本章节主要介绍感知机的基础知识,虽然在目前的机器学习范围内,感知机已经不怎么使用,但是通过对感知机的学习可以更好的了解以后的线性模型等相关知识。
同时读者可以点击链接:机器学习-目录_欲游山河十万里的博客-CSDN博客
学习完整的机器学习的相关知识。
目录
感知机
一、感知机的学习目标
二、感知机的介绍
2.1感知机模型
2.2感知机损失函数的定义
2.3简单的理解感知机的原理
2.4感知机结构介绍
2.4.1简单的逻辑电路
三、感知机的引入
3.1 线性可分和线性不可分
3.2感知机模型分析
四、感知机原始形式(鸢尾花分类)
4.1数据集的准备
4.1.1导入包
4.1.2导入数据集
4.1.3原始数据可视化
4.1.4划分数据集和标签
4.1.5感知机的实现
4.2感知机原始形式(鸢尾花分类)
4.2.1导入模块
4.2.2自定义感知机模型
4.2.3获取数据
参考文献
写在最后
感知机
感知机在1957年被提出,算是最古老的分类方法之一。
虽然感知机泛化能力不及其他的分类模型,但是如果能够对感知机的原理有一定的认识,在之后学习支持向量机、神经网络等机器学习算法的时候会轻松很多。
一、感知机的学习目标
- 感知机模型
- 感知机的损失函数和目标函数
- 感知机原始形式和对偶形式
- 感知机流程
- 感知机优缺点
二、感知机的介绍
在本部分,我参考了网上多位博文对感知机的不同理解,大家可以根据自己的喜好进行对应的理解。
输入为实例的特征向量,输出为实例的类别,取+1和-1;
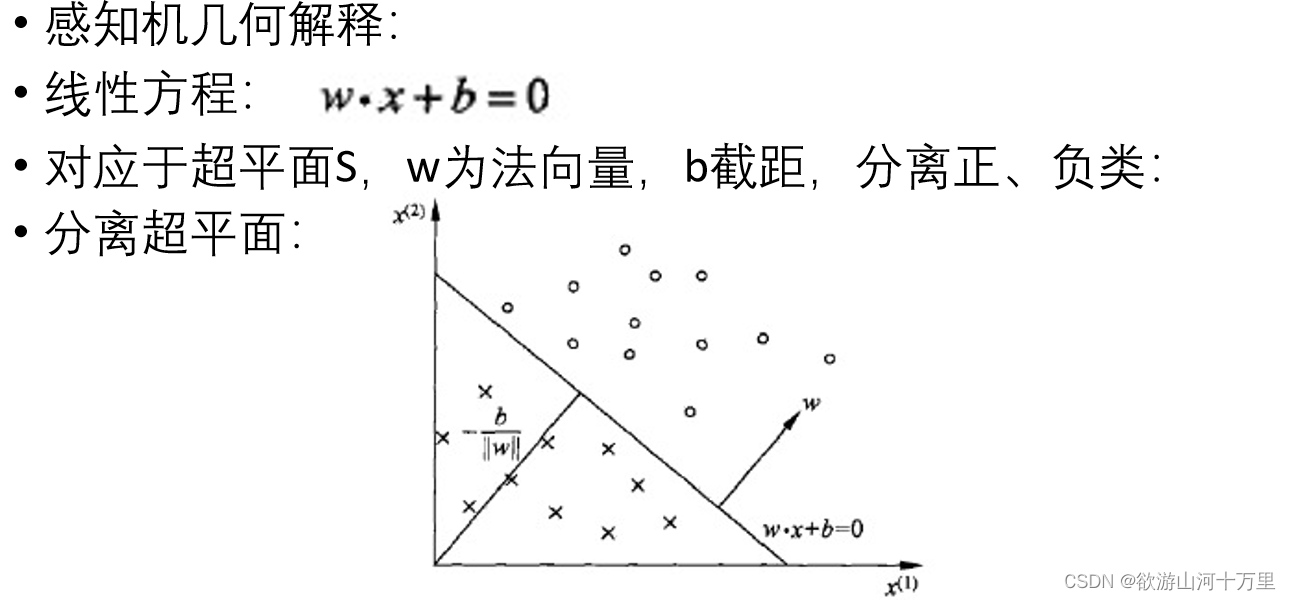
感知机对应于输入空间中将实例划分为正负两类的分离超平面,属于判别模型;
导入基于误分类的损失函数; 利用梯度下降法对损失函数进行极小化;
感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式;
1957年由Rosenblatt提出,是神经网络与支持向量机的基础。
2.1感知机模型

2.2感知机损失函数的定义


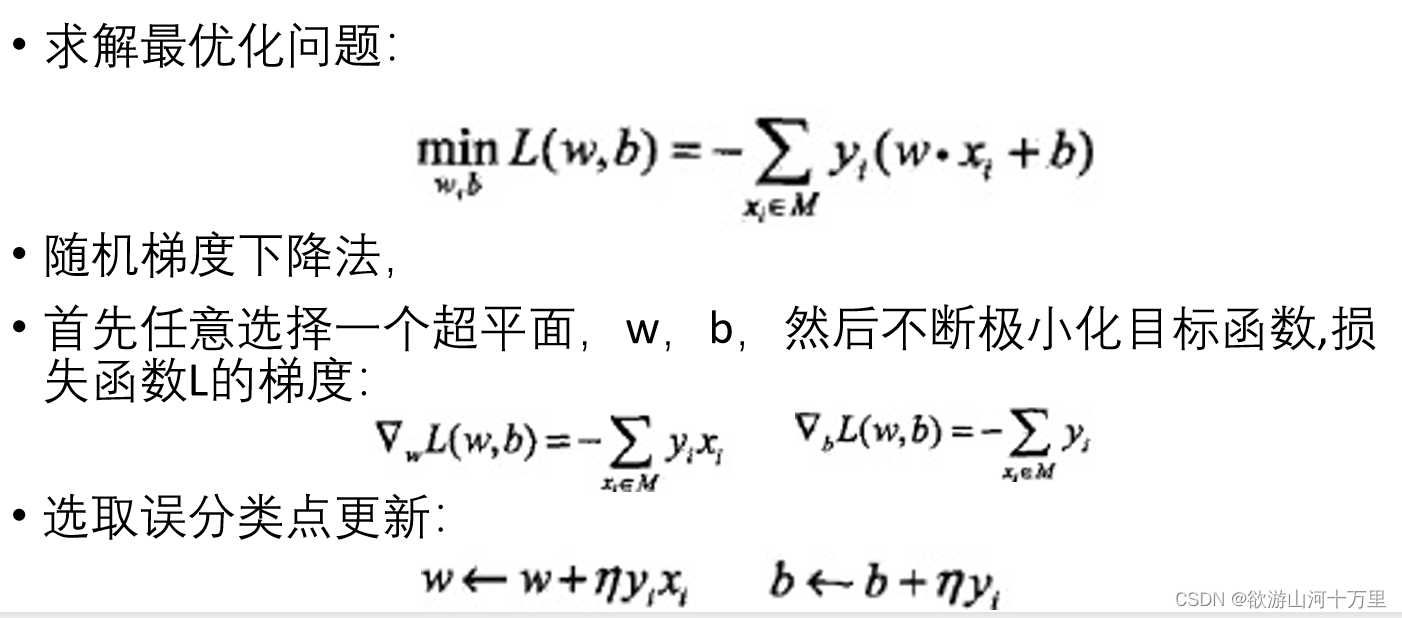
2.3简单的理解感知机的原理
1.感知机是根据输入实例的特征向量对其进行二类分类的线性分类模型:
感知机模型对应于输入空间(特征空间)中的分离超平面。
2.感知机学习的策略是极小化损失函数:
求出L最小数值时候的,w,b的值
损失函数对应于误分类点到分离超平面的总距离。
3.感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法,有原始形式和对偶形式。算法简单且易于实现。原始形式中,首先任意选取一个超平面,然后用梯度下降法不断极小化目标函数。在这个过程中一次随机选取一个误分类点使其梯度下降。
4.当训练数据集线性可分时,感知机学习算法是收敛的。感知机算法在训练数据集上的误分类次数满足不等式:
