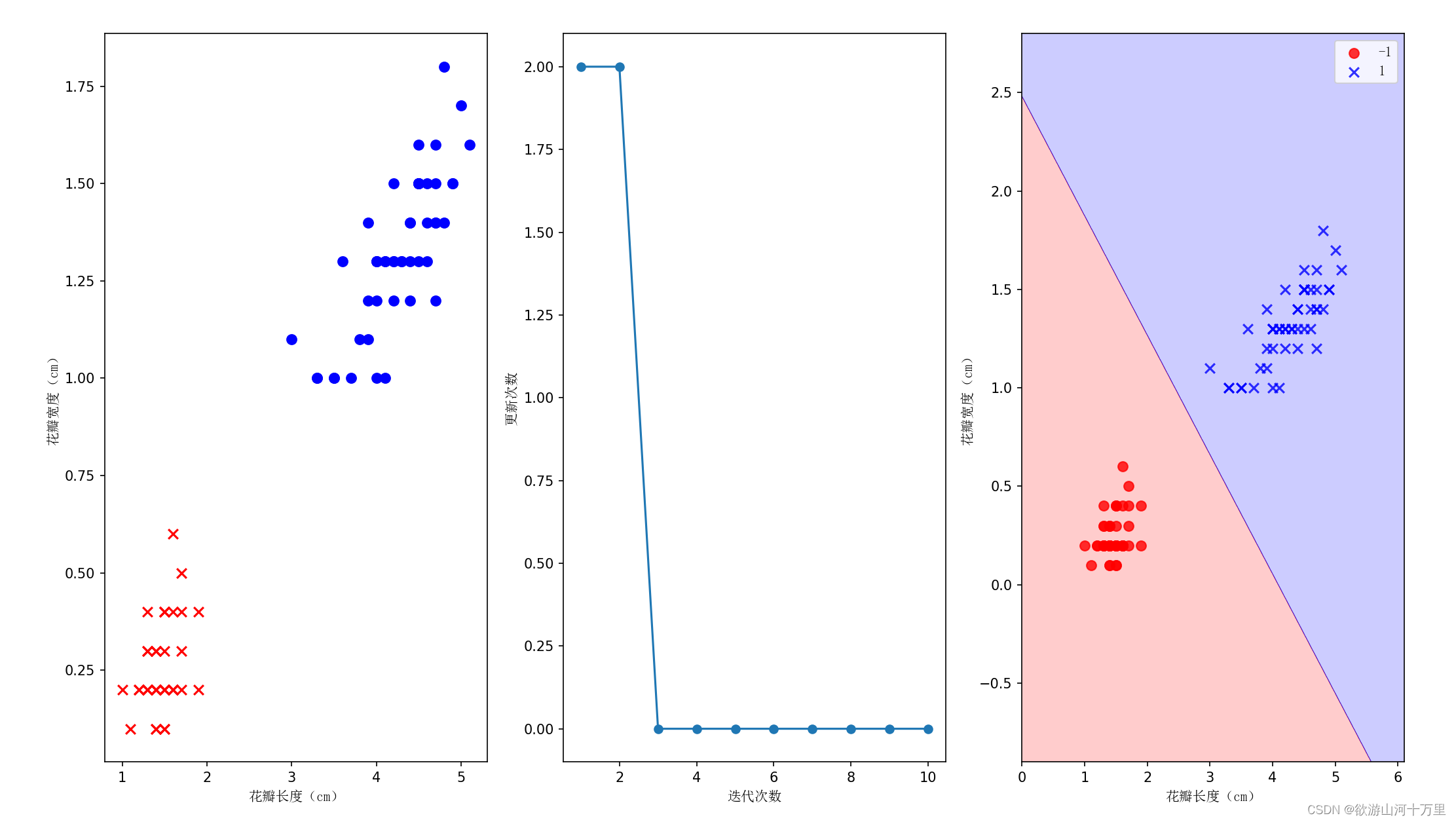
度量学习的主要思想是学习“好声音”的共性,以及和“不好声音”的差异性。图中左上角深蓝色部分是好的歌声片段,下方白色是差的歌唱片段。我们会选择一个锚点作为参考歌唱片段,一并汇入模型,让同一类别的特征向量之间的距离尽可能接近,并让不同类别之间的距离尽可能远离,以此来训练模型。
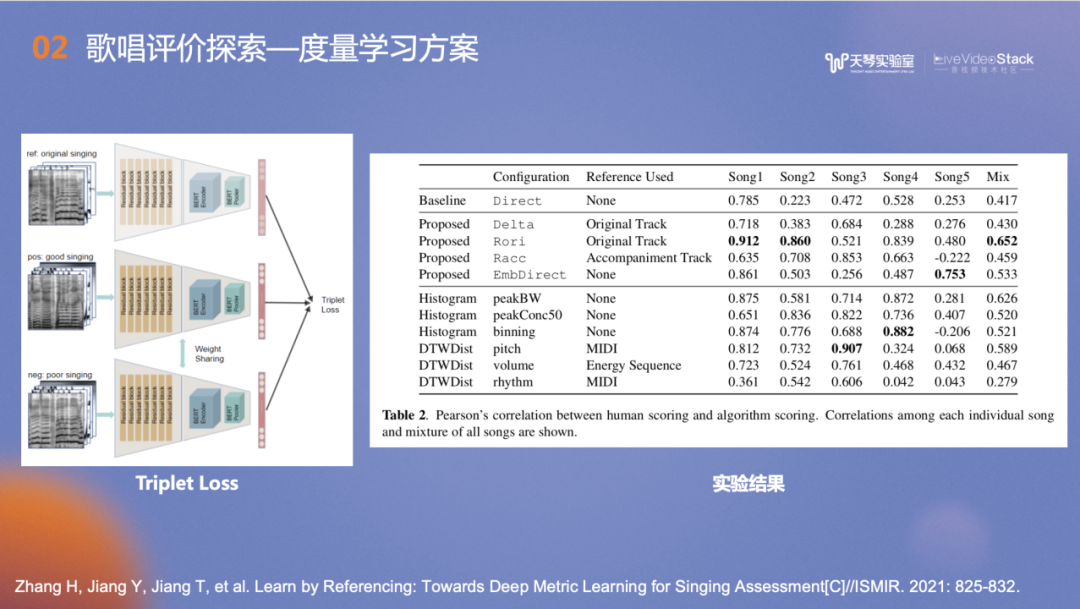
左图中是基于度量学习思想设计的模型结构,通过对比实验可以发现提出的度量学习方案在测试集的五首歌曲上的评价中不是所有的歌曲表现都好,但是泛化性相对最强。在音域跨度较大的戏曲或节奏非常快的歌曲上,无参考评价的方案比传统用基频和模板进行匹配的方法表现更好。

图中是学习得到的音频音色向量在二维空间中的分布,深色的点代表好听的歌声,浅色的点代表较差的歌声。可以看到深色的点呈聚集状,而浅色的点则较为分散,这和我们训练度量学习的Loss相关的。图案的分布不禁让我们想到托尔斯泰的一句话,“All happy families are happy alike; each unhappy familiy is unhappy in its own way”。在声音是否好听方面也类似:好听的声音是有共性的,但不好的声音各有各的缺点。
上文提到很多方法是以有参考为主的评价,但在实践过程中我们也遇到了一些问题——高阶用户之间的区分度不够。例如两个歌唱基础维度都比较不错的演唱,从模版匹配角度来说分数很接近,但声乐老师能明显判断哪位歌手是经过训练过,对气息的把控能力更强。

