目录
- 一、JVM
- 1.类加载过程
- 2.static和final变量的初始化时机
- 二、依赖
- 1.Spring Boot 自动装配
- 2.使用依赖过程中遇到问题如何排查
- 3.引入的某个依赖不符合预期,如何处理
- 三、数据库:
- 1.InnoDB 和 MyISAM 索引的区别
- 2.字符串类型字段,WHERE 数字,会走索引吗?数值型字段,WHERE 字符串,会走索引吗?
- 3.针对 RR 级别提问
- 4.间隙锁,什么时候触发
- 5.假设一台线上服务器只放了 MySQL 数据库,突发告警(CPU、内存等),如何排查
- 6.慢 SQL 如何排查,除了慢查询日志还有什么方式
一、JVM
1.类加载过程
类加载机制
Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。
类加载过程
在 Java 中,类加载是指将类的字节码文件加载到内存中,并将其转换为 Java 虚拟机可以使用的数据结构的过程。类加载过程主要包括以下三个步骤:
-
加载(Loading):将类的字节码文件加载到内存中。在加载阶段,Java 虚拟机会根据类的全限定名来查找类的字节码文件,并将其读入内存中。在读入字节码文件后,Java 虚拟机会为该类创建一个
java.lang.Class对象,用于表示该类在内存中的数据结构。 -
链接(Linking):将类的字节码文件转换为 Java 虚拟机可以使用的数据结构。链接阶段主要包括以下三个步骤:
-
验证(Verification):验证类的字节码文件是否符合 Java 虚拟机规范。在验证阶段,Java 虚拟机会对类的字节码文件进行各种验证,以确保其符合 Java 虚拟机规范。例如,Java 虚拟机会检查类的字节码文件是否包含不合法的指令、是否存在不合法的类型转换等。
-
准备(Preparation):为类的静态变量分配内存,并设置默认值。在准备阶段,Java 虚拟机会为类的静态变量分配内存,并设置默认值。例如,对于一个
int类型的静态变量,Java 虚拟机会为其分配 4 个字节的内存,并将其默认值设置为 0。 -
解析(Resolution):将类的符号引用转换为直接引用。在解析阶段,Java 虚拟机会将类的符号引用转换为直接引用。例如,Java 虚拟机会将类的全限定名转换为内存地址,以便在运行时快速访问类的方法和变量。
-
-
初始化(Initialization):为类的静态变量赋值,并执行静态代码块。在初始化阶段,Java 虚拟机会为类的静态变量赋值,并执行静态代码块。例如,对于一个
static代码块,Java 虚拟机会在类加载时执行该代码块,并将其中的静态变量赋值。
需要注意的是,类加载过程是一个递归的过程。当一个类被加载时,它所依赖的其他类也会被加载,并按照类的依赖关系进行初始化。同时,Java 虚拟机还提供了一些机制,例如类加载器、双亲委派模型等,来保证类的加载过程的安全性和可靠性。
2.static和final变量的初始化时机
初始化阶段,简言之,为类的静态变量赋予正确的初始值。(显式初始化)
具体描述
类的初始化是类装载的最后一个阶段。如果前面的步骤都没有问题,那么表示类可以顺利装载到系统中。此时,类才会开始执行Java字节码。(即:到了初始化阶段,才真正开始执行类中定义的 Java 程序代码。)
初始化阶段的重要工作是执行类的初始化方法:<clinit>()方法。
- 该方法仅能由Java编译器生成并由JVM调用,程序开发者无法自定义一个同名的方法,更无法直接在Java程序中调用该方法,虽然该方法也是由字节码指令所组成。
- 它是由类静态成员的赋值语句以及static语句块合并产生的。

子类加载前先加载父类?
在加载一个类之前,虚拟机总是会试图加载该类的父类,因此父类的 < clinit >总是在子类< clinit >之前被调用。也就是说,父类的static块优先级高于子类。
口诀:由父及子,静态先行。
哪些类不会生成方法?
