文章目录
- 1. 排序的两种方式
- 2. 索引排序
- 2.1 案例一
- 2.2 案例二
- 2.3 案例三
- 2.4 案例四
- 2.5 案例五
- 2.6 案例六
- 2.7 案例七
- 2.8 案例八
- 3. 其他情况
- 3.1 多表联查
- 3.2 order by null
- 4. 小结
前面跟小伙伴们分享的索引相关的内容,基本上都是在 where 子句中使用索引,实际上,索引也还有另外一个大的用处,那就是在排序中使用索引,今天我们就来聊聊这个话题。
1. 排序的两种方式
MySQL 中想给查询结果排序,我们只需要来一个 order by 即可,SQL 很简单,底层实现起来整体上来说,有两种不同的思路:
- filesort,有时候我们也将之称为文件排序,这个名字有时候会给我们一些误解,让人以为是在磁盘上进行排序的,然而实际上并不一定,数据量比较小的时候,直接在内存中进行排序就行了,只有当在内存中无法完成排序的时候,才会用到磁盘文件。
- 索引排序,由于 InnoDB 中的索引是按照 B+Tree 的形式将数据组织在一起的,B+Tree 中数据本身就是有序的,所以如果能够利用好索引,排序的事情就会事半功倍。
一共就这两种排序的方式,小伙伴们也发现了,如果我们的索引设计比较合理,最终能够按照第 2 种方式进行排序,那肯定是最好不过了。
不过这里需要注意一个细节,第二种排序方式快有一个前提,那就是不需要回表,如果查询的过程中需要回表,那么第二种方式就不一定快了。原因也简单:
- 如果不需要回表,也就是我们想要查询的数据都在索引树上,索引树上的数据本身又都是按照顺序存储的,那么查到数据直接返回即可,本身就是有序的。
- 如果查询的时候,索引树上并没有我们想要的字段,那么就需要回表,小伙伴们知道,回表基本上都是随机 IO 了,因为回表的时候,主键值并不一定连续,此时效率就会低一些。那么这个时候第二种排序方式的性能就不一定强于第一种了,当然,这并无固定结论,还是要结合具体情况分析,这里我只是告诉小伙伴们有各种可能的情况。
2. 索引排序
如果我们想用上索引排序,那么需要满足哪些条件呢?
还是以我们上篇文章的数据为例,假设我有如下表结构:
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`gender` varchar(2) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_prop_index` (`username`,`age`,`address`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
这个表中有一个联合索引,联合索引的字段包含 username、age 和 address 三个。
表中的数据如下:
| id(主键) | username | age | address | gender |
|---|---|---|---|---|
| 1 | ab | 99 | 深圳 | 男 |
| 2 | bw | 95 | 天津 | 男 |
| 3 | cx | 93 | 深圳 | 男 |
| 4 | bc | 80 | 上海 | 女 |
| 5 | bg | 85 | 重庆 | 女 |
| 6 | ac | 98 | 广州 | 男 |
| 7 | bw | 99 | 海口 | 女 |
| 8 | ck | 90 | 深圳 | 男 |
| 9 | cc | 92 | 武汉 | 男 |
| 10 | af | 88 | 北京 | 女 |
还是假设 username、age、address 三个字段组成联合索引,B+Tree 如下:
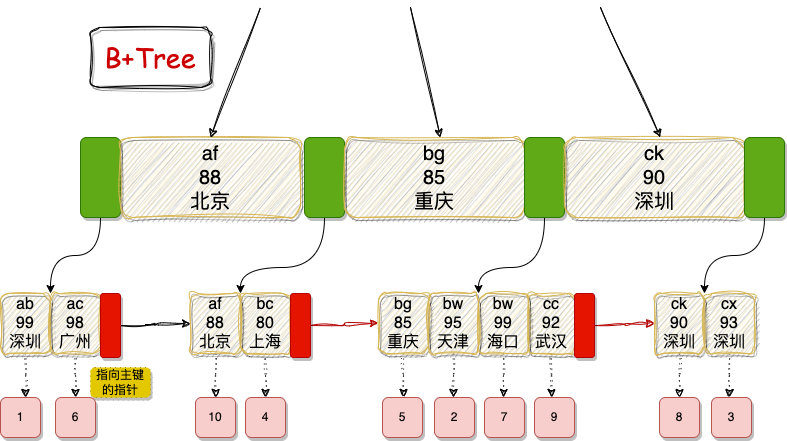
小伙伴们就想想,怎么样查询,查出来的结果是有序的?