当训练数据集线性可分时,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能有所不同。
2.4感知机结构介绍
感知机接收多个输入信号,输出一个信号。感知机的信号只有“流/不流”(1/0)两种取值。0对应“不传递信号”,1对应“传递信号”。
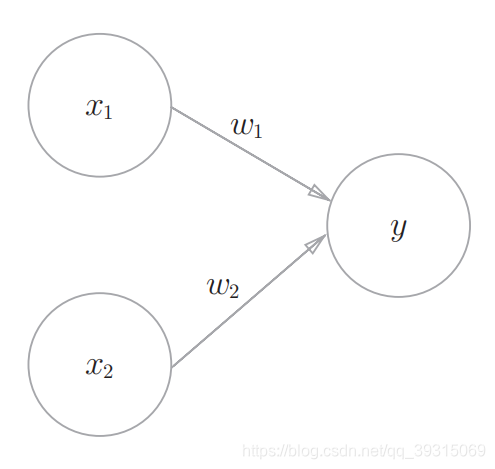
----上图是一个接收两个输入信号的感知机的例子。x1、x2是输入信号,y是输出信号,w1、w2是权重(w是weight的首字母)。图中的○称为“神经元”或者“节点”。输入信号被送往神经元时,会被分别乘以固定的权重(w1x1、w2x2)。神经元会计算传送过来的信号的总和,只有当这个总和超过了某个界限值时,才会输出1。这也称为“神经元被激活”。这里将这个界限值称为阈值,用符号θ表示。
----感知机的多个输入信号都有各自固有的权重,这些权重发挥着控制各个信号的重要性的作用。也就是说,权重越大,对应该权重的信号的重要性就越高。
----权重相当于电流里所说的电阻。电阻是决定电流流动难度的参数,电阻越低,通过的电流就越大。而感知机的权重则是值越大,通过的信号就越大。不管是电阻还是权重,在控制信号流动难度(或者流动容易度)这一点上的作用都是一样的。
下面开始举一些简单的例子并通过python语言实现这些案例
2.4.1简单的逻辑电路
与门
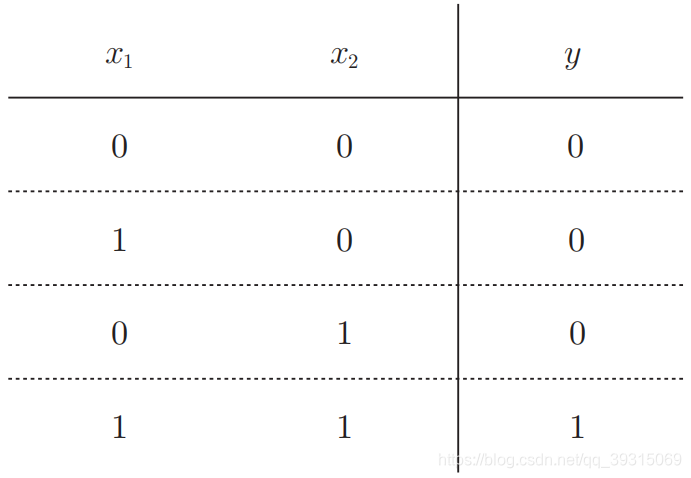
与非门和或门(NAND gate)
----与非门就是颠倒了与门的输出。仅当x1和x2同时为1时输出0,其他时候则输出1。
与非真值表
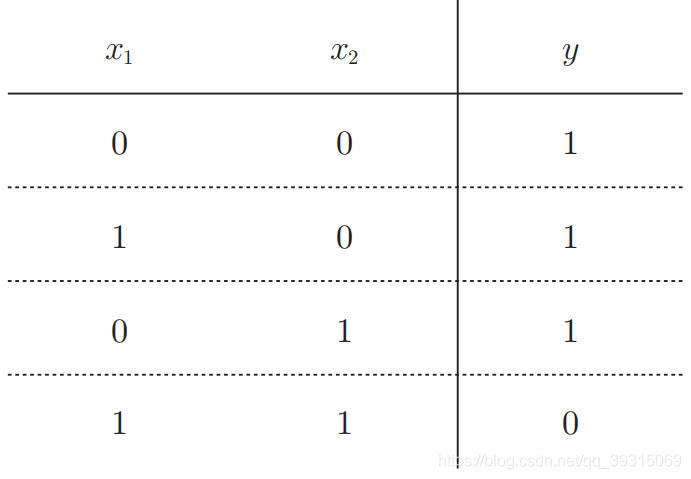
或门的表

下面开始代码的具体实现操作。
import numpy as np
def AND(x1,x2):#与门操作,需要x1和x2全部为1的情况下,才可以输出1
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b = -0.7
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
def NAND(x1,x2):#与非门操作,仅当x1和x2同时为1时输出0,其他时候则输出1
x = np.array([x1,x2])
w = np.array([-0.5,-0.5])
b = 0.7
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
def OR(x1, x2):#或门操作,相同为0,不同为1
x = np.array([x1,x2])
w = np.array([0.5,0.5])
b = -0.2
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
if __name__=="__main__":
