本专栏介绍基于深度学习进行图像识别的经典和前沿模型,将持续更新,包括不仅限于:AlexNet, ZFNet,VGG,GoogLeNet,ResNet,DenseNet,SENet,MobileNet,ShuffleNet,EifficientNet,Vision Transformer,Swin Transformer,Visual Attention Network,ConvNeXt, MLP-Mixer,As-MLP,ConvMixer,MetaFormer
ZFNet 文章目录
- 前言
- 1. ZFNet简介
- 2. 对卷积计算结果(feature maps)的可视化
- 3. 网络中对不同特征的学习速度
- 4. 图片平移,缩放,旋转对CNN的影响
- 5. ZFNet的改进点
- 6. 遮挡对卷积模型的影响
- 7. ZFNet的调参实验
- ZFNet实现代码
- 小结
前言
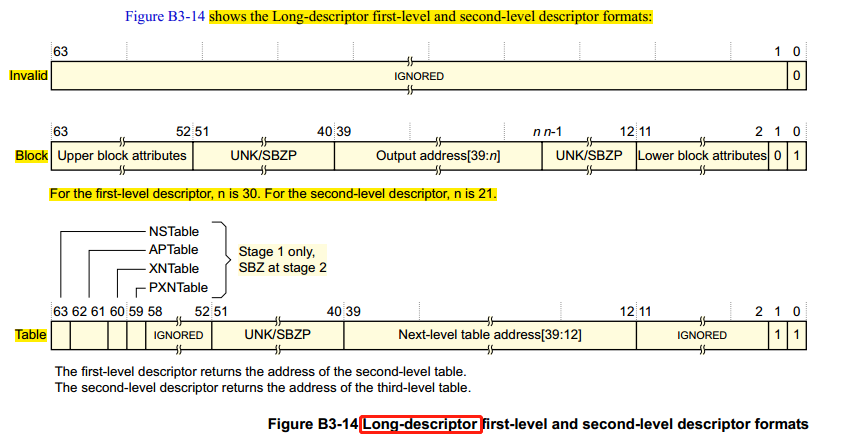
ZFNet在2013年 ILSVRC 图像分类竞赛获得冠军,错误率11.19% ,比去年的AlexNet降低了5%,ZFNet是由 Matthew D.Zeiler 和 Rob Fergus 在 AlexNet 基础上提出的大型卷积网络。ZFNet解释了为什么卷积神经网络可以在图像分类上表现的如此出色,以及研究了如何优化卷积神经网络。ZFNet提出了一种可视化的技术,通过可视化,我们就可以了解卷积神经网络中间层的功能和分类器的操作,这样就就可以找到较好的模型。ZFNet还进行消融实验来研究模型中的每个组件,它会对模型有什么影响。
小tips: Zeiler和Fergus并没有给自己的网络起名字,所以后人为了方便将这个网络成为ZFNet。同学们如果不想让别人给自己的网络起名字,写论文的时候记得起个名字~
论文名称:Visualizing and Understanding Convolutional Networks
论文下载链接:https://arxiv.org/pdf/1311.2901
pytorch代码实现:https://github.com/Arwin-Yu/Deep-Learning-Classification-Models-Based-CNN-or-Attention
创作不易,引用或转载请标明出处。
1. ZFNet简介
ZFNet其实跟AlexNet很像很像, 首先是ZFNet改变了AlexNet的第一层,将卷积核的尺寸从11×11变为7×7,并将步长从4变为2。这一微小的修改就显著地改进了整个卷积神经网络的性能,使ZFNet在2013年ImageNet图像分类竞赛中获得了冠军。下面是ZFNet和AlexNet的详细网络参数:

除此之外,ZFNet最大的贡献是对卷积操作为什么对图像数据有效这个问题做出的一系列实验和解释。
2. 对卷积计算结果(feature maps)的可视化
一项重要的实验是将卷积核的计算结果映射回原始的像素空间(映射的方法为反卷积,反池化)并进行可视化。例如,以Layer 1为例,图5-8红框中左上角的九宫格代表第一层卷积计算得到的前九张特征图映射回原图像素空间后的可视化(称为F9)。第一层卷积使用96个卷积核,这意味着会得到96张特征图,这里的前九张特征图是指96个卷积核中值最大的9个卷积核对应生成的特征图(这里称这9个卷积核为K9,即,第一层卷积最关注的前九种特征)。可以发现,这九种特征都是颜色和纹理特征,即蕴含语义信息少的结构性特征。
为了证明这个观点,将数据集中的原始图像裁剪成小图,将所有的小图送进网络中,得到第一层卷积计算后的特征图。统计能使K9中每个卷积核输入计算结果最大的前9张输入小图,即9×9=81张,如图5-8红框中右下角所示。结果表明刚刚可视化的F9和这81张小图表征的特征是相似的,且一一对应的。由此证明卷积网络在第一层提取到的是一些颜色,纹理特征。

同理,观察Layer2和Layer3的可视化发现,第二次和第三次卷积提取到的特征蕴含的语义信息更丰富,不再是简单的颜色纹理信息,而是一些结构化的特征,例如蜂窝形状,圆形,矩形等等。那么网络的更深层呢?我们看下图:

在网络的深层,如第四层,第五层卷积提取到的是更高级的语义信息,如人脸特征,狗头特征,鸟腿鸟喙特征等等。
最后,越靠近输出端,能激活卷积核的输入图像相关性越少(尤其是空间相关性),例如Layer5中,最右上角的示例:feature map中表征的是一种绿色成片的特征,可是能激活这些特征的原图相关性却很低(原图是人,马,海边,公园等,语义上并不相干);其实这种绿色成片的特征是‘草地’,而这些语义不相干的图片里都有‘草地’。‘草地’是网络深层卷积核提取的是高级语义信息,不再是低级的像素信息,空间信息等等。
所以,总结一下:CNN输出的特征图有明显的层级区分。
越靠近输入端,提取的特征所蕴含的语义信息比较少,例如颜色特征,边缘特征,角点特征等等;
越靠近输出端,提取的特征所蕴含的语义信息越丰富,例如Layer4中的狗脸,鸟腿等,都属于目标级别的特征。
3. 网络中对不同特征的学习速度
如下图所示,横轴表示训练轮数,纵轴表示不同层的feature maps映射回像素空间后的可视化结果:

由此可能出,low-level的特征(颜色,纹理等)在网络训练的训练前期就可以学习到, 即更容易收敛;high-level的语义特征在网络训练的后期才会逐渐学到。 由此展示了不同特征的进化过程。这也是一个合理的过程,毕竟高级的语义特征,要在低级特征的基础上学习提取才能得到。
4. 图片平移,缩放,旋转对CNN的影响
下图是探究图片平移对卷积模型影响的实验,a1是五张不同的图片经过不同大小的左右平移后的结果。
a2是原始图片与经过平移后的图片分别送进卷积网络后,第一层卷积计算得到的feature maps之间的欧氏距离,可以看出当图片平移0个像素时(即图中横轴=0处),距离最小(等于0)。其他位置随着左右平移,得到的距离都会陡增或陡减。五条彩色曲线分别代表五张不同的原始图片。
a3是原始图片与经过平移后的图片分别送进卷积网络后,第七层卷积计算得到的feature maps之间的欧氏距离,可以看出趋势与a2类似;但是,增减的曲线变换更平缓,这一定程度上说明了网络的深层提取的是高级语义特征,而不是低级的颜色,纹理,空间特征。这种语义信息不会随着平移操作而轻易改变,例如狗的图片平移后还是狗。
这个性质叫做:卷积拥有良好的平移不变性。
最后,a3表示的是原始图片与经过平移后的图片分别送进卷积网络后,卷积网络最后是识别结果。可以看出识别准确率是相对平稳的,且在横轴x=0时,识别准确率较高(此时,图片不平移,识别物体基本在图片中心位置)

下图探究图片缩放对卷积模型影响的实验,实验方法和表述与上面探讨平移时的设置类似,这里不做重复赘述。结果表明,网络的浅层相较于网络的深层对缩放操作更敏感;且最终的识别准确率较平稳。这个趋势跟探究平移操作对卷积模型影响的趋势类似,即:卷积操作也具有良好的缩放不变性。

