文章目录
- 📚PageRank概述
- 🐇什么是PageRank
- 🐇PageRank的简化模型
- 🐇PageRank的随机浏览模型
- 📚实验目的
- 📚实验平台
- 📚实验内容
- 🐇在本地编写程序和调试
- 🐇在集群上提交作业并执行
- 🥕Mapreduce方法
- 🥕Spark方法
- ⭐️代码
- ⭐️打包过程
📚PageRank概述
🐇什么是PageRank
- PageRank是一种在搜索引擎中根据网页之间相互的链接关系计算网页排名的技术。
- PageRank是Google用来标识网页的等级或重要性的一种方法。其级别从1到10级,PR值越高说明该网页越受欢迎(越重要)。
- 被许多优质网页所链接的网页,多半也是优质网页。一个网页要想拥有较高的PR值的条件:
- 有很多网页链接到它
- 有高质量的网页链接到它
🐇PageRank的简化模型
-
可以把互联网上的各个网页之间的链接关系看成一个有向图。
-
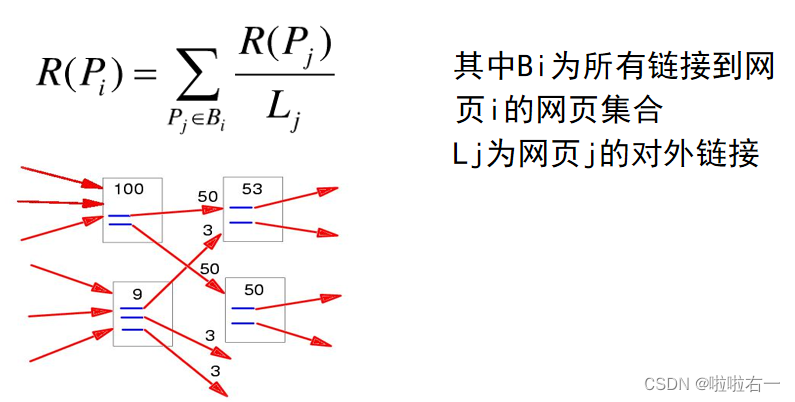
对于任意网页Pi,它的PageRank值可表示为:
-
从定义上来看,一个网页的PR值就是其他网页的PR值平均分流后传入到的此网页的总PR值。
-
PR值的计算就是经过多次迭代不断更新PR值直到满足一定的收敛条件。
- 实际的网络超链接环境没有这么理想化,PageRank会面临两个问题:
- 排名泄露:指存在网页出度为0,那么网页总的PR值在迭代过程中,指向这一个网页的有向边会不断流失PR值。(因为该网页X的PR值在迭代中用不上,相当于流失掉了)最终整个图的PR值都是0;
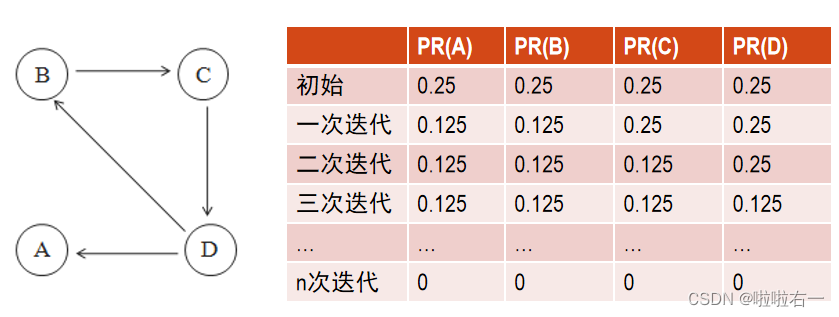
- 排名下沉:整个网页图中若有网页没有入度链接,如节点A所示,其所产生的贡献会被由节点B、C、D构成的强联通分量“吞噬”掉,就会产生排名下沉,节点A的PR值在迭代后会趋向于0。
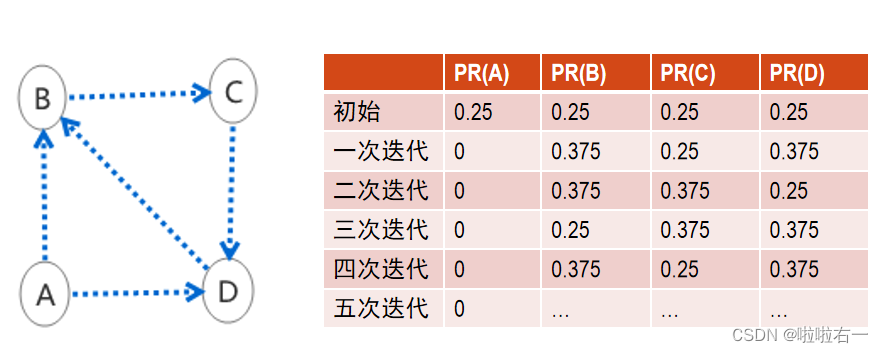
- 排名泄露:指存在网页出度为0,那么网页总的PR值在迭代过程中,指向这一个网页的有向边会不断流失PR值。(因为该网页X的PR值在迭代中用不上,相当于流失掉了)最终整个图的PR值都是0;
🐇PageRank的随机浏览模型
假定一个上网者从一个随机的网页开始浏览,上网者不断点击当前网页的链接开始下一次浏览。但是,上网者最终厌倦了,开始了一个随机的网页,随机上网者用以上方式访问一个新网页的概率就等于这个网页的PageRank值,这种随机模型更加接近于用户的浏览行为。
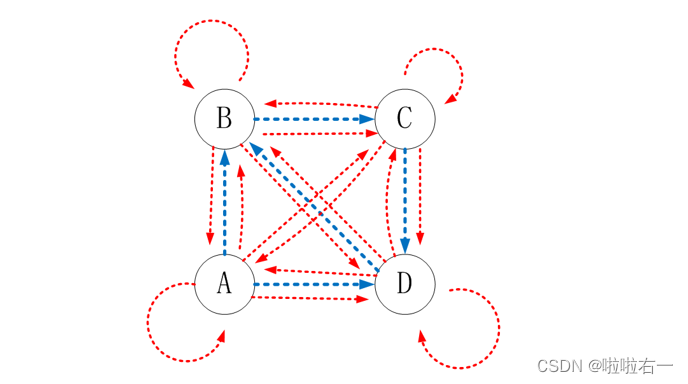
设定任意两个顶点之间都有直接通路,在每个顶点处以概率d按原来蓝色方向转移,以概率1-d按红色方向转移。

从模型上来看就是增加了1-d的部分。此时一个网页的PR值不仅仅取决于指向自己的网页这一部分(所占权值为d),还有另外一部分来自于任意一个网页,可以认为有概率1-d是来自于其他网页随即浏览的跳转,值为1/N(总网页数为N)。
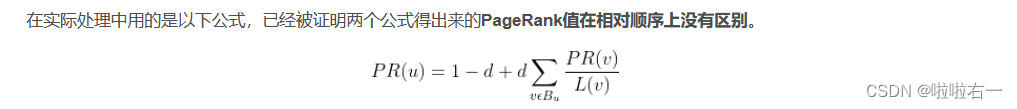
📚实验目的
PageRank 网页排名的算法,曾是 Google 关键核心技术。用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。通过对 PageRank 的编程在Hadoop 和 Spark 上的实现,熟练掌握 MapReduce 程序与 Spark 程序在集群上的提交与执行过程,加深对 MapReduce 与 Spark 的理解。
