@TOC
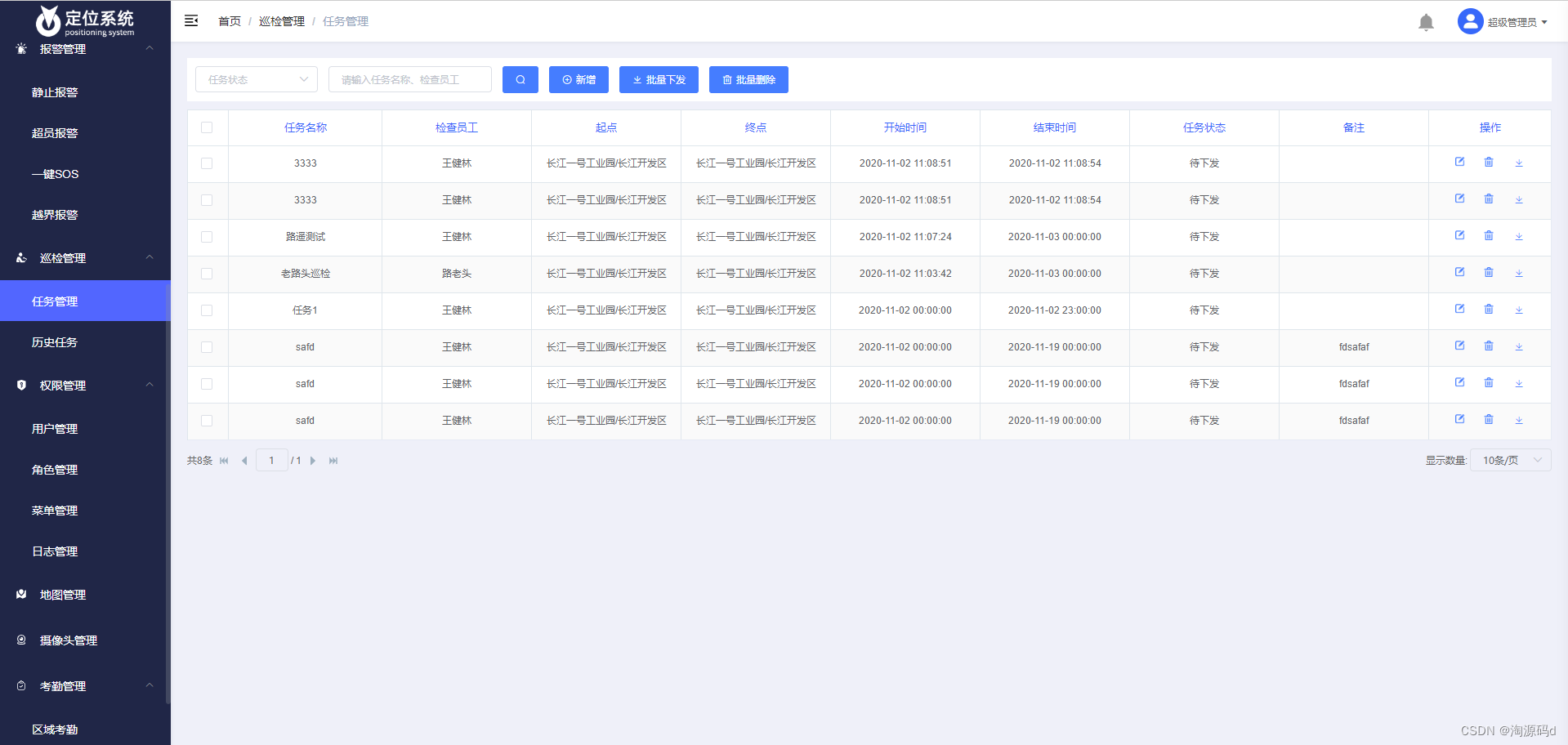
1. MySQL 的内连接、左连接、右连接有有什么区别?
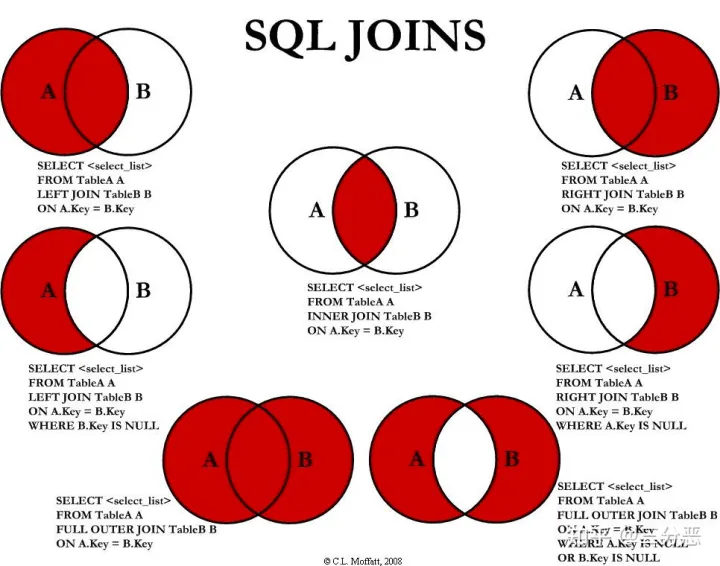
inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
left join 在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
right join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
varchar与char的区别?
| char | varchar | |
|---|---|---|
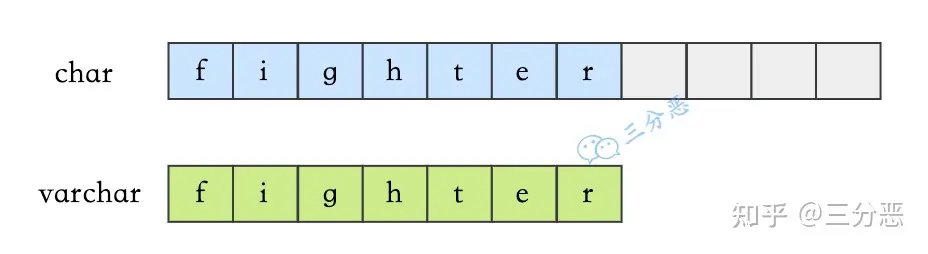
| char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充; | varchar表示可变长字符串,长度是可变的;插入的数据是多长,就按照多长来存储; | |
| 对于char来说,最多能存放的字符个数为255,和编码无关 | 对于varchar来说,最多能存放的字符个数为65532 | |
| 因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法; | varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法; |
日常的设计,对于长度相对固定的字符串,可以使用char,对于长度不确定的,使用varchar更合适一些。
DATETIME和TIMESTAMP的异同?
相同点
两个数据类型存储时间的表现格式一致。均为 YYYY-MM-DD HH:MM:SS
两个数据类型都包含「日期」和「时间」部分。
不同点
| DATETIME | TIMESTAMP | |
|---|---|---|
| 日期范围 | 1000-01-01 00:00:00.000000 到 9999-12-31 23:59:59.999999 | 1970-01-01 00:00:01.000000 UTC 到 2038-01-09 03:14:07.999999 UTC |
| 时区相关 | 存储时间与时区无关 | 存储时间与时区有关,显示的值也依赖于时区 |
