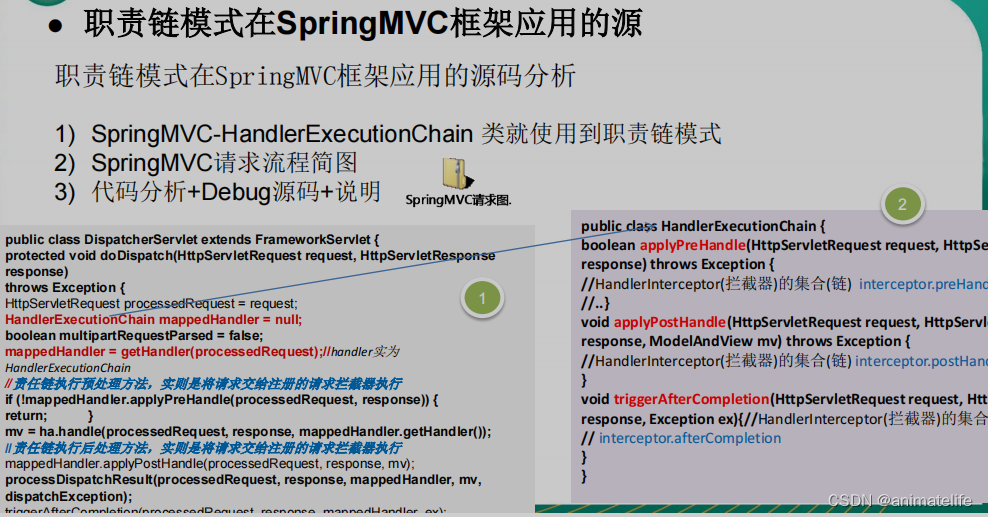
以下所有内容来自《自然语言处理 基于预训练模型的方法》
1. 文本的表示
利用计算机对自然语言进行处理,首先要解决语言在计算机内部的存储和计算问题。使用字符串表示计算文本的语义信息的时候,往往使用基于规则的方法。如:判断一个句子编译还是褒义,规则可能为:出现“喜欢”等就是褒义,出现“讨厌”等就是贬义。但是这种方法存在很多问题。基于机器学习的自然语言处理技术应运而生,本质就是将文本表示为向量,每一维代表一个特征。文本向量还可以计算两个文本之间的相似度等。
1.1 词的独热表示
词的独热表示就是使用一个词表大小的向量表示一个词,然后将词表中的第i个词wi表示为向量:
在该向量中,词表中第i个词在第i维上被设置为1,其余维均为0。这种表示被称为词的独热表示或独热编码。
当应用于基于机器学习的方法时,独热模型会导致数据稀疏问题。
为了缓解数据稀疏问题,传统的做法是除了词自身,再提取更多和词相关的泛化特征,如词性特征、词义特征和词聚类特征等。以语义特征为例,通过引入WordNet[1]等语义词典,可以获知“漂亮”和“美丽”是同义词,然后引入它们的共同语义信息作为新的额外特征,从而缓解同义词的独热表示不同的问题。
1.2 词的分布式表示
- 分布式语义假设
分布式语义假设是指词的含义可由其上下文的分布进行表示。
基于该思想,可以利用大规模的未标注文本数据,根据每个词的上下文分布对词进行表示。当然,分布式语义假设仅仅提供了一种语义建模的思想。具体到表示形式和上下文的选择,以及如何利用上下文的分布特征,都是需要解决的问题。
举个例子演示如何构建词的分布式表示:
假设语料库中有以下三句话:

假设以词所在的句子中的其他词语作为上下文,那么可以创建一个共现频次表:
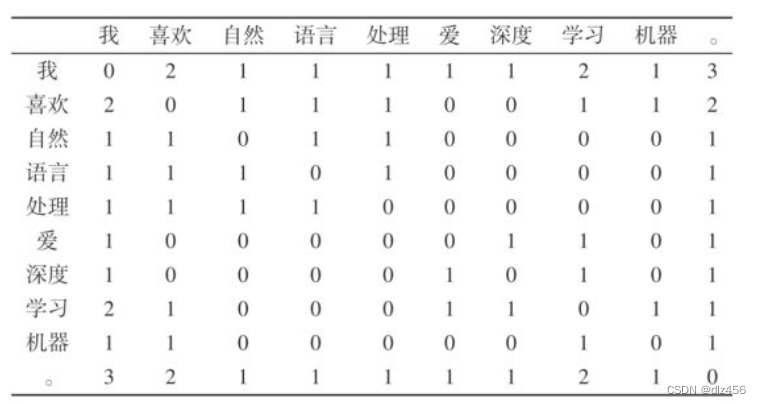
表中的每一行代表一个词的向量。通过计算两个向量之间的余弦函数,就可以计算两个词的相似度。如“喜欢”和“爱”,由于有共同的上下文“我”和“学习”,使得它们之间具有了一定的相似性,而不是如独热表示一样,没有任何关系。
直接使用与上下文的共现频次作为词的向量表示,至少存在以下三个问题:
1)高频词误导计算结果。如上例中,“我”“。”与其他词的共现频次很高,导致实际上可能没有关系的两个词由于都和这些词共现过,从而产生了较高的相似度。
2)共现频次无法反映词之间的高阶关系。例如,假设词“A”与“B”共现过,“B”与“C”共现过,“C”与“D”共现过,通过共现频次,只能获知“A”与“C”都与“B”共现过,它们之间存在一定的关系,而“A”与“D”这种高阶的关系则无法知晓。
3)仍然存在稀疏性的问题。即向量中仍有大量的值为0。
接下来介绍如何通过点互信息和奇异值分解两种技术来解决这些问题。 - 点互信息
首先看如何解决高频词误导计算结果的问题。其实就是通过权重来解决啦!最直接的想法是:如果一个词与很多词共现,则降低其权重;反之,如果一个词只与个别词共现,则提高其权重。信息论中的点互信息(Pointwise Mutual Information,PMI)恰好能够做到这一点。
