文章目录
- 包装dataset
- 构建词库
- 1.列举数据源
- 2. 遍历数据
- 3. 列举特殊符号
- 4. 构建词库 Field::vocab_cls
- load_vectors
- 构建读指针 data.BucketIterator
在上一文,我们学习了基于torchtext编写lstm模型的实践案例,本文将结合上文案例,深入案例代码,并借此学习torchtext的源码。
包装dataset
深入调试可知,首先DataFrameDataset.splits会要对train、test或val数据集调用构造函数,
@classmethod
def splits(cls, fields, train_df, val_df=None, test_df=None, **kwargs):
train_data, val_data, test_data = (None, None, None)
data_field = fields
if train_df is not None:
train_data = cls(train_df.copy(), data_field, **kwargs)
if val_df is not None:
val_data = cls(val_df.copy(), data_field, **kwargs)
if test_df is not None:
test_data = cls(test_df.copy(), data_field, True, **kwargs)
return tuple(d for d in (train_data, val_data, test_data) if d is not None)
构造函数中会对这个dataframe遍历,调用data.Example.fromlist。
class DataFrameDataset(data.Dataset):
def __init__(self, df, fields, is_test=False, **kwargs):
examples = []
for i, row in df.iterrows():
label = row.target if not is_test else None
text = row.text
examples.append(data.Example.fromlist([text, label], fields))
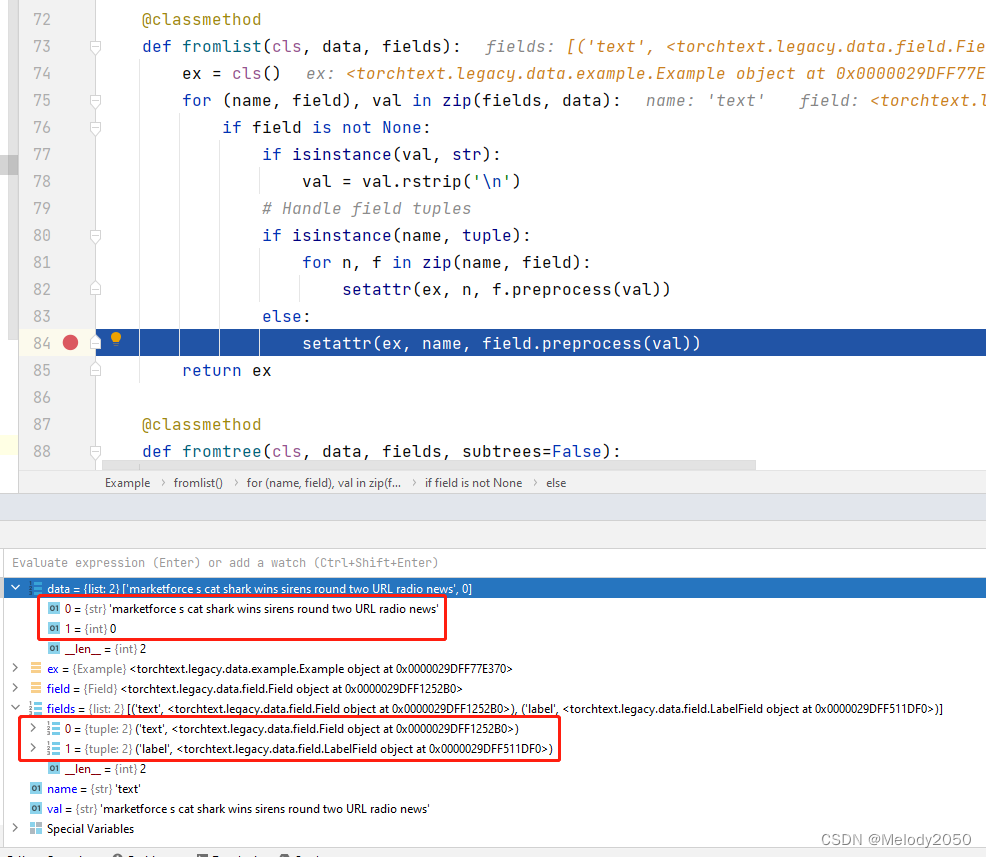
再深入这个fromlist方法,会被调用的if-else语句用注释进行了标注。
@classmethod
def fromlist(cls, data, fields):
ex = cls()
for (name, field), val in zip(fields, data):
if field is not None:
if isinstance(val, str):
val = val.rstrip('\n') # 被调用处
# Handle field tuples
if isinstance(name, tuple):
for n, f in zip(name, field):
setattr(ex, n, f.preprocess(val))
else:
setattr(ex, name, field.preprocess(val)) # 被调用处
return ex
截屏调试时的变量情况:
- data有两个元素,分别是str形式的评论和0-1标签。
- fields也有两个tuple元素,key为"text"的Field对象和key为"label"的LabelField对象。
preprocess函数会被调用,深入代码,下图中的红框部分被调用。调用了Field::tokenize后就返回x了,所以该函数只做了调用tokenize一件事。从下方截图也能看出,处理后的变量x是一个list的单词。
并没有调用
self.preprocessing(x)。
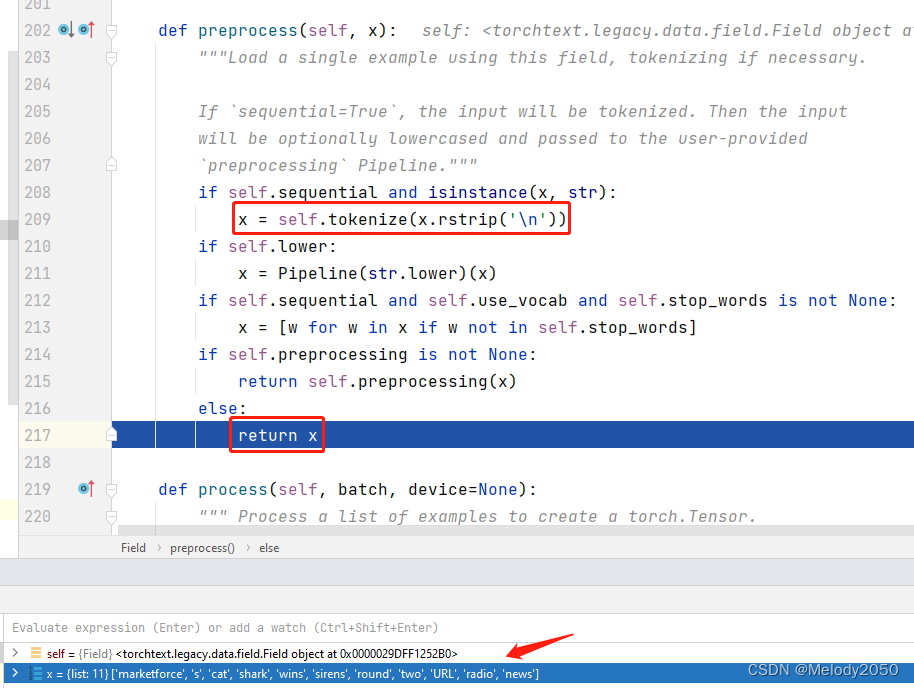
然后,这里的tokenize变量是一个partial偏函数,它在构造函数里赋值,调用的是torchtext的_spacy_tokenize函数。
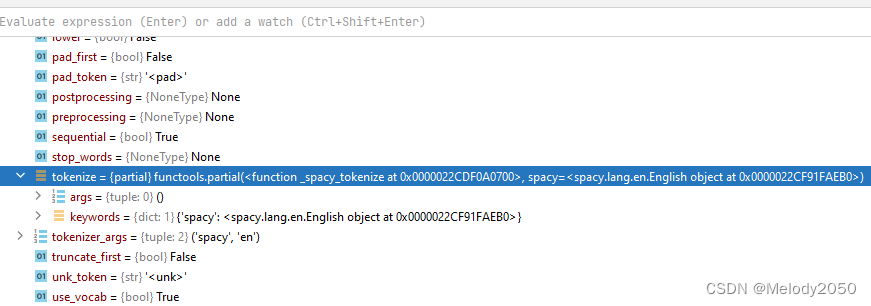