- 一个类中并没有声明任何的类变量,也没有静态代码块时
- 一个类中声明类变量,但是没有明确使用类变量的初始化语句以及静态代码块来执行初始化操作时
- 一个类中包含static final修饰的基本数据类型的字段,这些类字段初始化语句采用编译时常量表达式

代码举例:static与final的搭配问题
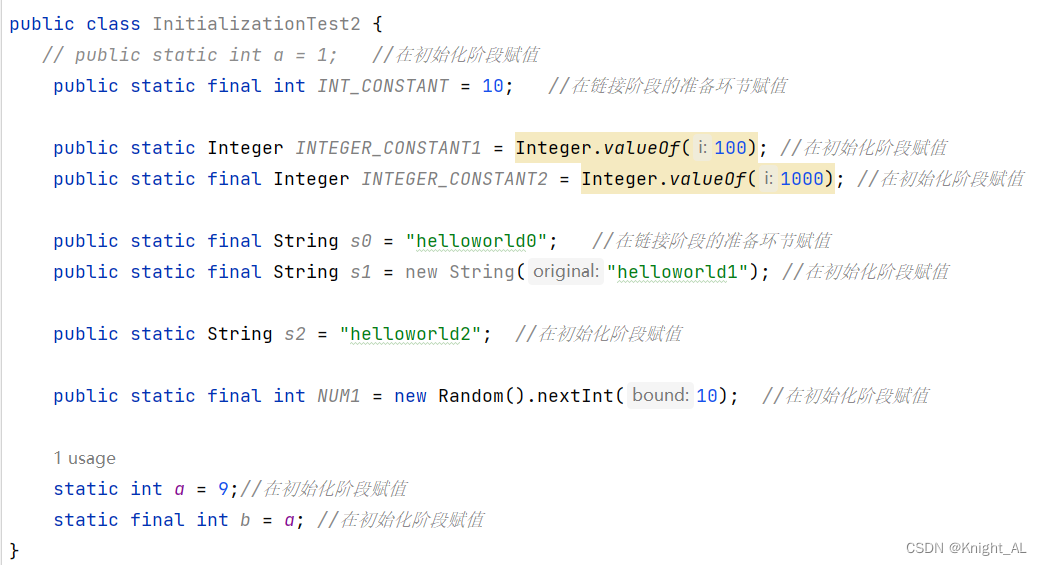
* 总结:
* 使用static + final 修饰的成员变量,称为:全局常量。
* 什么时候在链接阶段的准备环节:给此全局常量附的值是字面量或常量。不涉及到方法或构造器的调用。
* 除此之外,都是在初始化环节赋值的。
二、依赖
1.Spring Boot 自动装配
@SpringBootApplication 是一个组合注解,它包含了 @Configuration、@EnableAutoConfiguration 和 @ComponentScan 这三个注解的功能。它的作用是标识一个 Spring Boot 应用的主类,用于启动 Spring Boot 应用程序。
- @SpringBootConfiguration 注解表示该类是一个配置类,它会被 Spring IOC 容器用来生成 Bean 定义。
- @ComponentScan 注解表示扫描指定的包及其子包下的所有组件用于定义 Spring 的扫描路径,等价于在 xml 文件中配置 <context:component-scan > ,假如不配置扫描路径,那么 Spring 就会默认扫描当前类所在的包及其子包中的所有标注了 @Component , @Service , @Controller 等注解的类。,将它们注册到 Spring IOC 容器中。