这里不详细介绍了如何计算权重和概率什么的了,重点不只是这里。而且下面先要介绍的词嵌入。 - 奇异值分解
下面看如何解决共现频次无法反映词之间高阶关系的问题。相关的技术有很多,其中奇异值分解(Singular Value Decomposition,SVD)是一种常见的做法。 - 虽然在基于传统机器学习的方法中,词的分布式表示取得了不错的效果,但是其仍然存在一些问题。首先,当共现矩阵规模较大时,奇异值分解的运行速度非常慢;其次,如果想在原来语料库的基础上增加更多的数据,则需要重新运行奇异值分解算法,代价非常高;另外,分布式表示只能用于表示比较短的单元,如词或短语等,如果待表示的单元比较长,如段落、句子等,由于与其共现的上下文会非常少,则无法获得有效的分布式表示;最后,分布式表示一旦训练完成,则无法修改,也就是说,无法根据具体的任务调整其表示方式。为了解决这些问题,可引入一种新的词表示方式——词嵌入表示。
1.3 词嵌入表示
与词的分布式表示类似,词嵌入表示(Word Embedding)也使用一个连续、低维、稠密的向量来表示词,经常直接简称为词向量,但与分布式表示不同之处在于其赋值方式。
在词的分布式表示中,向量值是通过对语料库进行统计得到的,然后再经过点互信息、奇异值分解等变换,一旦确定则无法修改。
而词向量中的向量值,是随着目标任务的优化过程自动调整的。也就是说,可以将词向量中的向量值看作模型的参数。
1.4 文本的词袋表示
上面介绍了几种常见的词表示方法,那么如何通过词的表示构成更长文本的表示呢?在此介绍一种最简单的文本表示方法——词袋(Bag-Of-Words,BOW)表示。所谓词袋表示,就是假设文本中的词语是没有顺序的集合,将文本中的全部词所对应的向量表示(既可以是独热表示,也可以是分布式表示或词向量)相加,即构成了文本的向量表示。如在使用独热表示时,文本向量表示的每一维恰好是相应的词在文本中出现的次数。
虽然这种文本表示的方法非常简单、直观,但是其缺点也非常明显:首先是没有考虑词的顺序信息,导致“张三打李四”和“李四打张三”,虽然含义不同,但是由于它们包含的词相同,即使词序不同,词袋表示的结果也是一样的。其次是无法融入上下文信息。比如要表示“不喜欢”,只能将两个词的向量相加,无法进行更细致的语义操作。但是随着词表的增大,会引入更严重的数据稀疏问题。深度学习技术的引入为解决这些问题提供了更好的方案。
2. 自然语言处理任务
2.1 语言模型
语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个非常基础和重要的自然语言处理任务。利用语言模型,可以计算一个词序列或一句话的概率,也可以在给定上文的条件下对接下来可能出现的词进行概率分布的估计。
2.1.1 N元语言模型