📚实验平台
- 操作系统:Linux;
- Hadoop 版本:3.2.2;
- JDK 版本:1.8;
- Java IDE:Eclipse 3.8。
- Spark 版本:集群环境为 3.2.1
📚实验内容
写在前面:本次实验综合参考了此博客(点此直达),本篇本地主要展示Mapreduce,其中Mapreduce的本地提交和集群提交和实验二的方法基本相同。Spark部分借助sbt打包提交到集群,其中sbt打包部分参考博客点此达。
🐇在本地编写程序和调试
input文件DataSet下载链接,数据集中每一行内容的格式:网页+\t+该网页链接到的网页的集合(相互之间用英文逗号分开)。
(图片来源:隆华爱读书我不爱读书所以我没书读)

package pagerank;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class pagerank
{
//用于处理原始输入得到所需输入格式
public static class GraphBuilder
{
public static class GraphBuilderMapper extends Mapper<Object, Text, Text, Text>
{
@Override
//map:逐行分析原始数据
//输入:<默认为行偏移量,text类型的数据,按行处理>
//key不是page,而是行偏移。value是整个<Page, {page_1,page_2,page_3,...}>
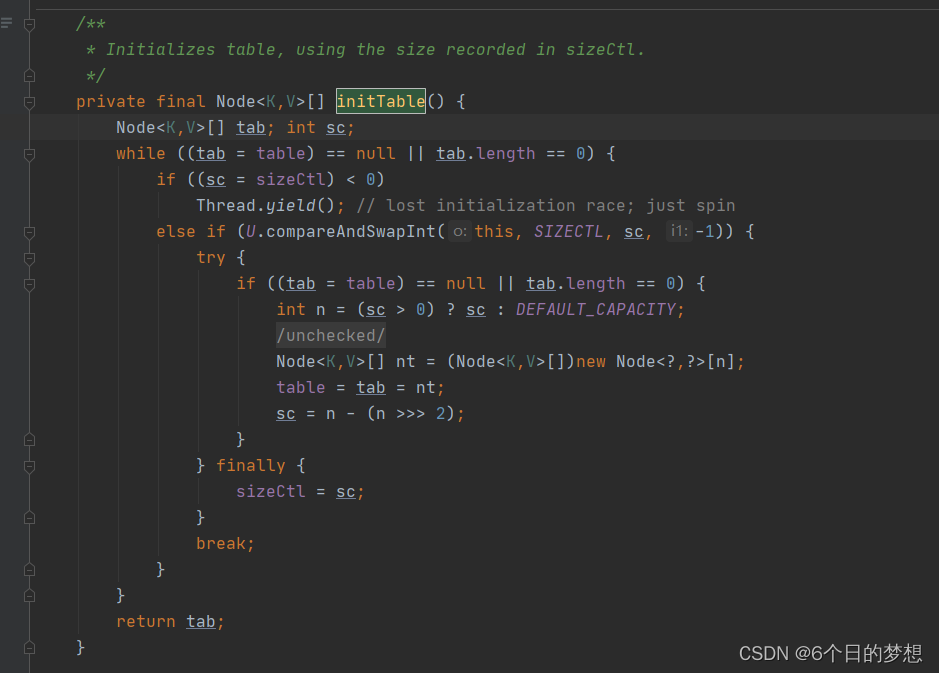
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
String initialpr = "1.0"; //初始化PR值
String[] temp = value.toString().split("\t");//按tab分片,temp[0]是网页,temp[1]是链接的网页
//输出<网页, (初始化PR值, 链接列表)>
//<Page,PR {page1,page2,page3,...}>
context.write(new Text(temp[0]), new Text(initialpr + "\t" + temp[1]));
}
}
//Reduce什么也不需要干,因此可以不写Reduce,直接将Map的输出作为最后的输出即可
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
Job job = Job.getInstance(conf, "GraphBuilder");
job.setJarByClass(GraphBuilder.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(GraphBuilderMapper.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
//迭代计算各个网页的PageRank值
public static class PageRankIter
{
private static final double d = 0.85; //damping阻尼系数
public static class PRIterMapper extends Mapper<Object, Text, Text, Text>