x1=1
x2=1
tmp=AND(x1,x2)
print(tmp)三、感知机的引入
本部分主要对感知机的实际运用举一些例子,希望可以尽可能方便理解感知机的运用
3.1 线性可分和线性不可分
每逢下午有体育课,总会有男孩和女孩在学校的操场上玩耍。
假设由于传统思想的影响,男孩总会和男孩一起打打篮球,女孩总会和女孩一起踢毽子、跳跳绳,如下图所示。
# 感知机引入图例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#设置中文字体的目录地址
font = FontProperties(fname='C:\\windows\\fonts\\simsun.ttc')
np.random.seed(1)
x1 = np.random.random(20)+1.5#生成20行一列的x1数据,数据范围都在0-1范围内随机生成并对每个数加上1.5,即1.5-2.5范围内
y1 = np.random.random(20)+0.5#y1的取值范围是0.5-1.5
x2 = np.random.random(20)+3#x2的取值范围是3.0-4.0
y2 = np.random.random(20)+0.5#y2的取值范围是0.5-1.5
# 一行二列第一个
plt.subplot(1,2,1)
#绘制(x1,y1)的散点图
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
#绘制(x2,y2)的散点图
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.vlines(2.8, 0, 2, colors="r", linestyles="-", label='$wx+b=0$')
plt.title('线性可分', fontproperties=font, fontsize=20)
plt.xlabel('x')
plt.legend(prop=font)
# 一行二列第二个
plt.subplot(1,2,2)
plt.scatter(x1, y1, s=50, color='b', label='男孩(+1)')
plt.scatter(x2, y2, s=50, color='r', label='女孩(-1)')
plt.scatter(3.5, 1, s=50, color='b')#这个时候有一个男孩跑到女孩的范围内
plt.title('线性不可分', fontproperties=font, fontsize=20)#设置图片的标题
plt.xlabel('x')
plt.legend(prop=font, loc='upper right')
plt.show()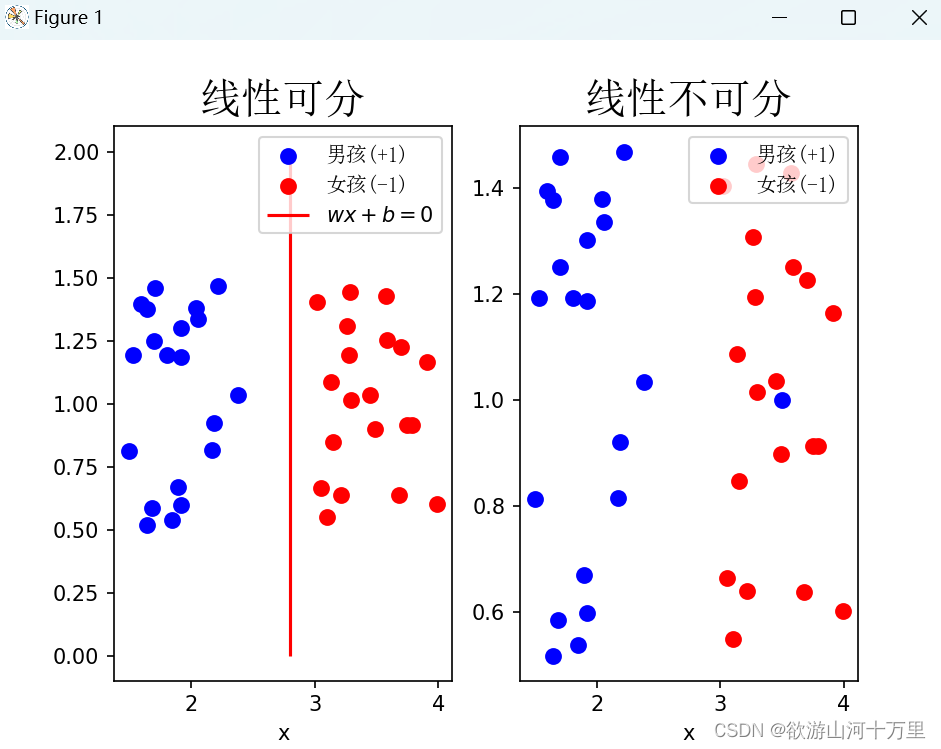
