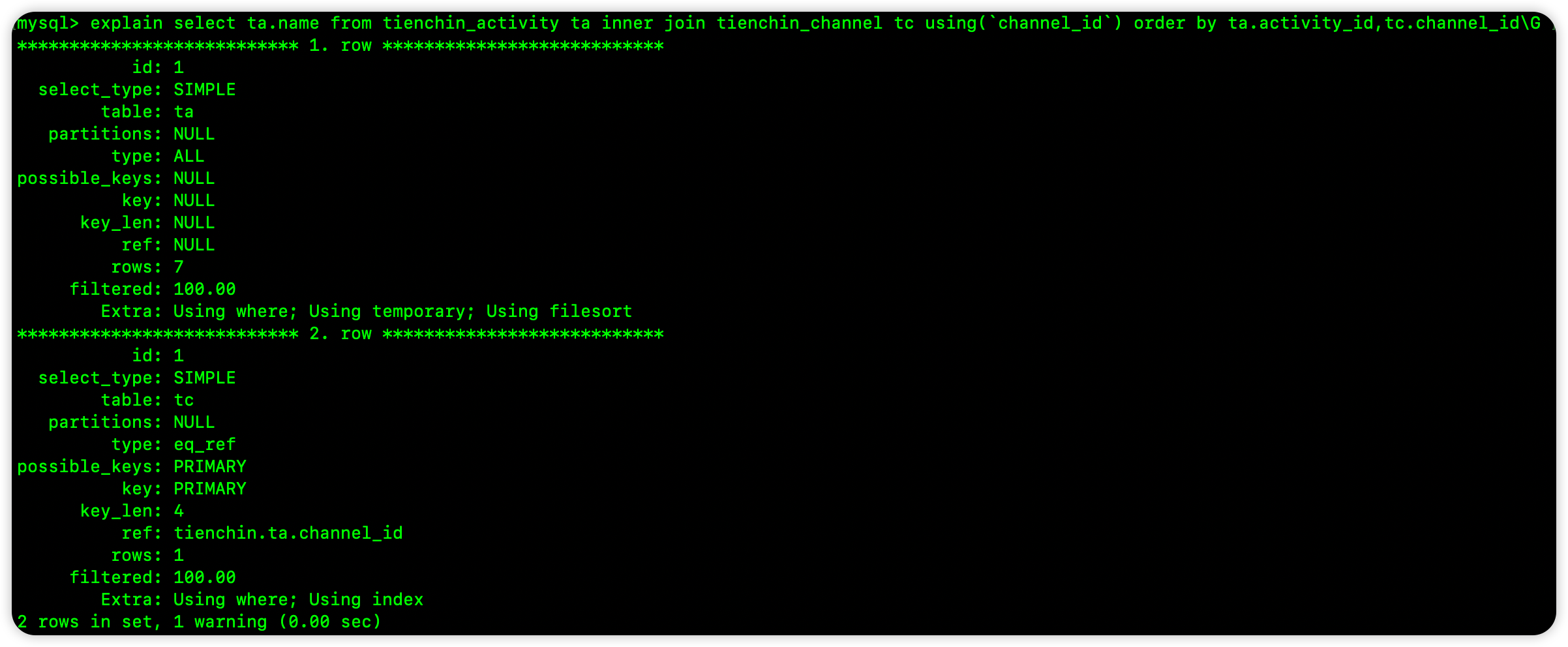
Java-Redis缓存穿透,击穿,雪崩和布隆算法
- 1.缓存穿透概念:
- 2.如何解决缓存穿透:
- 3.什么是缓存击穿?
- 4.什么是缓存雪崩?
- 5.导致缓存雪崩的原因:
- 6.缓存穿透,缓存击穿,缓存雪崩的区别:
1.缓存穿透概念:
当一个用户想要查询数据时,发现redis缓存里面没有,就会向mysql中发送请求查询,发现数据库也没有数据时,于是就查询失败。当秒杀场景时,用户访问量很大,就会给服务器很大压力,相当于出现缓存穿透。
2.如何解决缓存穿透:
1)将mysql中查询到数据,存到redis中。 比如从数据库中查询-1,返回一个null值,把这个kv键值对存储到redis中。但是如果id是一个UUID的话(动态的),会取得适得其反的
2)使用布隆过滤器存储未来可能查询的字段,但是因为不影响整体链路的性能,需要把布隆过滤器放到内存中,所以如果数据过大,会导致内存紧张。如何把重量级过滤器转变为轻量级的?
