企业大数据处理的挑战
随着大数据时代的到来,数据量迅猛增长,给传统的分析技术带来了巨大的冲击和挑战,企业面临着大数据处理的巨大挑战。将复杂的大数据处理问题进行简化,以便企业有更多人能够进行大数据处理,进而整体提升企业大数据处理能力显得尤为重要。可视化是简化大数据处理的关键。现有技术中有多种可视化方法,这些方法多是选择一种计算引擎作为底层计算引擎,并以一个固定的数据结构进行数据流转,无法以多种引擎、多种数据结构,支撑企业的大数据处理需求。
为满足企业多样化的大数据处理需求,必须能够同时运用各项前沿技术,对于可视化的大数据处理方案,需要能同时引入多种计算引擎,以便应对各种大数据处理场景。元年方舟数据中台,能接入多个大数据处理引擎,快速响应企业大数据处理需求,极大缩短大数据开发周期,提升企业研发实力,助力企业数字化转型。
可视化是支撑企业大数据处理的关键
可视化数据流是对数据处理流程的抽象,是对人们进行数据处理自然思路的可视化呈现。可视化数据流以插件为核心,插件与插件之间以线相连,每个插件代表一个数据处理步骤。
我们进行数据处理,不外乎是三个步骤,首先是输入数据,其次是处理数据,最后是输出数据。数据输入与输出要能够适配多种数据源类型,数据处理则要能包含各种数据处理常用逻辑。元年方舟数据中台提供的可视化数据流提供了简单易用的数据流设计界面,并提供了多种数据处理插件,能够满足用户各种场景的数据处理需求。