从左图中也可以看出总能找到一条直线将男孩和女孩分开,即男孩和女孩在操场上的分布是线性可分的,此时该分隔直线为 ωx+b=0。其中ω,b是参数,x是男孩和女孩共有的某种特征。如果某个男孩不听话跑到女孩那边去了,如下图右图所示,则无法通过一条直线能够把所有的男孩和女孩分开,则称男孩和女孩在操场上的分布是线性不可分的,即无法使用感知机算法完成该分类过程。上述整个过程其实就是感知机实现的一个过程。
3.2感知机模型分析
感知机是一个二分类线性模型,即输出为实例的类别,一般为其中一类称为正类(+1),另一类称为负类(−1)。
可以把上图所示的男孩(+1)称为正类,女孩(−1)称为负类。假设有m个实例n维特征并且数据线性可分的数据集
T={(x1,y1),(x2,y2),⋯,(xm,ym)}T={(x1,y1),(x2,y2),⋯,(xm,ym)}
它的输出空间即y的取值是y={+1,−1}。
由于数据线性可分,如果是二维空间,则总能找到一条直线将二维空间中的数据集分为两类,
如上图所示的 ωx+b=0,如果是三维空间,则能找到一个平面把三维空间中的数据集分为两类。
对于上述的假设的数据集T,则总能找到一个超平面S将该数据集分成两类,该超平面S可以记作
四、感知机原始形式(鸢尾花分类)
4.1数据集的准备
本部分使用sklearn的鸢尾花数据。
sklearn.datasets.load_iris(*, return_X_y=False, as_frame=False)
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性(分别是:花萼长度,花萼宽度,花瓣长度,花瓣宽度)。可通过这4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类的鸢尾花中的哪一类。
Iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一列代表某个被测量的鸢尾植物,一共有150条记录。
4.1.1导入包
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt4.1.2导入数据集
iris = load_iris()用来加载数据
df['label'] = iris.target划分数据的标签
这里我们只取花萼长度,花萼宽度,花瓣长度,花瓣宽度为属性
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
df.label.value_counts()4.1.3原始数据可视化
照花萼长度,花萼宽度进行可视化数据划分,0-49为0类,50-99为1类。
#使用0-50行地数据绘制一个scatter图
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
#使用50-100行的数据绘制一个scatter图
