JUC是java.util.concurrent包的简称。
1. AQS高频问题
1.1 AQS是什么?
先看类位置

AQS是JUC下大量工具的基础类,很多工具都基于AQS实现的,比如lock锁, CountDownLatch,Semaphore,线程池等等都用到了AQS。
AQS中有一个核心属性state,还有一个双向链表以及一个单向链表。其中state是基于volatile修饰,再基于CAS修改,可以保证原子,可见,有序三大特性。单向链表是内部类ConditionObject对标synchronized中的等待池,当lock在线程持有锁时,执行await方法,会将线程封装为Node对象,扔到Condition单向链表中,等待唤醒。如果线程唤醒了,就将Condition中的Node扔到AQS的双向链表等待获取锁。
1.2 唤醒线程时,AQS为什么从后往前遍历?
当持有资源的线程执行完成后,需要在AQS的双向链表拿出来一个,如果head的next节点取消了
如果在唤醒线程时,head节点的next是第一个要被唤醒的,如果head的next节点取消了,会出现节点丢失问题。
如下图,当一个新的Node添加到链表时有3个步骤,当第三个步骤还未完成时,如果从head开始就找不到需要被唤醒的节点了。
跑路重头开始去掉node,唤醒node就重后面取,防止取到丢失节点。

1.3 AQS的唤醒线程为什么用双向链表,(为啥不用单向链表)?
因为AQS中,存在取消节点的操作,如果使用双向链表只需要两步
-
需要将prev节点的next指针,指向next节点。
-
需要将next节点的prev指针,指向prev节点。
但是如果是单向链表,需要遍历整个单向链表才能完成的上述的操作。比较浪费资源。
1.4 AQS为什么要有一个虚拟的head节点
源码中定义是这样的:
/** * 等待队列的头,已延迟初始化。除了初始化时,它只能通过方法setHead进行修改。注: 如果头存在,则保证其waitStatus不为取消。 */ private transient volatile Node head;volatile int waitStatus;
每个Node都会有一些状态,这个状态不单单针对自己,还针对后续节点
-
1:当前节点取消了。
-
0:默认状态,啥事没有。
-
-1:当前节点的后继节点,挂起了。
-
-2:代表当前节点在Condition队列中(await将线程挂起了)
-
-3:代表当前是共享锁,唤醒时,后续节点依然需要被唤醒。
但是一个节点无法同时保存当前节点状态和后继节点状态,有一个哨兵节点,更方便操作。
事情要从 Node 类的 waitStatus 变量说起,简称 ws。每个节点都有一个 ws 变量,用于这个节点状态的一些标志。初始状态是 0。如果被取消了,节点就是 1,那么他就会被 AQS 清理。
还有一个重要的状态:SIGNAL —— -1,表示:当当前节点释放锁的时候,需要唤醒下一个节点。
所有,每个节点在休眠前,都需要将前置节点的 ws 设置成 SIGNAL。否则自己永远无法被唤醒。
而为什么需要这么一个 ws 呢?—— 防止重复操作。假设,当一个节点已经被释放了,而此时另一个线程不知道,再次释放。这时候就错误了。
所以,需要一个变量来保证这个节点的状态。而且修改这个节点,必须通过 CAS 操作保证线程安全。
So,回到我们之前的问题:为什么要创建一个虚拟节点呢?