{
//map:逐行分析数据
//输入:<Page,PR {page1,page2,page3,...}>
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
//按tab分片,temp[0]是网页,temp[1]是初始PR值,temp[2]是链接(指向)网页
String[] temp = value.toString().split("\t");
String url = temp[0];
double cur_rank = Double.parseDouble(temp[1]);//转换成double类型的数据
if (temp.length > 2)
{//说明有链接的(指向的)网页
String[] link = temp[2].split(",");//按逗号分片
for (String i : link)
{
//输出:<链接的网页,当前排名/指向的网页的数量>
//对于pageList里的每一个page都输出<page,pr>
context.write(new Text(i), new Text(String.valueOf(cur_rank / link.length)));
}
}
//输出:<当前网页,&+链接的网页>
//将所有出边tuple[2]传递到Reduce,这里用一个‘&’作为分割,方便后续判断是哪一种输入类型,即value是pr还是pageList。
context.write(new Text(url), new Text("&" + temp[2])); // 做个标记"&"
}
}
public static class PRIterReducer extends Reducer<Text, Text, Text, Text>
{
//reduce:按行处理数据
//输入:<链接的网页,当前排名/指向的网页的数量>;<当前网页,&+链接的网页>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
double new_rank = 0;//用于累加PR
String outurl = "";
for (Text i : values)
{
//对输入的value首字符进行判断,如果是'&'表示这是一个图结构,那么就保存下来便于待会Reduce输出;如果不是,那么说明是pr值,进行累加。
String temp = i.toString();
if (temp.startsWith("&"))
{//有&标识符,标志着向的信息
outurl = temp.substring(1);//取出向的网页列表
}
else
{//存放的是计算的PR中间值
new_rank += Double.parseDouble(temp);//原始PR+中间计算值
}
}
new_rank = d * new_rank + (1 - d); //加上阻尼系数限制,计算最后的PR
//输出:<网页,新的PR值 指向的网页信息>
//<pagei,PR {page1,page2,page3,...}>
context.write(key, new Text(String.valueOf(new_rank)+"\t"+outurl));
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
Job job = Job.getInstance(conf, "PageRankIter");