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')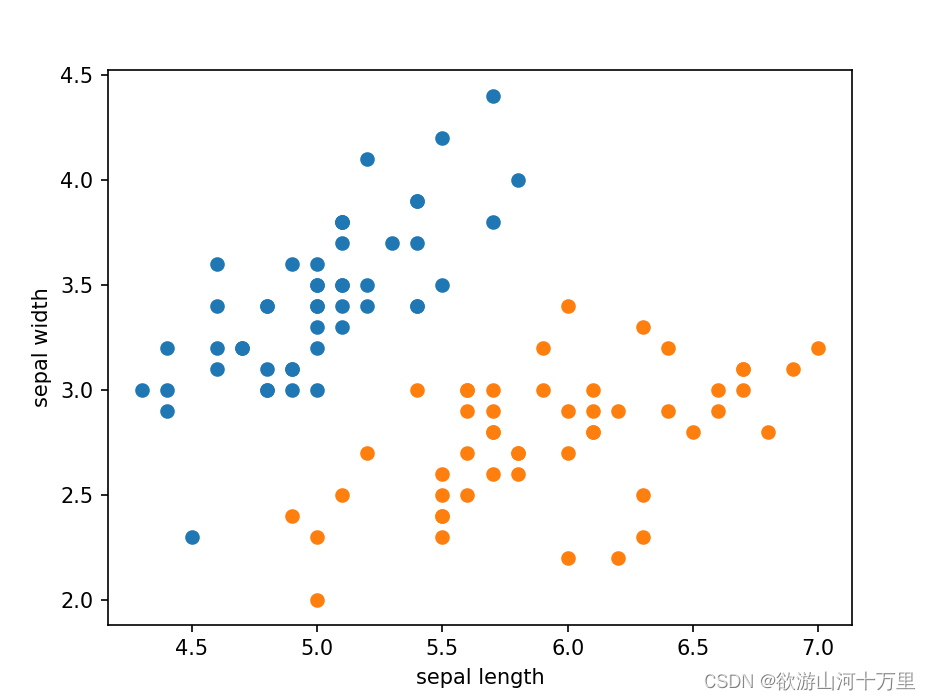
完整的代码
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
#以上的内容是实验过程中需要的导包
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)#开始导入数据
df['label'] = iris.target#划分数据的标签
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
print(df.label.value_counts())
#使用0-50行地数据绘制一个scatter图
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
#使用50-100行的数据绘制一个scatter图
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
#有这两个50的数据分属于两个不同的类别,所以可以清晰的看出图片的分类性质
plt.show()4.1.4划分数据集和标签
data = np.array(df.iloc[:100, [0, 1,-1]])#data取得的数据是0列,1列和最后一列的数据
#print(data)
#print(data.shape)#(100,3)
#x取得除最后一列的所有数据,y取得最后一列的所有数据
x, y = data[:, :-1], data[:, -1]
#print(x.shape)#(100,2)
#print(y.shape)#(100,1)
#将y中的值转化成1和-1
y = np.array([1 if i == 1 else -1 for i in y])#如果y的值是1,那么就赋值为1,否则就赋值为-1
#print(y)
4.1.5感知机的实现
#coding = utf-8
#数据线性可分,二分类数据
#此处为一元一次线性方程
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
#以上的内容是实验过程中需要的导包
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)#开始导入数据
df['label'] = iris.target#划分数据的标签
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
class Model:
def __init__(self):
self.w = np.ones(len(data[0]) - 1, dtype=np.float32)#生成一个w系数
self.b = 0#设置初始化的偏置量