| 存储空间 | 8 字节 | 4 字节 |
| 默认值 | 默认值为 null | TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP) |
MySQL中 in 和 exists 的区别?
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in(小表驱动大表)。
举例:
select * from A where id in(select id from B),当B表的数据集必须小于A表的数据集时,用in优于exists。
select *from A where exists (select 1 from B where b.id=a.id)。当A表的数据集小于B表的数据集时,用exists优于in。
SQL join查询为什么要小表驱动大表?
mysql的join实现原理是,以驱动表的数据为基础,“嵌套循环”去被驱动表匹配记录,
select * from a join b on a.bid =b.id
假设 a表10000数据,b表20数据
这里有2个过程,b 表数据最少,查询引擎优化选择b为驱动表,
循环b表的20条数据,
去a表的10000数据去匹配,这个匹配的过程是B+树的查找过程,比循环取数要快的多
小表驱动的方式
for 20条数据
匹配10000数据(根据on a.bid=b.id的连接条件,进行B+树查找)
查找次数 20+ log10000
大表驱动的方式
for 10000条数据
匹配20条数据(根据on a.bid=b.id的连接条件,进行B+树查找)
查找次数 10000+ log20
结论
可以看出来
小表驱动大表:20+ log10000
大表驱动小表:10000+ log20
显然小表驱动大表查询效率要高很多。
MySQL怎么存储emoji ?
MySQL可以直接使用字符串存储emoji。
但是需要注意的,utf8 编码是不行的,MySQL中的utf8是阉割版的 utf8,它最多只用 3 个字节存储字符,所以存储不了表情。
需要使用utf8mb4编码。
alter table blogs modify content text CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci not null;
drop、delete与truncate的区别?