语言模型的基本任务是在给定词序列w1w2··· wt−1的条件下,对下一时刻t可能出现的词wt的条件概率P(wt|w1w2··· wt−1)进行估计。一般地,把w1w2··· wt−1称为wt的历史。
比方说:对于历史“我喜欢”,希望得到下一个词为“读书”的概率,即:P(读书|我喜欢)。
在给定一个语料库时,该条件概率可以理解为当语料中出现“我喜欢”时,有多少次下一个词为“读书”,然后通过最大似然估计进行计算:
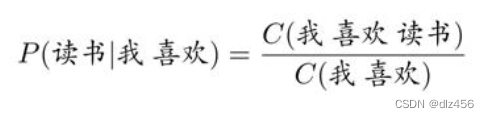
式中,C (·)表示相应词序列在语料库中出现的次数(也称为频次)。
通过以上的条件概率,可以进一步计算一个句子出现的概率,即相应单词序列的联合概率P (w1w2··· wl),式中l为序列的长度。可以利用链式法则对该式进行分解,从而将其转化为条件概率的计算问题,即:
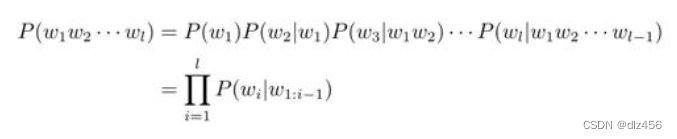
然而,随着句子长度的增加,w1:i−1出现的次数会越来越少,甚至从未出现过,那么P (wi|w1:i−1)则很可能为0,此时对于概率估计就没有意义了。为了解决该问题,可以假设“下一个词出现的概率只依赖于它前面n−1个词”,即: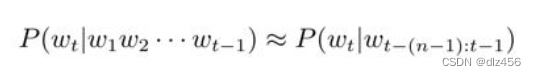
该假设被称为马尔可夫假设。
满足这种假设的模型,被称为N元语法或N元文法(N-gram)模型。
特别地,当n=1时,下一个词的出现独立于其历史,相应的一元语法通常记作unigram。当n=2时,下一个词只依赖于前1个词,对应的二元语法记作bigram。二元语法模型也被称为一阶马尔可夫链(Markov Chain)。类似的,三元语法假设(n=3)也被称为二阶马尔可夫假设,相应的三元语法记作trigram。n的取值越大,考虑的历史越完整。在unigram模型中,由于词与词之间相互独立,因此它是与语序无关的。
2.1.2 平滑
虽然马尔可夫假设(下一个词出现的概率只依赖于它前面n−1个词)降低了句子概率为0的可能性,但是当n比较大或者测试句子中含有未登录词【注意:未登录词问题,也就是说有一些词并没有收录在词典中,如新词、命名实体、领域相关词和拼写错误词等】时,仍然会出现“零概率”问题。由于数据的稀疏性,训练数据很难覆盖测试数据中所有可能出现的N-gram,但这并不意味着这些N-gram出现的概率为0。为了避免该问题,需要使用平滑(Smoothing)技术调整概率估计的结果。
2.2.3 语言模型性能评价
目前最为常用的是基于困惑度(Perplexity,PPL)的“内部评价”方式。
为了进行内部评价,首先将数据划分为不相交的两个集合,分别称为训练集和测试集,其中用于估计语言模型的参数。由该模型计算出的测试集的概率则反映了模型在测试集上的泛化能力。
2.2 自然语言处理基础任务
2.2.1 中文分词
词(Word)是最小的能独立使用的音义结合体,是能够独立运用并能够表达语义或语用内容的最基本单元。英语当中,词之间通常用分隔符区分。汉语中,没有明显的词之间的分隔符。因此,为了进行后续的自然语言处理,通常需要首先对不含分隔符的语言进行分词(Word Segmentation)操作。