给大家 1 分钟总结一下。
我们来梳理下:只有当索引的顺序和 order by 子句的顺序完全一致,并且所有列的排序方向也都一致的情况下,MySQL 才能通过索引来对结果进行排序,同时,如果是联合索引,order by 子句也需要满足最左匹配原则。
我举几个例子。
2.1 案例一
先来看如下 SQL:
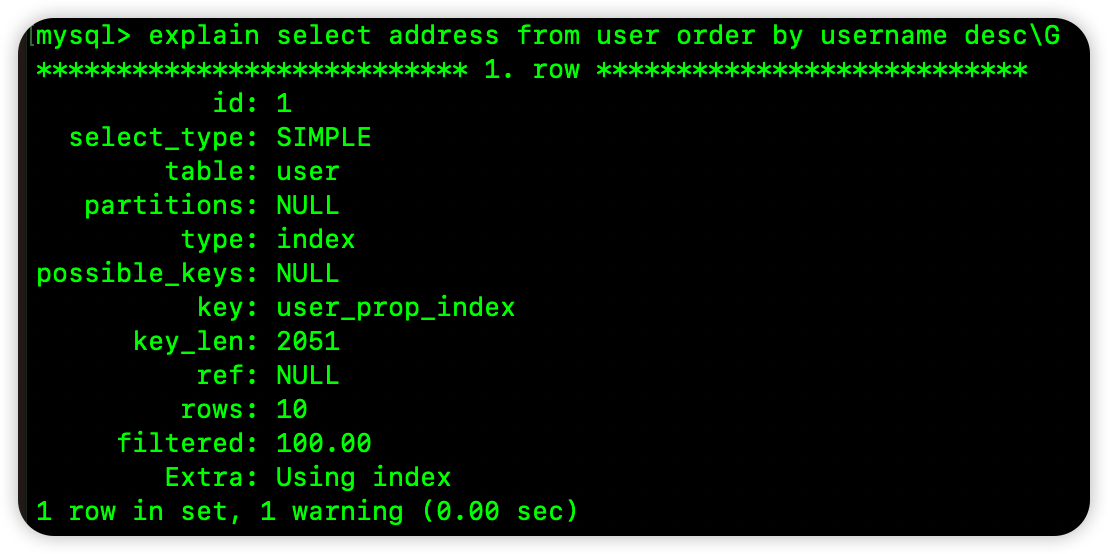
select address from user order by username;
这个是查询 address 字段,根据 username 进行排序。很明显,我们想要的 address 字段就存在于这个联合索引的 B+Tree 上,并且这个联合索引的 B+Tree 就是按照 username 进行升序排序的,所以这个 SQL 就可以通过索引进行排序,如下图:
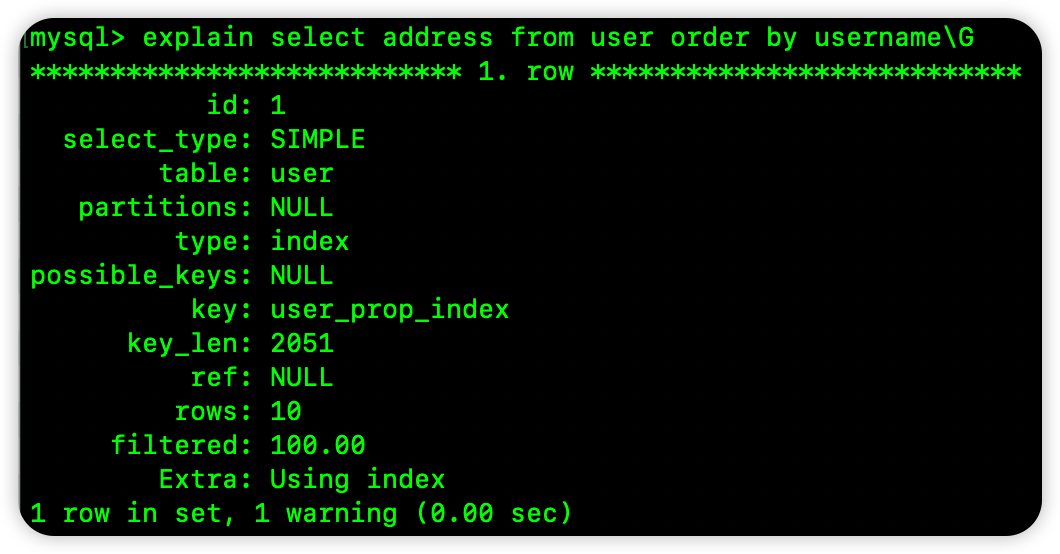
type:index 就说明了 MySQL 使用了索引扫描来进行排序的。
2.2 案例二
再来看下面这条 SQL:
select address from user order by username asc,age desc\G