于是我们进一步优化模型,升级了打分技术。希望通过无参考评价的方法可以脱离模版的约束,捕捉高唱功的表现,并对其进行打分。
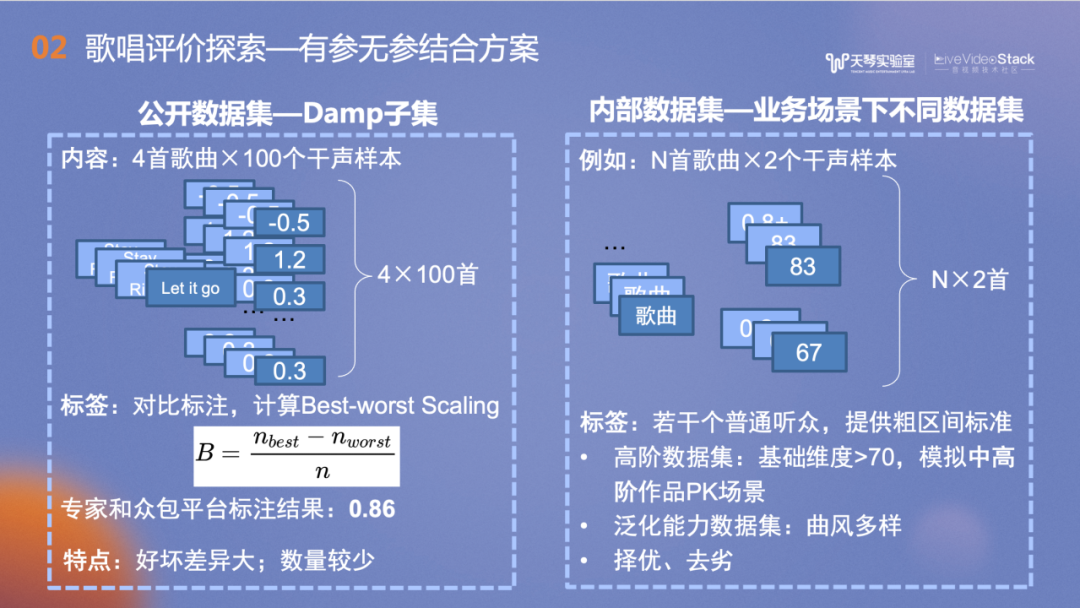
介绍实验之前先给大家介绍一下数据集。歌唱评价是比较小众的领域,其数据集也是业内非常稀缺的资源,公开数据集少之又少。我们找到了一个公开数据集——Damp子集,包含四首歌的100个干声样本。标注来源于新加坡国立大学的一项工作,他们将歌声放到众包平台上进行标注,让众包的标注人员两两比较测听选出好听的歌曲,计算出每首歌的Best-worst Scaling。最后选出一首集外的歌曲,和专家的评分做相关系数的计算,观察是否一致(越接近1越一致),结果得到相关系数是0.86。
右侧是我们自己搭建的内部数据集,每首歌包含了两个不同演唱者的作品,每个作品的音准分都在70分以上,希望在构建的是“高阶”演唱用户的数据集。每个标注人员都有一定的音乐学习背景,在标注时提供了为标注人员不同粗区间的标准,每首歌的精细化评分由标注人员来把握。
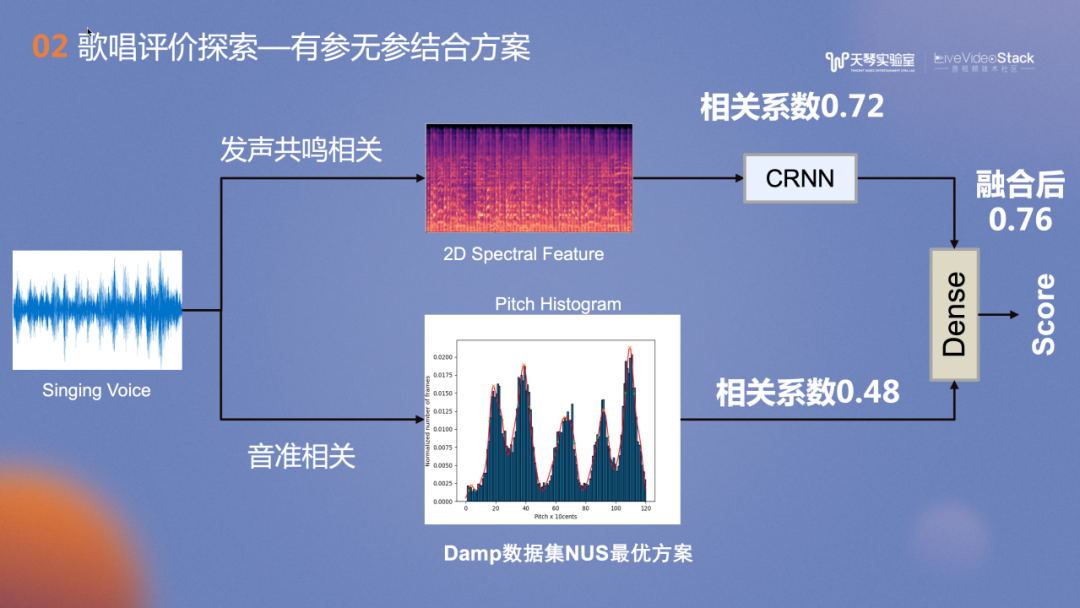
图中是NUS在Damp数据集上的最优实现,我们将其作为Baseline。方案包括两个分支:上分的发声共鸣相关分支和下方的音准相关分支。后者采用无参考的Pitch Histogram方法,支撑思想是好的歌手在达到某一个标准音时会非常果断,反复地击中歌曲的弦内音,图示的歌曲的五个峰值分别对应歌曲的弦内音,峰值越尖锐,歌手的演唱水平越高,跑掉的概率越低。它在Damp数据集的相关系数达到了0.48。我们对此方案进行实践后发现它的泛化性较弱。对于滑音较多或节奏较快的歌曲,并不能满足我们的业务需求。
