点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍
张鑫杰

香港科技大学电子与计算机工程系在读博士生,研究方向为图像视频压缩,
个人主页为https://xinjie-q.github.io/
内容简介
多视角图像压缩在3D相关应用程序中起着至关重要的作用。现有方法采用预测编码架构,需要联合编码来压缩相应的视差和残差信息。这要求相机之间的协作并在不同视图之间强制执行对极几何校正,使得在具有随机重叠视野的分布式相机系统中部署这些方法具有挑战性。幸运的是,分布式信源编码理论表明,通过独立编码和联合解码可以实现相关源的高效数据压缩,这促使我们设计基于学习的分布式多视角图像编码(LDMIC)框架。借助独立的编码器,LDMIC在解码器中引入了一个简单而有效的联合上下文传输模块,该模块基于交叉注意力机制来有效捕获不同视图间的全局相关性。实验结果表明,LDMIC在享受快速编码速度的同时,显著优于传统和基于学习的MIC方法。
论文链接:https://arxiv.org/abs/2301.09799
代码链接:https://github.com/Xinjie-Q/LDMIC
01
Definition
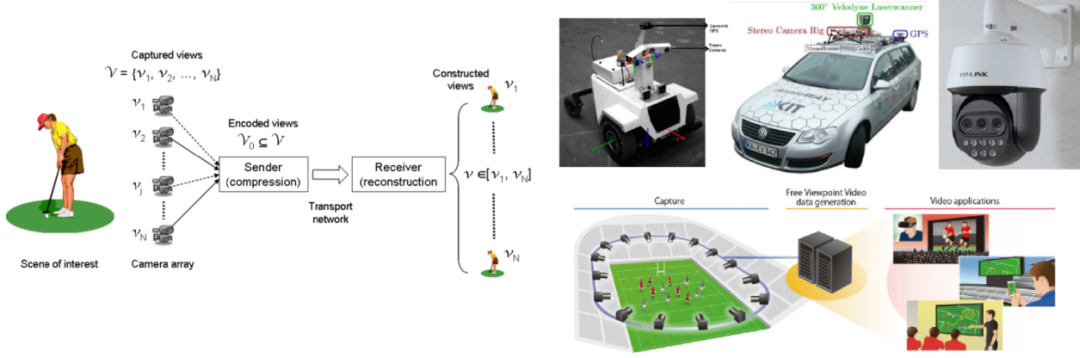
多视角图像编码指给定一组从不同视角来捕获当前感兴趣区域的相关图片,通过利用视角间的相关性来进行压缩和解压缩。多视角图像编码的方案在现实生活当中有着许多重要的应用,比如机器人导航、自动驾驶和视频监控。在这些应用中,我们经常会部署双目摄像头或者三目摄像头来去产生多视角图像。除此之外,在3D视频的生成当中,比如自由试点视频的生成当中,我们需要对同一个场景来部署多个摄像头捕获当前场景中的不同视角。由于通信带宽的限制,我们需要应用多视角编码的框架来尽可能减少传输所需要的比特数。
02
Benchmarks
Single Image Coding