self.tokenize = get_tokenizer(tokenize, tokenizer_language)

该函数使用了spacy的分词器功能,spacy是一个nlp工具库,可参考nlp工具库spacy。
所以总结而言,tochtext的data.Example.fromlist会将dataframe的单行数据转化为Example对象。每一列数据(句子和标签),都接受对应Field的预处理,然后设置到Example的属性中。而Dataset会持有这一组Example对象。
构建词库
这一步的核心是Field::build_vocab被调用,用于构建词库。
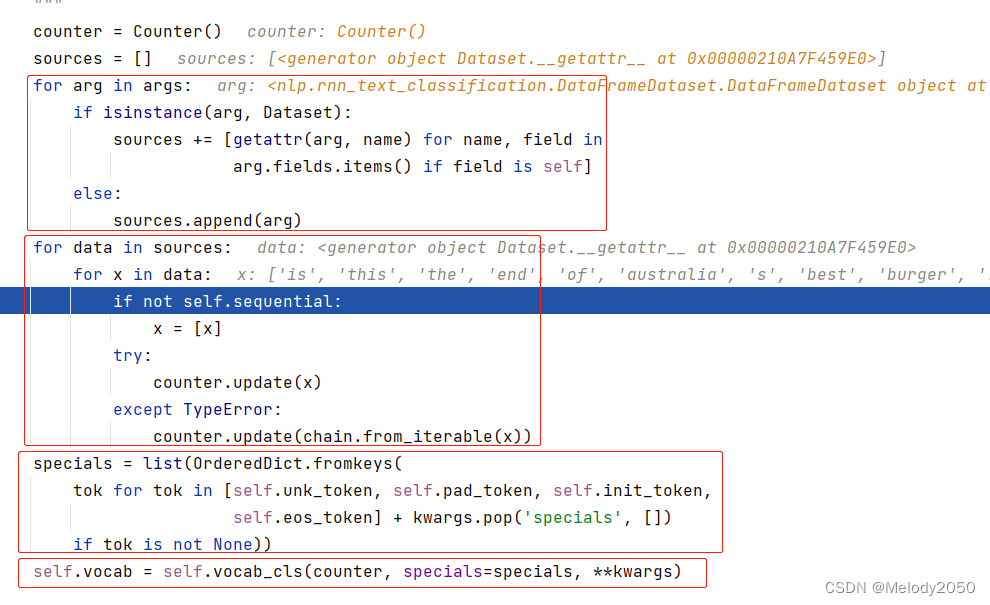
该函数的行为有4步,分别用红框标记了:
- 列举数据源
- 遍历每个数据源的每条数据。在本例中,只有一个数据源,它的效果相当于遍历
train_ds.text,而每条数据x都是字符串的list - 列举特殊符号,比如unk_token, pad_token等等。
1.列举数据源
看向第一个红框,为了编程鲁棒性,写的很复杂。sources保存的是一个个数据源,可供遍历。我们只按简单情况分析,在调用TEXT.build_vocab(train_ds,...时,只传入了一个Dataset参数,所以只有该对象的text成员会被添加到sources中。
2. 遍历数据
虽然为了编程鲁棒性,有两层for循环,但由于本文情况只有一个数据源,所以for循环的效果相当于下图。每个x都是字符串数组而已。

函数维护了一个Counter对象,它会对每种单词作计数。其Counter::update的demo如下:
from collections import Counter
c = Counter()
c.update(["the", "apple", "tree"])
# Counter({'the': 1, 'apple': 1, 'tree': 1})
print(c)
所以当这一步执行完时,Counter维护了每个单词的出现次数。
3. 列举特殊符号