发声共鸣相关的分支支撑思想是,即使不了解歌手唱的歌曲,但演唱一开始,就能凭借经验判断其唱功如何。Baseline使用神经网络在Damp较小的子集中进行训练,相关系数达到0.72。上下两个分支进行融合后,相关系数达到0.76。
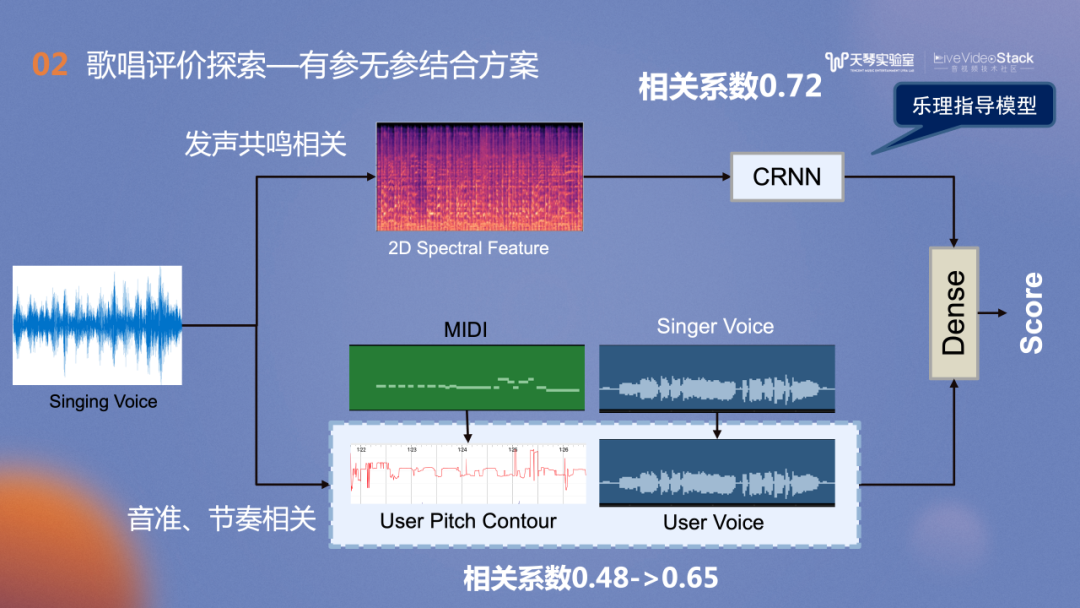
对音准节奏相关分支的改造,我们借助了TME非常丰富强大的曲库资源,优化为有参考的评价方案,在此分支的相关系数从Baseline的0.48提升到了0.65。对发声共鸣分支的改造思路是:高阶演唱中,我们关注的是是否有真假音转换,在不同发声之间的切换或声音的控制。此时,高阶用户的评价更和音色控制相关。因此我们借鉴了歌声音色的相关模型训练思路。
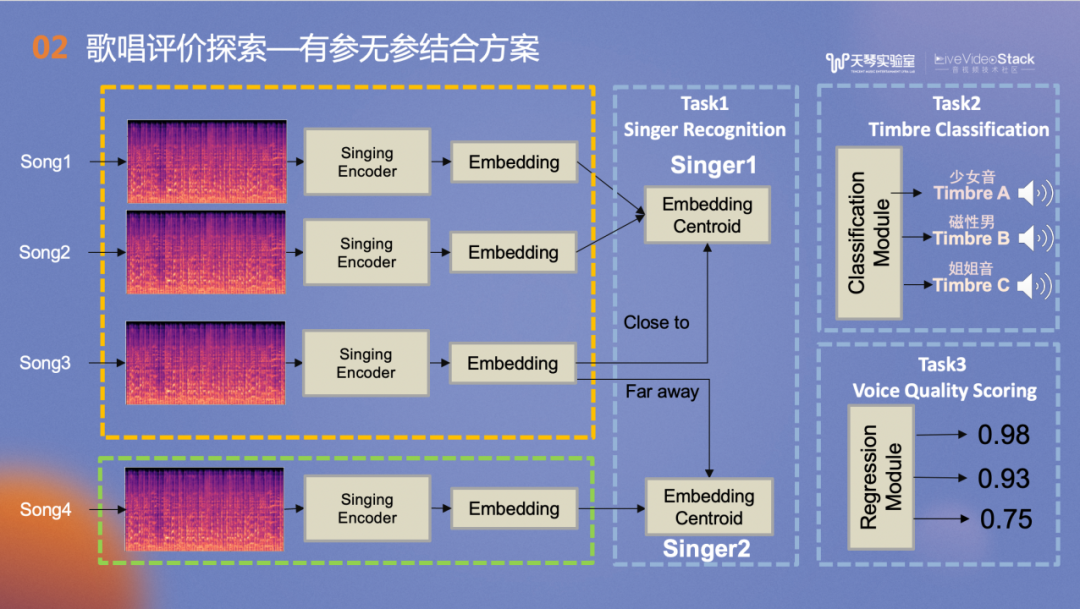
首先建立Pre-train的模型,以歌手识别任务作为Task1,即预训练任务。理想状态是同一个人唱的歌曲的音色Embedding在空间中尽量聚集,不同人唱的尽量分散。同时我们还进行了Task2和Task3的联合训练,前者主要是音色分类任务,隐空间中的音色向量能够表征不同的音色,如少女音、磁性男等。后者主要是通过音色向量反映发声的控制力,例如难听的大白嗓或控制较好的气声。经过训练最终得到了绿框中的Singing Encoder,表征了和嗓音音色与发声属性。
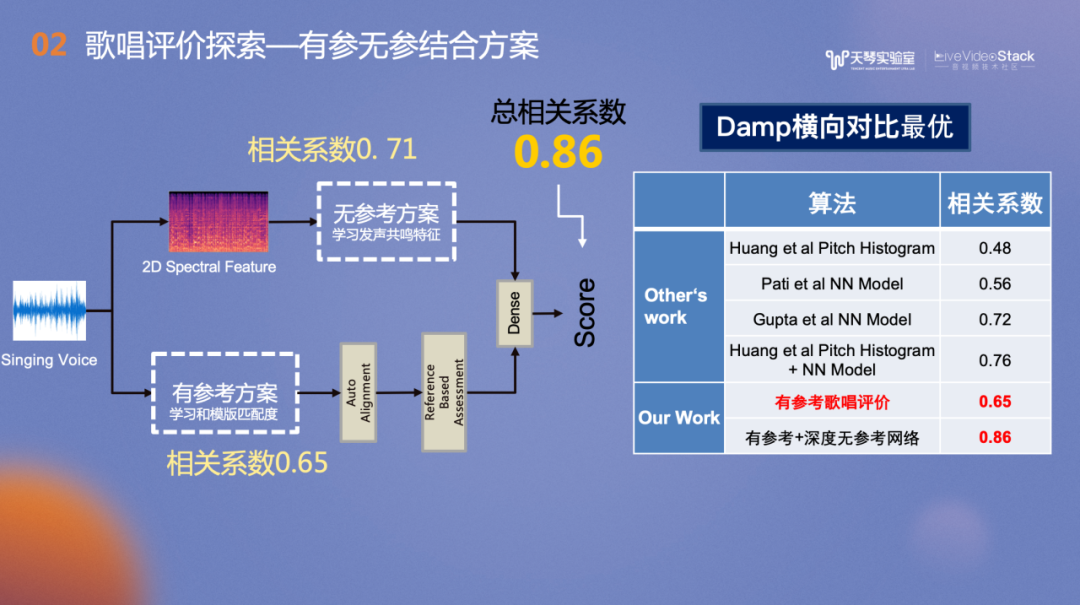