每个节点都必须设置前置节点的 ws 状态为 SIGNAL,所以必须要一个前置节点,而这个前置节点,实际上就是当前持有锁的节点。
问题在于有个边界问题:第一个节点怎么办?他是没有前置节点的。
那就创建一个假的。 这就是为什么要创建一个虚拟节点的原因。
总结下来就是:每个节点都需要设置前置节点的 ws 状态(这个状态为是为了保证数据一致性),而第一个节点是没有前置节点的,所以需要创建一个虚拟节点。
1.5 ReentrantLock的底层实现原理
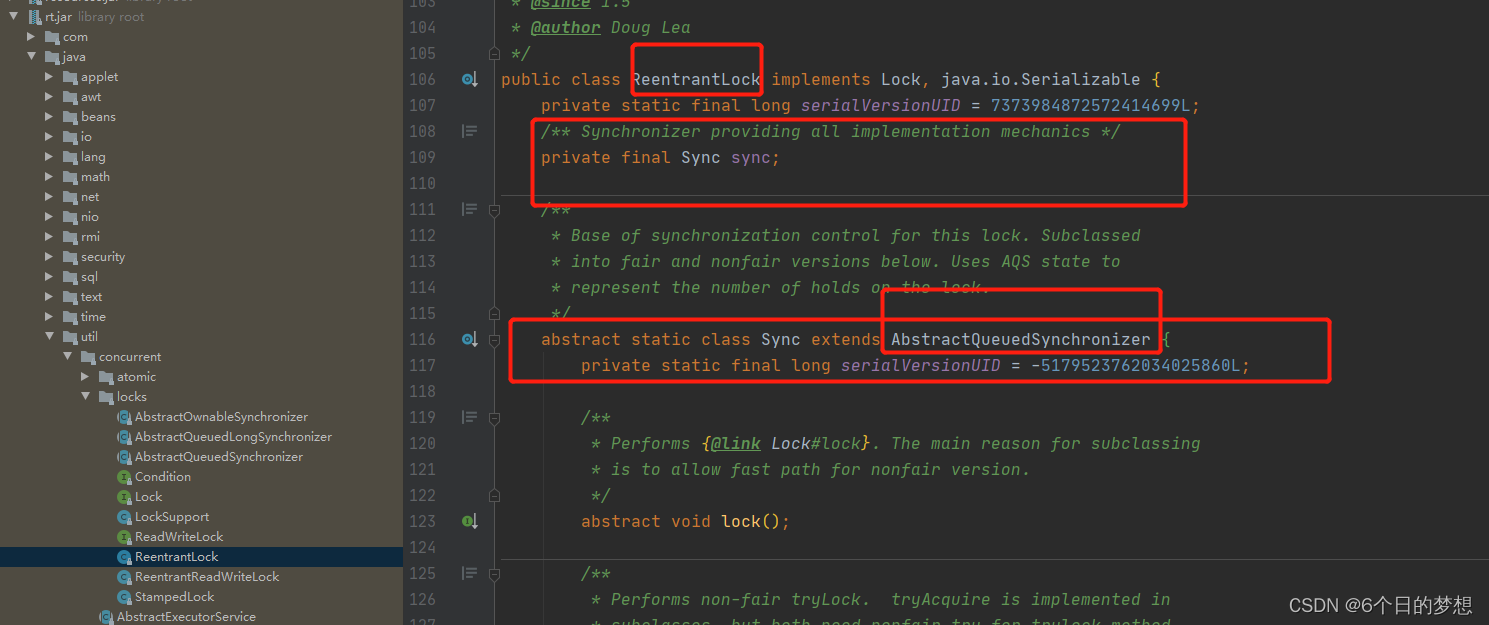
ReentrantLock是基于AQS实现的。
-
在线程基于
ReentrantLock加锁时,需要基于CAS去修改state属性,如果能从0改为1,代表获取锁资源成功 -
如果CAS失败了,添加到AQS的双向链表中排队(可能会挂起线程),等待获取锁。
-
持有锁的线程,如果执行了condition的await方法,线程会封装为Node添加到Condition的单向链表中,等待被唤醒并且重新竞争锁资源
1.6 ReentrantLock的公平锁和非公平锁的区别
公平锁和非公平中的lock方法和tryAcquire方法的实现有点不同,其他都一样
非公平锁
-
lock:直接尝试将state从 0 改为 1,如果成功,拿锁直接走,如果失败了,执行tryAcquire。 -
tryAcquire:如果当前没有线程持有锁资源,直接再次尝试将state从0 改为 1 如果成功,拿锁直接走。
公平锁
-
lock:直接执行tryAcquire。 -
tryAcquire:如果当前没有线程持有锁资源,先看一下,有排队的么。如果没有排队的,直接尝试将state从 0 改为 1。如果有排队的并且第一名,直接尝试将state从 0 改为 1。
如果都没拿到锁,公平锁和非公平锁的后续逻辑是一样的,加入到AQS双向链表中排队。
1.7 ReentrantReadWriteLock如何实现的读写锁
如果一个操作写少读多,还用互斥锁的话,性能太低,因为读读不存在并发问题。读写锁可以解决该问题。
ReentrantReadWriteLock也是基于AQS实现的一个读写锁,但是锁资源用state标识。如何基于一个int来标识两个锁信息,有写锁,有读锁,怎么做的?