job.setJarByClass(PageRankIter.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PRIterMapper.class);
job.setReducerClass(PRIterReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
//将PageRank值从大到小输出
public static class RankViewer
{
public static class PRViewerMapper extends Mapper<Object, Text, DoubleWritable, Text>
{
//处理经过迭代处理后输出的Data中间文件
//输入:<默认为行偏移量,text类型的数据,按行处理>
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
String[] temp = value.toString().split("\t");//按tab分片,temp[0]是网页,temp[1]是PR值,temp[2]是向的网页信息
// 输出:<PR值,网页>
//将PR提出来变为key,page作为value(图结构不需要用了,可以抛弃掉了)。
context.write(new DoubleWritable(Double.parseDouble(temp[1])), new Text(temp[0]));
}
}
public static class DescDoubleComparator extends DoubleWritable.Comparator
{
//给定的标准输出是按照降序排序,而Map默认是升序排序,因此需要自定义一个排序函数。基本就是继承原有的类将输出变成相反数即可
//重载key的比较函数,变为从大到小
public float compare(WritableComparator a, WritableComparable<DoubleWritable> b)
{
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)
{
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static class PRViewerReducer extends Reducer<DoubleWritable, Text, Text, Text>
{
//输入:<PR值,网页list(值为PR值的那些网页)>
@Override
protected void reduce(DoubleWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
for (Text i : values)
{
//遍历网页列表,输出:(网页名,保留小数点后10位的PR值)
context.write(new Text("(" + i + "," + String.format("%.10f", key.get()) + ")"), null);
}
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
Job job = Job.getInstance(conf, "RankViewer");