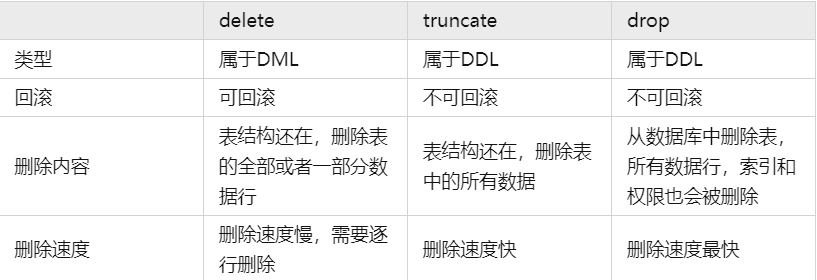
因此,在不再需要一张表的时候,用drop;在想删除部分数据行时候,用delete;在保留表而删除所有数据的时候用truncate。
UNION与UNION ALL的区别?

count(1)、count(*) 与 count(列名) 的区别?
MySQL日志文件有哪些?分别介绍下作用?
binlog 日志
二进制日志(binary log ),记录对 Mysql 数据库执行的所有 更改操作,包括 表结构的变更 和 表数据的修改 等,像 select 这种查询是不会记录 binlog 日志的。
binlog 日志采用 追加写 的方式写文件,一个文件写满后新写一个文件,仅在 事务提交前 进行一次写入。
生成的 binlog 日志文件可以用于 备份恢复、主从复制 以及 数据审计 等用途。
binlog 参数配置
binlog 日志默认是没有启动的,可以通过配置参数 log-bin 或 log_bin 来开启,开启 binlog 日志后,还有许多相关的参数可以做配置,这里捡几个重要的看下:
max_binlog_size:指定单个日志文件的最大值,达到阈值后,会生成一个新的日志文件,后缀名 +1,并记录到 .index 文件,形如 mysql-bin.000001、mysql-bin.000002 …
binlog_cache_size:日志缓存区大小。在事务未提交前,所有的 binlog 日志都会记录到内存缓存,等到事务提交的时候再写入日志文件,该参数即是设置该缓存区的大小。此外,日志缓存是基于会话的,也就是说 每个线程都有一块 binlog_cache_size 大小的内存缓存,因此,该值不宜设置太大;另一方面,如果某事务占用缓存超过设置值,就需要将日志写入临时文件,因此,该值也不能设置太小。那多大比较合适?可以通过 SHOW GLOBAL STATUS 查看 binlog_cache_disk_use (使用临时文件写日志次数)来判定,如果该值很大,说明缓存区过小,需要经常写临时文件,此时需要适当调大该参数。
sync_binlog:同步磁盘策略。我们平时写文件调用的 write() 函数其实并没有真正的将内容写到磁盘,而是写到文件系统的 page cache 里,真正将内容同步到磁盘的是 fsync() 函数。sync_binlog 就是用来设置 fsync() 函数的执行时机的:
sync_binlog = 0 : 不调用 fsync() 函数,由操作系统决定何时调用;
sync_binlog = 1 : 每个事务调用 write() 后立马执行 fsync() 函数;
sync_binlog = N (N>1) : 累计 N 个事务调用 write() 后,执行 fsync() 函数
binlog_format:日志格式,有三种格式选择STATEMENT、ROW、MIXED。默认是STATEMENT。
binlog和redo log有什么区别?
redo log是属于innoDB层面,binlog属于MySQL Server层面的,这样在数据库用别的存储引擎时可以达到一致性的要求。
redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
说一下数据库的三大范式?
三大范式的作用是为了控制数据库的冗余,是对空间的节省,实际上,一般互联网公司的设计都是反范式的,通过冗余一些数据,避免跨表跨库,利用空间换时间,提高性能。
第一范式:数据表中的每一列(每个字段)都不可以再拆分。 例如用户表,用户地址还可以拆分成国家、省份、市,这样才是符合第一范式的。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。 例如订单表里,存储了商品信息(商品价格、商品类型),那就需要把商品ID和订单ID作为联合主键,才满足第二范式。
第三范式:在满足第二范式的基础上,表中的非主键只依赖于主键,而不依赖于其他非主键。 例如订单表,就不能存储用户信息(姓名、地址)。
三级目录
小表驱动大表:https://blog.csdn.net/weixin_47104688/article/details/120238004
SQL join查询为什么要小表驱动大表?:https://www.cnblogs.com/hellotin/p/14227664.html
redolog/binlog:https://blog.csdn.net/LIFE_PLAN/article/details/126964034
https://blog.csdn.net/Xeroxo/article/details/119888551
来源:https://www.zhihu.com/question/486105337/answer/2538190061