在Damp数据集测评的指标来看,音准节奏相关的有参考方案最终的相关系数是0.65,上面的无参考和发声共鸣相关的分支相关系数达到0.71,经过融合后,总相关系数是0.86。无参考歌唱评价的模型规模较大,我们使用全民K歌内部数据集进行训练,在Damp的测试集上进行了测试。
右侧是Damp数据集和以往的学术界工作的对比,有参考歌唱评价达到了0.65的相关系数,结合有参考和深度无参考的网络,相关系数达到0.86,优于于Baseline在Damp数据集上的0.76相关系数。

上文提到,数据集是比较稀缺的资源,多数学术界的研究都囿于数据集,于是我们发布了歌唱评价数据集,它是国内首个真实K歌场景录制的歌唱评价开源数据集,部分样本包含外放原唱的回采或背景噪声。在收集过程中,我们花费大量时间精力用于用户隐私的保护,每条样本都是经用户同意《知情同意声明》和《个人信息使用声明》,并去除用户个人信息进行脱敏,最终获得了这样宝贵的资源。

目前我们收集了10首歌,每首歌有100个干声,并附带其MIDI和歌词句级别的时间戳,希望为学术界或工业界提供帮助。右下角是我们提供的粗略标注,包括性别、听感年龄、音质、噪声级别及最终歌唱评分。后续我们计划和高校合作进行精细化的歌唱标签标注,也就是审美相关的精细标注。
-03-
歌唱实践评价
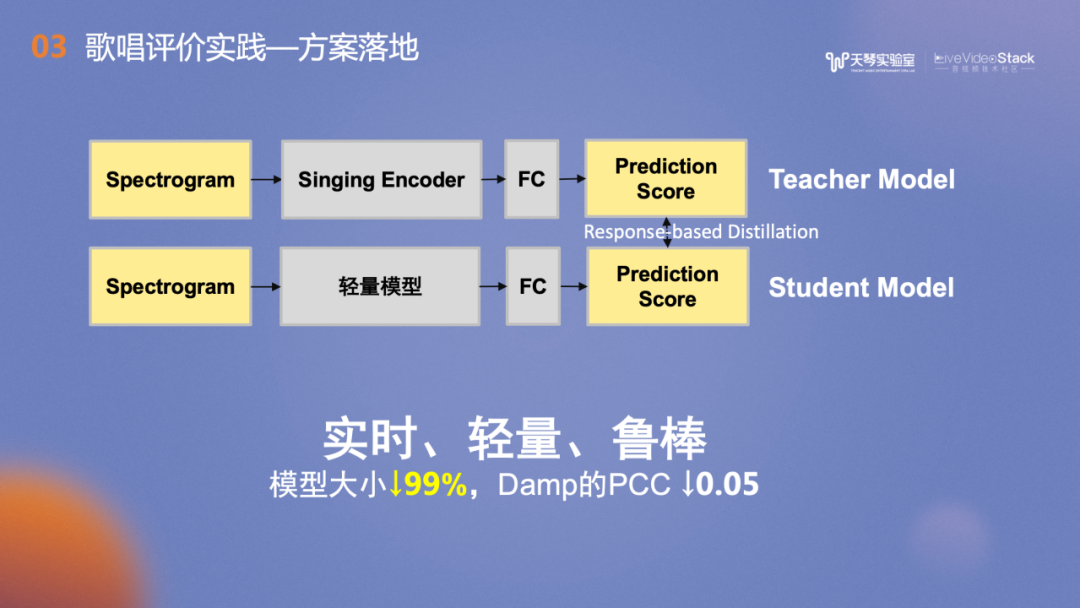
上文提到了多任务学习、预训练模型的表现非常好。但模型有40多兆,对移动端场景来说比较大。于是我们进行了模型蒸馏,将模型降至1M以内,在Damp数据集上的相关系数下降了0.05,对于产品侧来说是可以接受的。
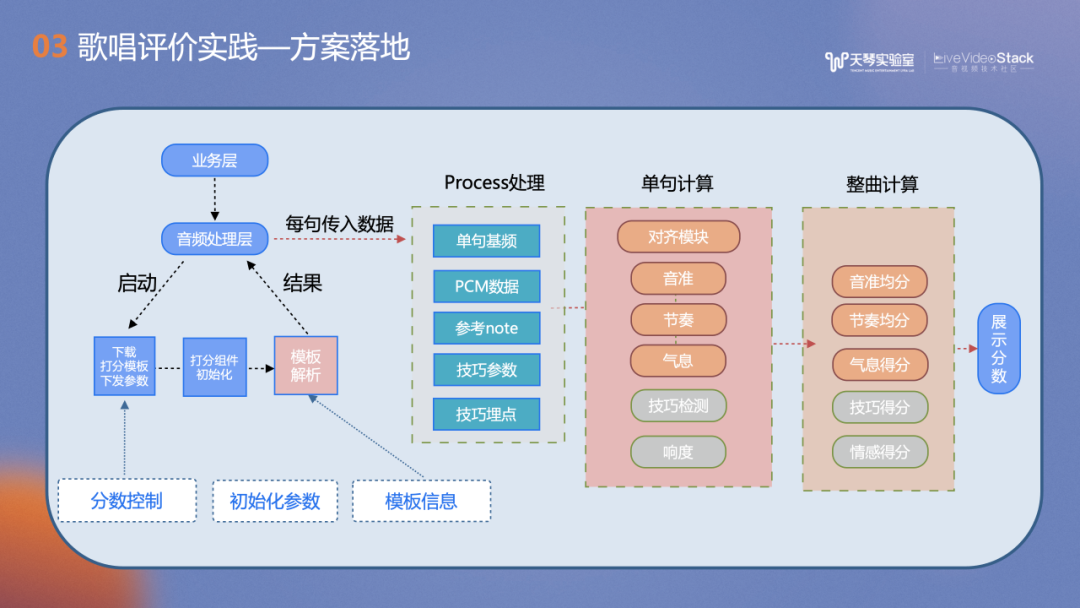