一个int,占了32个bit位。在写锁获取锁时,基于CAS修改state的低16位的值。在读锁获取锁时,基于CAS修改state的高16位的值。
写锁的重入,基于state低16直接标识,因为写锁是互斥的。读锁的重入,无法基于state的高16位去标识,因为读锁是共享的,可以多个线程同时持有。所以读锁的重入用的是ThreadLocal来表示,同时也会对state的高16为进行追加。
2、阻塞队列高频问题
2.1 说下你熟悉的阻塞队列?
-
ArrayBlockingQueue:底层基于数组实现,记得new的时候设置好边界,防止OOM。 -
LinkedBlockingQueue:底层基于链表实现的,可以认为是无界队列,但是可以设置长度。 -
PriorityBlockingQueue:底层是基于数组实现的二叉堆,可以认为是无界队列,因为数组会扩容。
ArrayBlockingQueue,LinkedBlockingQueue是ThreadPoolExecutor线程池最常用的两个阻塞队列。
2.2 虚假唤醒是什么?
虚假唤醒在阻塞队列的源码中就有体现。

/** Number of elements in the queue */ int count;
比如消费者1在消费数据时,会先判断队列是否有元素,如果元素个数为0,消费者1会await挂起。此处判断元素为0的位置,如果用if循环会导致出现一个问题。
-
如果生产者添加了一个数据,会唤醒消费者1并去拿锁资源。
-
此时如果来了消费者2抢到了锁资源并带走了数据的话,消费者1再次拿到锁资源时,无法从队列获取到任何元素,出现虚假唤醒问题。
解决方案,将判断元素个数的位置,设置为while判断。