下面介绍一些可以用于多视角图像编码的方法。最简单的方法是单帧图像编码,当这种方法应用在多视角中,可以独立地去压缩每一个视角的图片。传统的方法有JPEG、BPG以及目前最先进的VVC-intra。除此之外,近年来也有许多工作将深度学习的技术引入到图像压缩当中,并且取得了比传统图像编码更优越的压缩性能。如图1所示,基于学习的单帧图像压缩主要是依赖于非线性变换和Entropy模型[1]。非线性变换主要指的是一对编码器和解码器。编码器会将输入图片x从像素空间转换到特征空间上面,接着利用熵模型来预测当前特征空间的概率分布,通常我们会将的概率分布构建为一个高斯分布。在得到概率分布之后,我们会应用熵编码将无损压缩为比特流并传输到解码端进行重建。但是如果我们直接将单帧图像编码应用到多视角图像编码中,由于单帧图像编码只关注每一张图片,而没有关注不同视角之间的相关性,这会造成次优的压缩性能。
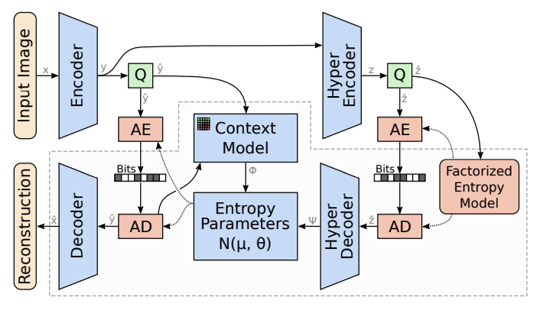
图1 单帧图像编码框架
Joint Multi-view Image Coding
图2显示了当前标准多视图图像编解码器 MV-HEVC 的编码过程 [2]。它采用了预测编码技术,可以概括为图3中的联合编码-解码范式。首先,与单帧图像编码相比,联合编码导致更高的编码复杂度。其次,联合编码需要预先收集所有不同视角的图像,这需要相机之间相互通信或将数据传输到中间的公共接收器,从而导致高通信开销。最后,大多数先前的方案利用基于对极几何校正的视差估计,这需要事先知道相机的内部和外部参数,以便在视差估计之前对图像进行校正。然而,在一些应用当中很难获取到相机的先验知识。
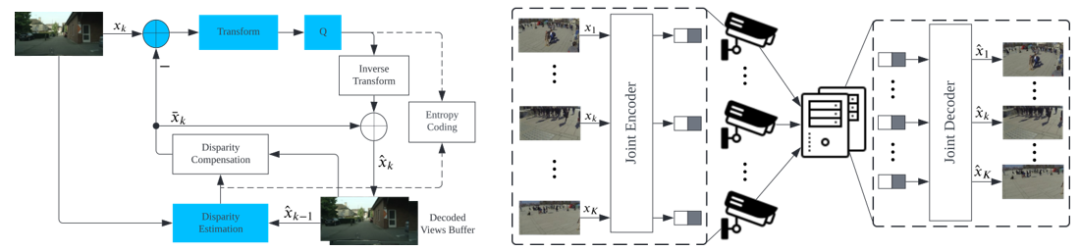
图2 MV-HEVC编码过程 图3 联合编码-解码框架
03
Distributed Source Coding
为解决上述问题,我们回顾了基于Slepian-Wolf Theorem的对称分布式信源编码 [3]。它表明了两个或多个相关源的单独编码和联合解码在理论上可以达到与联合编码-解码方案相同的压缩率。
