文章目录
- Momentum Contrastive Voxel-Wise Representation Learning for Semi-supervised Volumetric Medical Image Segmentation
- 摘要
- 本文方法
- Voxel-Wise Contrastive Objective
- Dimensional Contrastive Objective
- Consistency Loss
- 总损失
- 实验结果
Momentum Contrastive Voxel-Wise Representation Learning for Semi-supervised Volumetric Medical Image Segmentation
摘要
对比学习(CL)旨在学习医学图像分割中不依赖专家注释的有用表示。现有的方法主要通过简单地将所有输入特征映射到相同的恒定向量中,将单个正向量(即,同一图像的增强)与批次的整个剩余部分内的一组负向量进行对比。尽管这些方法具有令人印象深刻的经验性能,但仍存在以下缺点:
(1)防止问题崩溃为琐碎的解决方案仍然是一个艰巨的挑战;
(2)并非同一图像内的所有体素都是相同的正例的,因为在同一图像中存在不同的解剖结构。
本文方法
提出了一种新的对比体素表示学习(CVRL)方法,通过捕捉三维空间上下文和沿特征和批次维度的丰富解剖信息,有效地学习低级和高级特征。具体来说,我们首先引入了一种新的CL策略,以确保在3D表示维度之间的特征多样性提升。我们通过对3D图像进行双层对比优化(即低层和高层)来训练框架。在两个基准数据集和不同标记设置上的实验证明了我们提出的框架的优越性。更重要的是,我们还证明了我们的方法继承了标准CL方法的硬度感知特性的优点。
本文方法
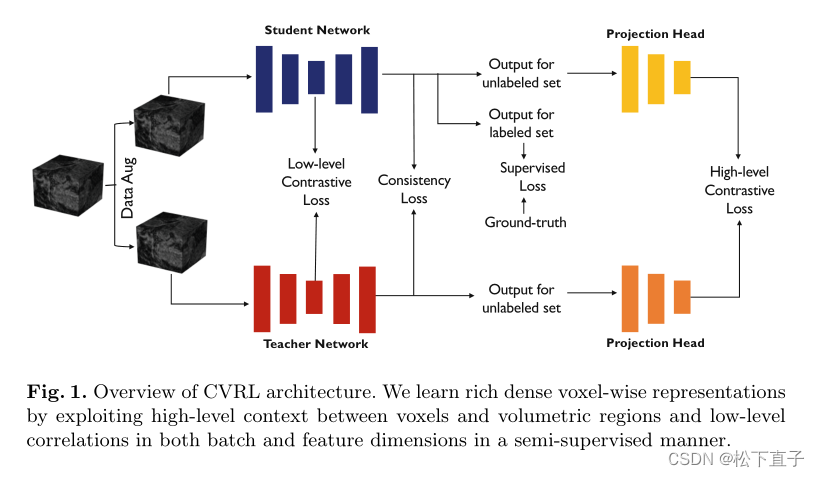
CVRL基于GCL,并遵循其最重要的组成部分,如数据扩充。我们的目标是学习更强的视觉表示,避免崩溃,以提高有限注释临床场景的整体分割质量。在有限的注释设置中,我们将半监督CVRL与两个组成部分——监督和非监督学习目标一起训练。具体而言,我们提出了一种新的体素表示学习算法,通过正则化嵌入空间和探索训练体素的几何和空间上下文,从3D未标记数据中学习低级和高级表示
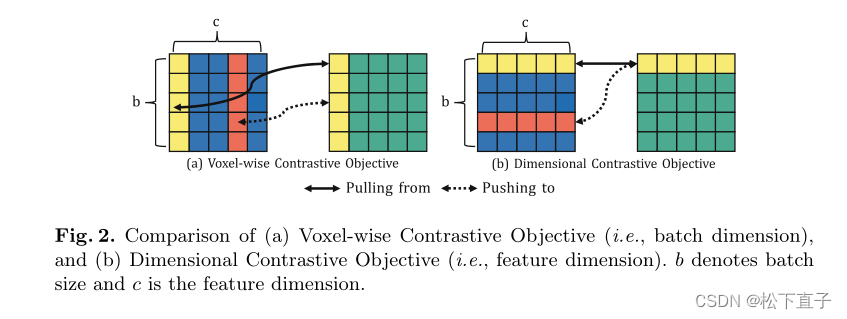
Voxel-Wise Contrastive Objective
使用标准的对比学习,我们鼓励特征提取器产生在数据增强下不变的表示。另一方面,特征仍应保持局部性:特征体积中的不同体素应包含其唯一信息。
具体来说,当学习的特征体积被划分为切片时,我们将来自同一图像的两个增强的体素对拉得更近;

为了获得体素对比损失,我们对由小批量学生特征体积中的所有特征体素组成的查询体素集合Qv取平均值:
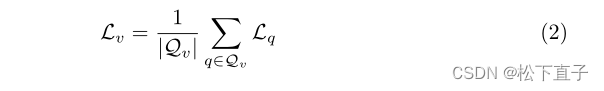
Dimensional Contrastive Objective
受对比学习中维度崩溃的最新发现的启发,我们提出了一个维度对比目标,以鼓励特征体素中的不同维度/通道包含不同的信息。给定一批形状为b×h×w×d×c的学生特征体积,我们将前4个维度分组以获得一组维度查询:q∈Qd⊂R(b×h x w×d),其中|Qd|=c,特征体积中的通道数。我们以相同的方式定义K={K+}ŞK−,但使用来自教师编码器的相应批处理特征量。在维度对比设置中,k+被定义为与查询q对应的相同特征维度的关键向量。维度对比损失是所有查询维度的平均值:
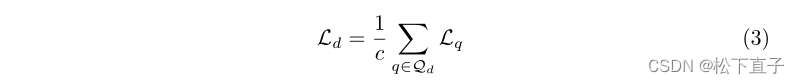
Consistency Loss
在网络参数上使用指数移动平均(EMA)可以提高训练稳定性和模型的最终性能。有了这一见解,我们引入了一个EMA教师模型,其中参数θ作为参数θ的移动平均值,为了促进训练稳定性和性能改进,我们将一致性损失定义为:
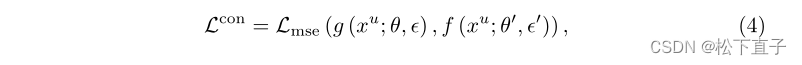
总损失

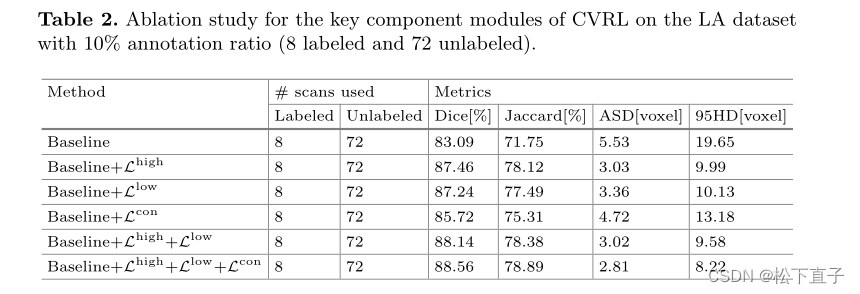
实验结果










![[230513] TPO72 | 2022年托福阅读真题第1/36篇 | 10:45](https://img-blog.csdnimg.cn/541dd74588be4d6ea14909ba1df137c8.png)
