文章目录
- 1. 前言
- 2. 分析背景
- 3. 内核镜像线性映射的建立过程
- 3.1 预备工作:内核解压缩
- 3.2 建立内核镜像区域的线性映射
- 3.2.1 定位内核入口
- 3.2.2 建立内核线性映射前的其它启动工作
- 3.2.2.1 将 CPU 设为 SVC 模式,且禁用 IRQ + FIQ 中断
- 3.2.2.2 获取处理器类型数据
- 3.2.2.3 建立线性映射页表
- 3.2.2.4 启用 MMU:由 物理地址 转换为 虚拟地址 访问
- 4. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 分析背景
本文基于 ARMv7 架构,Linux 4.14 内核进行分析。
3. 内核镜像线性映射的建立过程
3.1 预备工作:内核解压缩
对于 ARM32 架构 的 Linux 内核,在 bootloader(如 U-BOOT) 将内核镜像 载入到内存之后,但在进入内核入口 stext 之前,会有一个对压缩格式的内核镜像(如zImage)的解压缩过程,在这里简单的对这个解压缩过程进行下描述,但不做细节展开。解压缩的梗概如下(以LZMA压缩格式为例):
1. compile+link objcopy lzma压缩
linux源代码 -------------> arch/arm/boot/vmlinux(elf文件) --------> arch/arm/boot/Image ---------> piggy.lzma
compile
2. piggy.lzma.S(包含piggy.lzma) --------> piggy.lzma.o
link objcopy
3. (head.o misc.o decompress.o) + piggy.lzma.o -----> arch/arm/boot/compressed/vmlinux --------> arch/arm/boot/zImage
对于 ARM32 架构,内核解压缩代码位于目录 arch/arm/boot/compressed 目录下。从上面对解压缩的概述中,我们了解到:
1. 内核代码会被编译为 ELF 格式的 vmlinux ,然后通过 objcopy 去掉一些部分后生成 Image ,最后将 Image 压缩为
piggy.lzma ;
2. 将包含了整个 piggy.lzma 的 piggy.lzma.S 编译成 piggy.lzma.o ;
3. 将用于解压缩的 head.S, misc.c, decompress.c 代码编译为 .o ,再和包含内核进行的 piggy.lzma.o 一起,链接
为新的 vmlinux ,最后通过 objcopy 将新的 vmlinux 转换为 zImage 文件。
如果内核启动伴随有解压缩过程,会看到 Uncompressing Linux... 的内核日志。顺便提一下,ARM64 架构下不再有内核解压缩这一过程,而是直接加载编译链接生成的 Image 镜像文件。
对于内核解压缩过程,就简单的介绍到这里,接下来,我们从内核入口 stext 开始,逐步分析内核镜像区域线性映射的建立过程。
3.2 建立内核镜像区域的线性映射
3.2.1 定位内核入口
先来说一下内核入口 stext ,我们是依据什么确定 stext 是内核入口的?答案是内核链接脚本 arch/arm/kernel/vmlinux.lds.S 。看如下内核链接脚本片段:
OUTPUT_ARCH(arm)
ENTRY(stext)
...
SECTIONS
{
/* 舍弃部分,不被链接到内核 */
/DISCARD/ : {
...
}
. = PAGE_OFFSET + TEXT_OFFSET;
.head.text : {
_text = .; /* 内核镜像起始位置 链接地址 */
HEAD_TEXT /* 内核镜像开始位置代码 */
}
...
}
从上面的链接脚本语句 ENTRY(stext) 了解到,内核入口为即为 stext ;我们还可以看到,内核镜像起始位置的代码为 HEAD_TEXT 代码段。再来看一下,这个 HEAD_TEXT 是何方神圣?
/* include/asm-generic/vmlinux.lds.h */
...
/* Section used for early init (in .S files) */
#define HEAD_TEXT *(.head.text)
...
哈,原来 HEAD_TEXT 是 .o 文件中,那些名为 .head.text 输入段(section);而名为 .head.text 输入段(section),只在 arch/arm/kernel/head.S 中有定义,只此一家,别无分号:
/* arch/arm/kernel/head.S */
.arm
/* 内核入口 */
/*
* 在 inlcude/linux/init.h 定义了 __HEAD:
* #define __HEAD .section ".head.text","ax"
*/
__HEAD
ENTRY(stext)
...
对链接脚本不熟悉的读者,可查阅 ld 链接器文档。
另外,顺便对汇编代码里面出现的 #include 做一下说明,其实 AS 汇编器并不认识 #include 指示符,它支持的是 .include, .incbin 等指示符,那为什么我们可以将 #include 写入到汇编代码,但没有出现编译错误呢? 答案是,在内核的编译过程中,会通过 C 预处理器,将汇编代码处理一遍,把这其中符合 C 宏处理规范的代码(如 #include)处理掉,这样最后 AS 汇编器并不会看到 #include 等这些 C 宏代码语句了,这可以作为一个编程技巧,存储到知识库里。
3.2.2 建立内核线性映射前的其它启动工作
内核的启动过程,并不仅仅是建立内核线性映射,还含有其它的工作,如 CPU 模式设定,DTB 验证,alternative SMP/UP 表修正,PV表修正 等,下面将按这些工作发生的先后顺序,对它们一一进行分析说明。以下所有分析,均不讨论 ARM 虚拟化 扩展功能。
3.2.2.1 将 CPU 设为 SVC 模式,且禁用 IRQ + FIQ 中断
.arm
/* 内核入口 */
__HEAD
ENTRY(stext)
@ ensure svc mode and all interrupts masked
/*
* . 将 BOOT CPU 设为 SVC 模式
* . 禁用 BOOT CPU 的 IRQ + FIQ
* r9 是 BOOT CPU CPSR 寄存器新设定的值。
*/
safe_svcmode_maskall r9
3.2.2.2 获取处理器类型数据
Linux 内核预定义了处理器类型数据 struct proc_info_list :
/* arch/arm/include/asm/procinfo.h */
struct proc_info_list {
unsigned int cpu_val; /* 处理器 ID */
unsigned int cpu_mask; /* 处理器 ID 位掩码 */
unsigned long __cpu_mm_mmu_flags; /* used by head.S */
unsigned long __cpu_io_mmu_flags; /* used by head.S */
unsigned long __cpu_flush; /* used by head.S */
const char *arch_name;
const char *elf_name;
unsigned int elf_hwcap;
const char *cpu_name;
struct processor *proc;
struct cpu_tlb_fns *tlb;
struct cpu_user_fns *user;
struct cpu_cache_fns *cache;
};
ARM32 架构 的处理器数据定义在 arch/arm/mm/proc-*.S 文件中,如 arch/arm/mm/proc-v7.S 定义 ARMv7 系列 CPU 的处理器数据,下面截取了一些处理器数据以及相关函数接口定义:
/* arch/arm/mm/proc-v7.S */
__v7_ca7mp_setup: /* Cortex A7 MP(多核) 处理器初始化接口 */
...