下图是探究图片旋转对卷积模型影响的实验,可以看出旋转操作对卷积的影响正好与平移和缩放相反:卷积第一层对旋转的敏感程度较低,第七层对旋转的敏感程度高。这是因为颜色,纹理这些低级特征旋转前后还是相似的特征;但是目标级别的高级语义特征却不行,例如“特征9”旋转180°后变成了“特征6”. 看最终的识别准确率曲线也能发现旋转0°和350°时模型的识别准确率最高,因为此时旋转后模型最接近原始图片。对于某些存在对称性质的特征,例如原图中的电视,在旋转90°,180°,270°时都有不错的识别准确率。因此,卷积操作不具有良好的缩放不变性。

个人认为,究其原因:卷积的平移不变性是从滑动遍历这个操作带来的,不管一个特征出现在图中的什么位置,卷积核都可以通过滑动的方式,滑动到特征上面做识别。而缩放不变性则是从网络的层级结构中获得,不同层的卷积操作拥有不同尺寸的计算感受野 。至于旋转不变性缺失找不到对应的操作。那么,为什么现在的一些成熟项目,例如人脸识别,图像分类等依然可以对旋转的图片做识别呢? 这是因为我们用大量的训练数据,旋转不变性可以从大量的训练数据中得到。其实,不仅是旋转不变性,卷积本身计算方法带来的平移不变性和缩放不变性也是脆弱的,大部分也是从数据集中学习到的。记住,深度学习是一种基于数据驱动的算法。
5. ZFNet的改进点
ZFNet通过对AelxNet可视化发现,由于第一层的卷积核尺寸过大导致某些特征图失效(失效指的是一些值太大或太小的情况,容易引起网络的数值不稳定性,进而导致梯度消失或爆炸。图中的体现是(a)中的黑白像素块)。
此外,由于第一层的步长过大,导致第二层卷积结果出现棋盘状的伪影(例如(b)中第二小图和倒数第三小图)。因此ZFNet做了对应的改进。即将第一层 11X11步长为4的卷积操作变成 7X7步长为2的卷积。