- @EnableAutoConfiguration 注解表示开启自动配置,Spring Boot 会根据项目中的依赖自动配置应用程序。
这个注解才是实现自动装配的关键,点进去之后发现,它是一个由 @AutoConfigurationPackage 和 @Import 注解组成的复合注解。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
看起来很多注解,实际上关键在 @Import 注解,它会加载
AutoConfigurationImportSelector 类,然后就会触发这个类的 selectImports() 方法。根据返回的 String 数组(配置类的 Class 的名称)加载配置类。
我们重点看下
AutoConfigurationImportSelector 。
AutoConfigurationImportSelector中的selectImport是自动装配的核心实现,它主要是读取META-INF/spring.factories文件,经过去重、过滤,返回需要装配的配置类集合。
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
我们点进 getAutoConfigurationEntry() 方法:
- getAttributes 获取 @EnableAutoConfiguration 中的 exclude 、 excludeName 等。
- getCandidateConfigurations 获取所有自动装配的配置类,也就是读取 - spring.factories 文件,后面会再次说明。
- removeDuplicates 去除重复的配置项。
- getExclusions 根据 @EnableAutoConfiguration 中的 exclude 、 - excludeName 移除不需要的配置类。
- fireAutoConfigurationImportEvents 广播事件。
最后根据多次过滤、判重返回配置类合集。
现在我们结合 getAutoConfigurationEntry() 的源码来详细分析一下:
第 1 步:判断自动装配开关是否打开。
默认
spring.boot.enableautoconfiguration=true ,可在 application.properties 或 application.yml 中设置。
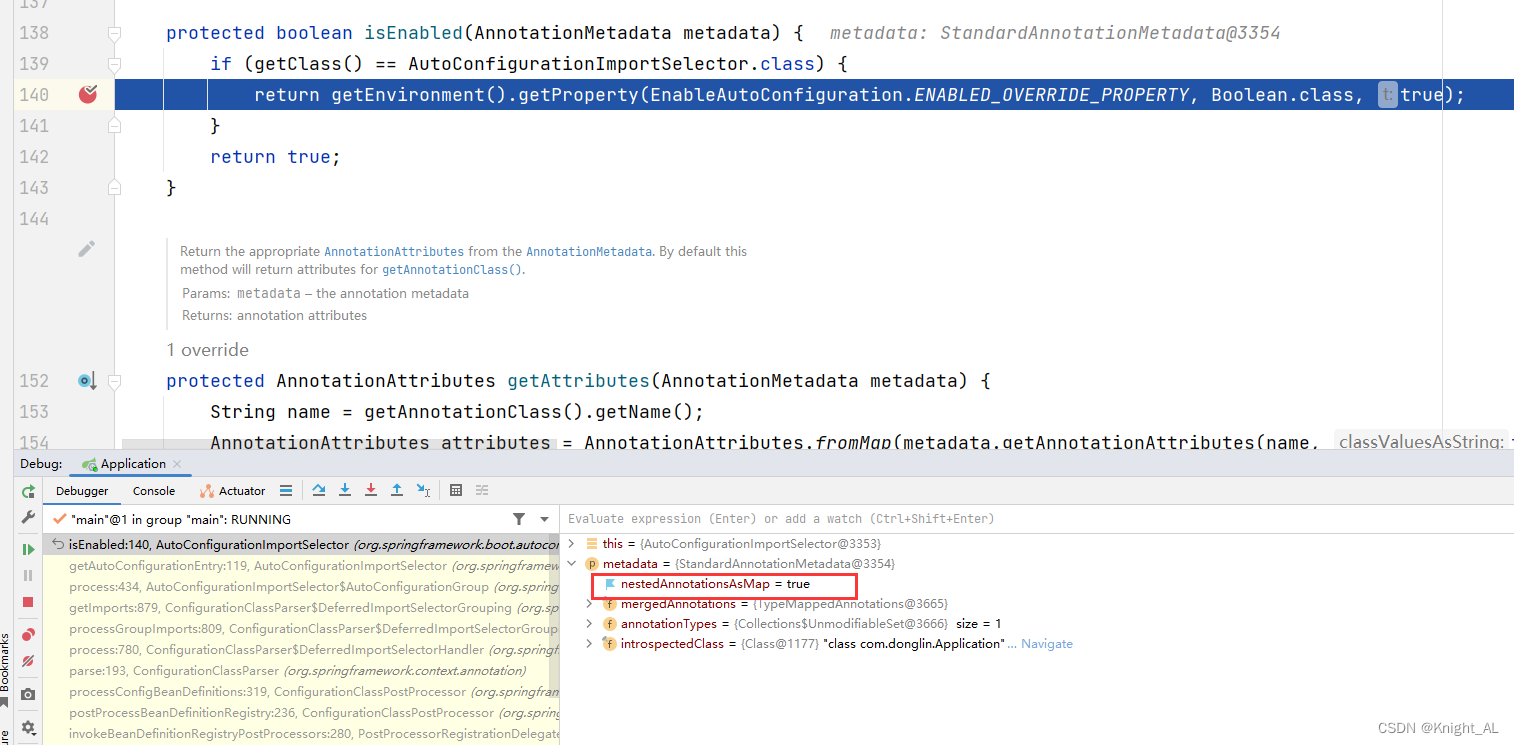
第 2 步 :
用于获取 EnableAutoConfiguration 注解中的 exclude 和 excludeName 。
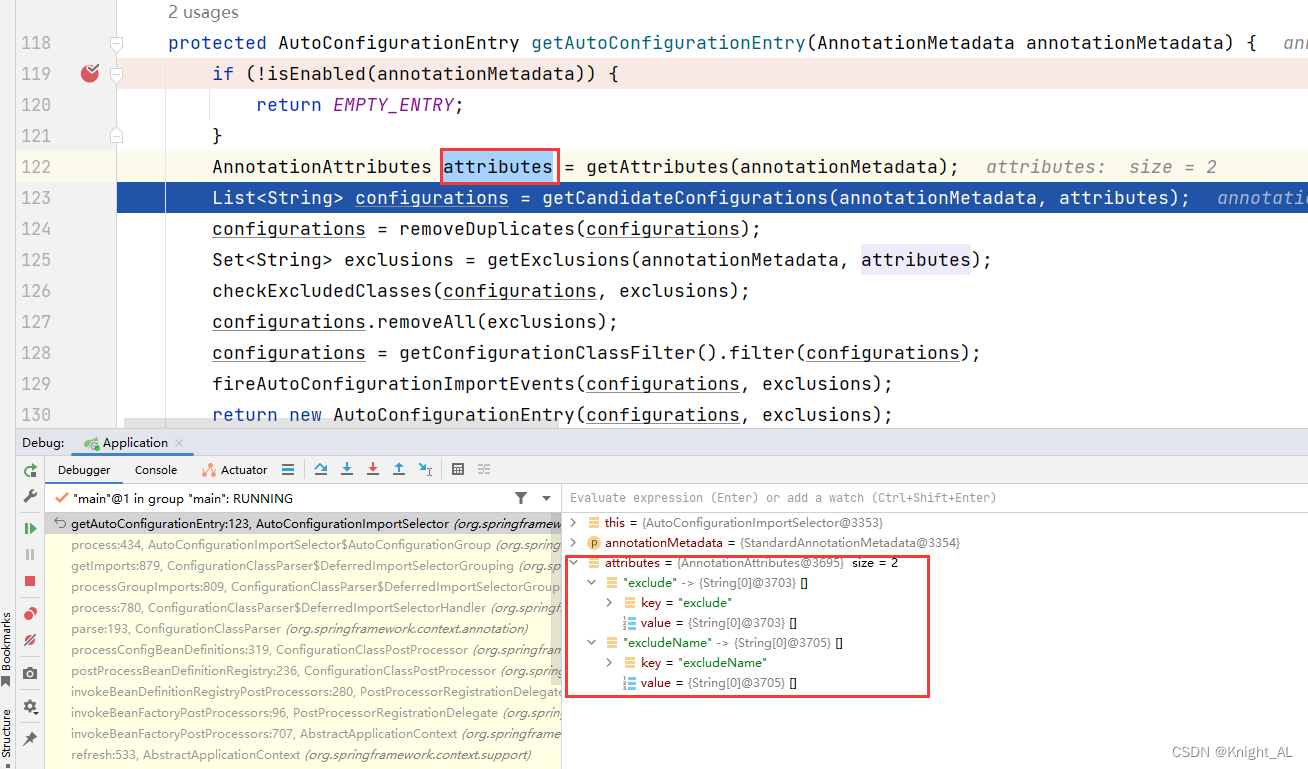
第 3 步:
获取需要自动装配的所有配置类,读取 META-INF/spring.factories 。

我们点进
getCandidateConfigurations() 方法:
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