b __v7_setup_cont
...
__v7_setup_cont:
...
/* 返回到 head.S: stext 中 1: b __enable_mmu 处 */
ret lr @ return to head.S:__ret
/*
* Standard v7 proc info content
*/
.macro __v7_proc name, initfunc, mm_mmuflags = 0, io_mmuflags = 0, hwcaps = 0, proc_fns = v7_processor_functions
/* proc_info_list::__cpu_mm_mmu_flags */
ALT_SMP(.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | \
PMD_SECT_AF | PMD_FLAGS_SMP | \mm_mmuflags)
ALT_UP(.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | \
PMD_SECT_AF | PMD_FLAGS_UP | \mm_mmuflags)
/* proc_info_list::__cpu_io_mmu_flags */
.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | \
PMD_SECT_AP_READ | PMD_SECT_AF | \io_mmuflags
/*
* 详见 arch/arm/mm/proc-macros.S
* .macro initfn, func, base
* .long \func - \base
* .endm
* 此处对应 proc_info_list::__cpu_flush 成员,
* 其值定义为 initfunc - &proc_info_list 地址差值。
*/
/* proc_info_list::__cpu_flush */
initfn \initfunc, \name
/* proc_info_list::arch_name */
.long cpu_arch_name
/* proc_info_list::elf_name */
.long cpu_elf_name
/* proc_info_list::elf_hwcap */
.long HWCAP_SWP | HWCAP_HALF | HWCAP_THUMB | HWCAP_FAST_MULT | \
HWCAP_EDSP | HWCAP_TLS | \hwcaps
/* proc_info_list::cpu_name */
.long cpu_v7_name
/* proc_info_list::proc (struct processor *proc;) */
.long \proc_fns
/* proc_info_list::tlb (struct cpu_tlb_fns *tlb;) */
.long v7wbi_tlb_fns
/* proc_info_list::user (struct cpu_user_fns *user;) */
.long v6_user_fns
/* proc_info_list::cache (struct cpu_cache_fns *cache;) */
.long v7_cache_fns
.endm
...
/*
* ARM Ltd. Cortex A7 processor.
*/
/* Cortex A7 处理器对象定义
* 详见: struct proc_info_list (arch/arm/include/asm/procinfo.h)
*/
.type __v7_ca7mp_proc_info, #object
__v7_ca7mp_proc_info:
.long 0x410fc070 /* proc_info_list::cpu_val */
.long 0xff0ffff0 /* proc_info_list::cpu_mask */
__v7_proc __v7_ca7mp_proc_info, __v7_ca7mp_setup
.size __v7_ca7mp_proc_info, . - __v7_ca7mp_proc_info