布隆算法!! : 通过错误率来换取空间的一个算法
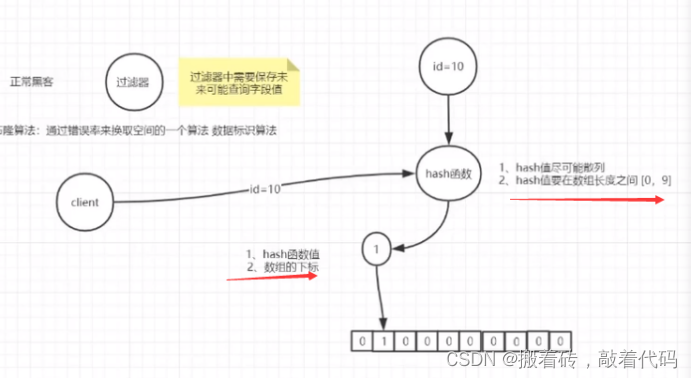
注解: 假设在布隆过滤器创建一个数组,长度是10,并且是二进制的。我们先把数据库中id=10通过hash函数(1.hash值进可能是散列表 2.hash值要在[0,数组容量-1]),得到一个value值,标识在过滤器里。
但是布隆算法会有错误率,导致原因 hash碰撞导致。但是 你如果还有一个客户端(id=983)去访问布隆过滤器,由于未被标识过,返回的是未被标识 ,那这个是肯定在数据库中没有的,用类似反证的手法。
布隆过滤器总结:
1)布隆过滤器告诉你数据存在,但是它不一定存在(由于hash碰撞导致的)
2)布隆过滤器告诉你数据不存,那么它肯定不存在
3)布隆算法的错误率受数据长度的影响 和 hash函数的个数影响
为什么 hash函数的个数会影响错误率?
假设id=10,通过布隆过滤器 三个hash算法 那么假设最后的hash值为 1,5,10 。之后我们客户端需要查询id=100是否存在,那么id=100经过布隆过滤器是三个hash算法,它可能为1的错误率为1/10,5的错误率为1/10,10的错误率为1/10,它总错误率为(1/10)的三次方,错误率降低。注意: hash函数的个数不是越多越好,3-5个差不多
3.什么是缓存击穿?
假设一个客户端 一个tomcat 一个redis(里面有一条热门数据 时间期限为1天) mysql
1天之内 是客户端---- tomcat ----redis
1天之后 客户端----tomcat----mysql 这种情况就叫缓存击穿
总结: redis中只有一条有效数据,当过了这个时间,tomcat就穿过redis,直接访问数据库,这个就叫缓存击穿
缓存击穿和缓存穿透的区别:
缓存击穿是缓存穿透的一种特殊表现形式
解决方案:
1)一般中小型公司不需要解决,因为很少有业务场景会有热门数据一直存在
2)分布式锁 可以解决多个节点上多个进行的排队问题
需要加锁的条件:
1)有共享资源
2)共享资源互斥
3)多任务的情况下
分布式锁如何解决缓存击穿:
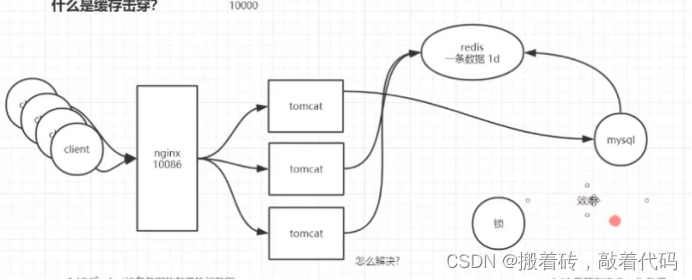
注释: 假设我有三台服务器,通过nginx代理了三台tomcat,假设客户端需要查询id=10的值,那么三台tomcat都先向redis缓存里面去找,发现缓存没有,那么会直接去找mysql数据。而当我加了一个分布式锁之后,那三台tomcat的请求先被我锁拦截,只有一台tomcat可以拿到这个锁,查找数据库id=10的值,等查询完成后,缓存到redis中,而这时候其他俩个tomcat就不用等着再去拿锁,直接去redis缓存中拿值,但是会存在效率问题。
4.什么是缓存雪崩?
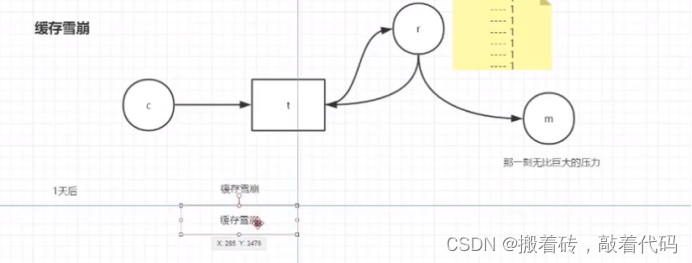
一台client 一台tomcat 一个redis(redis里面存有很多热点数据 时效1天) 一个mysql
当一天后,redis里面的很多热点数据时效,然而客户端还是发起了这些热点数据的请求,此时tomcat在redis里面查询不到数据,找到了mysql,这一次mysql数据库承受了巨大的压力,这个就叫缓存雪崩。
5.导致缓存雪崩的原因:
1)数据有效期都一致 ====>解决方法: 给数据设置不同的有效期
2)redis挂机 ===>设置redis集群
6.缓存穿透,缓存击穿,缓存雪崩的区别:
缓存击穿(1条数据失效导致的问题)和缓存雪崩(多条数据时效导致的问题) 都是缓存穿透的一种特殊表现形式

![[译] Dart 3 发布了](https://img-blog.csdnimg.cn/img_convert/b84aa8812b8251b9c1997ef667ab1a0e.png)