系列文章目录
Redis内存优化——String类型介绍及底层原理详解
Redis内存优化——Hash类型介绍及底层原理详解
Redis内存优化——List类型介绍及底层原理详解
Redis内存优化——Set类型介绍及底层原理详解
Redis内存优化——ZSet类型介绍及底层原理详解
文章目录
- 系列文章目录
- 前言
- ZSet
- 概述
- skiplist
- redis的skiplist
- 总结
前言
Redis是一种高性能的键值型数据库,它支持多种数据结构,其中一种是zset类型。zset类型可以存储一个有序的、不重复的字符串集合,类似于Java中的TreeSet或Python中的sorted set。zset类型的优点是可以对集合进行快速的添加、删除、判断是否存在等操作,以及对集合中的元素按照分值(score)进行排序,分值相同则按照字典序排序。
ZSet
概述
Redis 中的 zset 是一种有序集合类型,它可以存储不重复的字符串元素,并且给每个元素赋予一个排序权重值(score)。Redis 通过权重值来为集合中的元素进行从小到大的排序。zset 的成员是唯一的,但权重值可以重复。一个 zset 类型的键最多可以存储 2^32 - 1 个元素。
Redis中zset源码
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
Redis在存储zset结构的数据,为了达到内存和性能的平衡,针对少量存储和大量存储分别设计了两种结构,分别为:
redis7.0之前使用的ziplist和skiplistredis7.0之后使用的listpack和skiplist
也就是说不论是7.0前后都有两种结构,但是7.0后使用了listpack代替ziplist,这是由于ziplist的连锁更新问题,连锁更新问题请见我另一篇博文:Redis高可用系列——Set类型底层详解。这边博文中详细的解释。
当 zset 中的元素个数和元素值的长度比较小的时候,Redis 使用ziplist/listpack来节省内存空间。当 zset 中的元素个数和元素值的长度达到一定阈值时,Redis 会自动将ziplist/listpack转换为skiplist,以提高操作效率
具体来说,当 zset 同时满足以下两个条件时,会使用 listpack作为底层结构:
- 元素个数小于
zset_max_listpack_entries,默认值为 128 - 元素值的长度小于
zset_max_listpack_value,默认值为 64
当 zset 中不满足以上两个条件时,会使用 skiplist 作为底层结构。
skiplist
跳跃表是一种随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳跃表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳跃表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
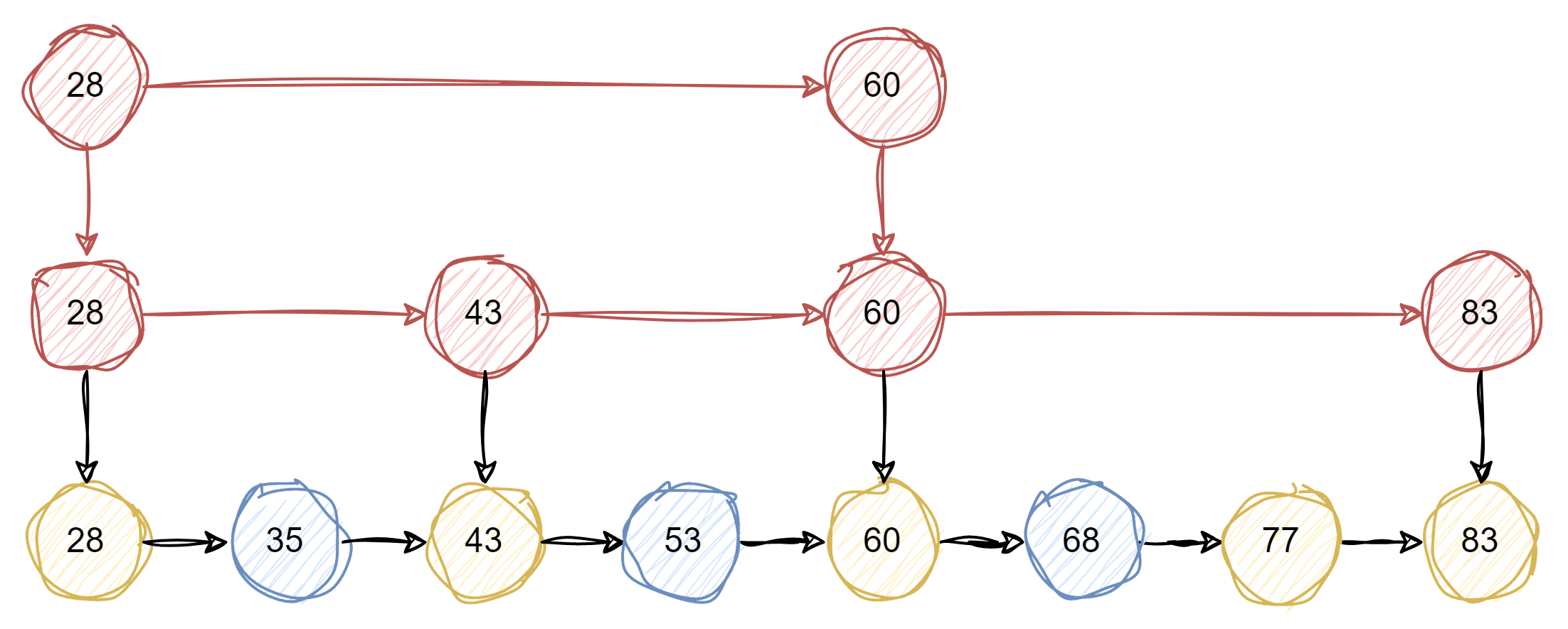
跳跃表相比于其他平衡树结构,有以下几个优点和缺点:
优点:
- 实现简单,易于理解和调试
- 插入和删除操作只需要修改局部节点的指针,不需要像平衡树那样进行全局调整
- 可以利用空间换时间,通过增加索引层来提高查找效率
- 支持快速的范围查询,可以方便地返回指定区间内的所有元素
缺点:
- 空间复杂度较高,需要额外存储多级索引
- 随机性太强,性能不稳定,最坏情况下可能退化成链表
- 不支持快速的倒序遍历,需要额外的指针来实现
redis的skiplist
skiplist这种数据结构有一个层数上的问题,当层数过多,会影响查询效率。是因为当层数过多,会进行多次IO操作。而Redis 使用了一个随机函数来决定每个节点的层数,这个随机函数的期望值是 1/(1-p) ,其中 p 是一个概率常数,Redis 中默认为 0.25。这样可以保证跳跃表的平均高度为 log (1/p) n ,其中 n 是节点数。Redis 还限制了跳跃表的最大层数为 32 ,这样可以避免过高的索引层造成空间浪费
总结
Redis Zset类型是一种可以存储一个有序的、不重复的字符串集合的数据结构,它有以下特点:
- 可以对集合进行添加、删除、判断是否存在等操作,时间复杂度都是O (1)
- 可以对集合中的元素按照分值(score)进行排序,分值相同则按照字典序排序
- 可以对多个集合进行交集、并集、差集等操作,并指定分值的聚合方式
- 可以用作排行榜、优先队列、延时任务等场景