self.l_rate = 0.000001#设置学习率,发现改变学习率之后绘制的图片效果不一样
# self.data = data
def sign(self, x, w, b):#实现wx+b的操作
y = np.dot(x, w) + b
return y
#随机梯度下降法
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
wrong_count = 0
for d in range(len(X_train)):
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0:
self.w = self.w + self.l_rate * np.dot(y, X) #w=w+l_rate*y*x
self.b = self.b + self.l_rate * y #b=b+l_rate*y
wrong_count += 1
if wrong_count == 0:
is_wrong = True
return 'Perceptron Model!'
def score(self):
pass
data = np.array(df.iloc[:100, [0, 1,-1]])#data取得的数据是0列,1列和最后一列的数据
#print(data)
#print(data.shape)#(100,3)
#x取得除最后一列的所有数据,y取得最后一列的所有数据
x, y = data[:, :-1], data[:, -1]
#print(x.shape)#(100,2)
#print(y.shape)#(100,1)
#将y中的值转化成1和-1
y = np.array([1 if i == 1 else -1 for i in y])#如果y的值是1,那么就赋值为1,否则就赋值为-1
#print(y)
perceptron = Model()
perceptron.fit(x, y)
x_points = np.linspace(4, 7, 10)
#x_points数据在系数的作用下,产生一个分类线
y_ = -(perceptron.w[0] * x_points + perceptron.b) / perceptron.w[1] #y_=(w0*x+b)/w1
print(y_)
plt.plot(x_points, y_)
#
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()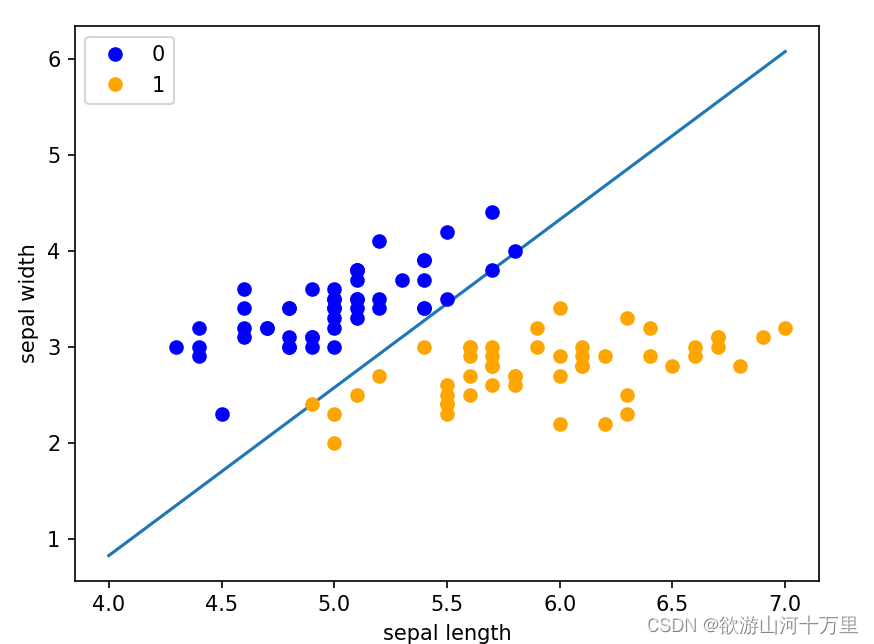
4.2感知机原始形式(鸢尾花分类)
这部分的博文,我是直接从其他大佬的博文转过来的来,区别不大,诸位有兴趣可以去给这位大佬点个赞
02-03 感知机对偶形式(鸢尾花分类) - 二十三岁的有德 - 博客园