启动阶段,通过读取 CPU ID 寄存器,来获取 CPU ID,然后通过 CPU ID 匹配 Linux 内核预定义的处理器类型数据 struct proc_info_list :如果找到匹配的数据,说明内核当前支持该处理器类型;否则说明内核不支持该处理器类型,系统将陷入死循环(即启动失败)。看一下具体代码:
/* arch/arm/kernel/head.S */
/*
* 读取处理器 ID 到 r9
* 参考 ARM Architecture Reference Manual.pdf, P687
*/
mrc p15, 0, r9, c0, c0 @ get processor id
/* 通过 r9 中的处理器 ID ,查找对应的系统预定义的处理器信息数据 proc_info_list ,
* 从 r5 寄存器返回。
* r5: 处理器信息指针,
* 类型为 struct proc_info_list *,
* 定义在 arch/arm/include/asm/procinfo.h
*/
bl __lookup_processor_type @ r5=procinfo r9=cpuid
movs r10, r5 @ invalid processor (r5=0)? /* r10: 处理器信息指针 */
THUMB( it eq ) @ force fixup-able long branch encoding
beq __error_p @ yes, error 'p' /* 出错,没找到匹配的处理器数据,系统将进入死循环 */
3.2.2.3 建立线性映射页表
在进入代码细节前,我们先泛泛而谈一下内存管理工作基本流程:简而言之一句话,内存管理就是将虚拟地址转换为物理地址(不考虑虚拟化场景)。那为什么要这么做?为什么要引入操作系统这个内存管理者?直接以物理地址访问不行吗?我们假设不用操作系统的内存管理,直接允许应用自己来使用系统中的内存,那大家都可以多吃多占,那谁该多用谁该少占?彼此之间的内存区间彼此覆盖又该怎么办(它们彼此缺少隔离机制)?于是,我们这时需要一个公共的内存管理者操作系统,来统一分配系统中的内存,这个管理者尽量满足大家的需求,而又尽量保持公平,同时可以避免应用彼此内存区间的覆盖。引入一个操作系统内存管理者,看起来解决了所有的问题,但事实并不然,虽然操作系统内存管理可以分配必须不覆盖的内存区间给不同应用,但是如果以物理地址来访问,仍然没法防止应用A写入到应用B的内存区间,应用A把应用B给整崩溃了,应用B何辜?这还只是两个应用相互影响的情形,以现在应用动辄几十个应用的情形,大家彼此乱写对方的内存区间,那就乱成一锅粥了。为此引入了虚拟地址的概念,每个应用的虚拟地址空间都是相同的(如32位应用的 0x00000000~0xFFFFFFFF),但它们可以映射到相同或不同的物理内存,这是地址空间隔离。所以操作系统这个内存管理者,具备了两个功能:第一,集中管理系统中的内存;第二,为系统中的应用建立独立隔离的地址空间。
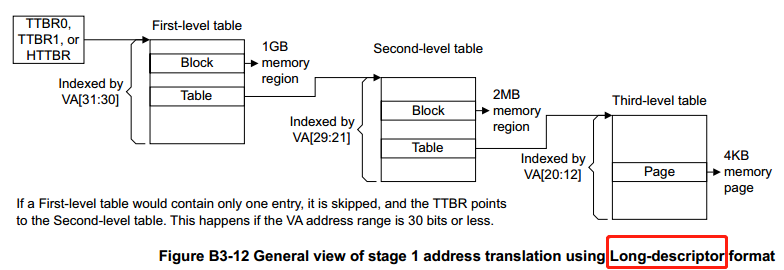
回到我们的分析场景:ARM32架构 下的 Linux 内存管理。要了解内存管理,首先需要了解硬件架构内存管理硬件的相关知识。在进入建立线性映射页表的代码分析之前,先来看看 ARMv7 架构(代码是针对ARMv7架构进行分析)的内存管理单元(MMU)硬件中和本文分析相关的部分。
先看下ARM32架构下的内存管理地址翻译的基本流程,如下图:
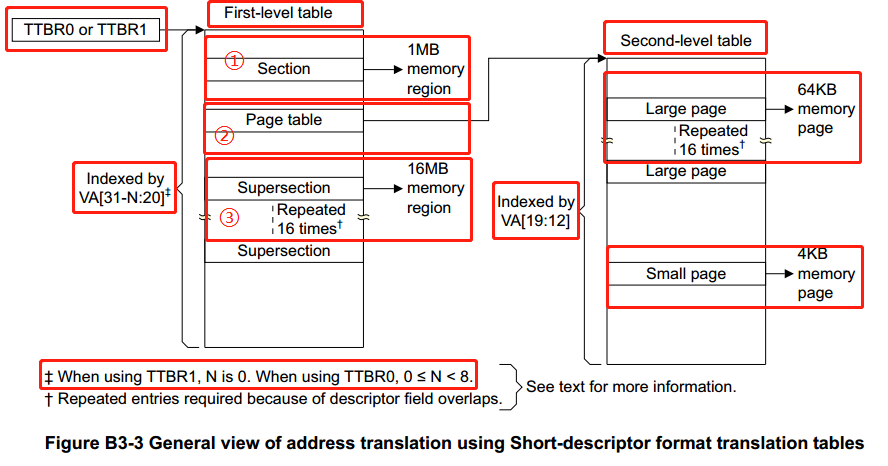
上图是ARM32架构下,使用2级(最多2级)页表进行映射的地址翻译(将虚拟地址转换为物理地址)流程,这里对该图进行一下简要说明:
1. TTBR0,TTBR1 寄存器存有第1级页表(First-level table)的物理基址;
2. 第1级页表(First-level table)的页表项,可能是下列3种类型中一种:
. 指向 1MB 大小 section 的物理基址
. 指向第2级页表(Second-level table)的物理基址
. 指向 16MB 大小 Supersection 的物理基址
3. 第2级页表(Second-level table)的页表项,可能是下列2种类型中一种:
. 指向 64KB 大小 Large page 的物理基址
. 指向 4KB 大小 Small page 的物理基址
4. VA 指32位虚拟地址:
. 1级页表映射(1MB section 或 16MB Supersection),将虚拟地址拆分为2部分,