这个 SQL 还是查询 address 字段,是根据 username 和 age 进行排序的,其中 username 是按照升序排序,age 则是按照倒序排序,小伙伴们想想,在前面这个联合索引的 B+Tree 中,username 是升序的没问题,当 username 相同的时候,age 也是按照升序排序的,但是 SQL 中却要一个升序一个倒序,显然从索引树中拿到的数据无法满足这样的条件,所以这个查询并不会使用索引排序,如下图:
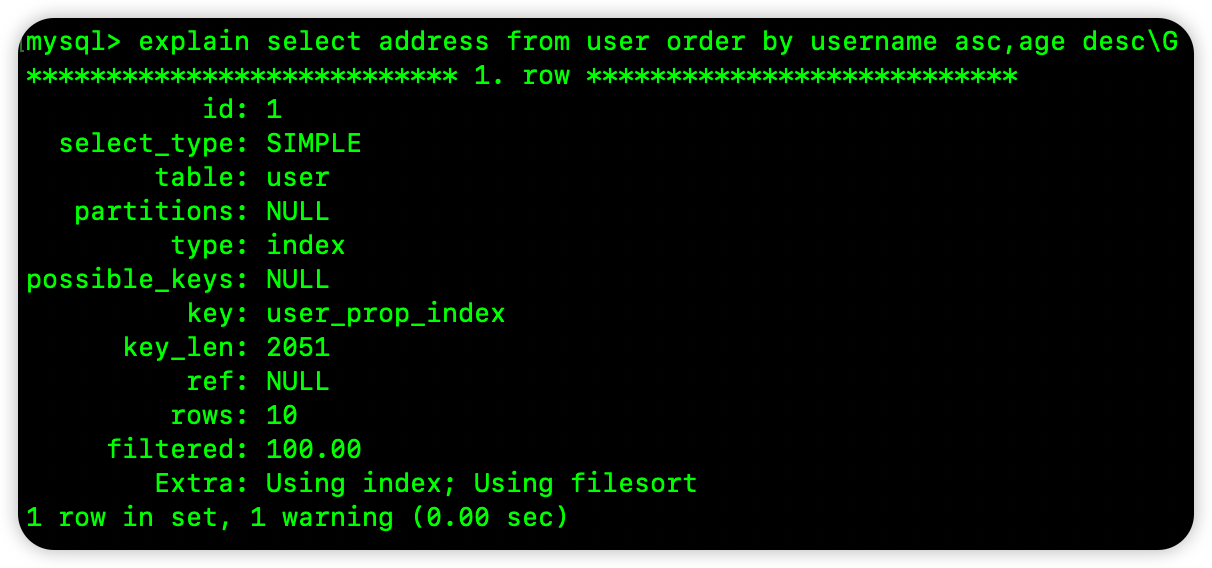
Extra 中的 Using filesort 就说明了这里需要文件排序,无法通过索引排序完成需求。
2.3 案例三
再来看如下 SQL:
select address from user order by username desc
这个 SQL 和 2.1 小节的 SQL 相比就是排序的顺序变了,第一个 SQL 没有写顺序,默认就是升序,这个里边写了是按照倒序来排列。B+Tree 中的 username 是升序,那么这个能用到索引排序吗?这个是可以使用到索引排序的,在 MySQL5.7 中,执行计划如下:
在 MySQL8.x 中,执行计划如下:

小伙伴们看到,区别在于 Extra 中多了一个 Backward index scan。
这是啥意思呢?
在 MySQL8 之前,索引是可以被反向扫描的,但是反向扫描效率会低一些,所以小伙伴们看到,在 MySQL5.7 中用到了索引排序,而且也没说其他的,这其实就是索引反向扫描了。