6. 遮挡对卷积模型的影响
ZFNet通过对原始图像进行矩形遮挡来探究其影响,如下图所示
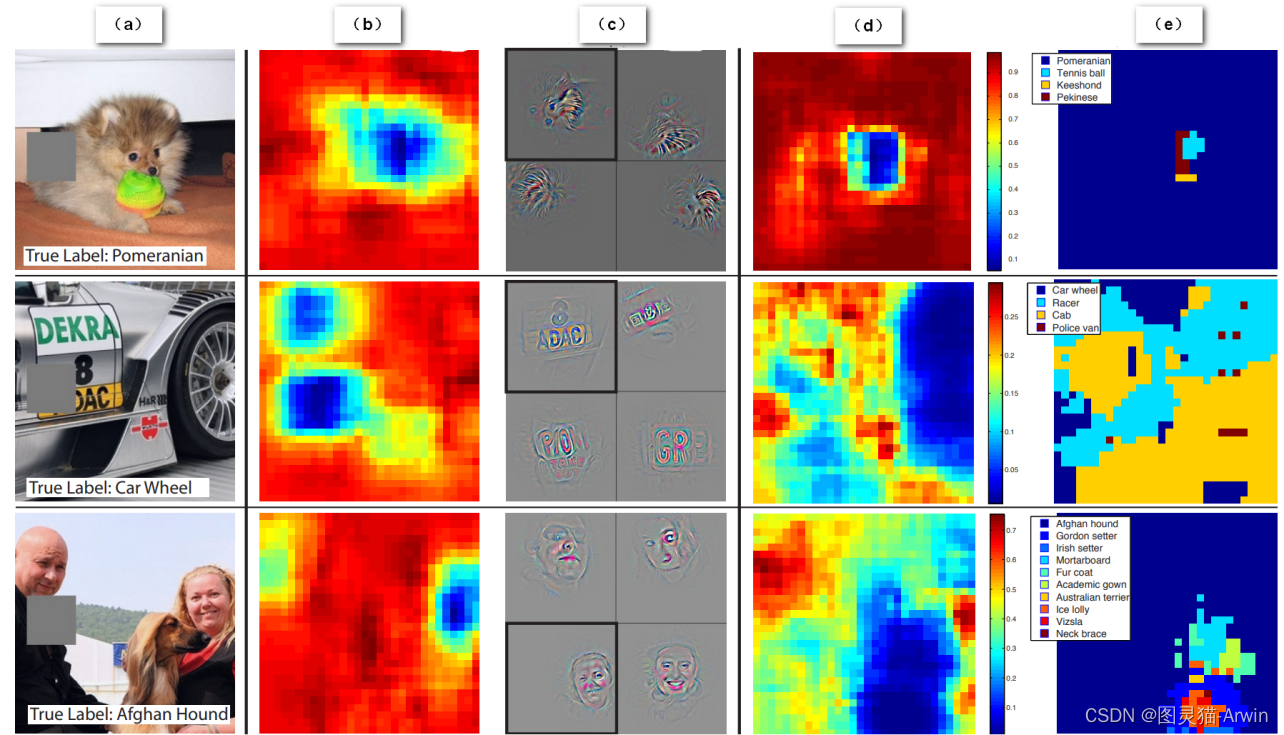
b表示计算遮挡后的图像经过第五个卷积层后得到的feature map 值的总和。红色代表更大的值。 由此可以看出来卷积计算后的特征图也是保留了原始数据中不同类别对象在图像中的空间信息。
c左上角的小图是经过第五个卷积后值最大的特征图的deconv可视化结果。由此实例2(可视化结果为英文字母或汉字,但是原图标签的“车轮”)可以看出卷积后值最大的特征图不一定是对分类最有作用的。c中的其他小图是统计数据集中其他图像可以使该卷积核输出最大特征图的deconv可视化结果。
d表示灰色滑块所遮挡的位置对图像正确分类的影响,红色代表分类成功的可能性大。例如博美犬的图像,当灰色滑块遮挡到博美犬的面部时,模型对博美犬的识别准确率大幅度下降。
e表示模型对遮挡后的图像的分类结果是什么。还拿博美犬的例子,灰色遮挡在图片中非狗脸的位置时,都不影响模型将其正确分类为博美犬(大部分都是蓝色标签,除了遮挡滑动到狗脸位置时)。
这个遮挡实验证明,模型确实可以理解图片,找到语义信息最丰富,对识别最关键的特征;而不是仅仅依靠一些颜色,纹理特征去做识别。
此外,模型还做了进一步的遮挡实验来证明卷积可以提取到高级的语义特征,如下图所示:

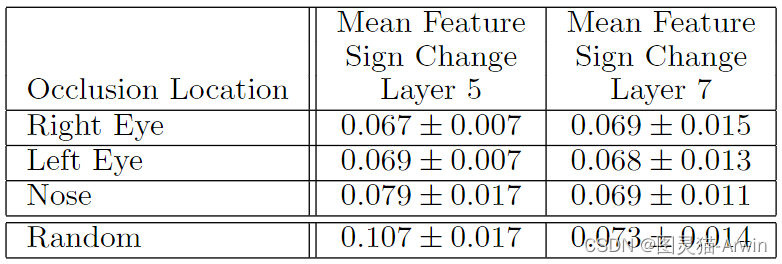
通过遮挡图像的不同部位来证明CNN在处理图像的时候是关注局部的高级语义特征,而不是根据图像的全部信息来处理。
例如第二列遮挡左眼,表中的结果是求这五种不同狗 Dpair 的Hamming distance之和,即:Dpair是原图和遮挡图,Hamming distance是分别送进CNN中得到的feature map的差值之和。
数值越小表面遮挡左眼这个操作对不同种类的狗起到的作用是差不多的。
表中随机遮挡的结果(最后一列)明显大于有规律的遮挡,因此反应了CNN确实隐式对不同类别的同种特征做了学习总结。
值得注意的是,Layer7的随机遮挡结果明显小于Layer5,这说明深层的网络提取的是语义信息(例如狗的类属),而不是low-level的空间特征。因此对随机遮挡可以不敏感。
7. ZFNet的调参实验
讲到这里,ZFNet的实验结果其实已经不重要了。其巧妙的实验设计,从各个方面深入探究了卷积操作对图像的有效性以及如何有效实施,这足以证明ZFNet模型的优秀性。为了遵守原论文的科学严谨性,我们还是给出实验结果。如下图所示:
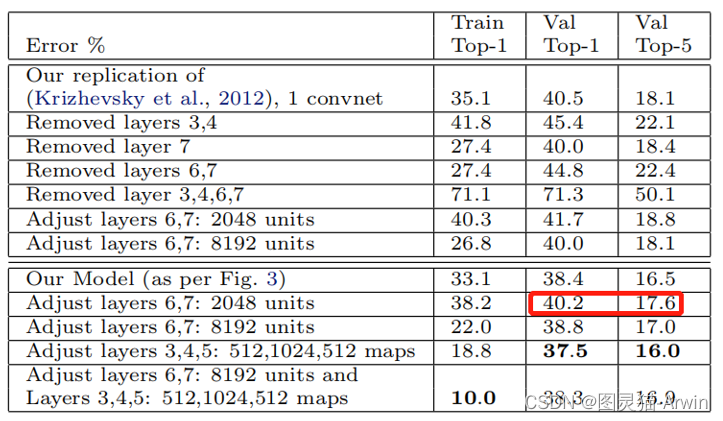
ZFNet对AelxNet进行了针对调参的消融实验。值得注意的是减少全连接层的参数反而可以提升一点准确率,一定程度证明了全连接层的参数还是太冗余了,即使有dropout。
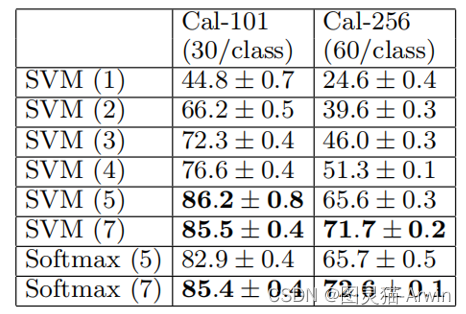
最后,作者将不同层得到的feature maps直接送进分类器中分类,结果表面越深层的CNN提取到的feature maps对图像的分类帮助越大。结果如下图所示:
ZFNet实现代码
这里给出模型搭建的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub: 完整代码链接
ps:里面还有其他经典模型的代码复现,希望对大家有用
import torch.nn as nn
import torch
# 与AlexNet有两处不同: 1. 第一次的卷积核变小,步幅减小。 2. 第3,4,5层的卷积核数量增加了。
class ZFNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(ZFNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2, padding=2), # input[3, 224, 224] output[96, 111, 111]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[96, 55, 55]
nn.Conv2d(96, 256, kernel_size=5, padding=2), # output[256, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256, 27, 27]
nn.Conv2d(256, 512, kernel_size=3, padding=1), # output[512, 27, 27]
nn.ReLU(inplace=True),
nn.Conv2d(512, 1024, kernel_size=3, padding=1), # output[1024, 27, 27]
nn.ReLU(inplace=True),
nn.Conv2d(1024, 512, kernel_size=3, padding=1), # output[512, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[512, 13, 13]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512 * 13 * 13, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def zfnet(num_classes):
model = ZFNet(num_classes=num_classes)
return model
小结
ZFNet模型是一个基于卷积神经网络的图像分类模型,由Matthew D. Zeiler和Rob Fergus于2013年提出,旨在改进AlexNet模型并提高其分类性能。改进主要包括以下几个方面。
- 更小的卷积核:AlexNet采用的卷积核尺寸为11×11,而ZFNet将卷积核尺寸缩小到7×7,使得模型更加适合处理高分辨率的图像。
- 更深的网络结构:ZFNet比AlexNet多了一层卷积层和一层全连接层,共有8层。这样可以提高网络的表达能力和分类性能。
- 特征可视化:ZFNet通过对网络中的特征进行可视化,帮助人们理解网络中不同层次的特征所表达的语义含义。
- ZFNet同样采用了ReLU作为激活函数,并使用Dropout技术进行正则化。此外,ZFNet还使用了数据增强技术,包括随机裁剪、随机水平翻转等,增加了训练数据的多样性。
在ImageNet图像分类竞赛中,ZFNet在Top-5准确率上取得了15.4%的成绩,比AlexNet提高了4%左右,表现出了更好的模型性能。