通过判断队列中的count数量,防止取不到元素。
3、线程池高频问题
3.1 线程池的7个参数
核心线程数,最大线程数,最大空闲时间,时间单位,阻塞队列,线程工厂,拒绝策略
3.2 线程池的状态有什么,如何记录的?
线程池有5个状态:RUNINING、SHUTDOWN、STOP、TIDYING、TERMINATED
运行、关闭、停止、整理、终止
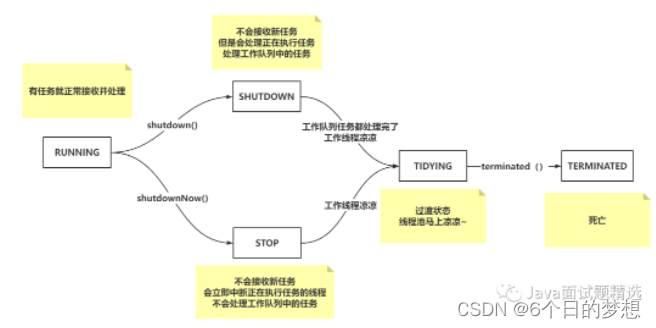
线程池的状态是在ctl属性中记录的。本质就是int类型

3.3 线程池常见的拒绝策略
AbortPolicy:丢弃任务并抛异常(默认)
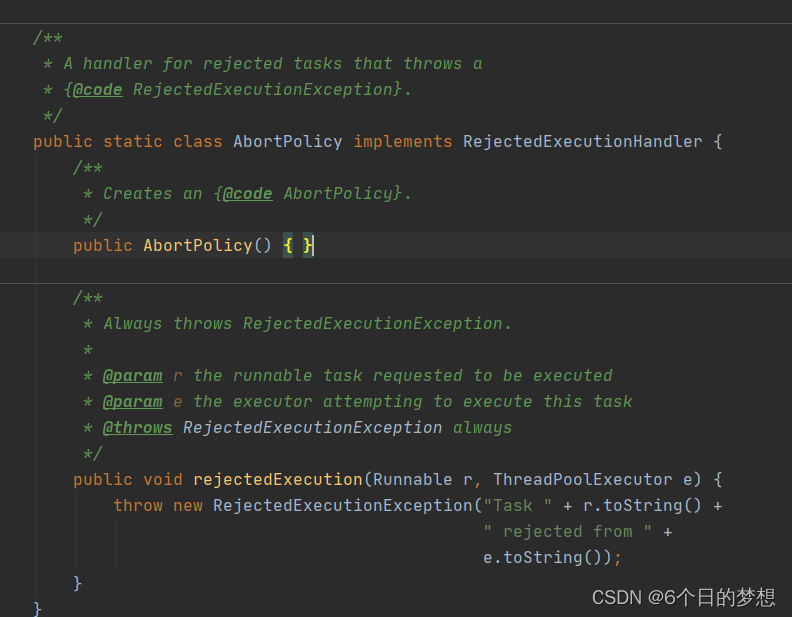
CallerRunsPolicy:当前线程执行
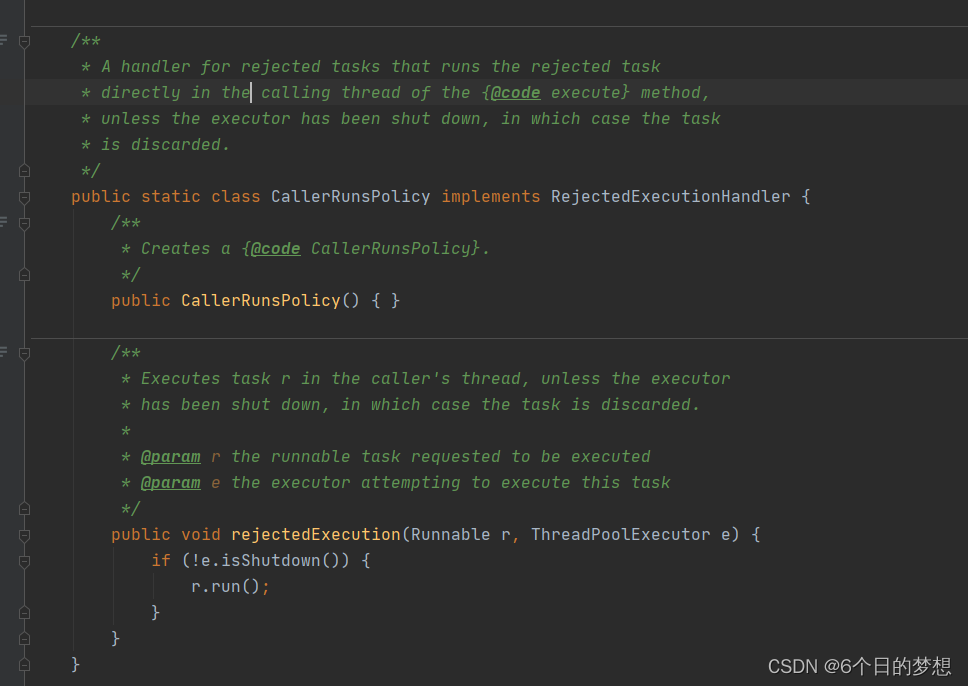
