查询模型
查询模型就是定义如何支持服务端多个并发服务,这里我们引入了worker的抽象概念,可以是线程也可以是进程,就是支持客户端请求并且返回结果的。

进程模型

进程池模型
不利于cache,并且进程之间的通信依赖于tcp,shared memory啥的,比较重。

线程模型

内存和cpu布局
一种是每个cpu通过systembus来访问内存的,这和cpu和内存区域的相对位置不影响速度。

更加现代的是下面这种
如果不是访问local的memory的话,要和别的cpu进行inter connected,然后copy到本地。这可能比本地的要慢50%。所以我们可以在要访问内存最近的cpu核上跑worker。可以用linux move pages, numactl

内存分配
是lazy的,就是先扩展进程的数据段,然后要用的时候,才到物理页,触发page fault.


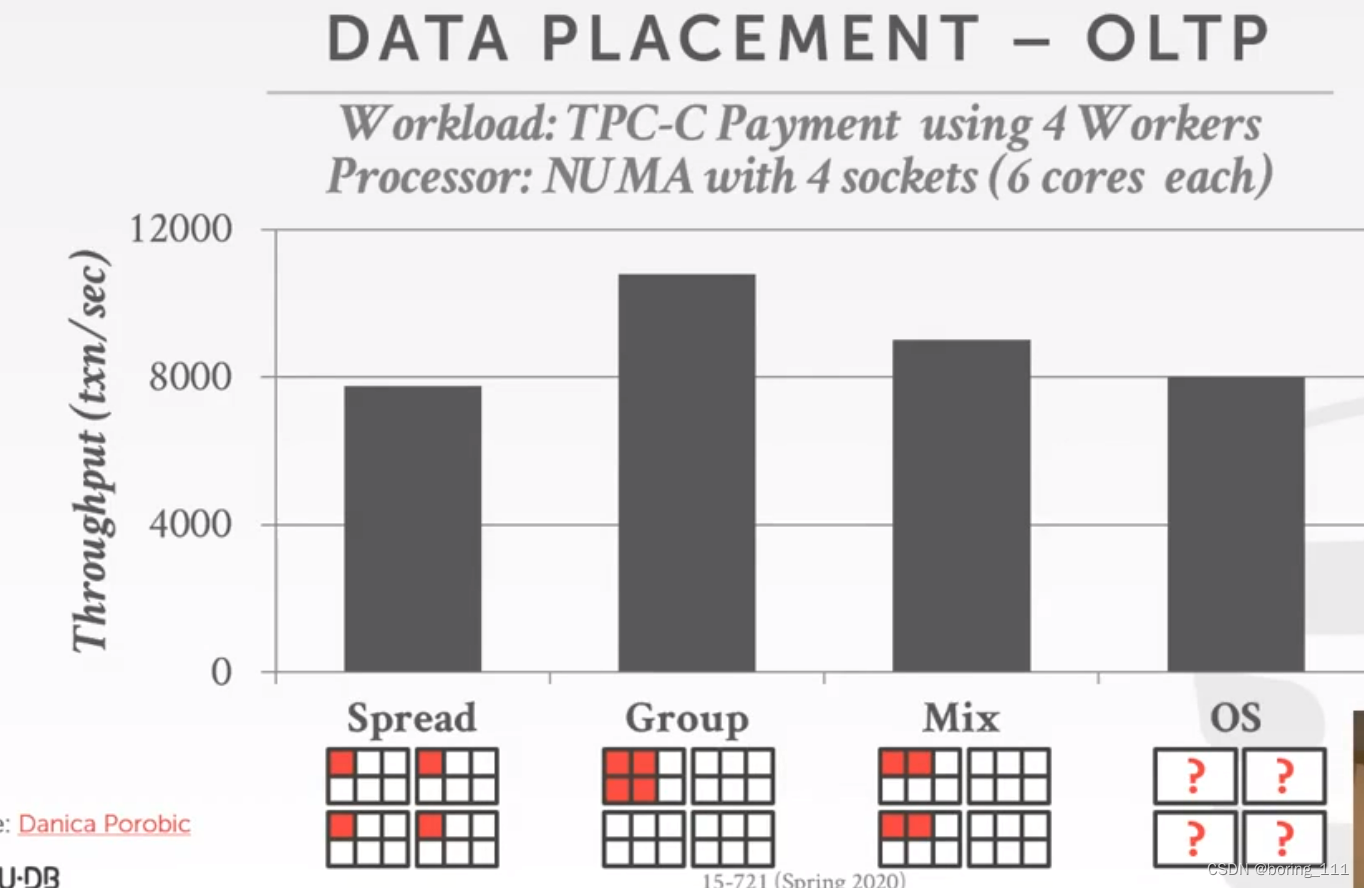
第二个如果group放置的话,比os乱搞可以快大概30%。并且会随着核心的上升而越来越明显。
计划模型
hyper