中文分词就是将一串连续的字符构成的句子分割成词语序列,如“我喜欢读书”,分词后的结果为“我 喜欢 读书”。
最简单的分词算法叫作正向最大匹配(Forward Maximum Matching,FMM)分词算法,即从前向后扫描句子中的字符串,尽量找到词典中较长的单词作为分词的结果。但是这个算法有一个很明显的缺点:倾向于切分出较长的词,这容易导致错误的切分结果。如“研究生命的起源”,由于“研究生”是词典中的词,所以使用正向最大匹配分词算法的分词结果为“研究生命的起源”,显然分词结果不正确。除了存在切分歧义,对中文词的定义也不明确,如“哈尔滨市”可以是一个词,也可以认为“哈尔滨”是一个词,“市”是一个词。
还有未登录词问题,也就是说有一些词并没有收录在词典中,如新词、命名实体、领域相关词和拼写错误词等。由于语言的动态性,新词语的出现可谓是层出不穷,所以无法将全部的词都及时地收录到词典中,因此,一个好的分词系统必须能够较好地处理未登录词问题。
2.2.2 子词切分
对于英语而言,词语之间通常已有分隔符(空格等)进行切分,无须再进行额外的分词处理。然而,由于这些语言往往具有复杂的词形变化,如“computer”“computers”“computing”,如果仅以天然的分隔符进行切分,不但会造成一定的数据稀疏问题,还会导致由于词表过大而降低处理速度。
传统的处理方法是根据语言学规则,引入词形还原(Lemmatization)或者词干提取(Stemming)等任务,提取出单词的词根,从而在一定程度上克服数据稀疏问题。
词形还原指的是将变形的词语转换为原形,如将“computing”还原为“compute”;而词干提取则是将前缀、后缀等去掉,保留词干(Stem),如“computing”的词干为“comput”,可见,词干提取的结果可能不是一个完整的单词。
词形还原或词干提取需要人工撰写大量的规则,这种基于规则的方法不容易扩展。因此,基于统计的无监督子词(Subword)切分任务应运而生,并在现代的预训练模型中使用。
所谓子词切分,就是将一个单词切分为若干连续的片段。常用的是字节对编码BPE算法。
2.2.3 词性标注
词性是词语在句子中扮演的语法角色,也被称为词类。例如,表示抽象或具体事物名字(如“计算机”)的词被归为名词,而表示动作(如“打”)、状态(如“存在”)的词被归为动词。词性可为句法分析、语义理解等提供帮助。
词性标注(POS Tagging)任务是指给定一个句子,输出句子中每个词相应的词性。
例如,当输入句子为:

则词性标注的输出为:

其中,斜杠后面的PN、VV、NN和PU分别代表代词、动词、名词和标点符号。
词性标注的主要难点在于歧义性,即一个词在不同的上下文中可能有不同的词性。
2.2.4 句法分析
句法分析(Syntactic Parsing)的主要目标是给定一个句子,分析句子的句法成分信息,例如主谓宾定状补等成分。最终的目标是将词序列表示的句子转换成树状结构,从而有助于更准确地理解句子的含义,并辅助下游自然语言处理任务。