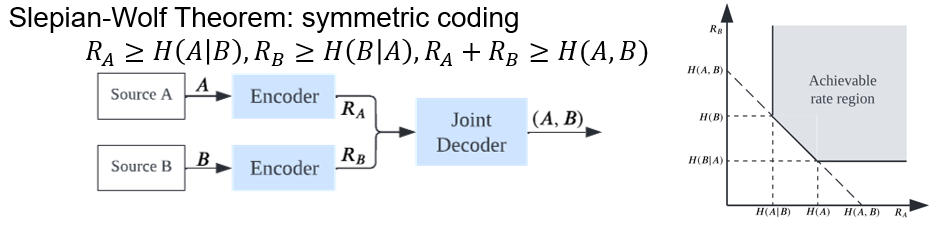
图4 Slepian-Wolf Theorem
04
Proposed Method: LDMIC
基于信息论结果,我们首先引入分布式信源编码来解耦视图间操作。如图5所示,我们只使用一个简单的图像编码器来压缩每个视图图像,这使我们能够享受低编码复杂度并避免相机协作。然后,我们在解码器处设计了一个与几何无关的联合上下文传输(Joint Context Transfer, JCT)模块,以利用视图间相关性进行高质量重建。值得注意的是,我们的 JCT 模块基于交叉注意机制,不依赖视差估计,这可以避免相机参数泄漏。最后,我们联合训练编码器和解码器以隐式地使潜在表示更紧凑,从而进一步提高压缩性能。
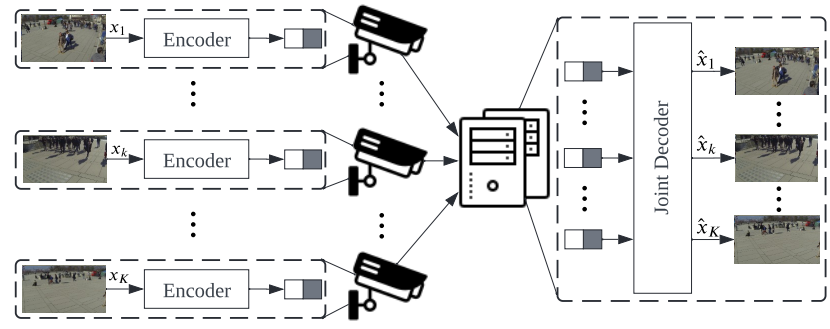
图5 提出的对称分布式编码框架
图6展示了具体的网络结构。其中编码器以及熵模型采用的是单帧图像编码,在解码端则插入了我们提出的联合上下文编码模块去充分地利用不同视角之间的相关性。
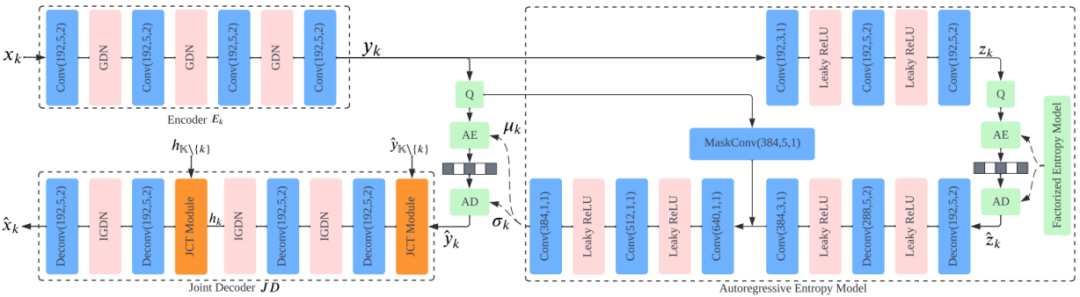
图6 带有具有自回归熵模型的 LDMIC 框架
Joint Context Transfer Module
图7展示了我们提出的联合上下文转移模块,其中的核心模块是交叉注意力机制。在其中我们利用交叉注意力机制去充分利用不同视角之间的群集相关信息,这样的操作允许我们在不知道相机参数的前提下充分利用不同视角之间的相关性,这能够使其适用于任何的多相机系统。
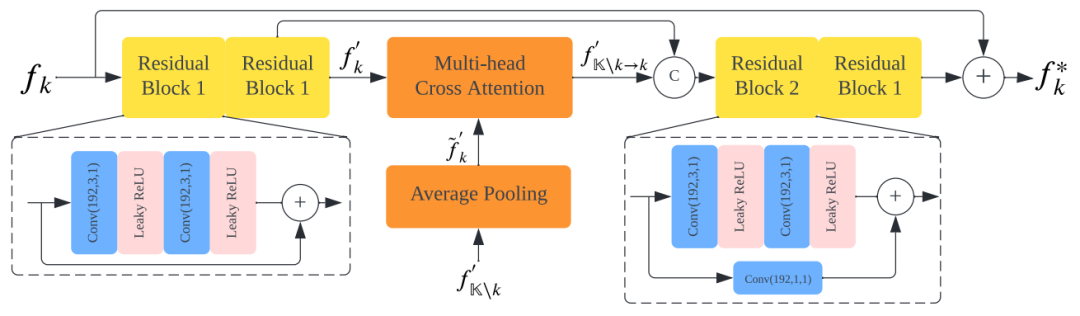
图7 所提出的联合上下文传输模块中第 k 条路径的示例
05
Experiments
Compression Performance
如图8所示,我们提出的方法可以实现与当前先进的联合编码解码方案相当的编码性能。
