引言
首先说明下晶飞上位机软件存在的问题,实验所采用的FLA5000型号光谱仪,光谱波段从280-970nm,FWHM值为2.4nm。
1、上位机软件中的光谱数据复制功能基本是废的,最多只能到599.9nm,后面的数据全部消失。
2、上位机软件本身无法导出csv或其他格式的光谱数据文件,只能以FlaSpec格式进行保存,所以需要对该格式进行分析。
3、提供了光谱表功能,但是问题在于依然无法全部显示数据,只能到800nm左右,并且没有提供保存数据功能,只能手动复制。
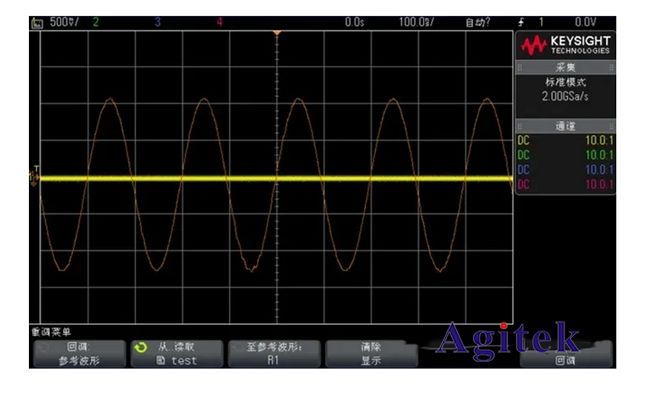
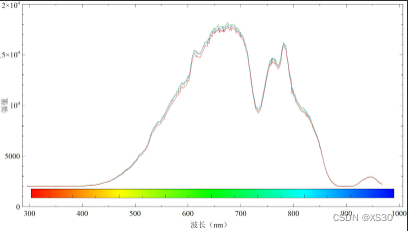
PS:可能是我不会用,也可能是拿到的非最新版软件,晶飞上位机软件确实存在蛮多问题,或者说交互逻辑反直觉,但是光谱仪的一致性还不错,如下图所示,但是其动态范围较低(技术手册上的指标比USB2000要高,但是实测就是差了一大截),容易饱和,限制了实验及应用场景。
数据格式分析
将FlaSpec文件以文本格式打开(这里使用Notepad++),根据官方软件中所查看到的数据进行多点匹配,可以得知,其文件中记录的FWHM值为1nm,该型号物理FWHM值为2.4nm,故推测其为插值得到。
如下图1所示,line5:起始波段;line6:截止波段;line7:最大峰值;line15:第一个波段幅值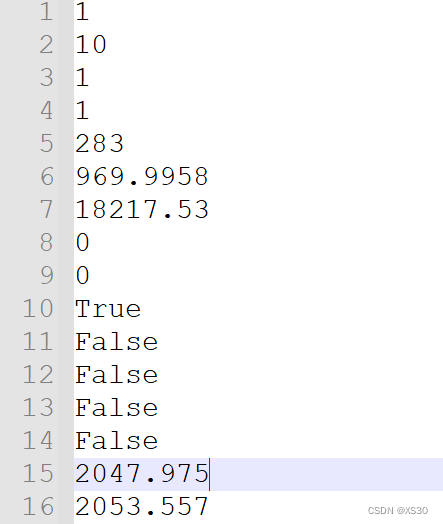
其他数据暂时不知用途,line1-4猜测应该为波长间隔、采样次数、积分时间、滑动平均次数等。
line10-14猜测应为触发模式是否开启等参数,如下图2所示。

在line700:为截止波段幅值
line701,会出现一个空白行,而后的数据又开始从起始幅值开始记录数据?

批处理代码
运行流程:首先读取路径下所有FlaSpec文件,并且提取指定范围的数据,复制到对应名称的csv文件,然后读取所有csv文件,使用pandas工具进行合并到一个csv文件中。
import os
import pandas as pd
def extract_data(file_path):
# 打开文件并读取内容
with open(file_path, 'r') as f:
lines = f.readlines()
# 提取第15行到第700行的数据
data_lines = lines[14:699]
# 将数据保存到一个字符串中
data_str = ''
for line in data_lines:
data_str += line
return data_str
def main():
# 指定要读取的文件夹路径,输入你的路径
folder_path = 'XXX/PycharmProjects/Fla5000/folder'
# 遍历文件夹中所有的.FlaSpec文件
for filename in os.listdir(folder_path):
if filename.endswith('.FlaSpec'):
file_path = os.path.join(folder_path, filename)
# 提取数据并保存到一个新的.csv文件中
data_str = extract_data(file_path)
csv_filename = os.path.splitext(filename)[0] + '.csv'
csv_path = os.path.join(folder_path, csv_filename)
with open(csv_path, 'w') as f:
f.write(data_str)
# 获取文件夹中所有csv文件的路径
csv_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.csv')]
# 合并csv文件
df_list = []
for csv_file in csv_files:
df = pd.read_csv(csv_file, header=None)
df_list.append(df)
merged_df = pd.concat(df_list, axis=1)
# 将合并后的数据保存为新的csv文件
merged_df.to_csv(os.path.join(folder_path, 'merged_data.csv'), index=False, header=None)
if __name__ == '__main__':
main()
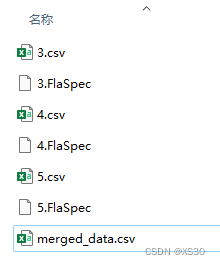
路径下的各类文件。
需要注意的是,如果安装pandas出现错误,可以使用使用代码[1]进行安装,在此表示感谢。
py -3 -m pip install pandas -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
结语
综上所述,FlaSpec文件格式较为简单,容易使用python等语言进行批量处理,在进行数据采集及后续的数据分析过程中,使用该格式文件只能说是曲线救国了,后续如果继续使用该光谱仪,会将批处理代码实现后放出。
初步构想为自动读取文件夹下所有flaspec文件,并根据数据格式进行解析,后写入到一个同csv文件中。
参考资料
[1] python安装pandas报错,version问题看这里!!!