💗 💗 博客:小怡同学
💗 💗 个人简介:编程小萌新
💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞
命名空间
常见域的种类
常见的域的种类有:全局域,局部域,命名空间域,类域
其中命名空间域需要指定访问命名空间中的变量或者直接展开命名空间域才能访问(展开命名空间域暴露在全局中)//好比命名空间域是个围墙需要访问变量才能看见,展开命名空间好比把墙拆除所有变量暴露在全局之中但这样容易发生变量命名冲突
命名空间的定义
关键字:namespace
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
命名空间使用
命名空间中可以定义变量/函数/自定义类型 命名空间还可以嵌套
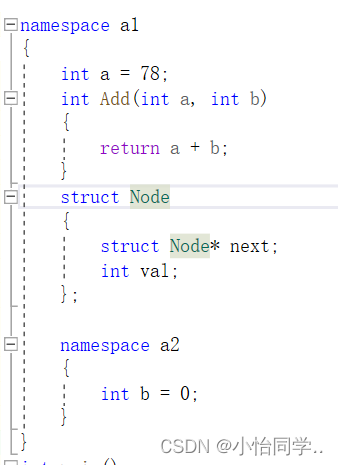
命名空间使用的三种方式
加命名空间名称及作用域限定符

使用using namespace 命名空间名称引入
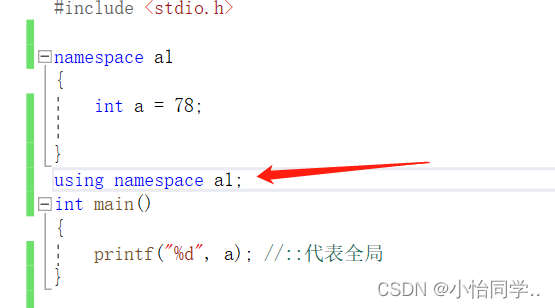
using 命名空间名::变量(将命名空间某个变量引入)
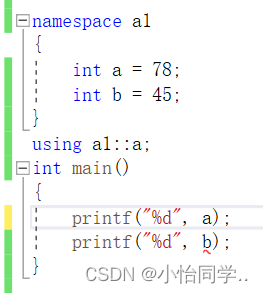
C++的输入和输出
#include using namespace std
//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中


缺省参数
缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该 形参的缺省值,否则使用指定的实参。

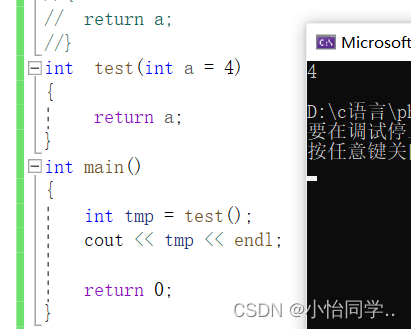
缺省参数分类
半缺省参数
// 半缺省参数必须从右往左依次来给出,不能间隔着给
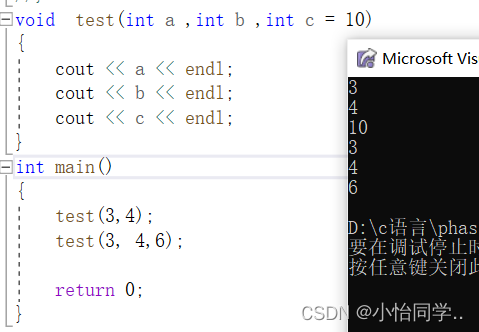
全缺省参数

缺省参数的注意事项
1.缺省参数不能在声明与定义中同时出现 //因为担心声明与定义不统一 //声明中给缺省值,定义中不用给缺省值 ,预处理头文件展开,当编译时查看代码,当声明与函数调用处统一则往下进行
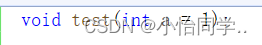


2.C语言不支持(编译器不支持)
3.缺省值必须是常量或者全局变量
函数重载
函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数 的形参列表(参数个数 或 类型 或
类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
函数重载代码实现
1.参数类类型不同
2.参数个数不同
3.参数类型顺序不同
//返回值不同不构成重载
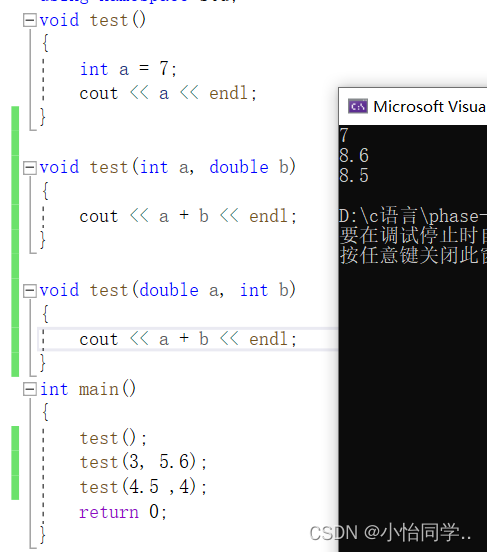
c++支持重载而,为什么c语言不支持重载
首先,我们需要明白在c/c++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接
预处理时头文件会展开,编译时每个文件遍历各自文件的代码,链接时在符号表寻找地址,然后链接在一起。
我的理解是重载成功,必不可少的两个因素是
一是重复的函数名在编译时会报错 因为在c语言中,相同的函数在编译时名字相同,无法判断
但是在c++中,在编译阶段,用巧妙的方法使得相同函数名分开