获取候选配置了使用了 Spring Framework 自定义的 SPI 机制,使用 SpringFactoriesLoader#loadFactoryNames 加载了类路径下
/META-INF/spring.factories 文件中的配置类,里面是以 key/value 形式存储,其中一个 key 是 EnableAutoConfiguration 类的全类名,而它的 value 是一个以 AutoConfiguration 结尾的类名的列表。以 spring-boot-autoconfigure 模块为例,其 spring.factories 内容如下。
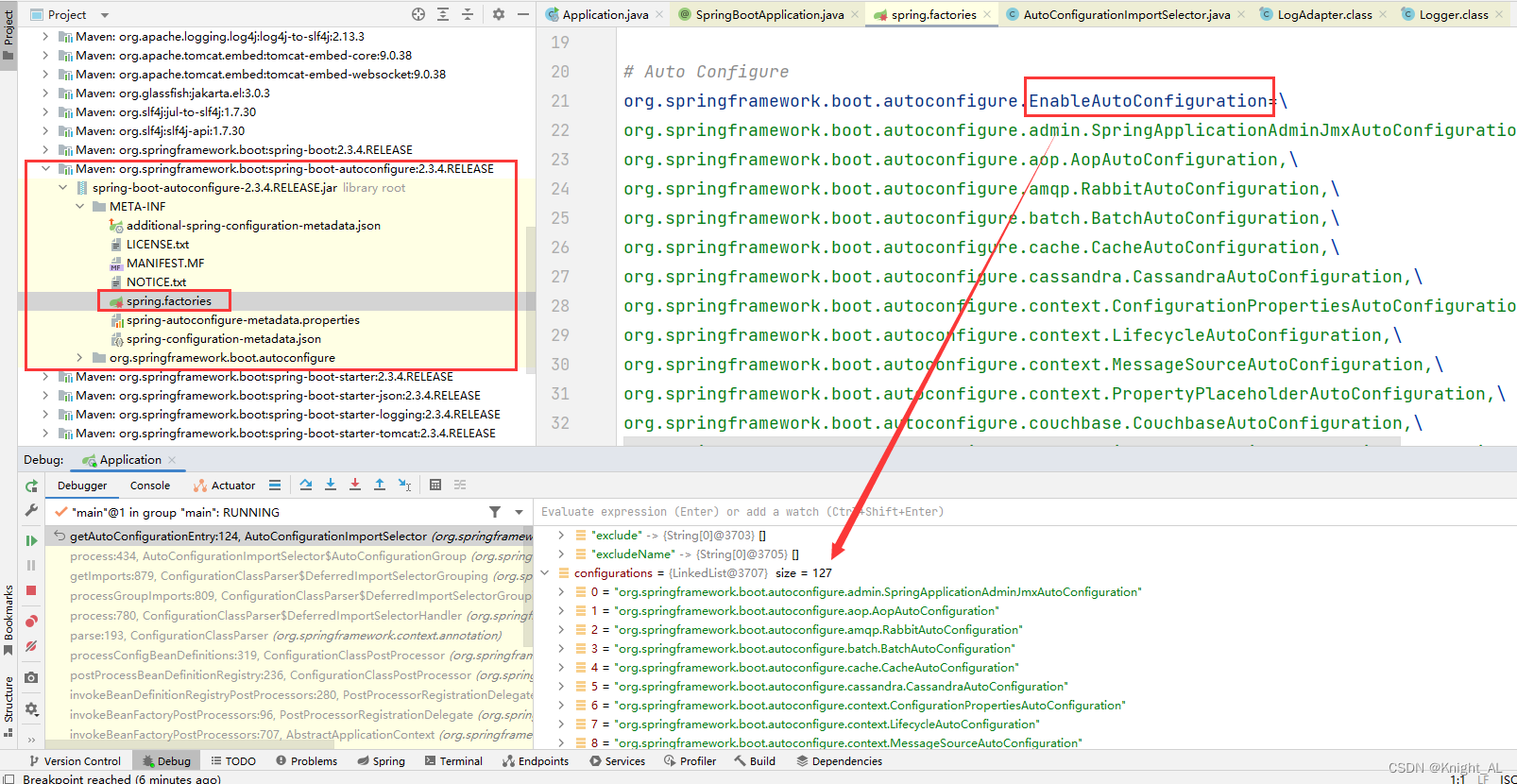
不光是这个依赖下的 META-INF/spring.factories 被读取到,所有 Spring Boot Starter 下的 META-INF/spring.factories 都会被读取到。
如果,我们自定义一个 Spring Boot Starter,就需要创建 META-INF/spring.factories 文件。
第 4 步 :
到这里可能面试官会问你:“ spring.factories 中这么多配置,每次启动都要全部加载么?”。
很明显,这是不现实的。我们 debug 到后面你会发现, configurations 的值变小了。
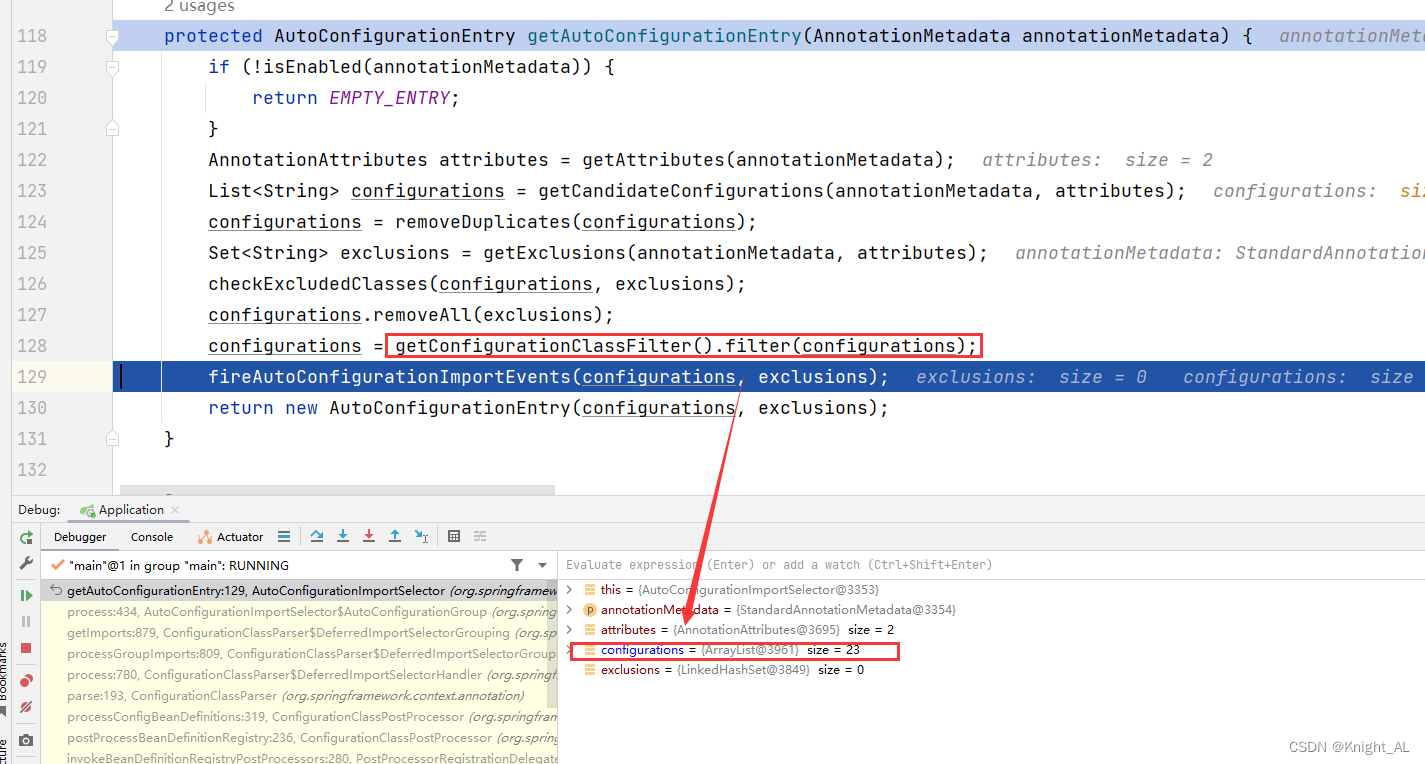
虽然 127 个全场景配置项的自动配置启动的时候默认全部加载。但实际经过后续处理后只剩下 23 个配置项真正加载进来。很明显,Spring Boot 只会加载实际你要用到的场景中的配置类。这是如何做到的了?