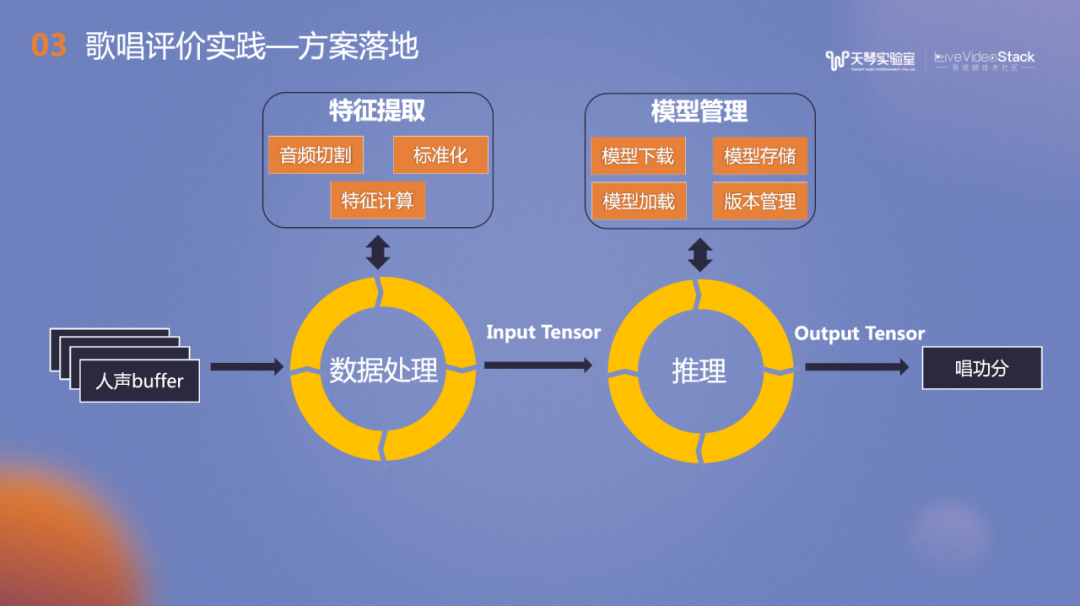
上图介绍了在K歌场景的流程框图,包括对声音进行采集、加载与下载模板,并进行初始化,采集每一句的音频相关特征PCM数据,进行单句得分计算以及整曲计算,最后得出歌唱评价分数。
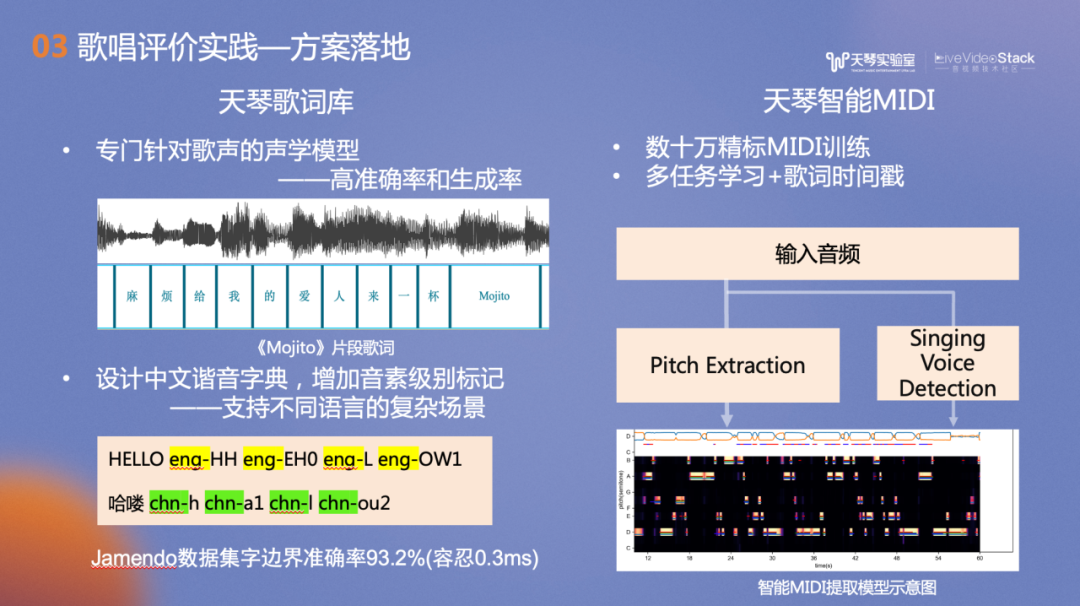
歌唱评价依赖的曲库模版包括歌词和MIDI。其中歌词由天琴歌词库提供,我们针对歌声训练的声学模型具有高准确率和生成率,专门设计了中文谐音字典,增加音素级别标记。本数据集的字边界准确率达到93.2%,容忍度是0.3ms。
右侧是天琴智能MIDI,我们升级了主旋律提取技术,利用曲库内非常庞大的人工精标的MIDI进行训练,结合多任务学习和歌词时间戳信息,得到高精度的天琴智能MIDI。
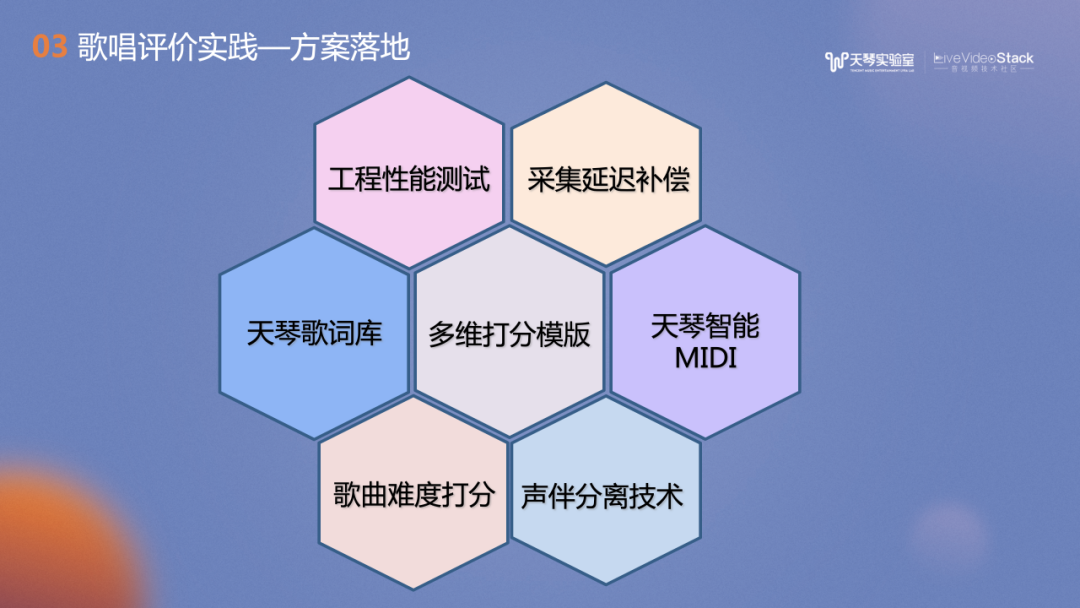
歌唱评价的落地实践中还有许多配套支持的工作,例如模型的管理、存储和加载,工程性能的考虑、设备延迟的补偿、声伴分离技术及歌曲难度打分技术等等。
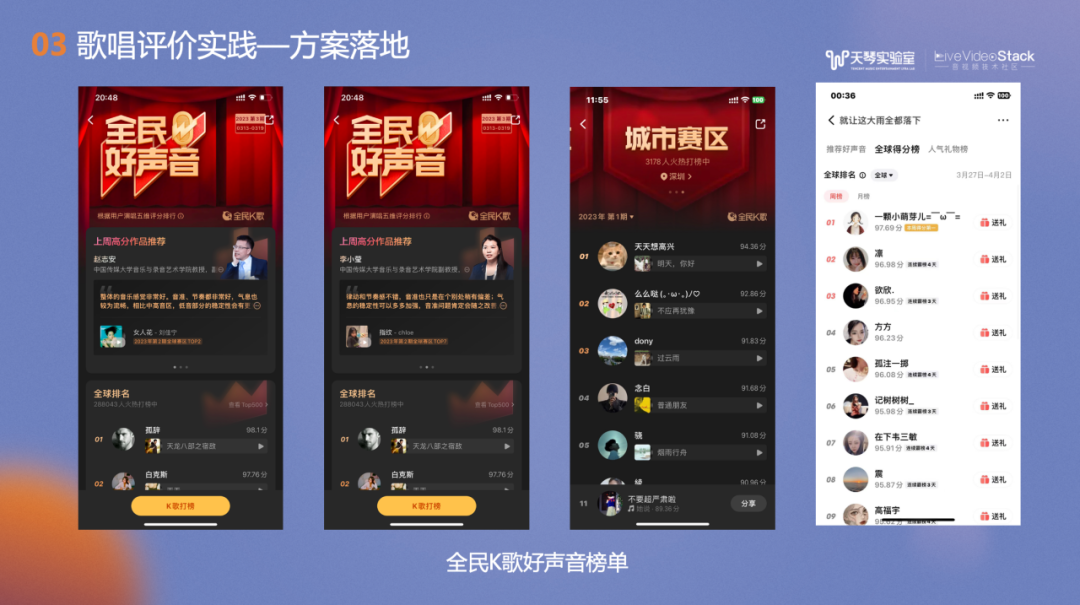
接下来为大家介绍一系列实践的具体应用。我们将最新升级的歌唱评价技术应用在了全民好声音榜单,在用户每次的演唱结束的同时会显示当前用户的地区排名及全球排名。榜单上的优质作品吸引和激励用户更多地演唱发布作品,进行打榜挑战。此应用上线后,用户的录唱行为有明显提升,3日留存和7日留存都有明显的上涨。


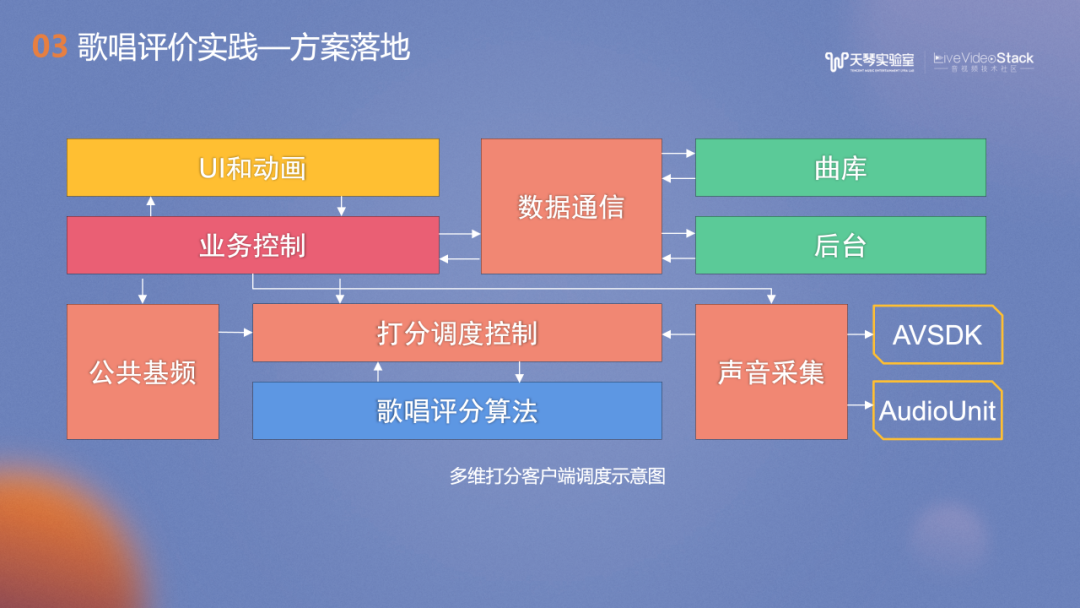