高位部分用来索引第1级(First-level table)的页表项,低位部分是相对于 section
或 Supersecion 内的偏移
. 2级页表映射(64KB Large page 或 4KB Small page),将虚拟地址拆分为3部分,
高位部分用来索引(First-level table)的页表项,中间位部分用来索引
(Second-level table)的页表项,低位部分是相对于 Large page 或 Small page
内的偏移
从上面了解到,页表项可以是不同的类型,那是通过什么来决定页表项的类型?第1级页表(First-level table)的页表项 和 第2级页表(Second-level table)的页表项 有着不同的定义。首先看第1级页表(First-level table)的页表项的定义:
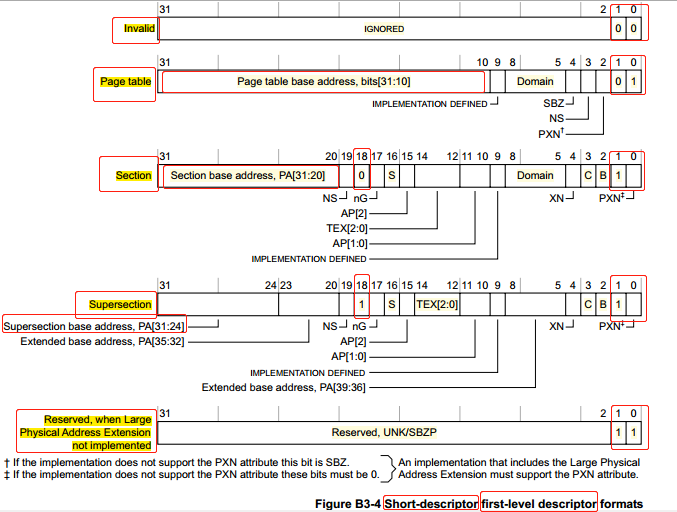
我们看到,第1级页表(First-level table)的页表项,每个页表项为32位长度(并非所有情形,后面会加以补充说明),最低2位决定了页表项的类型:
0b00 :非法页表项
0b01 :页表项指向第2级页表(Second-level table)的物理基址
0b10 :页表项指向 Section(Bit[18]为0) 或 Supersection(Bit[18]为1) 的基址
0b11 :保留类型
再看第2级页表(Second-level table)的页表项的定义:
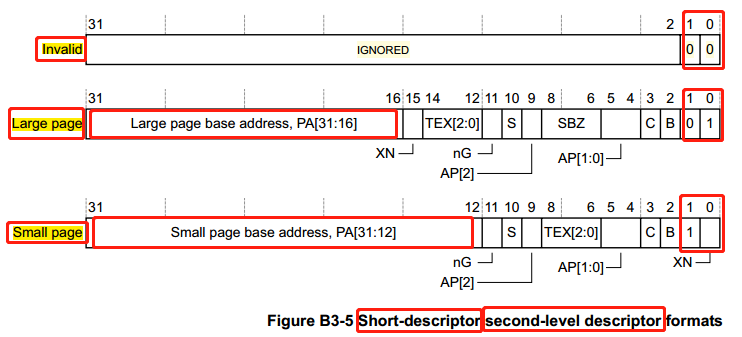
我们看到,第2级页表(Second-level table)的页表项,每个页表项为32位长度(并非所有情形,后面会加以补充说明),最低2位决定了页表项的类型:
0b00 :非法页表项
0b01 :页表项指向 64KB Large page 的物理基址
0b1x :页表项指向 4KB Small page 的物理基址
最低位 XN==1 ,表示页表包含的数据不具备可执行权限
你可能注意到,上面的页表项说明中,都有一个 Short-descriptor 标记,这是什么意思?我们先跑下题,再回头来解答这个问题。一个系统能支持的最大内存,由硬件的物理地址位数决定,如果硬件系统只支持32位物理地址,那么系统最多只能管理 2^32 = 4GB 的物理内存,如果32位系统下,要支持超过4GB的内存,又或者,某些的机器虽然只支持4GB内存空间,但是内存的起始物理地址不是0,那么最大物理地址也超过了32位物理地址能表达的范围,这时候该怎么办?为此,硬件引入了物理地址扩展,以能访问超过4G内存地址的物理内存区间。在ARM32架构下,这个特性为 LPAE(Large Physical Address Extension),它将物理地址扩展到40位,因此能访问物理地址区间也扩展到 2^40 = 128GB 。回到我们的问题,因为LPAE扩展了物理地址范围,对应的虚拟地址范围也同样需要扩展,页表的管理也发生了变化,为此引入了和 短描述符(Short-descriptor) 对应的 长描述符(Long-descriptor) :
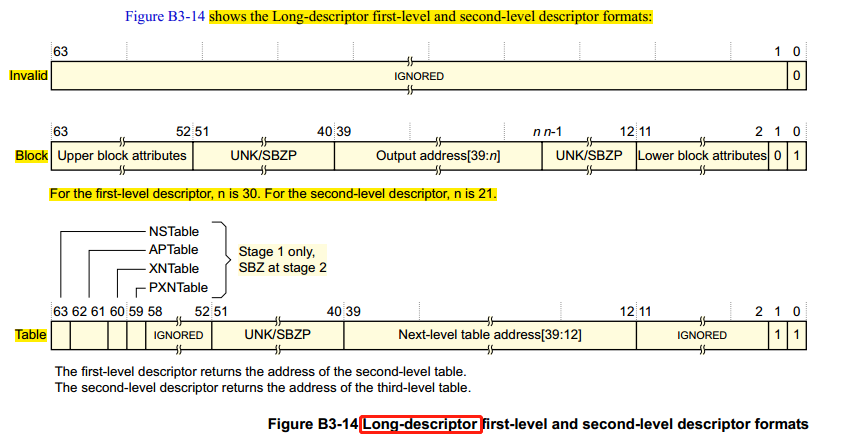
长描述符(Long-descriptor) 方式下,页表映射最多可达3级,页表项的长度也变为了64位,更多关于 长描述符(Long-descriptor) 细节不在本文展开,感兴趣的读者可参考 ARM 官方手册 《DDI0406C_d_armv7ar_arm.pdf》。
经过前面的铺垫,现在可以进入到代码细节的分析了:
/*
* 检查系统内存管理硬件是否支持 LPAE 特性。
*
* ARMv7-A: Large Physical Address Extension, 4GB => 1024GB.
* 转换 32 位虚拟地址 为 40 位物理地址,这需要系统提供页表长描述符
* (long descriptor)的支持.
* 参考 DDI0406C_d_armv7ar_arm.pdf, P1615
*/
#ifdef CONFIG_ARM_LPAE
mrc p15, 0, r3, c0, c1, 4 @ read ID_MMFR0
and r3, r3, #0xf @ extract VMSA support
cmp r3, #5 @ long-descriptor translation table format?