按需加载
这里我们分析剩下的 23 个自动配置类,观察到每一个自动配置类都有着 @Conditional 或者其派生条件注解。
@ConditionalOnBean:当容器里有指定 Bean 的条件下
@ConditionalOnMissingBean:当容器里没有指定 Bean 的情况下
@ConditionalOnSingleCandidate:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean
@ConditionalOnClass:当类路径下有指定类的条件下
@ConditionalOnMissingClass:当类路径下没有指定类的条件下
@ConditionalOnProperty:指定的属性是否有指定的值
@ConditionalOnResource:类路径是否有指定的值
@ConditionalOnExpression:基于 SpEL 表达式作为判断条件
@ConditionalOnJava:基于 Java 版本作为判断条件
@ConditionalOnJndi:在 JNDI 存在的条件下差在指定的位置
@ConditionalOnNotWebApplication:当前项目不是 Web 项目的条件下
@ConditionalOnWebApplication:当前项目是 Web 项 目的条件下
@Configuration(
proxyBeanMethods = false
)
// 检查是否有该类才会进行加载
@ConditionalOnClass({
RedisOperations.class})
// 绑定默认配置信息
@EnableConfigurationProperties({
RedisProperties.class})
@Import({
LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class})
public class RedisAutoConfiguration {
public RedisAutoConfiguration() {
}
...
}
所以当 classpath 下存在某一个 Class 时,某个配置才会生效。
上面所有的注解都在做一件事:注册 bean 到 Spring 容器。他们通过不同的条件不同的方式来完成:
@SpringBootConfiguration 通过与 @Bean 结合完成 Bean 的 JavaConfig 配置;
- @ComponentScan 通过范围扫描的方式,扫描特定注解注释的类,将其注册到 Spring 容器;
- @EnableAutoConfiguration 通过 spring.factories 的配置,并结合 @Condition 条件,完成bean的注册;
- @Import 通过导入的方式,将指定的 class 注册解析到 Spring 容器;
我们在这里画张图把 @SpringBootApplication 注解包含的几个注解分别解释一下。
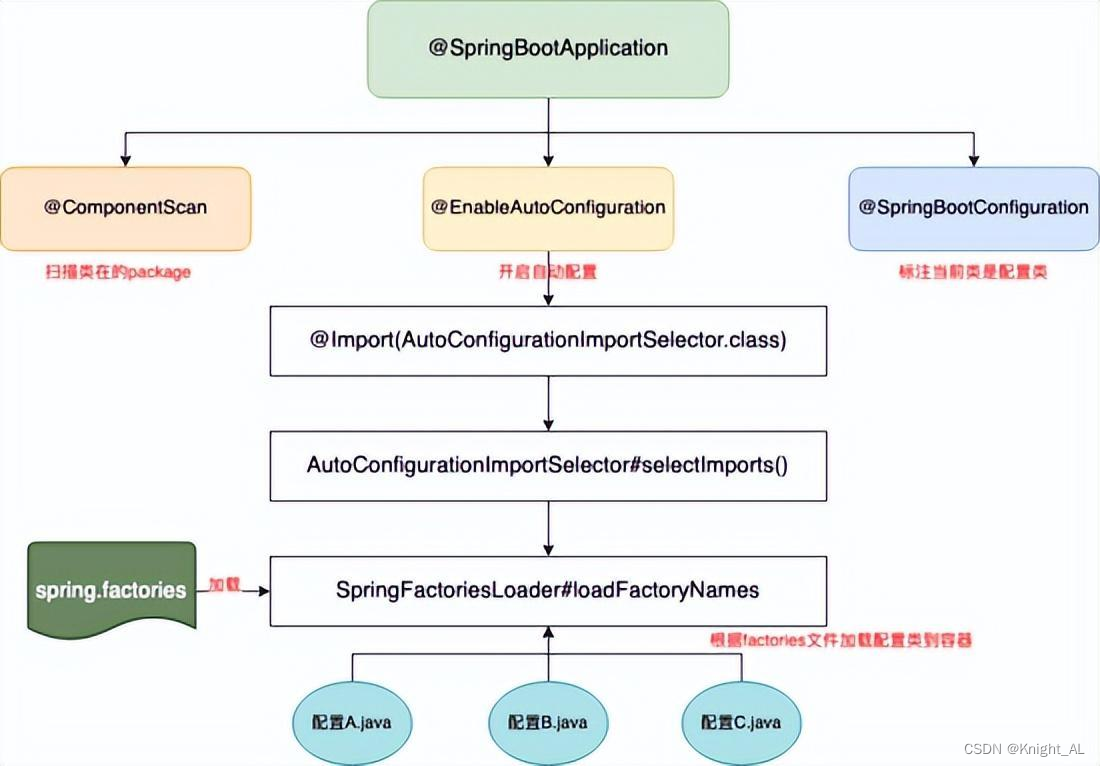