例如,对于以下两个句子:

虽然它们只相差一个“的”字,但是表达的语义是截然不同的。通过对两句话进行句法分析,就可以准确地获知各自的主语,从而推导出不同的语义。
典型的句法结构表示方法包含两种——短语结构句法表示和依存结构句法表示。
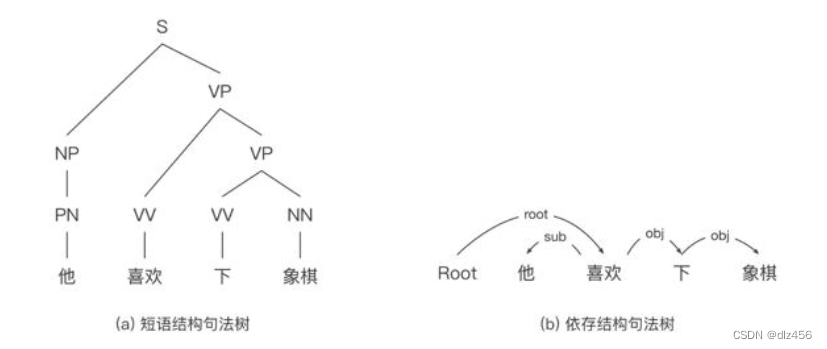
在短语结构句法表示中,S代表起始符号,NP和VP分别代表名词短语和动词短语。在依存结构句法表示中,sub和obj分别表示主语和宾语,root表示虚拟根节点,其指向整个句子的核心谓词。
2.2.5 语义分析
根据待表示语言单元粒度以及语义表示方法的不同,语义分析又可以被分为多种形式。
从词语的粒度考虑,一个词语可能具有多种语义(词义),例如“打”,含义即可能是“攻击”(如“打人”),还可能是“玩”(如“打篮球”),甚至“编织”(如“打毛衣”)等。根据词语出现的不同上下文,确定其具体含义的自然语言处理任务被称为词义消歧。对于每个词可能具有的词义,往往是通过语义词典确定的,如WordNet等。除了以上一词多义情况,还有多词一义的情况,如“马铃薯”和“土豆”具有相同的词义。
由于语言的语义组合性和进化性,无法像词语一样使用词典定义句子、段落或篇章的语义,因此很难用统一的形式对句子等语言单元的语义进行表示。众多的语言学流派提出了各自不同的语义表示形式,如语义角色标注(Semantic Role Labeling,SRL)、语义依存分析(Semantic Dependency Parsing,SDP)等。
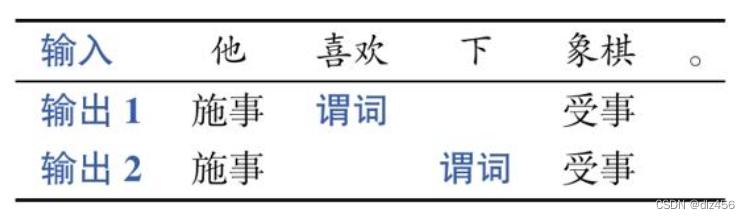
语义角色标注:首先识别句子中可能的谓词(一般为动词),然后为每个谓词确定所携带的语义角色(也称作论元),如表示动作发出者的施事(Agent),表示动作承受者的受事(Patient)等。除了核心语义角色,还有一类辅助描述动作的语言成分,被称为附加语义角色,如动作发生的时间、地点和方式等。表2-2展示了一个语义角色标注的示例,其中有两个谓词——“喜欢”和“下”,并针对每个谓词产生相应的论元输出结果。
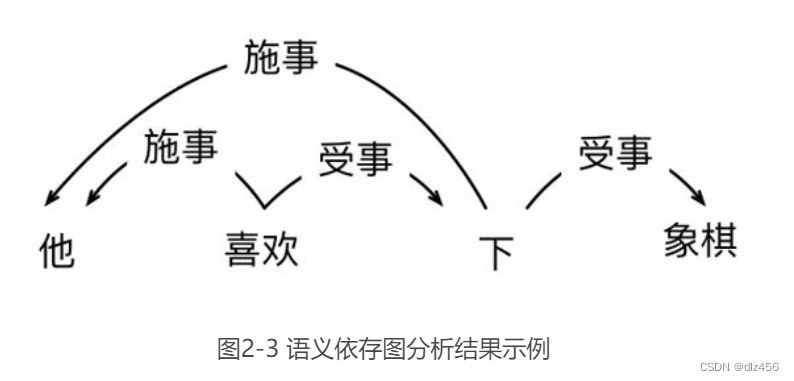
语义依存分析则利用通用图表示更丰富的语义信息。根据图中节点类型的不同,又可分为两种表示——语义依存图(Semantic Dependency Graph)表示和概念语义图(Conceptual Graph)表示。其中,语义依存图中的节点是句子中实际存在的词语,在词与词之间创建语义关系边。而概念语义图首先将句子转化为虚拟的概念节点,然后在概念节点之间创建语义关系边。
2.3 自然语言处理应用任务
2.3.1 信息抽取
信息抽取是从非结构化的文本中自动提取结构化信息的过程,这种结构化的信息方便计算机进行后续的处理。另外,抽取的结果还可以作为新的知识加入知识库中。信息抽取一般包含以下几个子任务:
命名实体识别(Named Entity Recognition,NER)是在文本中抽取每个提及的命名实体并标注其类型,一般包括人名、地名和机构名等,也包括专有名称等,如书名、电影名和药物名等。
关系抽取(Relation Extraction)用于识别和分类文本中提及的实体之间的语义关系,如夫妻、子女、工作单位和地理空间上的位置关系等二元关系。
事件抽取(Event Extraction)的任务是从文本中识别人们感兴趣的事件以及事件所涉及的时间、地点和人物等关键元素。其中,事件往往使用文本中提及的具体触发词(Trigger)定义。
2.3.2 情感分析
自然语言处理中的情感分析主要研究人类通过文字表达的情感,因此也称为文本情感分析。
情感分析可以从任务角度分为两个主要的子任务,即情感分类(识别文本中蕴含的情感类型或者情感强度,其中,文本既可以是句子,也可以是篇章)和情感信息抽取(抽取文本中的情感元素,如评价词语、评价对象和评价搭配等)。
2.3.3 问答系统
问答系统(Question Answering,QA)是指系统接受用户以自然语言形式描述的问题,并从异构数据中通过检索、匹配和推理等技术获得答案的自然语言处理系统。根据数据来源的不同,问答系统可以分为4种主要的类型:1)检索式问答系统,答案来源于固定的文本语料库或互联网,系统通过查找相关文档并抽取答案完成问答;2)知识库问答系统,回答问题所需的知识以数据库等结构化形式存储,问答系统首先将问题解析为结构化的查询语句,通过查询相关知识点,并结合知识推理获取答案;3)常问问题集问答系统,通过对历史积累的常问问题集进行检索,回答用户提出的类似问题;4)阅读理解式问答系统,通过抽取给定文档中的文本片段或生成一段答案来回答用户提出的问题。在实际应用中,可以综合利用以上多种类型的问答系统来更好地回答用户提出的问题。
2.3.4 机器翻译
机器翻译(Machine Translation,MT)是指利用计算机实现从一种自然语言(源语言)到另外一种自然语言(目标语言)的自动翻译。
机器翻译方法一般以句子为基本输入单位,研究从源语言句子到目标语言句子的映射函数。机器翻译自诞生以来,主要围绕理性主义和经验主义两种方法进行研究。所谓“理性主义”,是指基于规则的方法;而“经验主义”是指数据驱动的统计方法,在机器翻译领域表现为基于语料库(翻译实例库)的研究方法。近年来兴起的基于深度学习的机器翻译方法利用深度神经网络学习源语言句子到目标语言句子的隐式翻译规则,即所有的翻译规则都被编码在神经网络的模型参数中。该方法又被称为神经机器翻译(Neural Machine Translation,NMT)。
2.3.5 对话系统
对话系统(Dialogue System)是指以自然语言为载体,用户与计算机通过多轮交互的方式实现特定目标的智能系统。其中,特定目标包括:完成特定任务、获取信息或推荐、获得情感抚慰和社交陪伴等。