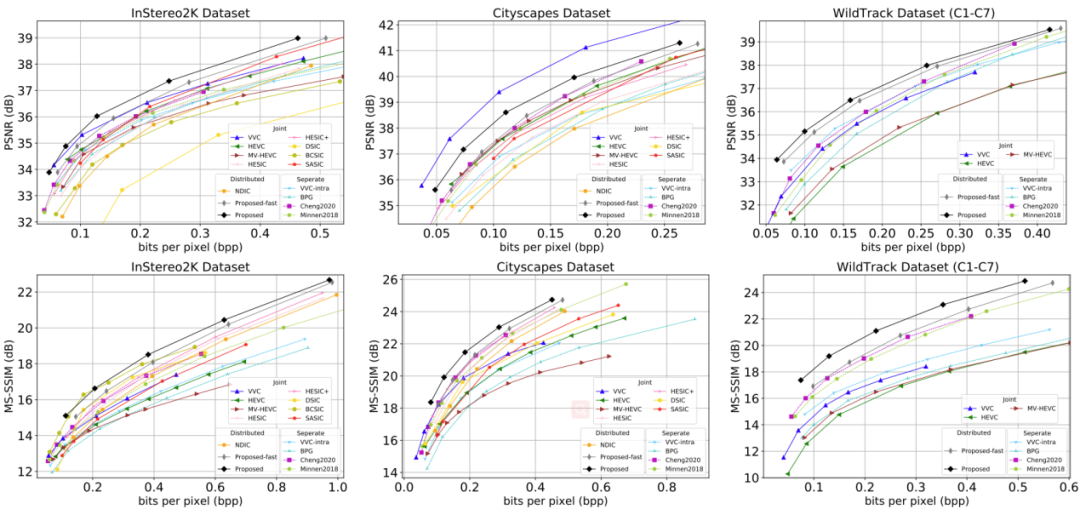
图8 不同数据集下的压缩性能
Complexity Performance
此外,我们的方法继承了传统分布式压缩在图像级并行化方面的优势。在与联合编码-解码方法相比,我们的方法有更低的计算开销。
表1 基于学习的图像编解码器的计算复杂度比较
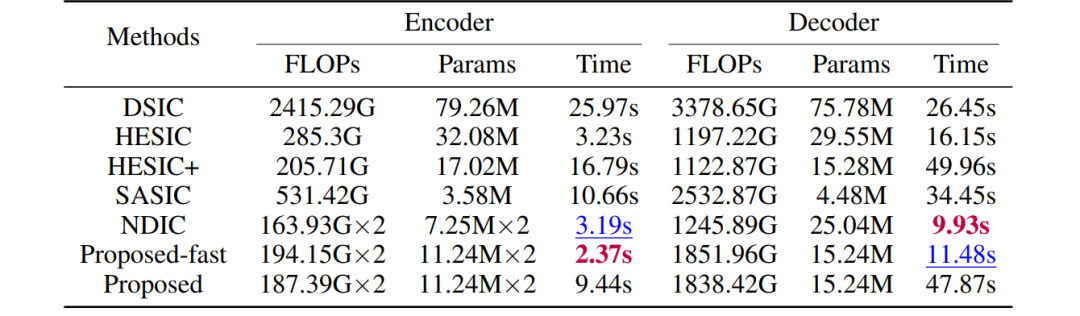
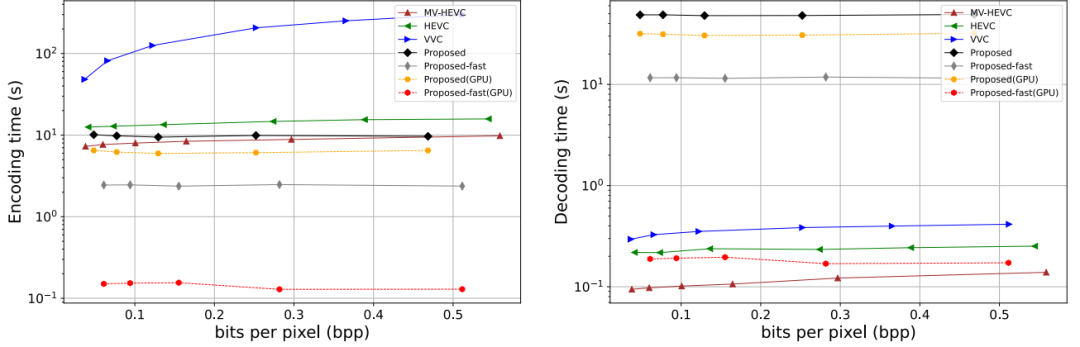
图9 提出的方法和传统编解码器的计算复杂度比较
Ablation Studies
JCT模块的有效性:我们进行了一系列的消融研究,包括插入/除去JCT模块来实现Joint/Separate Encoding-Decoding和将JCT模块替换成其他视间操作。实验结果表明,我们提出的 JCT 模块可以更高地捕获视角相关性和重建更高质量地图片。
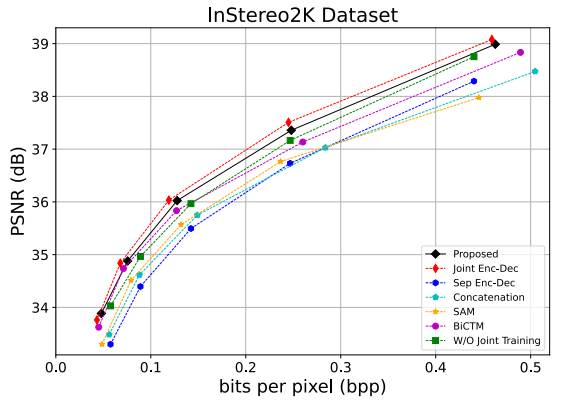
图10 消融研究
联合训练策略的有效性:我们利用联合训练的好处来隐含地帮助编码器学习去除部分视图间冗余。因此,潜在特征表示会更紧凑。为了研究其效果,我们固定住预训练编码器和熵模型,仅训练联合解码器。如图所示,具有联合训练策略的潜在特征图包含更多的低幅值的元素,这表明可以用更少的比特来进行编码。
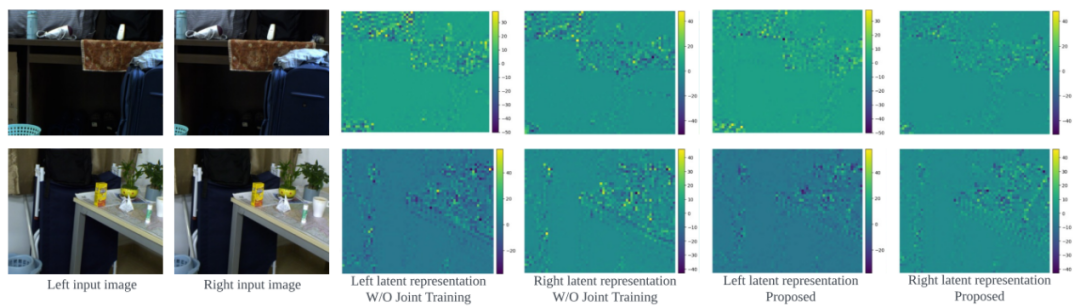
图11 来自InStereo2K 数据集的可视化示例
06
Conclusion
首先,我们提出了第一个用于多视图图像编码的基于学习的视图对称框架。它解耦了编码器的视图间操作,这对于分布式相机系统来说是非常需要的。其次,我们还在解码器处提供了一个联合上下文传输模块,以显式捕获视图间相关性以生成更高质量地图片。另外,我们引入端到端的编码器-解码器训练策略来隐式地使潜在表示更紧凑。最后,我们希望所提出的方法可以作为未来在相关任务中的贡献的可能解决方案,例如单视图和多视图视频压缩。
07
Summary
[1] David Minnen, Johannes Balle, and George D Toderici. Joint autoregressive and hierarchical priors for learned image compression. Advances in neural information processing systems, 31, 2018.
[2] Gerhard Tech, Ying Chen, Karsten Muller, Jens-Rainer Ohm, Anthony Vetro, and Ye-Kui Wang. Overview of the multiview and 3d extensions of high efficiency video coding. IEEE Transactions on Circuits and Systems for Video Technology, 26(1):35–49, 2015.
[3] David Slepian and Jack Wolf. Noiseless coding of correlated information sources. IEEE Transactions on information Theory, 19(4):471–480, 1973.
整理:陈研
审核:张鑫杰
提
醒
点击“阅读原文”跳转到59:07可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!


![[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling](https://img-blog.csdnimg.cn/d8775c50461f401e962e16833c5b9d0a.png)