可以找到空闲的cpu,然后steal,内存,缓存到本地。

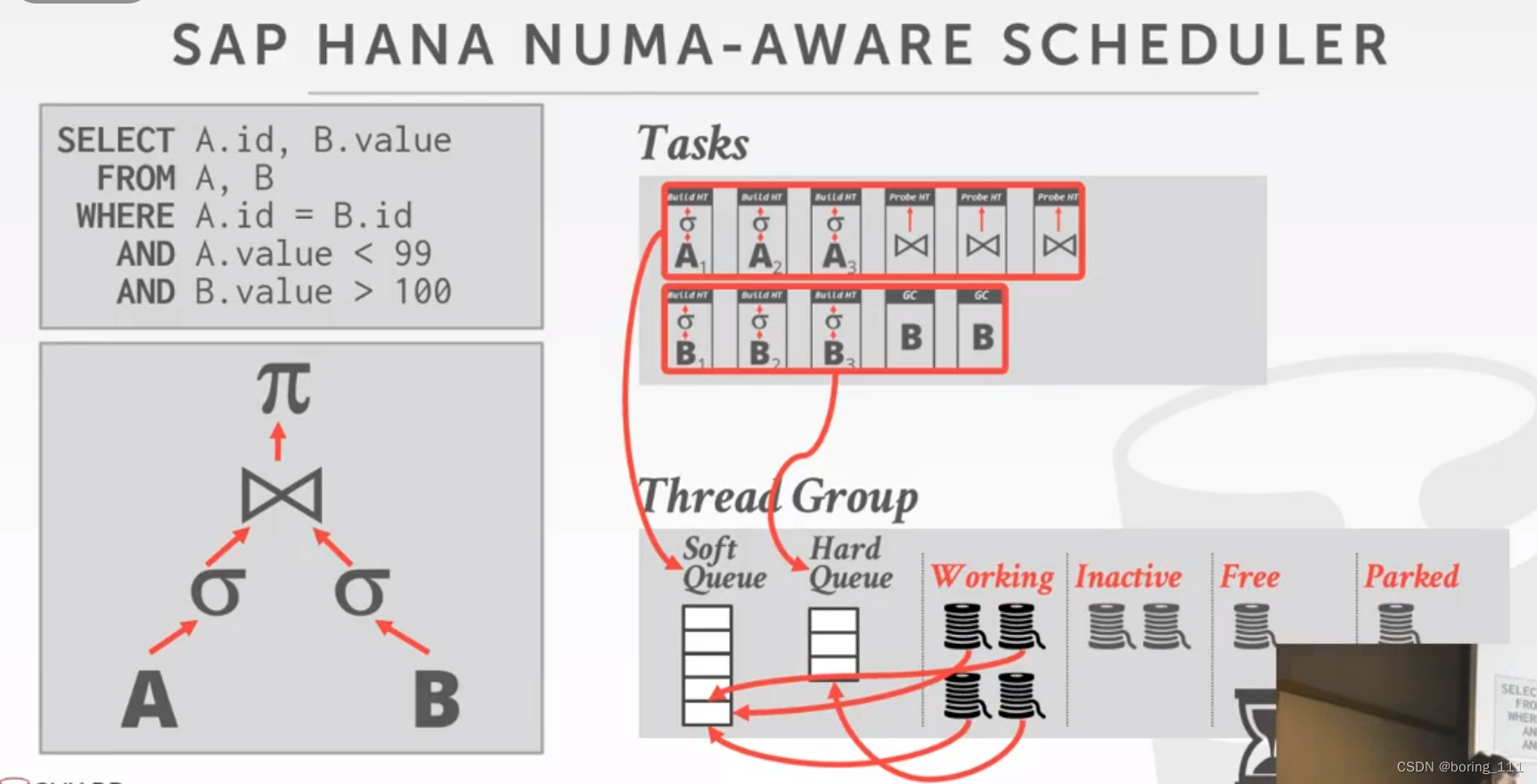
hana

watchdog记录和更新的是全局信息

SQLOS
就是在内核态的os上建一个用户态的os,提供任务调度,IO调度,高级版的事务锁啥的。

超载

解决

Summary
track内存分布,就像分布式系统中的本地分片。

最后,向不良人6大结局致敬。
![FE_Vue学习笔记 - 模板语法[插值 指令] 数据绑定[v-bind v-model] 数据代理 事件](https://img-blog.csdnimg.cn/ba78e3bb949240fb8c1c7927fd8162f2.png)

![[译] Dart 3 发布了](https://img-blog.csdnimg.cn/img_convert/b84aa8812b8251b9c1997ef667ab1a0e.png)