对话系统主要分为任务型对话系统(Task-Oriented Dialogue)和开放域对话系统(Open-Domain Dialogue)。前者是任务导向型的对话系统,主要用于垂直领域的自动业务助理等,具有明确的任务目标,如完成机票预订、天气查询等特定的任务。后者是以社交为目标的对话系统,通常以闲聊、情感陪护等为目标,因此也被称为聊天系统或聊天机器人(Chatbot),在领域和话题上具有很强的开放性。
任务型对话系统一般由顺序执行的三个模块构成,即自然语言理解、对话管理和自然语言生成。
3. 基本问题
3.1 文本分类问题
文本分类(Text Classification或Text Categorization)是最简单也是最基础的自然语言处理问题。即针对一段文本输入,输出该文本所属的类别,其中,类别是事先定义好的一个封闭的集合。文本分类具有众多的应用场景,如垃圾邮件过滤(将邮件分为垃圾和非垃圾两类)、新闻分类(将新闻分为政治、经济和体育等类别)等。
在使用机器学习,尤其是深度学习方法解决文本分类问题时,首先,需要使用文本表示技术,将输入的文本转化为特征向量;然后,使用机器学习模型(也叫分类器),将输入的特征向量映射为一个具体的类别。
3.2 结构预测问题
在结构预测问题中,输出类别之间具有较强的相互关联性。例如,在词性标注任务中,一句话中不同词的词性之间往往相互影响,如副词之后往往出现动词或形容词,形容词之后往往跟着名词等。结构预测任务通常是自然语言处理独有的。
下面介绍三种典型的结构预测问题——序列标注、序列分割和图结构生成。
1)序列标注
谓序列标注(Sequence Labeling),指的是为输入文本序列中的每个词标注相应的标签,如词性标注是为每个词标注一个词性标签,包括名词、动词和形容词等。序列标注问题可以简单地看成多个独立的文本分类问题,即针对每个词提取特征,然后进行标签分类,并不考虑输出标签之间的关系。
2)序列分割
很多自然语言处理问题可以被建模为序列分割问题,如分词问题,就是将字符序列切分成若干连续的子序列;命名实体识别问题,也是在文本序列中切分出子序列,并为每个子序列赋予一个实体的类别,如人名、地名和机构名等。
3)图结构生成
其输入是自然语言,输出结果是一个以图表示的结构。图中的节点既可以来自原始输入,也可以是新生成的;边连接了两个节点,并可以赋予相应的类型。
3.3 序列到序列问题
很多自然语言处理问题可以归为序列到序列(Sequence-to-Sequence,Seq2seq)问题。机器翻译问题就是典型的代表,其中,输入为源语言句子,输出为目标语言句子。将其推广到序列到序列问题,输入就是一个由若干词组成的序列,输出则是一个新的序列,其中,输入和输出的序列不要求等长,同时也不要求词表一致。
基于深度学习模型,可以直接将输入序列表示为一个向量,然后,通过该向量生成输出序列。其中,对输入序列进行表示的过程又叫作编码,相应的模型则被称为编码器(En-coder);生成输出序列的过程又叫作解码,相应的模型则被称为解码器(Decoder)。因此,序列到序列模型也被称为编码器–解码器(Encoder-Decoder)模型。
4. 评价指标
准确率、F值等。