THUMB( it lo ) @ force fixup-able long branch encoding
blo __error_lpae @ only classic page table format
#endif
#ifndef CONFIG_XIP_KERNEL
adr r3, 2f /* r3 = 标号 2 的物理地址 */
ldmia r3, {r4, r8}/* r4 = 标号 2 的链接虚拟地址, r8 = PAGE_OFFSET */
sub r4, r3, r4 @ (PHYS_OFFSET - PAGE_OFFSET) /* r4 = 标号 2 的物理地址 - 标号 2 的链接虚拟地址 */
add r8, r8, r4 @ PHYS_OFFSET /* r8 = PAGE_OFFSET 对应的物理地址 */
#else
ldr r8, =PLAT_PHYS_OFFSET @ always constant in this case
#endif
/*
* r1 = machine no, r2 = atags or dtb,
* r8 = phys_offset, r9 = cpuid, r10 = procinfo
*/
bl __vet_atags /* fdt/atags合法性验证 */
#ifdef CONFIG_SMP_ON_UP /* CONFIG_SMP_ON_UP: 允许在 单核处理器 上启动 支持 SMP 的内核 */
/*
* 如果是单核系统,将所有 .alt.smp.init 段中起始 9998 标号处
* 多核场景内容,替换为单核场景下应使用的内容。
*/
bl __fixup_smp
#endif
#ifdef CONFIG_ARM_PATCH_PHYS_VIRT
/*
* 物理/虚拟地址运行时动态转换功能: 修正 add/sub 转换指令的立即数部分。
* arch/arm/include/asm/memory.h
* __pv_stub() 建立的 .pv_table 段 (__phys_to_virt(), __virt_to_phys_nodebug())。
*/
bl __fixup_pv_table
#endif
/* 创建 1MB Section 粒度的、内核镜像区间的线性映射页表 */
bl __create_page_tables
/* 建立内核镜像线性映射后,启动 MMU 的工作,将在后面作出分析 */
...
__create_page_tables 是我们的重头戏,由此建立了内核镜像区间的线性映射,来看细节:
/*
* r8 = PAGE_OFFSET 对应的物理地址
* 返回:r4 = 指向第一级页表物理地址,也即页表物理首地址
*/
__create_page_tables:
/* r4 = 内核初始页表物理地址, 16KB / 20KB(LPAE) 大小(swapper_pg_dir) */
/*
* 目前物理地址空间分布如图:
*
* 物理地址空间
* 高 | |
* 地 ^ | ... |
* | | |
* 址 | |------------------------|
* | | |
* 增 | | Kernel Image |
* | | |
* 长 | |------------------------| <--- PHYS_OFFSET + TEXT_OFFSET(0x60000000 + 0x408000 = 0x60408000)
* | | swapper_pg_dir(16K) |
* 方 | |------------------------| <--- r4 = PHYS_OFFSET + TEXT_OFFSET - 0x4000(0x60404000)
* | | |
* 向 | | |
* 低 |------------------------| <--- PHYS_OFFSET(0x60000000): kernel空间物理起始地址
* | ... |
*/
pgtbl r4, r8 @ page table address
/*
* Clear the swapper page table
*/
/* kernel 16KB (!CONFIG_ARM_LPAE) 或 16KB + 4KB (CONFIG_ARM_LPAE) 一级(L1)页表(swapper_pg_dir)全部清0 */
mov r0, r4
mov r3, #0
add r6, r0, #PG_DIR_SIZE
1: str r3, [r0], #4
str r3, [r0], #4
str r3, [r0], #4
str r3, [r0], #4
teq r0, r6
bne 1b
#ifdef CONFIG_ARM_LPAE
/*
* Build the PGD table (first level) to point to the PMD table. A PGD
* entry is 64-bit wide.
*/
/*
* 建立 LPAE 第1级长描述页表:
* 4个页表项,每个页表项指向【第2级4个页表】的物理首地址。
* / -----------------
* | 0 | PGD Table Entry |--------
* | |-----------------| |
* | 1 | PGD Table Entry |------ |
* | |-----------------| | |
* 4KB / 2 | PGD Table Entry |---- | |
* 512项 \ |-----------------| | | |
* | 3 | PGD Table Entry |-- | | |
* | |-----------------| | | | |
* | | ...... | | | | |
* | | | | | | |
* \ |-----------------| | | | |
* /| PGD Table |<-|-|-|-
* / |-----------------| | | |
* /--| PGD Table |<-|-|-
* 4*4KB / |-----------------| | |
* 512项 |----| PGD Table |<-|-
* \ |-----------------| |
* ---| PGD Table |<-
* |-----------------|
* | ...... |
*/
/* 参考文档: DDI0406C_d_armv7ar_arm.pdf, P1334 */
/* r4: 内核页表起始物理地址 */
mov r0, r4
/*
* r3: 第一个 PGD 页表物理地址(即 第二级页表 物理地址)
*
* 每个长描述符页表项是 64 位长度,所以 0x1000 = 4096 长度空间,包含的
* 长描述符页表项个数为 4096 / 8 = 512 ,但仅使用了前 4 个表项。
* 详见 DDI0406C_d_armv7ar_arm.pdf, P1336
*/
add r3, r4, #0x1000 @ first PMD table address
/*
* 长描述符页表项第 2 位表示页表项类型: 类型 3 表示页表项指向下一级页表.