4.2.1导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.font_manager import FontProperties
from sklearn.datasets import load_iris
# 中文字体设置
font = FontProperties(fname='C:\\windows\\fonts\\simsun.ttc')4.2.2自定义感知机模型
class Perceptron():
"""自定义感知机算法"""
def __init__(self, learning_rate=0.01, num_iter=50, random_state=1):
self.learning_rate = learning_rate
self.num_iter = num_iter#循环遍历更新权重直至算法收敛
self.random_state = random_state
def fit(self, X, y):
"""初始化并更新权重"""
# 通过标准差为0.01的正态分布初始化权重
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.errors_ = []
# 循环遍历更新权重直至算法收敛
for _ in range(self.num_iter):
errors = 0
for x_i, target in zip(X, y):
# 分类正确不更新,分类错误更新权重
update = self.learning_rate * (target - self.predict(x_i))
self.w_[1:] += update * x_i
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def predict_input(self, X):
"""计算预测值"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""得出sign(预测值)即分类结果"""
return np.where(self.predict_input(X) >= 0.0, 1, -1)4.2.3获取数据
由于获取的鸢尾花数据总共有3个类别,所以只提取前100个鸢尾花的数据得到正类(versicolor 杂色鸢尾)和负类(setosa 山尾),并分别用数字1和-1表示,并存入标记向量y,之后逻辑回归会讲如何对3个类别分类。同时由于三维以上图像不方便展示,将只提取第三列(花瓣长度)和第三列(花瓣宽度)的特征放入特征矩阵X。
'''
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
注释的这一行代码的作用和下面的三行代码的作用是一样的,但是在格式上还是有一些不一样,比如对不同分类的命名方式上的区别
'''