多维度打分功能已经作为了打分SDK对内外提供支持,上图是打分组件在酷狗唱唱、Wesing以及全民K歌的录唱落地应用。

此外,多维打分组件也支持了全民K歌中的“K歌王者”游戏以及右侧QQ音乐直播中,主播之间的歌唱PK。

全民K歌8.0版本之后进行了游戏化升级,画面内容以横屏呈现,增加了K歌游戏的沉浸感。数据分析表明,用户粘度及使用时长都非常可观。

此外,还有一些歌唱的游戏化玩法,比如参考相关文献,将歌声的特征和消耗卡路里映射,实现游戏化的录唱评分。
-04-
智能音频品鉴系统
最后,再介绍下我们的智能音频品鉴系统。我们希望结合音频内容理解能力,对歌唱作品和音乐作品进行全方位的理解。

上文有提到,我们将用户的歌唱表现分为用户维度和歌曲维度。对于用户维度,主要是用户先天演唱条件,我们在各个维度上都进行了实现。例如音域维度包括音域上界和下界,舒适音域和极限音域,在音色维度进行可进行歌唱人鉴定或相似音色匹配,在发声维度进行发声共鸣相关的分析。
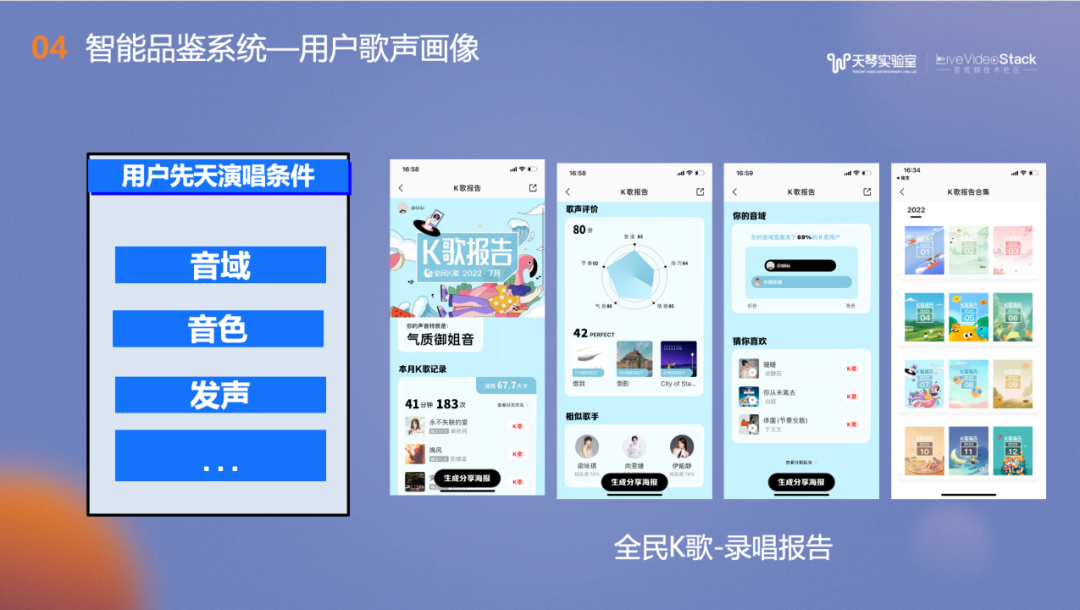
以上功能都已在全民K歌的录唱报告中落地,我们会基于用户这个月内发布的作品进行音频特征的汇总并在月度录唱报告上呈现,比如用户的嗓音标签、音色相似的明星、音域范围和喜爱歌手的对比图等,用户还可以通过反复的练习拓展歌唱评价的五维打分能力图。
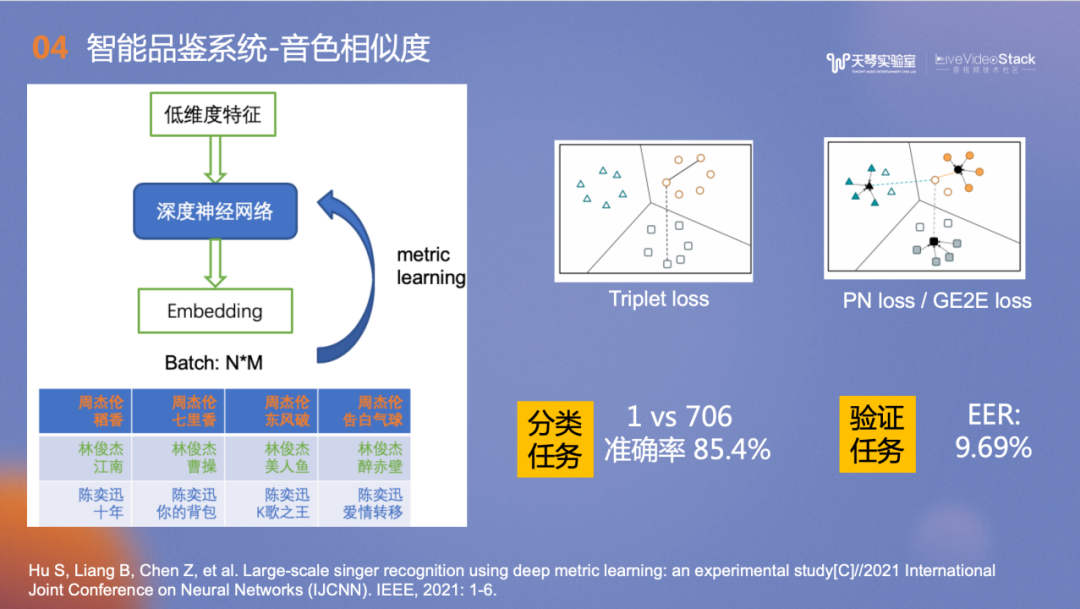
音色相似度计算中运用到的技术是分类任务和验证任务,在1v706的歌手分类任务中,准确率达到85.4%,EER是9.69%。
