目录
1、鲁棒性
2、泛化能力
1、鲁棒性
定义:在统计学领域和机器学习领域,对异常值也能保持稳定、可靠的性质,称为鲁棒性。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持某些性能的特性。有一个与鲁棒性很相似的概念叫模型的泛化能力。
鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,也是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。根据对性能的不同定义,可分为稳定鲁棒性和性能鲁棒性。以闭环系统的鲁棒性作为目标设计得到的固定控制器称为鲁棒控制器。
鲁棒性包括稳定鲁棒性和品质鲁棒性。一个控制系统是否具有鲁棒性,是它能否真正实际应用的关键。因此,现代控制系统的设计已将鲁棒性作为一种最重要的设计指标。
AI模型的鲁棒可以理解为模型对数据变化的容忍度。假设数据出现较小偏差,只对模型输出产生较小的影响,则称模型是鲁棒的。 Huber从稳健统计的角度给出了鲁棒性的3个要求:
- 模型具有较高的精度或有效性。
- 对于模型假设出现的较小偏差(noise),只能对算法性能产生较小的影响。
- 对于模型假设出现的较大偏差(outlier),不能对算法性能产生“灾难性”的影响。
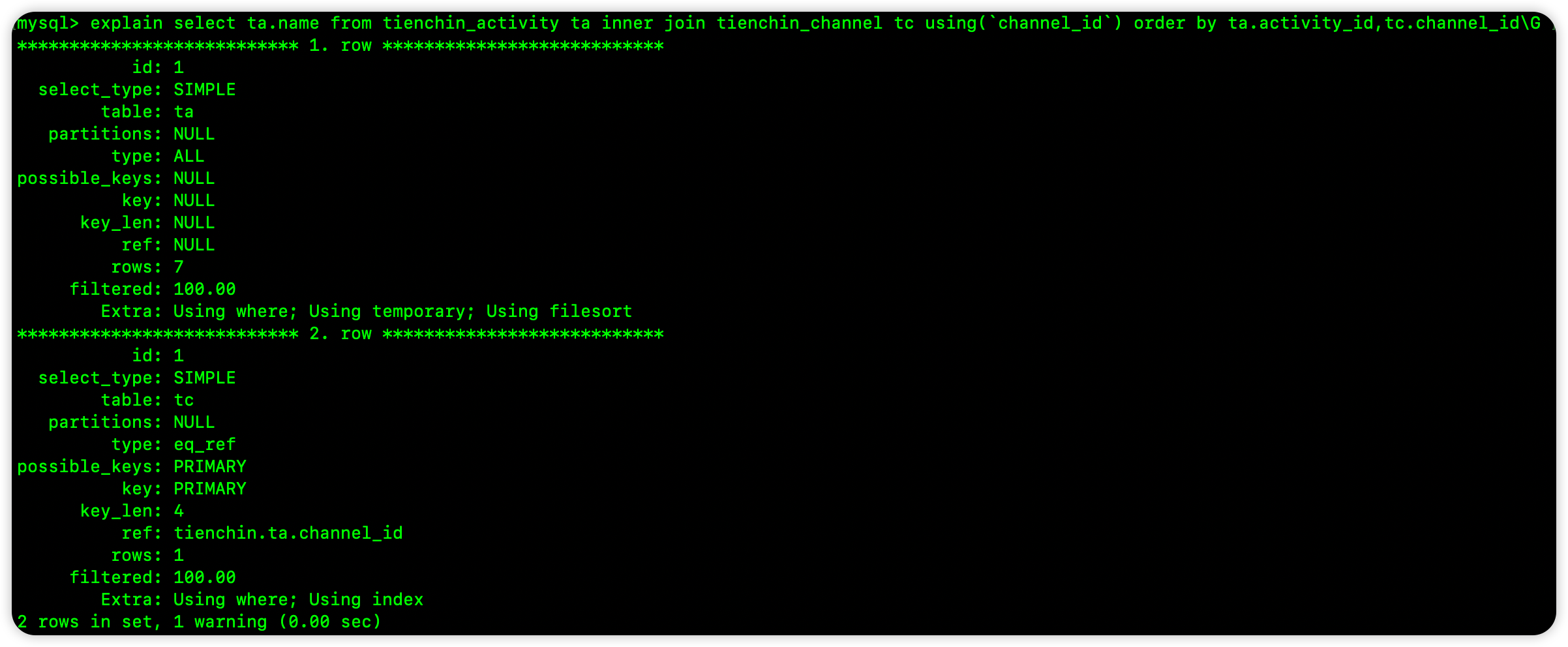
我们先来看一组例子理解鲁棒性的表现:

如上图,生成的对抗样本中的扰动对人类视觉来说不敏感,但是对于模型来说,原本以57.7%的概率被判成熊猫的图片在修改后以99.3%的概率被判成了长臂猿。则该系统的抗干扰性差,鲁棒性低。
提升鲁棒性的方法:
- 从数据上提升性能
收集更多的数据、产生更多的数据、对数据做缩放、对数据做变换、特征选择、重新定义问题
- 从算法上提升性能
算法的筛选、从文献中学习、重采样的方法
- 从算法调优上提升性能
注意力机制(给与每个像素权重,来衡量像素间的相关性SPNet)、模型可诊断性、权重的初始化、学习率、激活函数、网络结构、batch和epoch、正则项、优化目标、提早结束训练
- 用融合方法提升效果
模型融合、视角融合、stacking、多尺度融合(使用不同尺度的卷积核,增加模型的感受野,典型代表金字塔Deeplab系列)
- 增加模型宽度
将通道分成多组,每组单独进行卷积,然后再将通道合成可以减少模型的参数,提高模型准确率,增加鲁棒性(ResNext)。
2、泛化能力
(generalization ability)是指机器学习算法对新鲜样本的适应能力,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
根据泛化能力好的网络设计的神经网络控制器的鲁棒性也会有所改善。泛化能力指对未知数据的预测能力。例如小样本。
提升模型泛化能力的方法:
- 从数据角度上来说。可以通过数据增强、扩充训练集等方法提高泛化能力。
- 在训练策略上,可以增加每个batch size的大小,进而让模型每次迭代时见到更多数据,防止过拟合。
- 调整数据分布,做训练数据集的类别均衡。
- 调整网络结构。如果数据集较小,可以降低模型复杂度防止过拟合。如果数据集较大,可以尝试更加复杂的模型。
- 减少过拟合的方法也可以提升模型的泛化能力。
模型泛化能力的评估:用测试集对模型进行评估。
通常有下列方法:
- 留出法
hold-out。 K折交叉验证法cross validation。- 留一法
Leave-One-Out:LOO。 - 自助法
bootstrapping。