Spring Boot 通过 @EnableAutoConfiguration 开启自动装配,通过 SpringFactoriesLoader 最终加载 META-INF/spring.factories 中的自动配置类实现自动装配,自动配置类其实就是通过 @Conditional 按需加载的配置类,想要其生效必须引入 spring-boot-starter-xxx 包实现起步依赖。
2.使用依赖过程中遇到问题如何排查
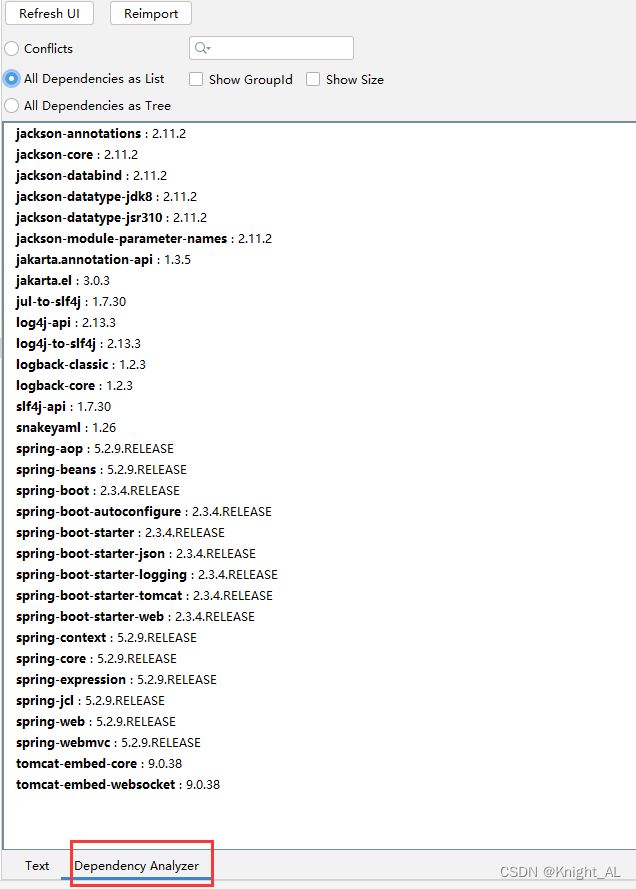
1.使用idea自带的依赖树:使用依赖管理工具(例如 Maven、Gradle 等)可以查看项目的依赖树,以便了解项目中使用的依赖及其版本。通过查看依赖树,可以发现依赖冲突、依赖版本不兼容等问题。
(快捷键ctrl+shift+alt+u)
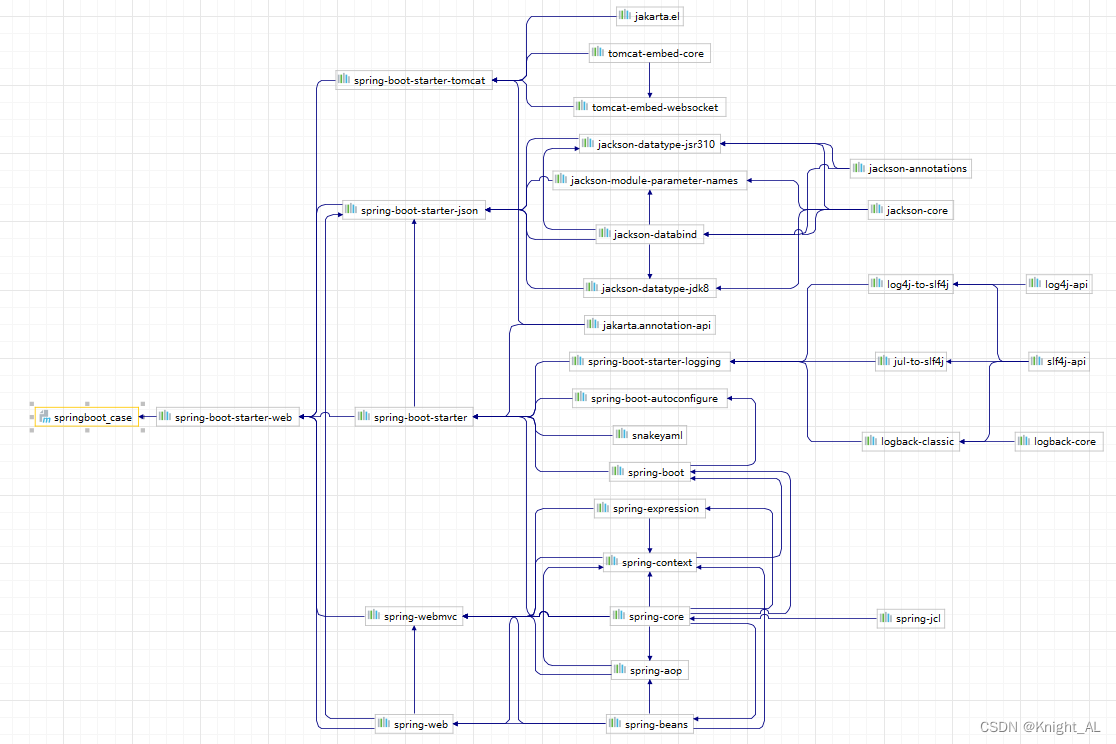
2.使用idea商城中的插件maven helper

3.引入的某个依赖不符合预期,如何处理
最短路径优先原则
依赖链路一:主要根据依赖的路径长短来决定引入哪个依赖(两个冲突的依赖)。
举例说明:
依赖链路一:A -> X -> Y -> Z(21.0)
依赖链路二:B -> Q -> Z(20.0)
项目中同时引入了A和B两个依赖,它们间接都引入了Z依赖,但由于B的依赖链路比较短,因此最终生效的是Z(20.0)版本。这就是最短路径优先原则。
此时如果Z的21.0版本和20.0版本区别较大,那么就会发生Jar包冲突的表现。
最先声明优先原则
如果两个依赖的路径一样,最短路径优先原则是无法进行判断的,此时需要使用最先声明优先原则,也就是说,谁的声明在前则优先选择。
举例说明:
依赖链路一:A -> X -> Z(21.0)
依赖链路二:B -> Q -> Z(20.0)
A和B最终都依赖Z,此时A的声明(pom中引入的顺序)优先于B,则针对冲突的Z会优先引入Z(21.0)。
如果Z(21.0)向下兼容Z(20.0),则不会出现Jar包冲突问题。但如果将B声明放前面,则有可能会发生Jar包冲突。
三、数据库:
1.InnoDB 和 MyISAM 索引的区别
外键 事务 锁
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 关注点 | 并发查询,节省资源、消耗少、简单业务 | 并发写、事务、多表关系、更大资源 |
| 默认安装 | Y | Y |
| 默认使用 | N | Y |
| 自带系统表使用 | Y | N |
2.字符串类型字段,WHERE 数字,会走索引吗?数值型字段,WHERE 字符串,会走索引吗?
字符串类型字段,WHERE 数字,会走索引吗?不会
数值型字段,WHERE 字符串,会走索引吗?会
- 当索引字段是字符串类型,输入参数是数值类型时,会将字段转换成数值类型再进行查找,也就是对索引字段做了函数操作,破坏了索引的有序性,因此无法使用索引。
- 当索引字段是数值类型,输参数是字符串类型时,会将输入参数转换成数值类型再进行查找,对等号后面的输入参数进行函数操作,并不影响索引字段的有序性,因此可以使用索引。
3.针对 RR 级别提问
RR 级别并不能完全避免幻读问题。幻读是指在一个事务中,多次执行同一个查询语句,但是每次查询的结果集都不同。在 RR 级别下,虽然可以避免不可重复读问题,但是无法避免幻读问题。