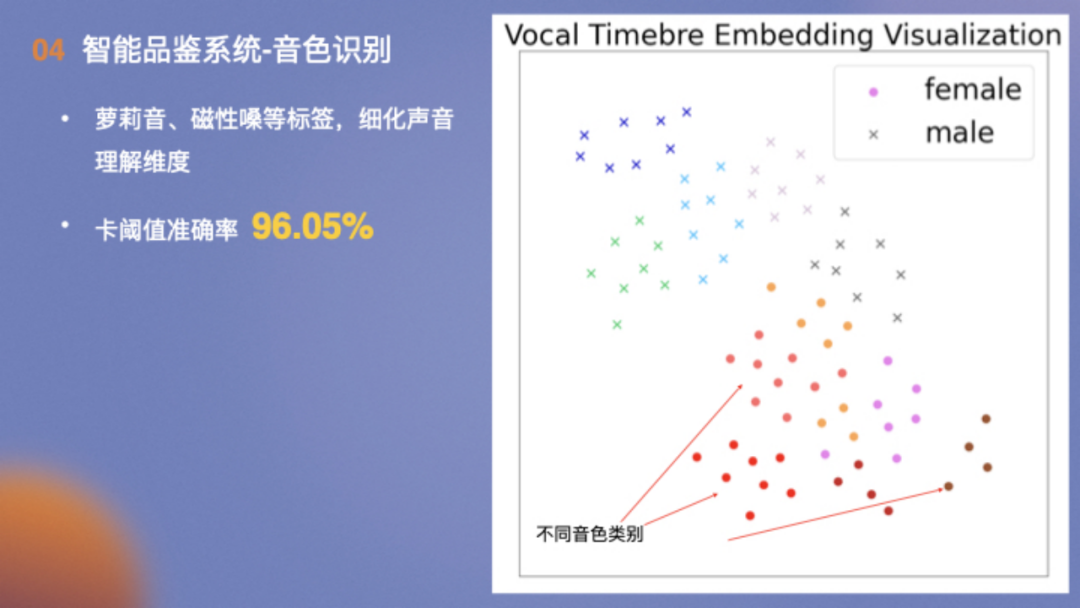
音色识别方面,结合平台的实际情况,对用户演唱的音色进行分类,卡阈值准确率高达96.05%。右侧是各种音色在二维空间的分布,左上角是男性的音色、右下是女性的音色以及在两种音色之间分布着中性的音色。
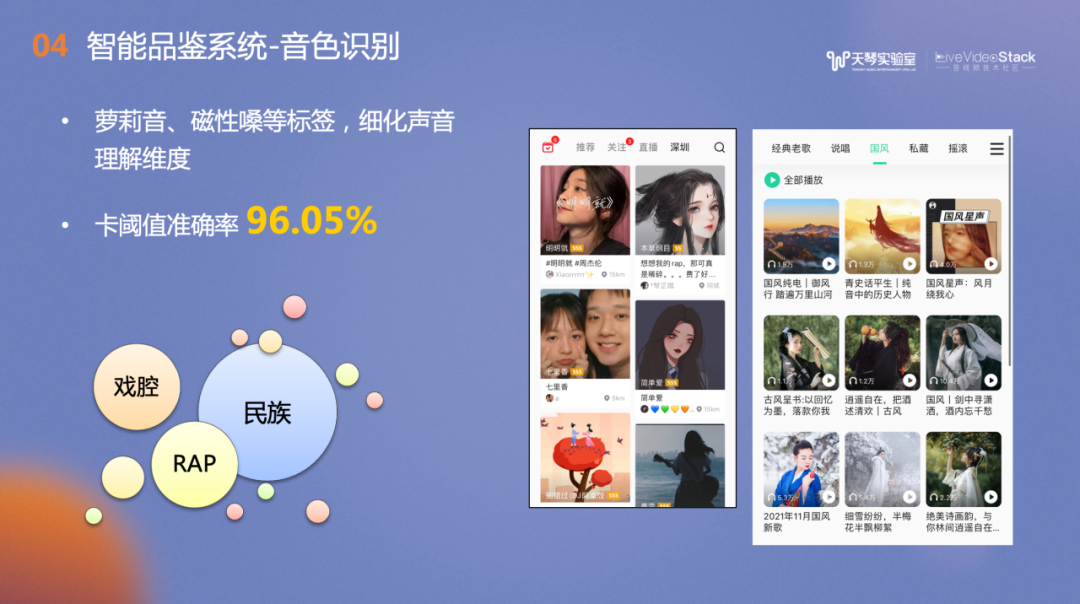
此外,我们还可以对特色唱腔,如戏腔、民族唱法及rap进行识别,通过技术快速发现普通大众中的“民间好声音”。
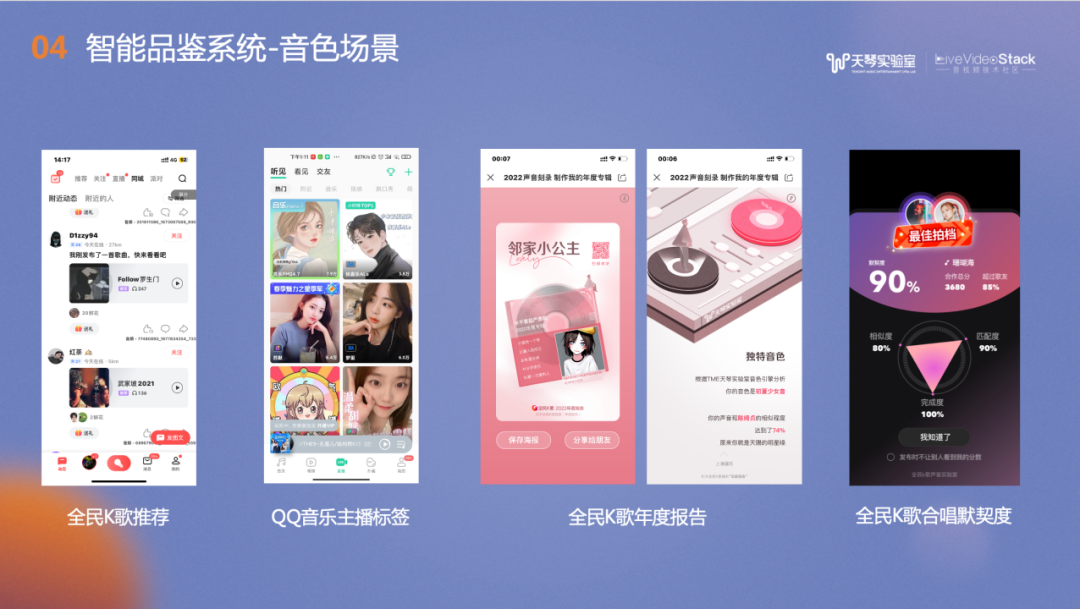
音色落地场景很多,例如全民K歌推荐;QQ音乐主播标签;在全民K歌年度报告中,我们还结合的天琴实验室的图片生成技术,根据用户的声线生成音色画像;此外我们还可以根据合唱双方的音色匹配度进行音色默契度的评分。

另一个音色标签使用场景是腾讯音乐的启明星平台,目前已有30w+的音乐人入驻,我们会对其中的唱将进行音色打标,用户可以在启明星平台进行交易,如上传demo,选择适配音色后演唱歌曲。我们根据上传的作品为每一位入驻音乐人打上音色标签,例如听感年龄、音色颗粒度及唱功分数,以便客户挑选心仪的演唱歌手。
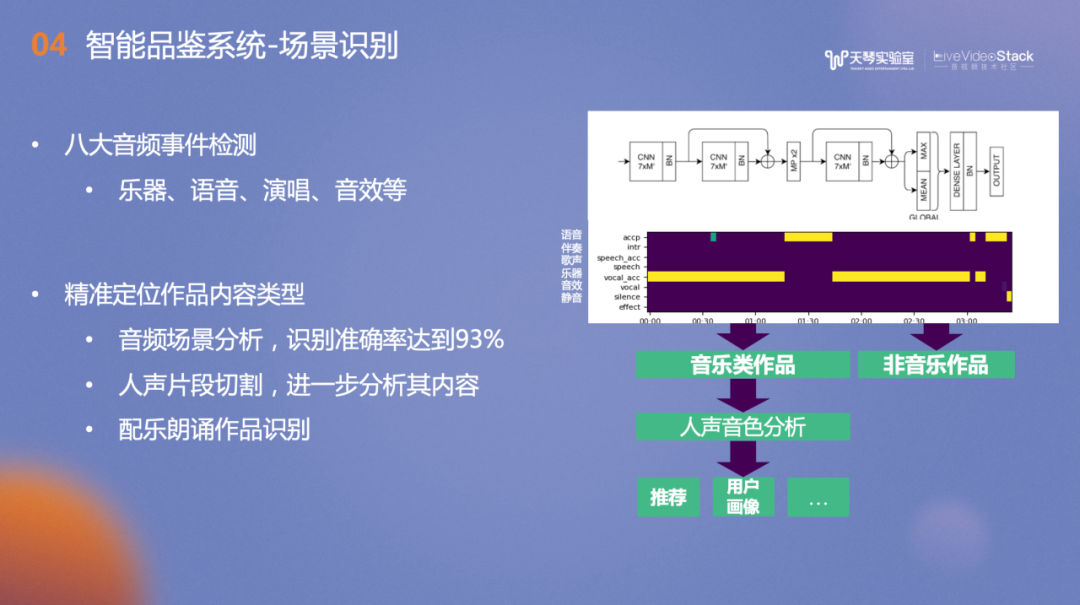
场景识别任务服务于全民K歌中短视频内容识别,通过音频场景识别、声音事件检测、朗诵识别、乐器演奏识别等作品内容进行理解,从而更有效地聚类分发。
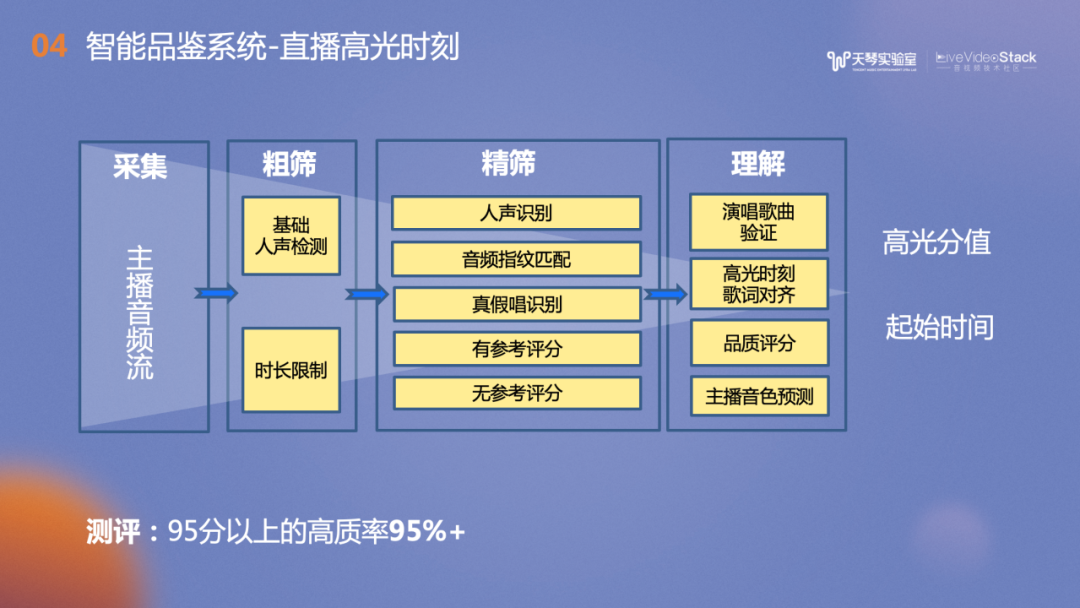