* 详见 DDI0406C_d_armv7ar_arm.pdf, P1336
*/
orr r3, r3, #3 @ PGD block type
/* 长描述符 第一级页表 仅包含 4 个页表项 */
mov r6, #4 @ PTRS_PER_PGD
/*
* 软件标记。用来标记 长描述符页表项 指向的是 swapper 进程的页表。
* bit[55], 因为 长描述符页表项 用 64-bit 存储,而且分为低 32-bit
* 和 高 32-bit ,所以 bit[55] 在高 32-bit 的第 (55 - 32) 位,因此
* 有: #1 << (55 - 32) 。
* 为什么是 bit[55] 呢?因为当页表项类型为 3 时,页表项的 bit[58:52]
* 被硬件忽略,详见 DDI0406C_d_armv7ar_arm.pdf, P1336
*/
mov r7, #1 << (55 - 32) @ L_PGD_SWAPPER
1:
/* 设置长描述符页表项低 32-bit: 下一级页表地址 */
str r3, [r0], #4 @ set bottom PGD entry bits
/* 设置长描述符页表项高 32-bit: L_PGD_SWAPPER */
str r7, [r0], #4 @ set top PGD entry bits
/* r3: 下一个 PGD 页表物理地址(即 第二级页表 物理地址)。
* 每个第二级页表大小为 4KB(0x1000)
*/
add r3, r3, #0x1000 @ next PMD table
subs r6, r6, #1
bne 1b
/* r4 = 第2级 4个 页表物理首地址 */
add r4, r4, #0x1000 @ point to the PMD tables
#endif /* CONFIG_ARM_LPAE */
/*
* r10 = proc_info_list *
* r7 = proc_info_list::__cpu_mm_mmu_flags
*/
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags
/*
* Create identity mapping to cater for __enable_mmu.
* This identity mapping will be removed by paging_init().
*/
/* 建立 CPU MMU 启用函数 __enable_mmu 的等同映射,这是基于 ARM 官方手册的建议 */
adr r0, __turn_mmu_on_loc /* r0 = __turn_mmu_on_loc 的当前物理地址 */
/*
* r3 = __turn_mmu_on_loc 的链接虚拟地址
* r5 = __turn_mmu_on 的链接虚拟地址
* r6 = __turn_mmu_on_end 的链接虚拟地址
*/
ldmia r0, {r3, r5, r6}
/* r0 = __turn_mmu_on_loc (当前物理地址 - 链接虚拟地址) */
sub r0, r0, r3 @ virt->phys offset
/* r5 = __turn_mmu_on 的当前物理地址 */
add r5, r5, r0 @ phys __turn_mmu_on
/* r6 = __turn_mmu_on_end 的当前物理地址 */
add r6, r6, r0 @ phys __turn_mmu_on_end
/*
* 如果启用了 LPAE, 则为 3 级页表:
* . r5 = __turn_mmu_on 当前物理地址 >> 21 (高 11 位)
* . r6 = __turn_mmu_on_end 当前物理地址 >> 21 (高 11 位)
* 详见 DDI0406C_d_armv7ar_arm.pdf, P
*
* 如果没启用 LPAE, 则为 2 级页表:
* . r5 = __turn_mmu_on 当前物理地址 >> 20 (高 12 位)
* . r6 = __turn_mmu_on_end 当前物理地址 >> 20 (高 12 位)
* 详见 DDI0406C_d_armv7ar_arm.pdf, P1323
*/
mov r5, r5, lsr #SECTION_SHIFT
mov r6, r6, lsr #SECTION_SHIFT
/*
* 启用了 LPAE: r3 = proc_info_list::__cpu_mm_mmu_flags |
* 区间 [__turn_mmu_on,__turn_mmu_on_end] 当前页面地址高 11 位
*
* 没启用 LPAE: r3 = proc_info_list::__cpu_mm_mmu_flags |
* 区间 [__turn_mmu_on,__turn_mmu_on_end] 当前页面地址高 12 位
* r7 = proc_info_list::__cpu_mm_mmu_flags
*/
1: orr r3, r7, r5, lsl #SECTION_SHIFT @ flags + kernel base
/*
* 所谓 identity mapping ,是指传递给 MMU 的【输入地址】,不管是 【物理地址(PA)】,
* 还是 【虚拟地址(VA)】 ,它们得到 【同一个输出地址】 。
*
* 假设已知 __turn_mmu_on 的链接虚拟地址为 0xC0200000 ,
* 同时假设 0xC0000000 对应的物理地址为 0x60000000 .
* 那么可以推得 __turn_mmu_on 的当前物理地址为:
* 0xC0200000 - 0xC0000000 + 0x60000000 = 0x60200000
* (1) 如果启用了 LPAE
* r5 = 0x60200000 >> 21
* r3 = 0x60200000 | mm_mmuflags
* (2) 如果没启用 LPAE
* r5 = 0x60200000 >> 20
* r3 = 0x60200000 | mm_mmuflags
* 此处用 __turn_mmu_on 的【物理地址】 作为 【输入地址】,然后将其 【输出地址】
* 配置为 __turn_mmu_on 的【物理地址】,即 【输入地址】 和 【物理地址】 都是
* __turn_mmu_on 的【物理地址】 。
* 后面的内核镜像映射,会将 __turn_mmu_on 的虚拟地址,映射为其物理地址。
* 这两者结合起来,就是 identity mapping ,也就是 __turn_mmu_on 有两个
* 页表映射项:
* . 一个以 __turn_mmu_on 的【物理地址】 作为 【输入地址】
* . 一个以 __turn_mmu_on 的【虚拟地址】 作为 【输入地址】
* 这两个映射表项的 【输出地址】 都是 __turn_mmu_on 的【物理地址】 。
*
* 配置 identity mapping 的目的是为启用 MMU 的代码片段工作正确。
*/
str r3, [r4, r5, lsl #PMD_ORDER] @ identity mapping
cmp r5, r6
addlo r5, r5, #1 @ next section
blo 1b
/*
* Map our RAM from the start to the end of the kernel .bss section.