job.setJarByClass(RankViewer.class);
job.setOutputKeyClass(DoubleWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PRViewerMapper.class);
job.setSortComparatorClass(DescDoubleComparator.class);
job.setReducerClass(PRViewerReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
//以PageRankfunction作为主类,调用前三个函数的main函数
public static class PageRankFunction
{
//进行10次迭代
private static int times = 10;
public static void main(String[] args) throws Exception
{
//建立网页间的连接信息并初始化PR值,结果存入Data0
String[] functionPageRankBuilder = {"", args[1] + "/Data0"};
functionPageRankBuilder[0] = args[0];
GraphBuilder.main(functionPageRankBuilder);
String[] functionPageRankIter = {"", ""}; //迭代操作
for (int i = 0; i < times; i++)
{
functionPageRankIter[0] = args[1] + "/Data" + i;//Data i 是输入路径,Data i+1 是输出路径
functionPageRankIter[1] = args[1] + "/Data" + (i + 1);
PageRankIter.main(functionPageRankIter);
}
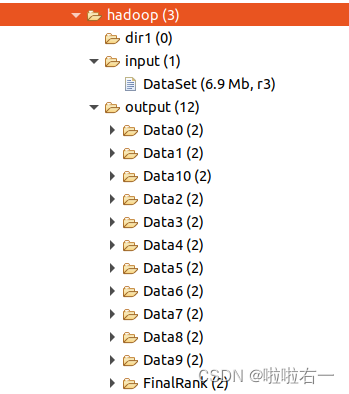
//最后一次输出的数据是输入信息,结果输出到FinalRank文件夹
String[] functionPageRankViewer = {args[1] + "/Data" + times, args[1] + "/FinalRank"};
RankViewer.main(functionPageRankViewer);
}
}
// 主函数入口
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs:localhost:9000");
PageRankFunction.main(args);
}
}
补充说明 :关于pagerank的Mapreduce本地运行
- 首先记得开
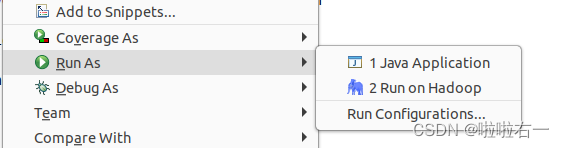
start-dfs.shRun As后选中Run on Hadoop
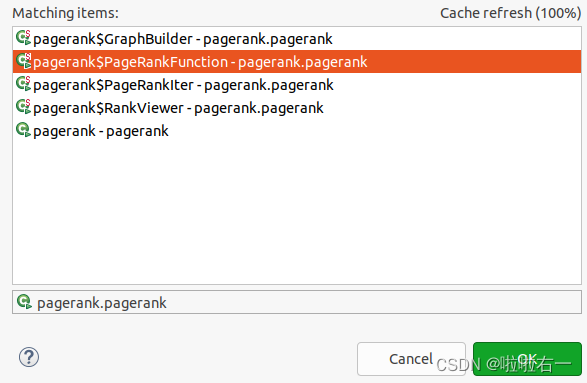
- 选中
PageRankfunction后再点OK,以它为主类,调用其他函数的main函数。
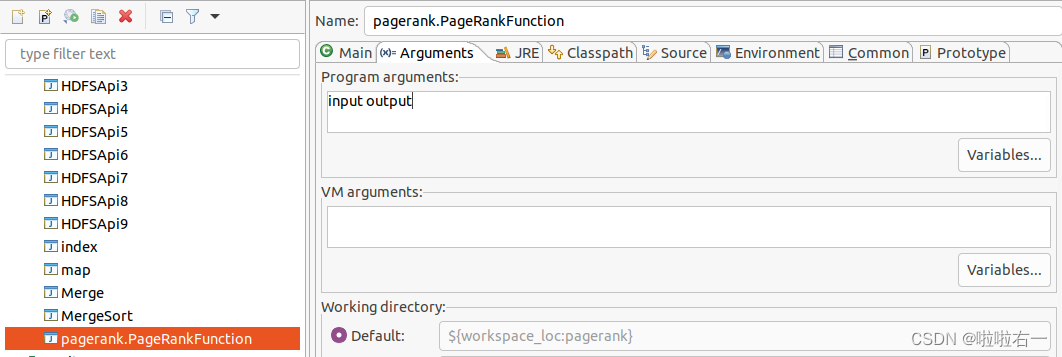
- 以上是选好主类,但是还跑不了👀,得再去设置Arguments
Run As里选中Run Configurations...