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)#开始导入数据
df['label'] = iris.target#划分数据的标签
print(df)
# 取出前100行的第五列即生成标记向量
y = df.iloc[0:100, 4].values
y = np.where(y == 1, 1, -1)
# 取出前100行的第一列和第三列的特征即生成特征向量
X = df.iloc[0:100, [2, 3]].values
plt.subplot(1,3,1)
plt.scatter(X[:50, 0], X[:50, 1], color='r', s=50, marker='x', label='山鸢尾')
plt.scatter(X[50:100, 0], X[50:100, 1], color='b',
s=50, marker='o', label='杂色鸢尾')
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.subplot(1,3,2)
perceptron = Perceptron(learning_rate=0.1, num_iter=10)
perceptron.fit(X, y)
plt.plot(range(1, len(perceptron.errors_) + 1), perceptron.errors_, marker='o')
plt.xlabel('迭代次数', fontproperties=font)
plt.ylabel('更新次数', fontproperties=font)
plt.subplot(1,3,3)
plot_decision_regions(X, y, classifier=perceptron)
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.legend(prop=font)
plt.show()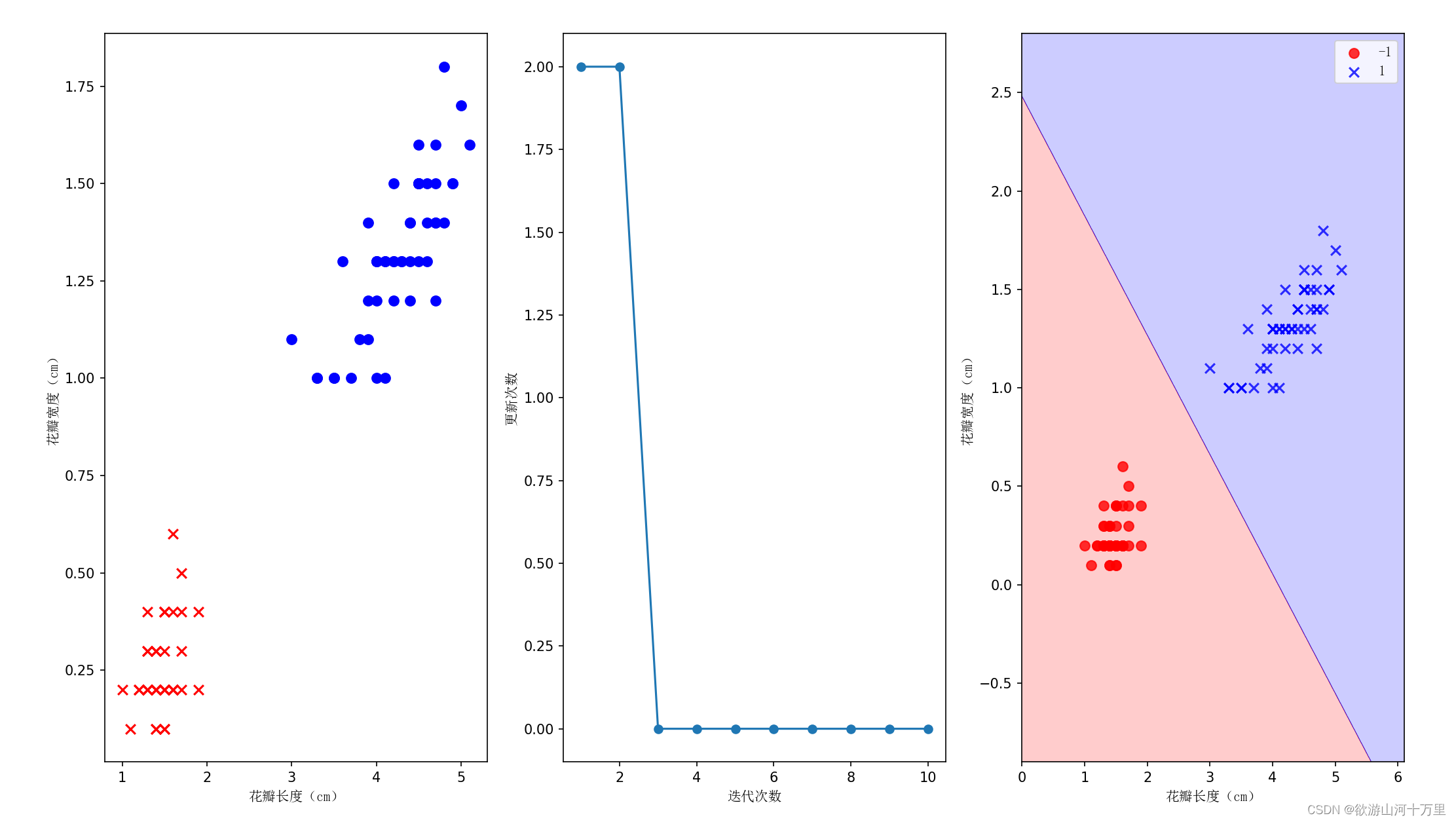
参考文献
复现经典:《统计学习方法》第 2 章 感知机
02-01 感知机 - 二十三岁的有德 - 博客园
感知机介绍_机器人_robot的博客-CSDN博客_感知机
感知机python代码实现_maggieyiyi的博客-CSDN博客_感知机代码
02-02 感知机原始形式(鸢尾花分类) - 二十三岁的有德 - 博客园
02-03 感知机对偶形式(鸢尾花分类) - 二十三岁的有德 - 博客园
pandas中df.iloc函数应用_天山卷卷卷的博客-CSDN博客_df1.iloc
什么是感知机(超详细 | 图文)_Xav Zewen的博客-CSDN博客_感知机
写在最后
为了完成这一篇博文,我参考了如上很多个大佬的博文,我真心地觉得诸位大佬地水平高超,博文条例清晰,诸位可以直接通过链接阅读我所推荐地几位大佬地博文。