从 MySQL8 开始,索引定义时候的降序关键字 DESC 将不再被忽略,索引树在存储数据的时候可以降序存储了,这样在将来查询的时候扫描索引就可以按照正向扫描了,正向扫描效率相对于反向扫描效率会高一些。
这块我来举个例子说明问题。假设我有如下创建表的 SQL:
CREATE TABLE t (
c1 INT, c2 INT,
INDEX idx1 (c1 ASC, c2 ASC),
INDEX idx2 (c1 ASC, c2 DESC),
INDEX idx3 (c1 DESC, c2 ASC),
INDEX idx4 (c1 DESC, c2 DESC)
);
当我在 MySQL5.7 中执行如上 SQL 之后,再来查看表的定义,结果如下:

可以看到,虽然我在执行的时候定了索引字段的顺序,但是这个顺序实际上是被忽略了。
再来看看 MySQL8 中执行之后的结果:
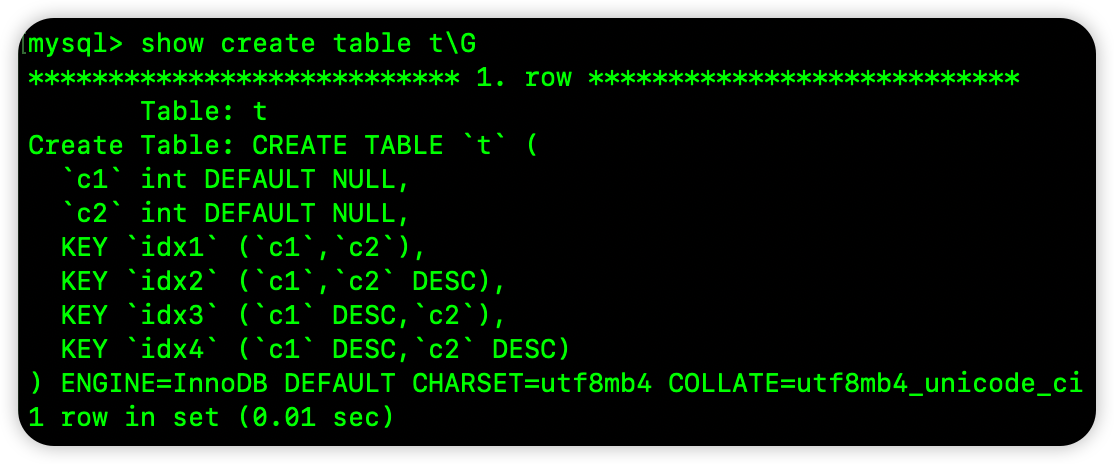
可以看到,在 MySQL8 中,索引定义时字段的顺序被保留了。这印证了我们前面所说的没有问题。
最后,回到我们的问题,Backward index scan 表示优化器在查询的时候将能够使用降序索引。
2.4 案例四
再来看如下 SQL:
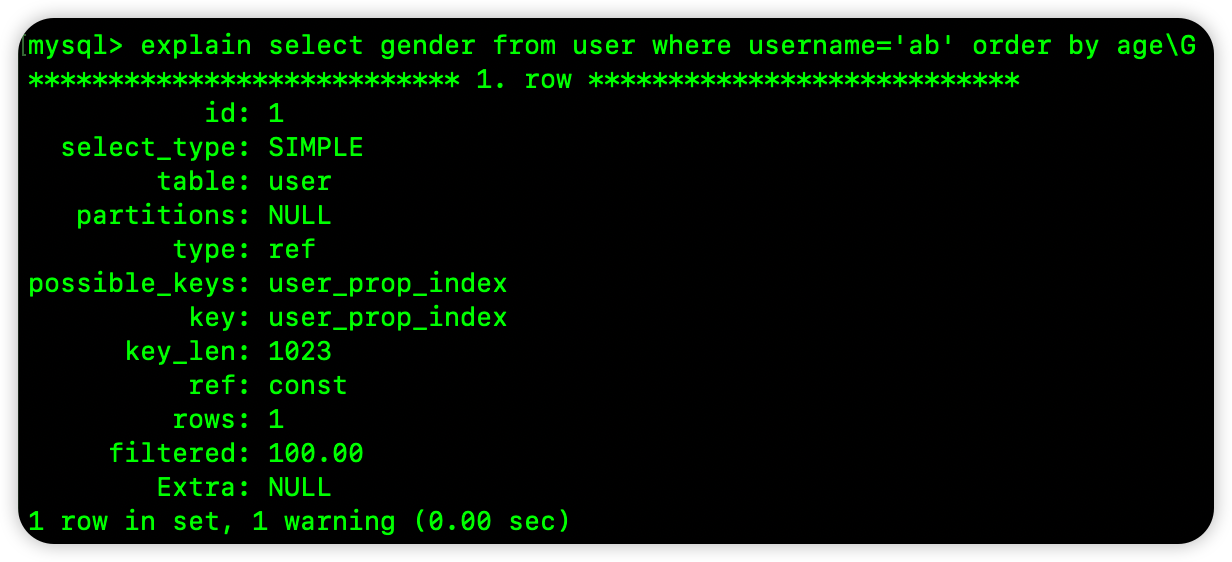