可视化数据流发展现状
目前很多厂商也有可视化数据流产品方案,但都有明显缺点。首先是只能接入一种开源计算引擎,无法接入多个开源计算引擎,限制了数据处理的灵活性;其次是只能依托一种数据结构进行数据分析,无法以任意数据结构进行数据分析,限制了数据分析的灵活性。
元年的多引擎可视化数据流实现方案
元年的可视化数据流方案是一种多引擎可视化数据流实现方案,一个可视化数据流可同时使用多个开源计算引擎,并能够用多种数据结构进行数据分析。
可视化数据流抽象体系
元年可视化数据流共有3个核心抽象,分别是步骤、引擎、数据结构,其关系如下图所示:
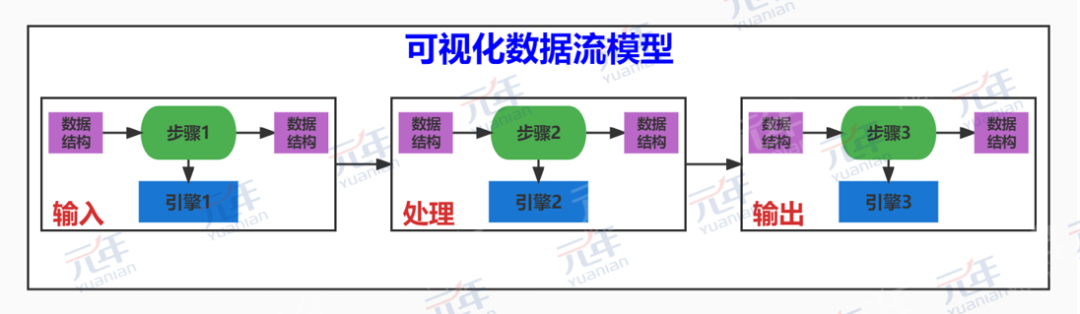
(图1:可视化数据流抽象图)
一个完整的可视化数据流由多个步骤构成,每个步骤均有输入与输出数据结构,每个步骤均可运用不同的引擎。
1、步骤
步骤代表数据处理流程中的一个步骤,无论是输入步骤、处理步骤、输出步骤,均是步骤。以一个‘步骤’抽象统御输入、处理、输出的好处是抽象层次更高,抽象体系更统一,更方便将公共优化机制运用于所有类型的步骤,比如每一步均可开启重试机制,一套重试机制可用于所有类型的步骤。
2、引擎
引擎代表底层实际执行数据处理任务的计算引擎。元年可视化数据流正是通过这一抽象,实现了接入所有前沿优秀计算引擎的能力。
3、数据结构
数据结构是数据流转的载体。可视化数据流的每一个步骤,均有输入与输出,每一个步骤的输入与输出数据结构可以是不同的,就能够令可视化数据流的流动形式与流动内容更为灵活。
可视化数据流设计界面
元年的可视化数据流设计界面,具有美观的、不同颜色的插件,具有网格状的画布,用户通过简单的拖拽与连线,即可完成数据流的绘制工作,极大地提升大数据开发效率。
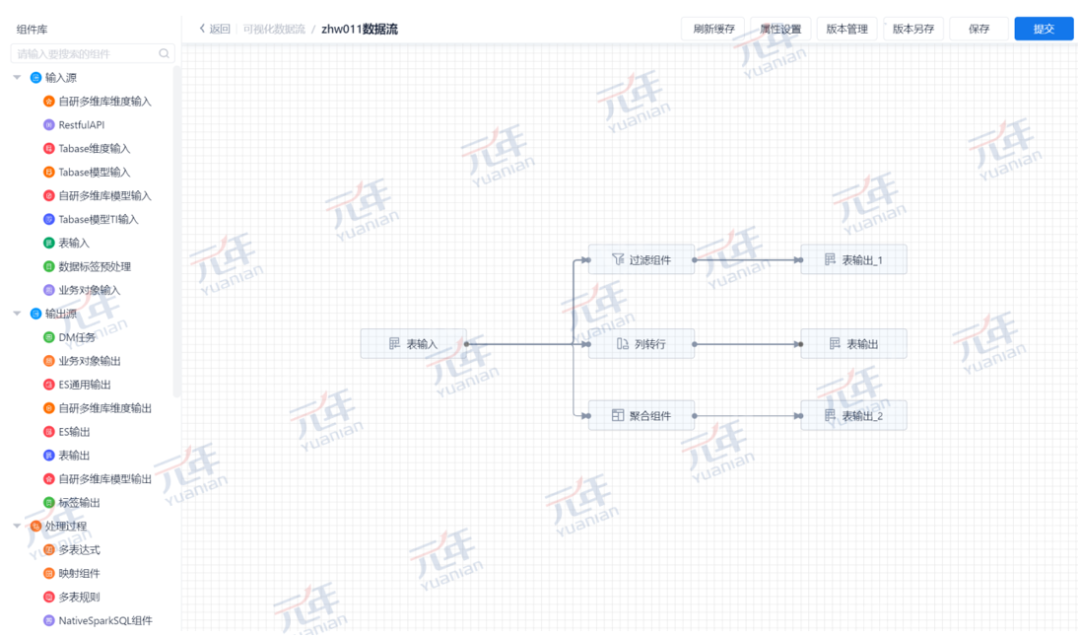
(图2:可视化数据流设计界面)
可视化数据流管理系统
元年的可视化数据流具有统一的、易用的管理系统,能够方便地进行数据流的增删改查,及可视化数据流运行情况的监控。
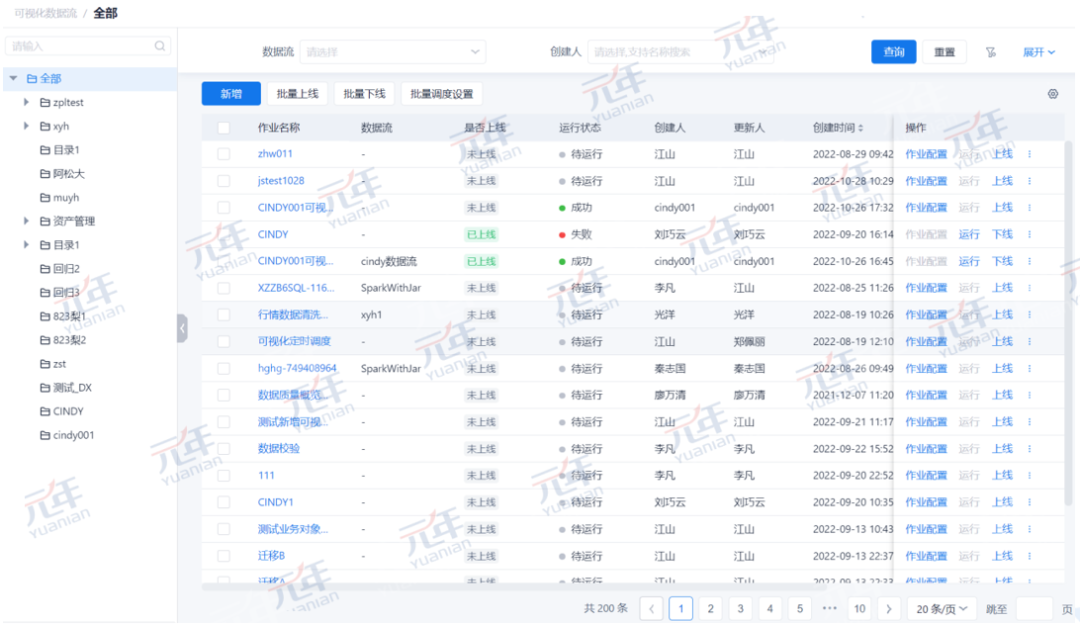
(图3:可视化数据流管理界面)
元年方舟数据中台集成多个开源计算引擎,一个数据流能同时运用多个开源计算引擎进行数据处理,极大提升了数据处理的灵活性;允许开发者以任意数据结构进行数据分析,一个数据流能运用多个数据结构进行数据分析,极大提升了数据分析的灵活性。
基于元年方舟的可视化数据流的可视化与灵活性,一方面极大提升用户数据开发的效率。传统数据开发,若想要运用大数据组件的计算能力,不仅需要有深厚的大数据技术底蕴,而且从开发到调试到部署,整个周期很长,而运用元年方舟的可视化数据流,则能将原来20人天的工作量,缩减到1人天,因用户不需要了解底层原理,也不需要繁琐的调试与部署,只需要通过拖拉拽的方式,实现业务逻辑,就能轻松完成大数据处理工作。一方面有利于用户进行技术沉淀,提升企业技术复用能力。元年方舟的可视化数据流本质上是解耦了数据开发的各个环节,使得通用数据处理逻辑,能以插件的方式沉淀下来,形成企业可复用的技术资产。
最后我们看一个真实的案例,通威集团在引入元年数据中台之后,平滑地将原来的数据开发逻辑迁移到可视化数据流,并将通用数据处理逻辑提取出来,沉淀为可复用的插件。依托可视化数据流的可视化能力与衔接数据处理逻辑的能力,以拖拉拽的方式,复用通用插件,迅速定制开发了多个新的数据处理作业,同时开发成本、测试成本、运维成本大幅降低,提升了整个数据团队的工作效率。

![[附源码]SSM计算机毕业设计疫情防控期间人员档案追寻系统设计与实现论文JAVA](https://img-blog.csdnimg.cn/69bb747af3064bb5b9be90331bb3c4f3.png)

![[附源码]Python计算机毕业设计SSM跨移动平台的新闻阅读应用(程序+LW)](https://img-blog.csdnimg.cn/07e0f53b03f1456fa16dd1a5328ba4ad.png)