*/
/*
* 建立区间 [内核空间起始位置虚拟地址 PAGE_OFFSET, 内核镜像结束位置虚拟地址) 的页表。
*/
/* (1) 如果启用了 LPAE
* r4 = 第2级 4个 页表物理首地址
* r0 = r4 + (PAGE_OFFSET >> (21 - 3))
* = 内核空间起始位置虚拟地址 PAGE_OFFSET 对应页表项的物理地址
* (2) 如果没启用 LPAE
* r4 = 第1级页表物理首地址,也是所有页表的物理首地址
* r0 = r4 + (PAGE_OFFSET >> (20 - 2))
* = 内核空间起始位置虚拟地址 PAGE_OFFSET 对应页表项的物理地址
*/
add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER)
ldr r6, =(_end - 1) /* 内核镜像 结束位置 虚拟地址 */
/*
* r8 = PAGE_OFFSET 对应的物理地址
* r7 = proc_info_list::__cpu_mm_mmu_flags
*
* r3 = PAGE_OFFSET 对应的物理地址 | proc_info_list::__cpu_mm_mmu_flags
*/
orr r3, r8, r7
/* r6 = r4 + (r6 >> (SECTION_SHIFT - PMD_ORDER))
* = 【内核镜像 结束位置 虚拟地址】 对应页表项的物理地址
*/
add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER)
/* r3: 内核空间当前 section 映射的 物理地址
* r0: 内核空间当前 section 对应页表项的物理地址
*/
/*
* (1) 建立内核空间当前 section 的页表映射:
* (2) r0 更新为内核空间下一 section 的页表项物理地址: r0 += (1 << PMD_ORDER)
* (3) r3 更新为内核空间下一 section 要映射的物理地址
*/
1: str r3, [r0], #1 << PMD_ORDER
add r3, r3, #1 << SECTION_SHIFT
cmp r0, r6 /* 到达内核镜像结尾了吗? */
bls 1b /* 否的话就继续;是的话就结束了 */
/*
* Then map boot params address in r2 if specified.
* We map 2 sections in case the ATAGs/DTB crosses a section boundary.
*/
/*
* 从下面的代码了解到,内核只为 DTB 建立 2个 section 的映射,
* 这意味着 DTB 最大只能是 2个 section 的大小:
* . 如果开启了 LAPE , 2 * 2MB = 4MB
* . 如果没开启 LAPE , 2 * 1MB = 2MB
*/
/*
* r2 = atags or dtb 物理地址
* r8 = PAGE_OFFSET 的物理地址
*/
/* r0 = DTB section 物理基地址 */
mov r0, r2, lsr #SECTION_SHIFT
movs r0, r0, lsl #SECTION_SHIFT
/* r3 = DTB section 的链接虚拟地址 */
subne r3, r0, r8
addne r3, r3, #PAGE_OFFSET
/* r3 = DTB section 页表项物理地址 */
addne r3, r4, r3, lsr #(SECTION_SHIFT - PMD_ORDER)
/* r6 = DTB section 物理基地址 | proc_info_list::__cpu_mm_mmu_flags */
orrne r6, r7, r0
/*
* 配置 DTB section 页表项: VA -> PA
* . [r3] = DTB section 物理基地址 | proc_info_list::__cpu_mm_mmu_flags
* . r3 += #1 << PMD_ORDER (即 r3 指向下一个 DTB section 的页表项物理地址)
*/
strne r6, [r3], #1 << PMD_ORDER
/* r6 = 下一 DTB section 物理基地址 | proc_info_list::__cpu_mm_mmu_flags */
addne r6, r6, #1 << SECTION_SHIFT
/* 配置下一 DTB section 页表项: VA -> PA */
strne r6, [r3]
#ifdef CONFIG_ARM_LPAE
/* r4 = 指向第一级页表物理地址,也即页表物理首地址 */
sub r4, r4, #0x1000 @ point to the PGD table
#endif
ret lr
ENDPROC(__create_page_tables)
到此,已经建立了内核镜像区间,以及 DTB 的线性映射。为什么说是线性映射?因为这些映射,让虚拟地址到物理地址保持一个固定的差值。接下来,我们剩下的工作,就是开启 MMU ,进入按虚拟地址的世界了。
3.2.2.4 启用 MMU:由 物理地址 转换为 虚拟地址 访问
在本小节之前的分析,都是使用物理地址在进行访问。但最终,内核要转换到使用虚拟地址进行访问,这是通过建立页表后再启用 MMU 后达成的。看代码细节:
/* 内核入口 */
__HEAD
ENTRY(stext)
...