- 点开之后,将
pagerank.PageRankFunction的Arguments设置好input output,然后再点Run。
- 最后等着就行,等一会儿之后refresh就好。

🐇在集群上提交作业并执行
🥕Mapreduce方法
-
把代码里的"hdfs://localhost"改为"hdfs://10.102.0.198:9000",一共有4个地方需要改。
-
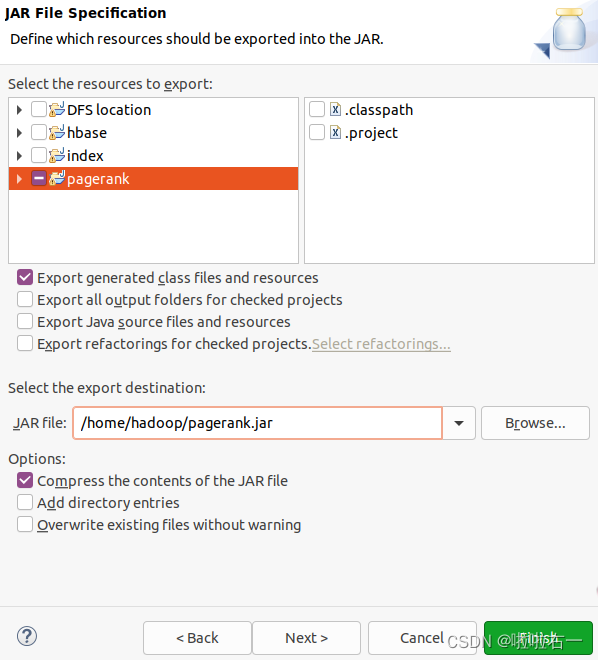
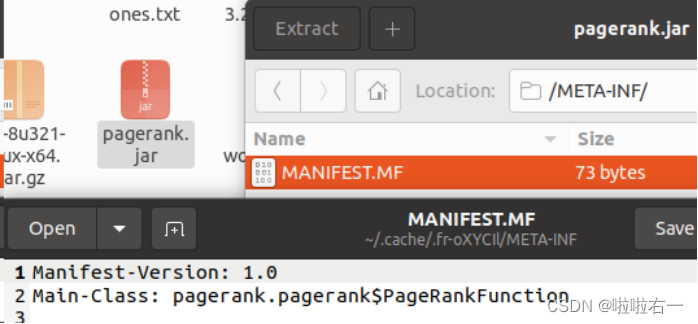
修改后通过export,导出jar包,关注Main-Class的设置,这里详见实验二(
不想再写一遍了
-
在终端依次输入
集群的服务器地址为 10.102.0.198,用户名和密码为“bigdata_学号”,用户主目录为/home/用户名,hdfs 目录为/user/用户名。集群上的数据集存放目录为 hdfs://10.102.0.198:9000/ex3/input。
scp pagerank.jar bigdata_学号@10.102.0.198:/home/bigdata_学号 ssh bigdata_学号@10.102.0.198 hadoop jar pagerank.jar /ex3/input /user/bigdata_学号/Experiment_3_Hadoop diff <(hdfs dfs -cat /ex3/output/part-r-00000) <(hdfs dfs -cat /user/bigdata_学号/Experiment_3_Hadoop/part-r-00000) -
在浏览器中打开 http://10.102.0.198:8088,可以查看集群上作业的基本执行情况。对应学号那显示SUCCEEDED就是提交成功。
🥕Spark方法
说在前面:关于Spark的sbt打包,虽然有博客参考,但实操起来还是报错重重😢,以下是不完全尝试过程截图😢。关于报错,总结起来主要是两点:
- 权限问题(如只读,无法访问),解决办法就是一切都在Home文件夹里完成
- 版本问题,涉及到build.sbt文件的设置问题
接下来只写亲测能行的😄
⭐️代码
(关注输出路径
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.hadoop.fs.{FileSystem, Path}
import java.io.File
object PageRank
{
//删除HDFS上指定的文件。
def hdfsDel(sc: SparkContext, filePath: String): Unit =
{
//第一步将文件路径转换为Path对象
val output = new Path(filePath)
//第二步获得与SparkContext的配置相关联的hadoopConfiguration
val conf = sc.hadoopConfiguration
//然后通过FileSystem.get (conf)获得hdfs文件系统
val hdfs = FileSystem.get(conf)
//最后,检查文件是否存在于文件系统中,如果存在则用hdfs对象对其进行删除
//hdfs.delete(output, true)中的true表明该目录不为空
if (hdfs.exists(output))
hdfs.delete(output, true)
}
def main(args: Array[String]): Unit =
{
//setMaster:设置主节点,使用与类似于hdfs的conf设置
val conf = new SparkConf().setAppName("PageRank_lalayouyi").setMaster("spark://10.102.0.198:7077")
//通过SparkContext得到Spark的上下文,可以连接到文件系统,主要还是得到RDD算子进行操作。
val scontext = new SparkContext(conf)
//-----------------------------进行迭代前的一些准备-------------------------
val d = 0.85//阻尼系数
val iterCount = 10//迭代次数
//从HDFS读取图结构,并把图结构存入内存
val lines = scontext.textFile("hdfs://10.102.0.198:9000/ex3/input", 1)
//map,得到<page {page1,page2,page3...}>,即<当前网页,指向的网页列表>
//将每行数据按tab分隔,取分隔后的第一个元素作为key,取分隔后的第二个元素,按逗号分隔成多个元素作为value,返回一个新的RDD,RDD(弹性分布式数据集)
//这一系列操作会被多次使用,最后加个cache表示将此RDD存放内存,增加代码的效率
val links = lines.map(line => (line.split("\t")(0), line.split("\t")(1).split(","))).cache()
//初始化PR值
var ranks = links.mapValues(_ => 1.0)
//------------------------------- 接下来进行迭代---------------------------