4.间隙锁,什么时候触发
唯一索引等值查询:
1.当查询的记录是存在的,next-key lock 会退化成「记录锁」。
2.当查询的记录是不存在的,next-key lock 会退化成「间隙锁」。
非唯一索引等值查询:
1.当查询的记录存在时,除了会加 next-key lock 外,还额外加间隙锁,也就是会加两把锁。
2.当查询的记录不存在时,只会加 next-key lock,然后会退化为间隙锁,也就是只会加一把锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
唯一索引在满足一些条件的时候,next-key lock 退化为间隙锁和记录锁。
非唯一索引范围查询,next-key lock 不会退化为间隙锁和记录锁。
5.假设一台线上服务器只放了 MySQL 数据库,突发告警(CPU、内存等),如何排查
排查过程:
使用top 命令观察,确定是mysqld导致还是其他原因。
如果是mysqld导致的,使用 show processlist 命令可以查看当前 MySQL 实例中正在执行的所有线程(也称为 session)的状态信息,确定是不是有消耗资源的sql在运行。找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
kill 掉这些线程(同时观察 cpu 使用率是否下降),
进行相应的调整(比如说加索引、改 sql、改内存参数)
重新跑这些 SQL。
其他情况:
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
6.慢 SQL 如何排查,除了慢查询日志还有什么方式
开启慢查询
set global slow_query_log=1
设置慢查询的时间
SET GLOBAL long_query_time=0.1;
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
使用mysqldumpslow去分析,查找sql,然后在使用explain进行分析

排查思路
- 第1个原因:没有索引或者 导致索引失效。
- 第2个原因:单表数据量数据过多,导致查询瓶颈
- 第3个原因:网络原因或者机器负载过高。
- 第4个原因:热点数据导致单点负载不均衡。
除了慢查询日志还有什么方式
除了慢查询日志,还有一些其他的方式可以帮助我们识别和优化 MySQL 中的慢查询,包括:
-
使用 MySQL 自带的性能分析工具:MySQL 自带了一些能分析工具,如 EXPLAIN、SHOW PROFILE、SHOW STATUS 等,可以帮助我们分析 SQL 查询语句的执行计划、性能瓶颈等信息。
-
使用第三方性能分析工具:除了 MySQL 自带的工具,还有一些第三方的性能分析工具,如 Prometheus . Skywalking等,可以帮助我们分析慢查询日志,找出慢查询的原因和优化建议。
-
使用 MySQL 监控工具:MySQL 监控工具可以帮助我们实时监控 MySQL 实例的性能指标,如 CPU 使用率、内存使用率、磁盘 I/O 等,从而帮助我们及时发现性能问题(MySQL Enterprise Monitor,Zabbix)。