select gender from user where username='ab' order by age
这个 SQL 中已经给 username 指定了具体的值了,在前面的 B+Tree 中,当 username 已经确定的时候,那么接下来就是按照 age 排序的,如果 age 相同则是按照 address 排序,所以上面这个 SQL 是可以通过索引排序的:
2.5 案例五
再来看如下 SQL:
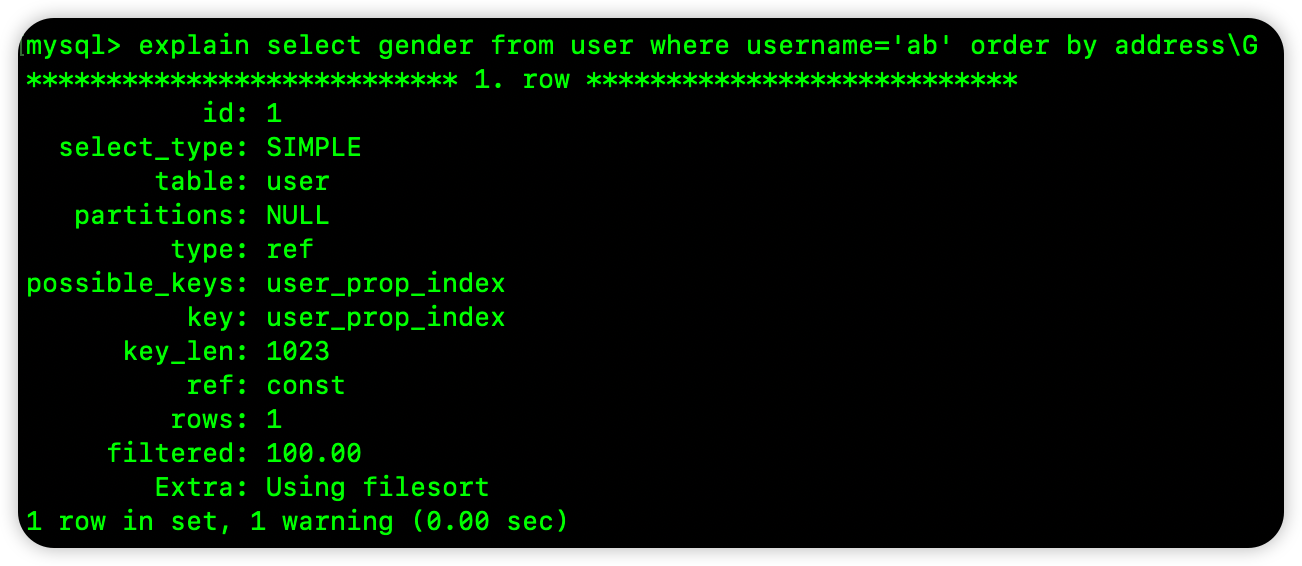
select gender from user where username='ab' order by address
这个 SQL 中 username 也是给指定了具体的值了,但是排序却是按照 address 排序的,小伙伴们知道,当 username 确定后,首先是按照 age 排序,其次才是按照 address 排序,所以,对于上面这个 SQL,从索引树中读取出来的数据,顺序并不一定是按照 address 排的,所以上面这个 SQL 无法用到索引排序:
2.6 案例六
再来看下面这个 SQL:
select gender from user where username like 'a%' order by age
这个 SQL 中的查询条件 username 是范围搜索,当 username 是范围搜索的时候,就无法保证相应的 age 是有序的了,所以这个 SQL 也无法使用索引排序:
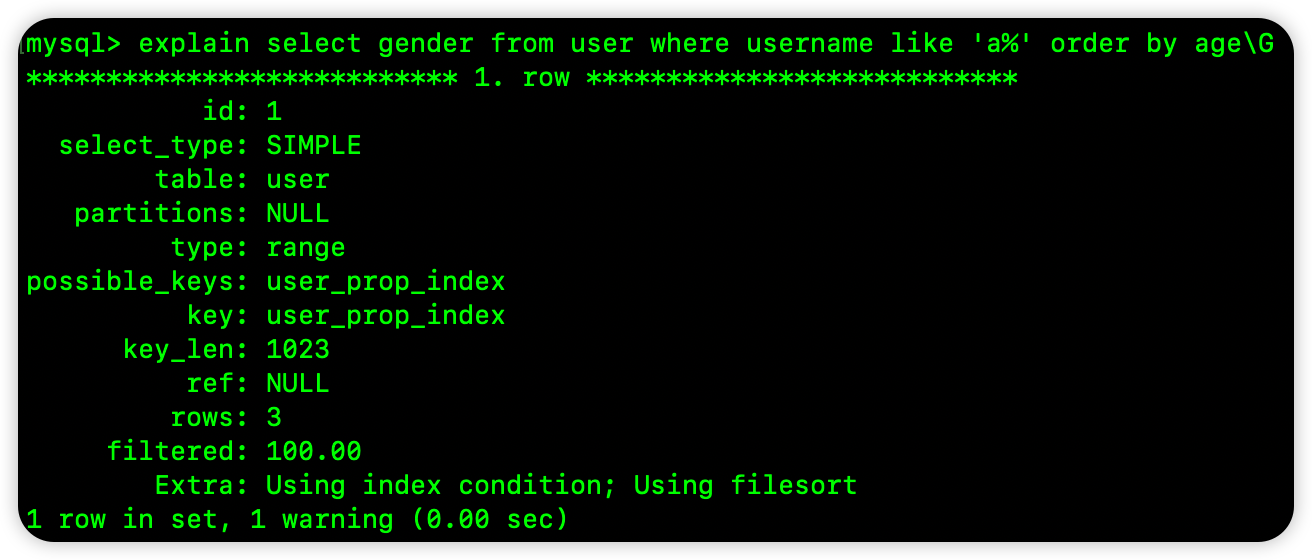
另外需要注意的是,像查询条件中的 IN 和 BETWEEN 这样的关键字,也算是范围搜索,如果 where 子句中出现这些关键字,也是有可能导致无法使用索引排序的。
2.7 案例七
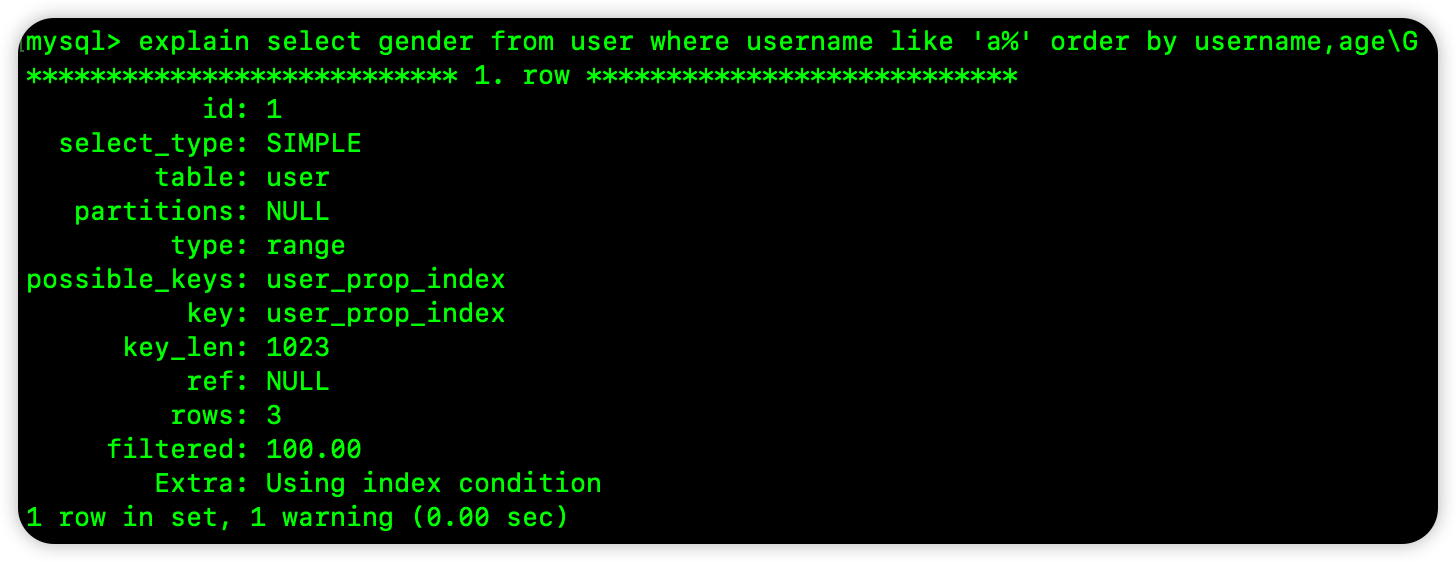
再来看下面这个 SQL:
select gender from user where username like 'a%' order by username,age
这个虽然 username 也是按照范围搜索,但是最终排序的时候却是按照 username 和 age 排序的,按照范围搜索拿出来的 username 和 age 本身就是有序的,所以这里也可以使用索引排序:
2.8 案例八
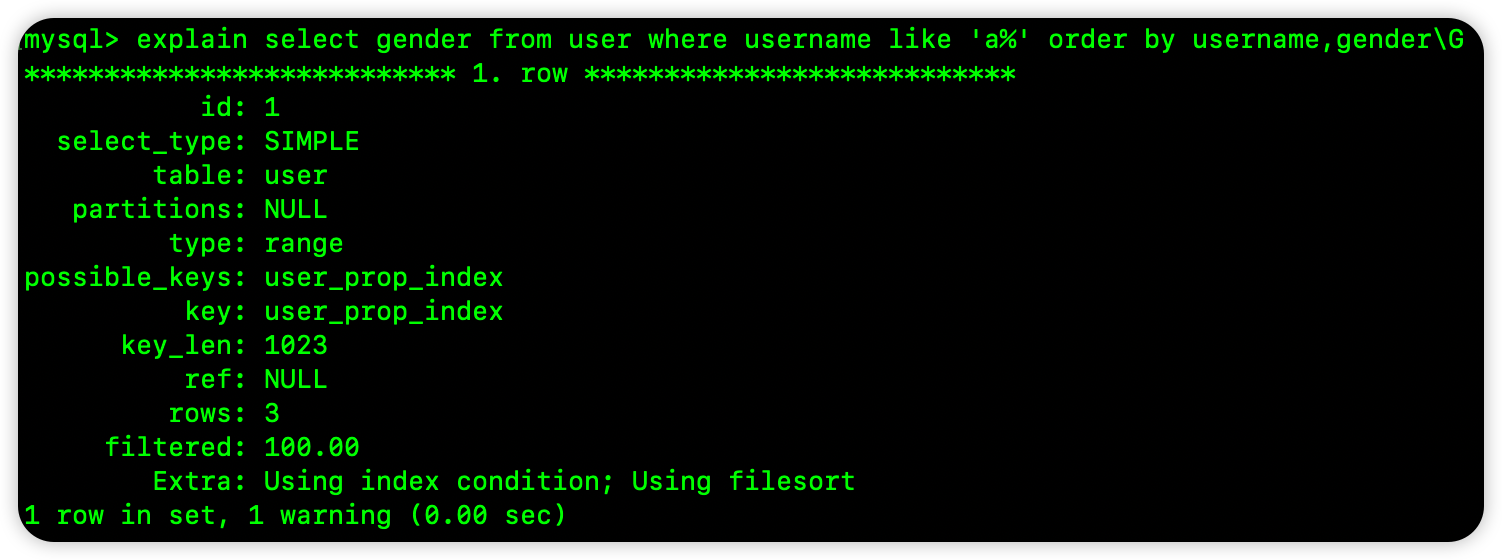
再来看下面这个 SQL:
select gender from user where username like 'a%' order by username,gender
这个 SQL 就不用多说了,排序字段中出现了索引之外的列,那肯定没法使用索引排序了:
总之,就是当我们根据 where 子句中的条件从 B+Tree 中定位到数据之后,定位到的这个数据究竟是否有序?如果有序且是 SQL 中要求的顺序,就能使用索引排序,否则就不可以。
现在我们再来回过头看一下一开始的结论,大家这个时候应该就好理解了:
只有当索引的顺序和 order by 子句的顺序完全一致,并且所有列的排序方向也都一致的情况下,MySQL 才能通过索引来对结果进行排序,同时,如果是联合索引,order by 子句也需要满足最左匹配原则。
3. 其他情况
3.1 多表联查
当我们在查询的时候是多表连接查询时,如果用到了排序,那么 order by 子句中涉及到的字段,必须全部在第一个表中,此时才会用到索引排序。
松哥举一个 TienChin 项目中的例子,TienChin 中有一个活动渠道表 tienchin_channel,还有一个活动表 tienchin_activity,活动表中引用到了渠道表的 id,我们来做如下一个多表联合查询:
select ta.name from tienchin_activity ta inner join tienchin_channel tc using(`channel_id`)
我们来看下这个 SQL 的执行计划:
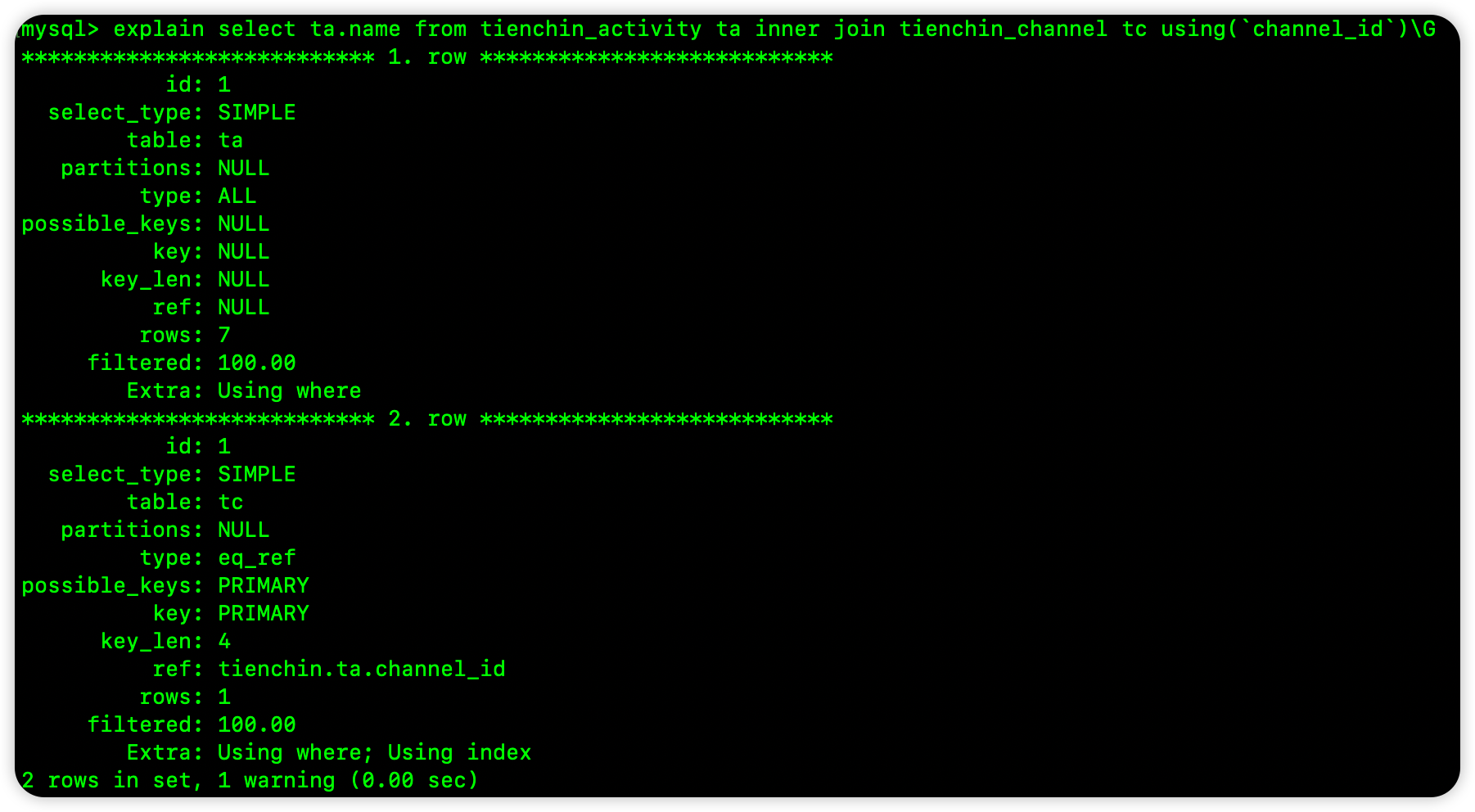