bl __create_page_tables
/*
* r13 = __mmap_switched 的链接虚拟地址
* __enable_mmu 开启 MMU 后,将跳转到 __mmap_switched 执行。
*/
ldr r13, =__mmap_switched @ address to jump to after
@ mmu has been enabled
/* lr = CPU 初始化函数(如 __v7_ca7mp_setup)的返回地址 */
badr lr, 1f @ return (PIC) address
#ifdef CONFIG_ARM_LPAE
mov r5, #0 @ high TTBR0
/*
* r4 = 页表物理基址
* r8 = r4 >> 12 (4KB 物理页框号)
*/
mov r8, r4, lsr #12 @ TTBR1 is swapper_pg_dir pfn
#else
/* r8 = 页表物理基址 */
mov r8, r4 @ set TTBR1 to swapper_pg_dir
#endif
/*
* r10 = proc_info_list *
* r12 = proc_info_list::__cpu_flush 其值为:
* &proc_info_list::proc->_proc_init - &proc_info_list
* 详见 proc-v7.S 中 __v7_proc 定义 和 proc-macros.S 中 initfn 定义。
*/
ldr r12, [r10, #PROCINFO_INITFUNC]
/* r12 = CPU 初始化函数 &proc_info_list::proc->_proc_init 指针
* 如 __v7_ca7mp_setup (arch/arm/mm/proc-v7.S)
*/
add r12, r12, r10
ret r12 /* CPU 初始化: 如 __v7_ca7mp_setup */
1: b __enable_mmu /* 开启 MMU */
ENDPROC(stext)
__enable_mmu:
#if defined(CONFIG_ALIGNMENT_TRAP) && __LINUX_ARM_ARCH__ < 6
orr r0, r0, #CR_A
#else
bic r0, r0, #CR_A
#endif
#ifdef CONFIG_CPU_DCACHE_DISABLE
bic r0, r0, #CR_C
#endif
#ifdef CONFIG_CPU_BPREDICT_DISABLE
bic r0, r0, #CR_Z
#endif
#ifdef CONFIG_CPU_ICACHE_DISABLE
bic r0, r0, #CR_I
#endif
#ifdef CONFIG_ARM_LPAE
mcrr p15, 0, r4, r5, c2 @ load TTBR0
#else
mov r5, #DACR_INIT
mcr p15, 0, r5, c3, c0, 0 @ load domain access register
mcr p15, 0, r4, c2, c0, 0 @ load page table pointer
#endif
b __turn_mmu_on /* 在 identity mapping 代码中开启 MMU */
ENDPROC(__enable_mmu)
.align 5
.pushsection .idmap.text, "ax"
ENTRY(__turn_mmu_on)
mov r0, r0
instr_sync
mcr p15, 0, r0, c1, c0, 0 @ write control reg
mrc p15, 0, r3, c0, c0, 0 @ read id reg
instr_sync
mov r3, r3
mov r3, r13
ret r3 /* 返回到 __mmap_switched 处 */
__turn_mmu_on_end:
ENDPROC(__turn_mmu_on)
.popsection
.align 2
.type __mmap_switched_data, %object
__mmap_switched_data:
.long __data_loc @ r4
.long _sdata @ r5
.long __bss_start @ r6
.long _end @ r7
.long processor_id @ r4
.long __machine_arch_type @ r5
.long __atags_pointer @ r6
#ifdef CONFIG_CPU_CP15
/* CP15 控制寄存器值 */
.long cr_alignment @ r7
#else
.long 0 @ r7
#endif
.long init_thread_union + THREAD_START_SP @ sp
.size __mmap_switched_data, . - __mmap_switched_data
/*
* The following fragment of code is executed with the MMU on in MMU mode,
* and uses absolute addresses; this is not position independent.
*
* r0 = cp#15 control register
* r1 = machine ID
* r2 = atags/dtb pointer
* r9 = processor ID
*/
__INIT
__mmap_switched: /* 此处代码运行于 MMU 开启状况 */
adr r3, __mmap_switched_data /* r3 = __mmap_switched_data 虚拟地址 */
/*
* r4 = __data_loc 链接虚拟地址 (内核数据段 .data 起始位置虚拟地址)
* r5 = _sdata 链接虚拟地址 (内核数据段 .data 起始位置虚拟地址)
* r6 = __bss_start 链接虚拟地址 (内核 bss 数据段其实位置虚拟地址)
* r7 = _end (内核结束位置虚拟地址)
*
* r3 += 4 * 4 => __mmap_switched_data.processor_id 的链接虚拟地址
*/
ldmia r3!, {r4, r5, r6, r7}
/*
* 初始化内核数据段 (.data): [__data_loc, __bss_start):
* 当 .data 段的 LMA(加载地址) 和 VMA(运行时地址) 不同时,需要做数据拷贝。
*/
cmp r4, r5 @ Copy data segment if needed
1: cmpne r5, r6 /* r5 < __bss_start ? */
ldrne fp, [r4], #4 /* fp = 内核数据段当前位置 [r4] 数据, r4 += 4 */
strne fp, [r5], #4 /* [r5] <= fp, r5 += 4 */
bne 1b
/* 内核 bss 数据段清 0 */
mov fp, #0 @ Clear BSS (and zero fp)
1: cmp r6, r7
strcc fp, [r6],#4
bcc 1b
/*
* r4 = &processor_id (arch/arm/kernel/setup.c)
* r5 = &__machine_arch_type (arch/arm/kernel/setup.c)
* r6 = &__atags_pointer (arch/arm/kernel/setup.c)
* r7 = &cr_alignment (arch/arm/kernel/entry-armv.S)
*/
ARM( ldmia r3, {r4, r5, r6, r7, sp})
THUMB( ldmia r3, {r4, r5, r6, r7} )
THUMB( ldr sp, [r3, #16] )
/* processor_id = 处理器 ID */
str r9, [r4] @ Save processor ID
/*
* r1 = machine no
* __machine_arch_type = machine no
*/
str r1, [r5] @ Save machine type
/* __atags_pointer = DTB 物理地址 */
str r2, [r6] @ Save atags pointer
cmp r7, #0
/* cr_alignment = CP15 控制寄存器值 */
strne r0, [r7] @ Save control register values
b start_kernel /* 跳转到 start_kernel() 执行 */
ENDPROC(__mmap_switched)
到此,对于内核镜像线性映射的建立过程,已经全部完成,进入内核的 C 代码入口 start_kernel() 。
4. 参考资料
《ARM Architecture Reference Manual.pdf》
《DDI0406C_d_armv7ar_arm.pdf》







![[230513] TPO72 | 2022年托福阅读真题第1/36篇 | 10:45](https://img-blog.csdnimg.cn/541dd74588be4d6ea14909ba1df137c8.png)