for (i <- 0 until iterCount) //进行10次迭代
{
//得到<page,({page1,page2,page3……},PR)>,指向的网页信息+ranks值字符串
val mapInput = links.join(ranks)
//计算输出的pr
val answer = mapInput.flatMap
{
//将每个网页的排名值(rank)平均分配给它所指向的所有链接页面(linkList)
//由一个page输出多个<page_i,pr'>,即标定好给谁多少pr
case (_, (linkList, rank)) => linkList.map(pageTo => (pageTo, rank / linkList.size))
}
//reduce,先求和得到总的pr,再加权,这里的reduceByKey就是将同一个key中的value值累加
val pagePR = answer.reduceByKey((x, y) => x + y)
//mapValues只对value做出操作,key保留;
ranks = pagePR.mapValues(v => (1 - d) + d * v)
}
//sortBy进行排序操作(mapValues只对value做出操作,key保留),输出格式是保留10位小数
val result = ranks.sortBy(x => x._2, false).mapValues(x => x.formatted("%.10f"))
//输出:(page,PR)
//结果输出路径
val SavePath = "hdfs://10.102.0.198:9000/user/bigdata_学号/Experiment_3_Spark"
//如果目标目录已经存在,那么再写到该目录会出错,因此需要先将存在的目录删除
hdfsDel(scontext, SavePath)
//保存到文件系统
result.saveAsTextFile(SavePath)
}
}
⭐️打包过程
sbt包下载链接

-
新建
/usr/local/sbtsudo mkdir /usr/local/sbt sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名 -
把
sbt-launch.jar移动到/usr/local/sbt中
用Move to直接选中目标地址移动(也可以终端) -
在
/usr/local/sbt中创建 sbt 脚本cd /usr/local/sbt vim ./sbt添加如下内容
#!/bin/bash SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@" -
保存后,为./sbt脚本增加可执行权限
chmod u+x ./sbt -
最后运行如下命令,检验 sbt 是否可用(请确保电脑处于联网状态,首次运行会处于 “Getting org.scala-sbt sbt 0.13.11 …” 的下载状态,请耐心等待。最后有个这就行👇
(真的要等挺久

-
在Home文件夹里建文件夹!不然既写不了scala文件又改不了build.sbt还打不了包!😢
这里的框架是:
- 先在home里建pagerank文件夹
- 然后在pagerank文件夹里建src文件夹
- 然后在src文件夹里建main文件夹
- 然后在main文件夹里建scala文件夹
- 最后在scala文件夹里开终端输
touch pagerank.scala,然后把上边的代码放在pagerank.scala里。
-
在pagerank里(也就是它生成之后是和src放一块的)vim一个build.sbt(
vim build.sbt),填上如下信息:name := "Simple Project" //这要是改了,之后打包文件名也要改 version := "1.0" scalaVersion := "2.13.10" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.2" libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.2.2" -
然后可以得到如下结构
-
开始打包(在pagerank里开终端,也就是前边是~/pagerank$)
/usr/local/sbt/sbt package打包成功最后会显示下图

-
文件上传集群,关注这里的终端位置
cd ~/pagerank/target/scala-2.13 scp simple-project_2.13-1.0.jar bigdata_学号@10.102.0.198:/home/bigdata_学号 -
登录ssh
ssh bigdata_学号@10.102.0.198 -
spark运行
spark-submit --class PageRank ~/simple-project_2.13-1.0.jar最后运行后大致是这么几行

-
检查结果正确与否
diff <(hdfs dfs -cat /ex3/output/part-r-00000) <hdfs dfs -cat /user/bigdata_学号/Experiment_3_Spark/part-00000)最后在10.102.0.198:8080查看,如果提交成功最后学号对应行的对应时间大致是20s左右。