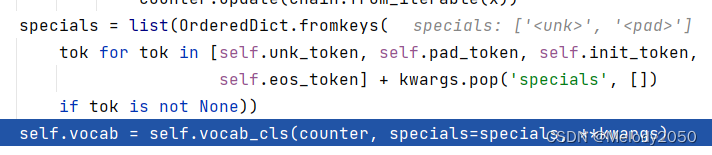
这一步写得复杂,只要管specials是一个字符串的list就好,内容是单纯的['<unk>', '<pad>']。不明白为什么要这么麻烦地将list转换为dict,又转换回list。
4. 构建词库 Field::vocab_cls
深入self.vocab_cls来到了Vocab对象的构造函数(没明白为什么,没看到对该变量的赋值)。
这个函数太长,此处就不截图了,仅讲结论。感兴趣可以自行调试。
- 准备变量。初始化
min_freq、max_size等参数。 - 将单词按频率、字典序排序,得到
words_and_frequencies。 - 生成
self.itos和self.stoi,前者是list,用于将编号转换为单词;后者是dict,用于将单词转换为编号。 - 调用
load_vectors,为每个词库里的单词加载向量,这些向量都是预先训练好的。
其它讲解如下:
specials_first会控制进行编号时,特殊符号编到头号(占据0号、1号等等),还是编到尾号(占据25000号、25001号)。在本例该值为True,所以编号时先编给specials符号。
defaultdict(self._default_unk_index)的用法可参考详解python中defaultdict用法、python中defaultdict用法详解。这里的函数在遇到未知单词时会直接返回0。_default_unk_index被调用会返回self.unk_index·,而后者在上一行被赋值了0。
def _default_unk_index(self):
return self.unk_index
words_and_frequencies的大小为14278,而itos的大小为14280,相差的2就是特殊符号<unk>和<pad>。下面是三个变量的截图。
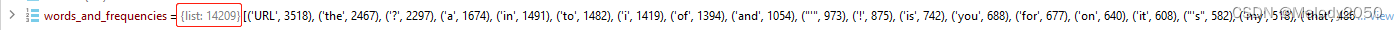


每次调试时,变量
counter的单词数都不同,这并不是因为spacy的分词策略不幂等,而是因为train_test_split的分割具有随机性,所以每次运行时,分得的train_df和valid_df内容都不一样。