在直播方面,我们提供了直播高光时刻的识别功能,简单来说就是定位并裁剪出歌唱主播的演唱精彩部分。具体流程如下:对采集到的主播音频流进行粗筛,包括基础人声检测和时长限制,再进行精筛包括人声识别(一小时的直播中可能只有几分钟的有效歌唱片段)、音频指纹匹配(判断唱的哪首歌曲)、真假唱识别(判断是真唱还是播放的原唱),再进行唱功赏析。理解方面会校准歌词时间戳,为主播直播片段的音频品质进行评分,过滤掉大混响,或者背景噪声太大等影响用户听感的演唱作品。此外还输出主播音色标签、高光分值及裁剪出的高光片段,评测结果表明,高质率达到95%+。
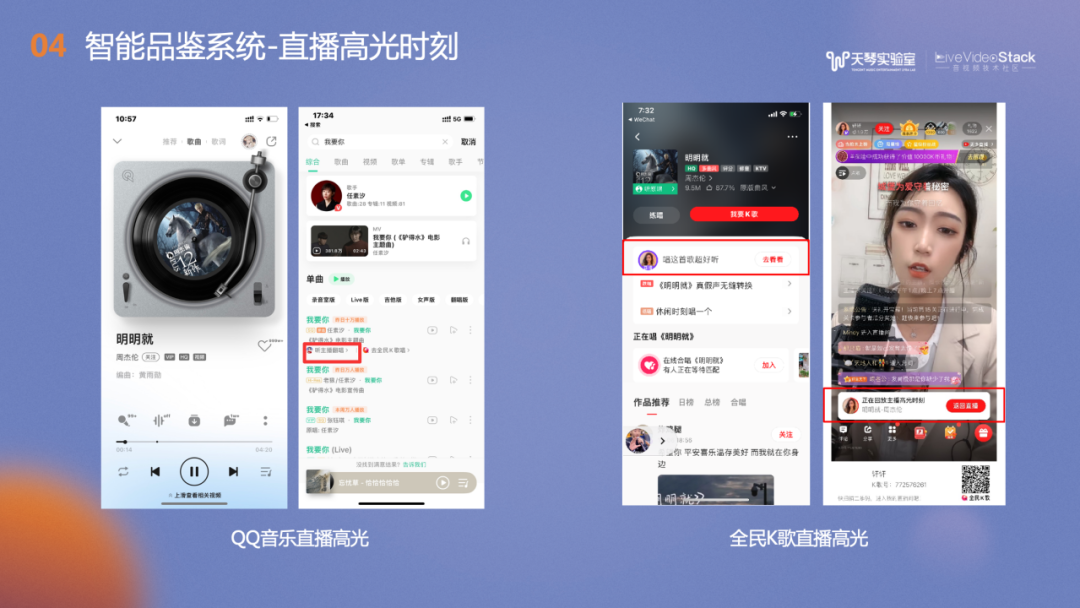
图片展示了直播高光时刻在移动端的显式入口,例如QQ音乐的播放界面、搜索界面。全民K歌的伴奏详情页以及推荐页。
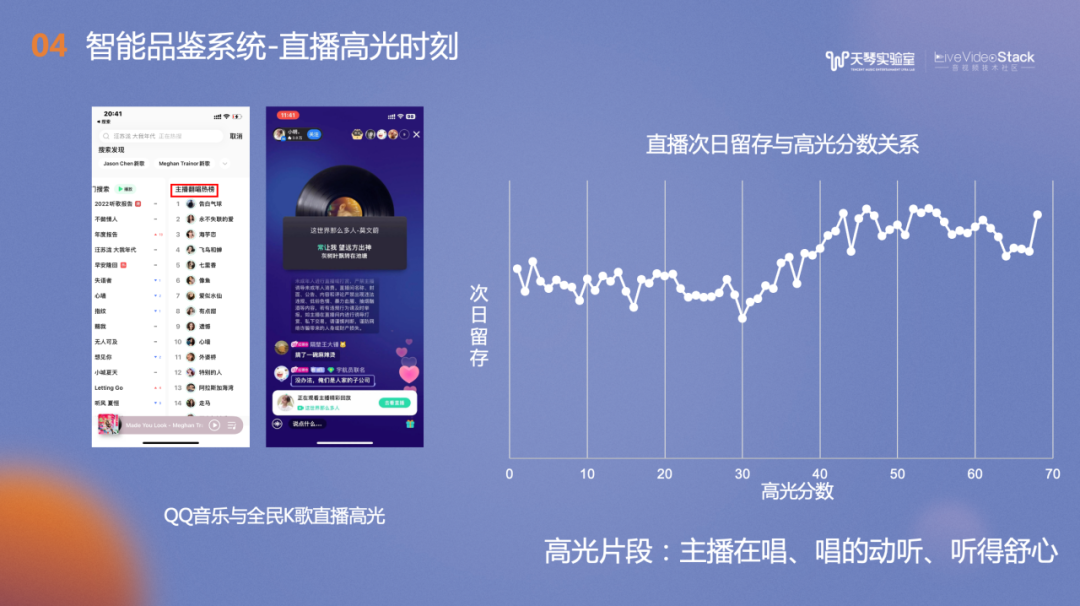
QQ音乐也根据品鉴得分建立了主播翻唱的热榜,异步展示了主播的高光片段作品,榜单按照综合得分排序。我们通过实验,计算了直播次日留存与高光分数的关系,可以看到高光分数在30分之后,次日留存率会随之显著提高。此外我们也结合视频分析的技术,为音视频直播的多模态智能理解做出贡献。
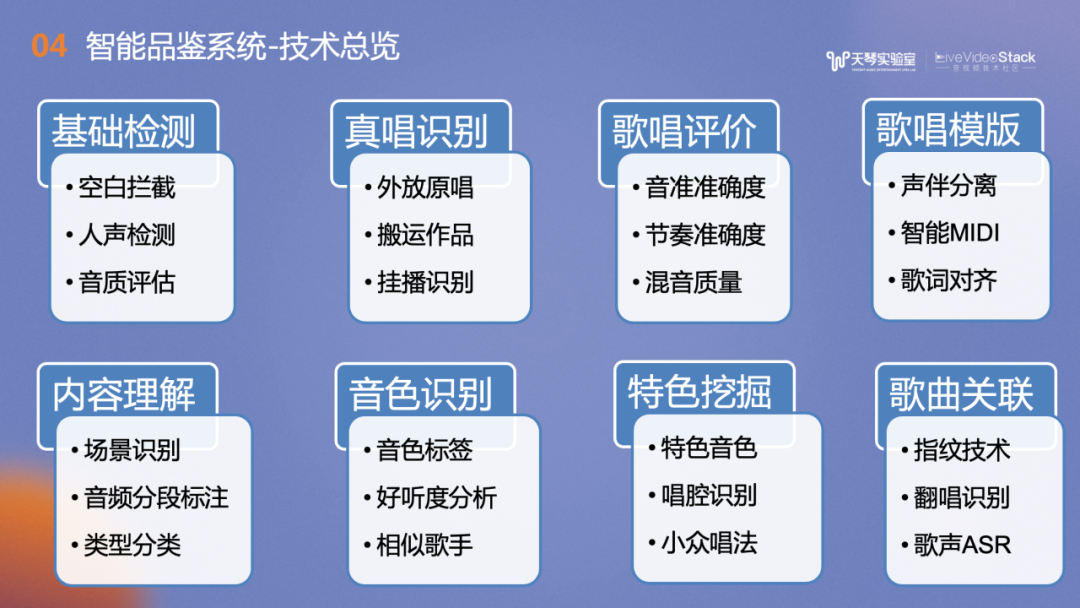
最后再罗列下我们品鉴的能力。希望用我们日益打磨的音频内容理解能力的技术,能促进整个音频音乐领域的理解智能化,贡献到更多的产品与研究中。欢迎大家和我们多多交流与合作。以上是本次的分享,谢谢!

▲扫描图中二维码或点击“阅读原文” ▲
直通LiveVideoStackCon 2023上海站九折优惠