可以看到,在这个查询中,优化器将 ta 表作为了第一张表,tc 表作为了第二张表,那么根据前面的结论,如果使用第一个表中的索引排序,就会用到索引排序,第二张表的则用不了,我们来验证一下。
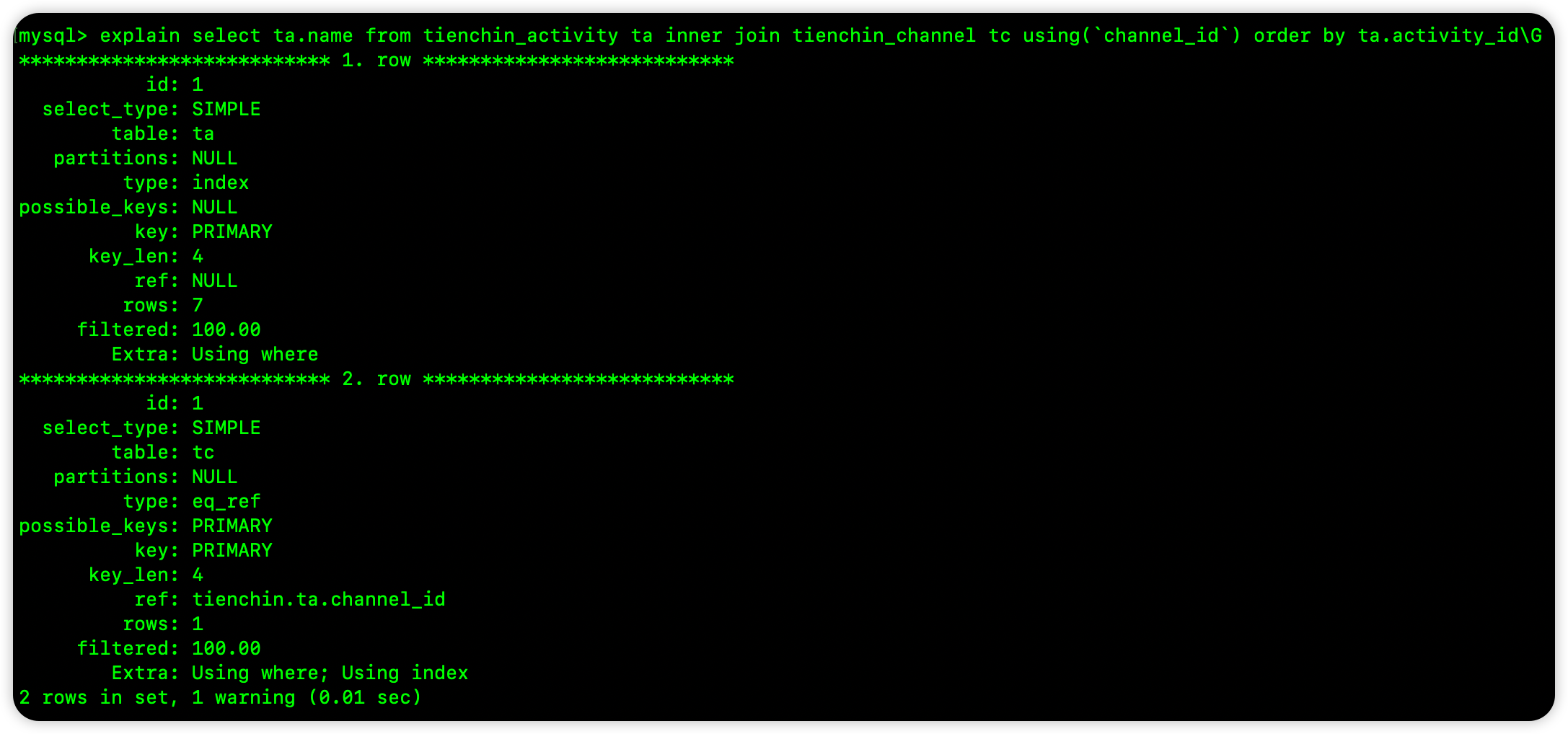

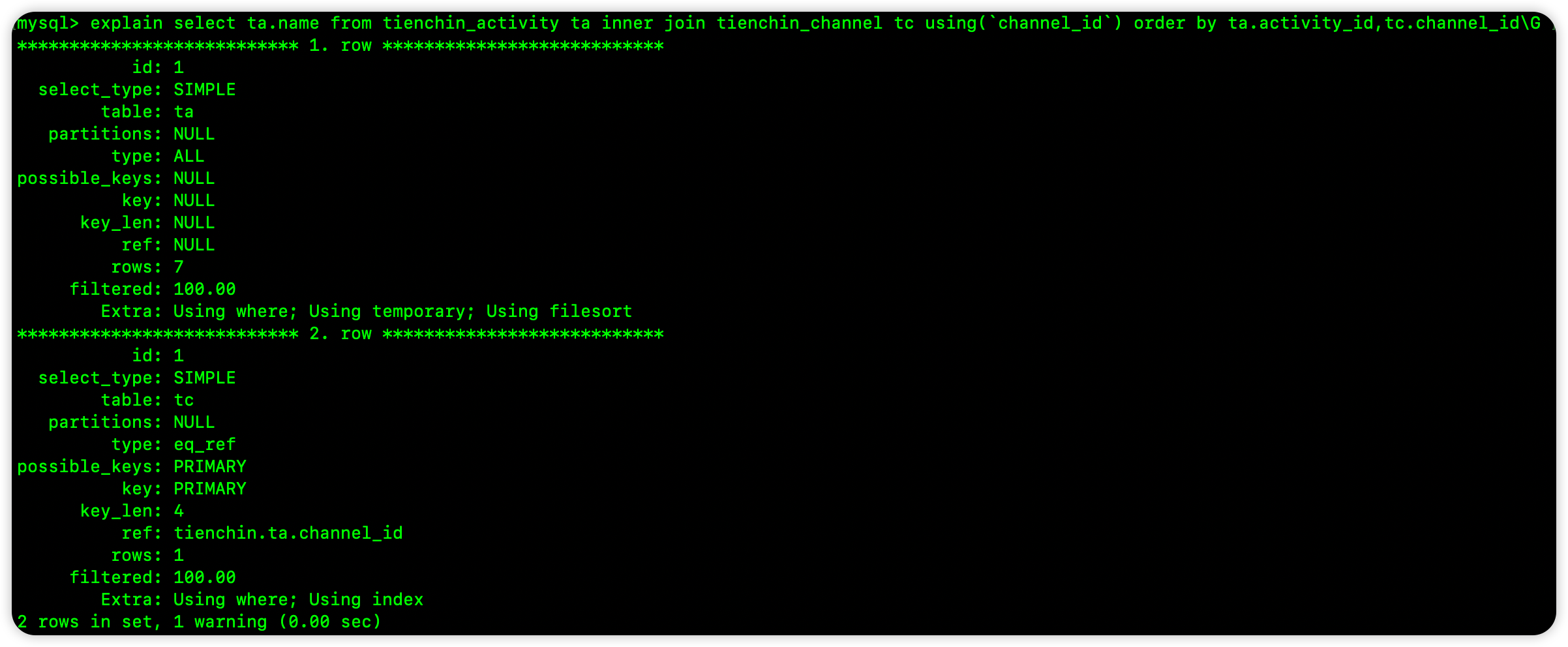
可以看到,如果是第一张表的索引,就用到了索引排序;如果是第二张表的索引,就没有用到索引排序,如果两张表的索引都用了,也不会使用索引排序。
3.2 order by null
还有一种特殊的情况就是 order by null,不知道有没有小伙伴见到过有人这样写?
在 MySQL8 之前,默认会按照 group by 的字段进行排序,此时加上 order by null 就是告诉 MySQL,不用帮我排序了,直接返回结果就行了,因为如果不加 order by null,则可能会进行 filesort 排序,降低查询效率。
不过从 MySQL8 开始,默认已经不会按照 group by 字段排序了,所以这句现在其实可以不用写了。
4. 小结
好啦,关于 MySQL 中的索引排序就和小伙伴们聊这么多,希望大家都有所收获~




![[SWPUCTF] 2021新生赛之Crypto篇刷题记录(11)](https://img-blog.csdnimg.cn/d5dc9f95a3c345719652cfbb39455ccb.png)