load_vectors
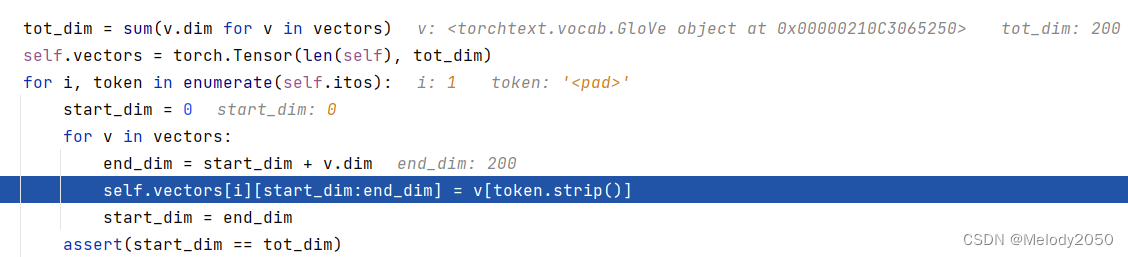
Field::vocab_cls在最后调用了load_vectors,其作用顾名思义,只是为了将词向量从已训练词库(本文是"‘glove.6B.200d’")中读出,并赋值给self.vectors。每个单词序号都有对应的词向量(包括特殊词汇<unk>、<pad>)
该函数
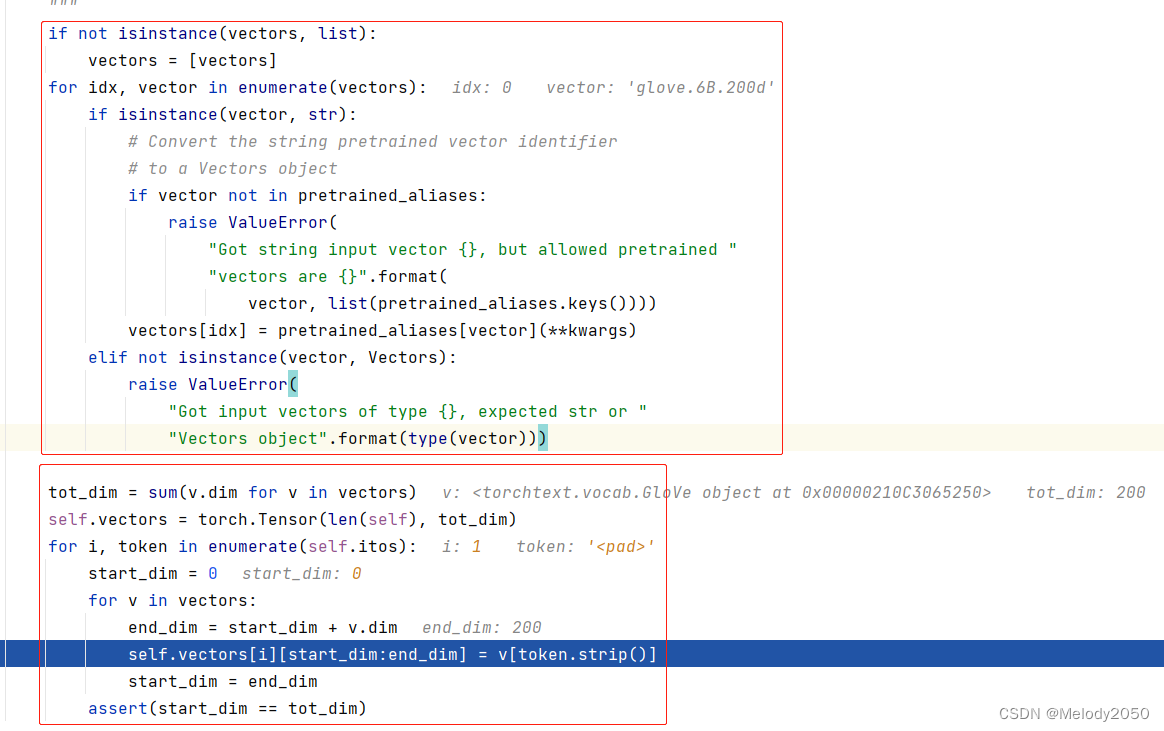
下图是
load_vectors的调试截屏。由于只使用一个词库,vectors长度仅为1。而从焦点行的行为可知,当使用了多个词库时,向量会横向拼接。
构建读指针 data.BucketIterator
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_ds, val_ds),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)

![[附源码]Python计算机毕业设计Django儿童早教课程管理系统论文2022](https://img-blog.csdnimg.cn/c0d3f0d9586e4a1682b774ff1c1b1709.png)


![[附源码]Python计算机毕业设计SSM科技项目在线评审系统(程序+LW)](https://img-blog.csdnimg.cn/14622f3e321642e4b8b4875bbb810cdf.png)


![[附源码]SSM计算机毕业设计疫情防控期间人员档案追寻系统设计与实现论文JAVA](https://img-blog.csdnimg.cn/69bb747af3064bb5b9be90331bb3c4f3.png)

![[附源码]Python计算机毕业设计SSM跨移动平台的新闻阅读应用(程序+LW)](https://img-blog.csdnimg.cn/07e0f53b03f1456fa16dd1a5328ba4ad.png)