二是链接时需要把函数地址和对应的函数链接在一起,(相当于声明是承若,而在链接阶段就是实现承若)
假设链接器看到a.o调用函数,但是没有函数的地址,就会到b.o的符号表中找函数的地址,然后链接到一起。
那么链接时,面对函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的函数名修饰规则。使得与对应函数赋予地址。
//当定义与声明同时存在时,不用通过链接 直接在编译阶段call(地址)就可以
//当声明与定义分别在各自文件时,编译阶段有声明存在就可通过
引用
引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。相当于一个人有了两个或者多个名字,都是只同一个人
书写方式:类型& 引用变量名(对象名) = 引用实体;
引用特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
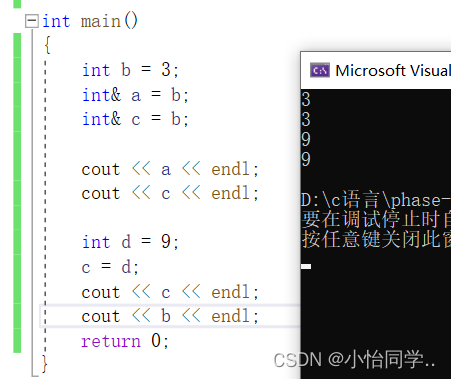


// c = d 这个步骤只是在赋值 没有引用别的变量
//定义的使用必须用变量来定义
引用的使用
常引用 //引用的使用权限只能缩小不能放大


做返回值

做参数
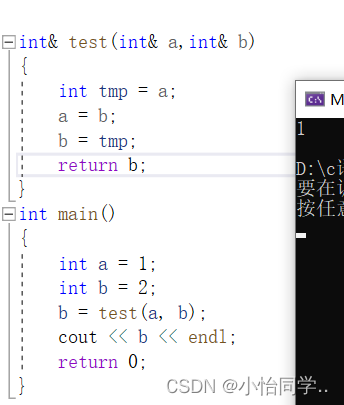
传值返回与引用返回的差别 传值返回出作用域之后生成一个临时变量 ,而引用返回出作用域不会生成一个临时变量,所以出作用域后,栈会自动销毁,比较不安全
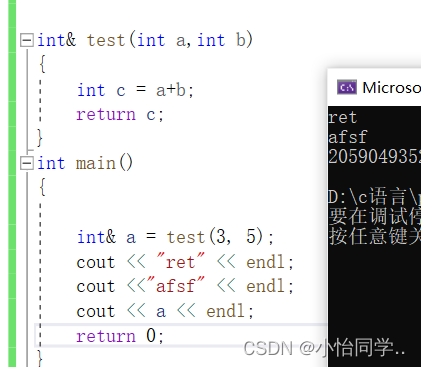
//引用做返回类型,变量最好是静态,全局或者是malloc
引用的优点
//引用在语法层面不会开空间 因为以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低,所以引用在一定程度上效率会更高
引用与指针的区别
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型 实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占 4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
内联函数
内联的定义
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧
的开销,内联函数提升程序运行的效率。
内联的特点
内联函数的特点是以空间换时间,在编译阶段函数体替换函数调用, 缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
使用建议:不能用于递归,频繁调用的函数,函数代码量大也不行 //编译器会自动挑选inline发来的请求 //如果调用10000次相同的函数
编译阶段call~
代表调用一次,为一个指令,代码量为50行为50个指令(因为实现同一个函数)所以指令共10000+50,而内敛函数直接展开所以是10000*50个指令
//inline不会调用函数所以在编译阶段不会call 宏优点:
1.增强代码的复用性。
2.提高性能。 缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查 。 //所以运用内联函数来换用宏,注意:内敛函数的声明与定义需要写在一起,因为内联函数直接展开,可以通过编译阶段但链接阶段找不到地址
auto关键字
auto的注意事项
//auto是一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
1.auto与指针和引用结合起来使用 用auto和auto*没有任何区别 auto声明引用类型时则必须加&

2.在同一行定义多个变量 //且是相同变量
3. auto不能作为函数的参数
4.auto不能直接用来声明数组
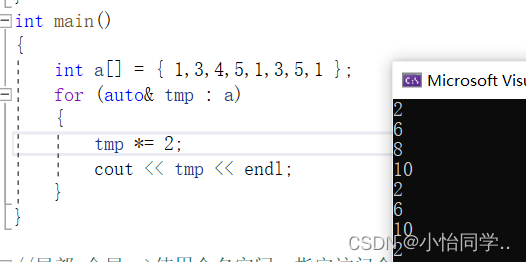
基于范围的for循环
//用于循环数组
for循环后的括号由冒号前后分为两部分:第一部分是范围内用于迭代的变量, 第二部分则表示被迭代的范围。




![[MTK7621] dhcp.script 脚本分析](https://img-blog.csdnimg.cn/d10b6023df794f1a88b554dcb7da42ea.png)