DiscardPolicy:丢弃任务直接不要
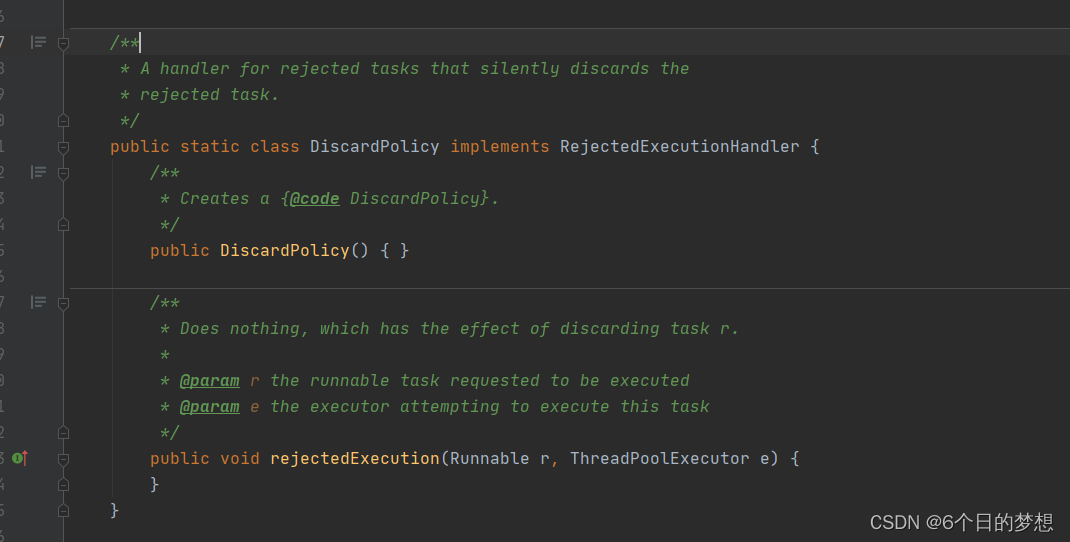
DiscardOldestPolicy:丢弃等待队列中最旧的任务,并执行当前任务
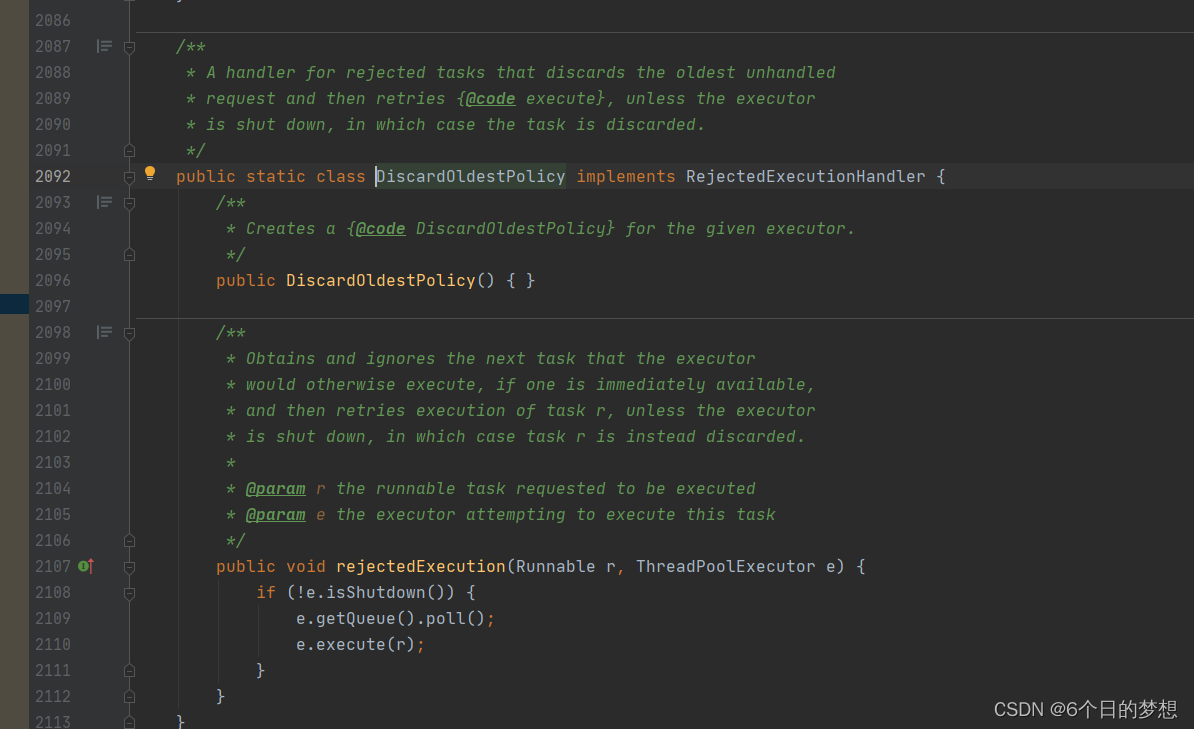
一般情况下,线程池自带的无法满足业务时,自定义一个线程池的拒绝策略,实现下面的接口即可。
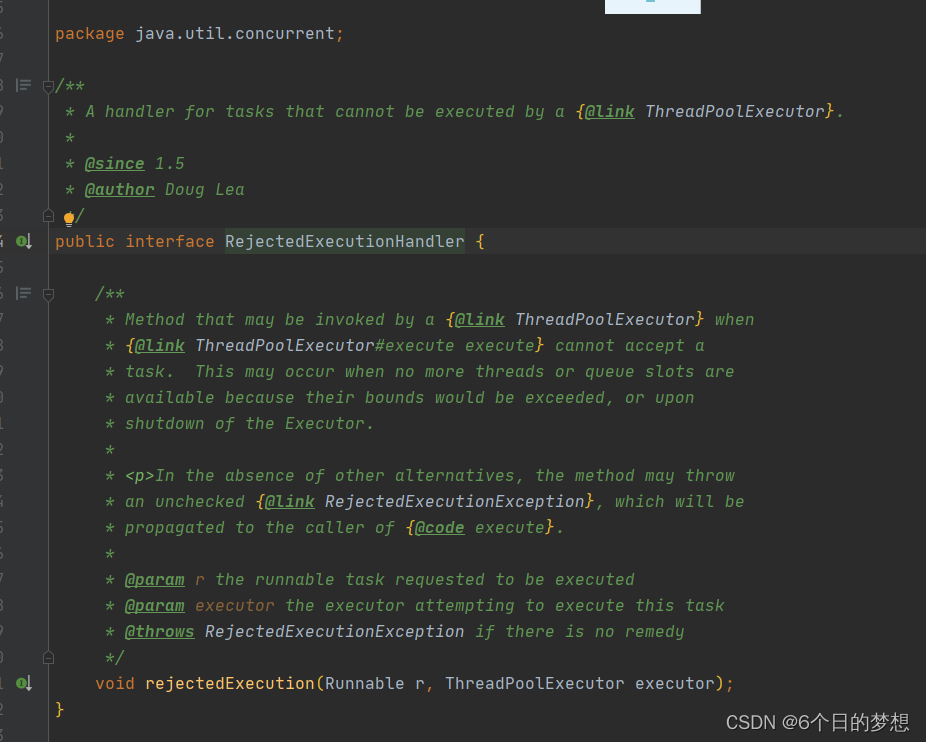
上面4个都有实现
3.4 线程池执行流程
核心线程不是new完就构建的,是懒加载的机制,添加任务才会构建核心线程
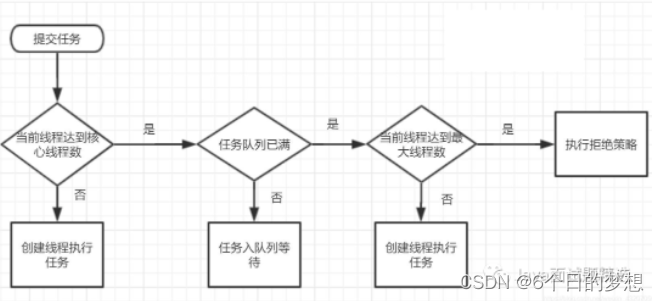
3.5 线程池为什么添加空任务的非核心线程

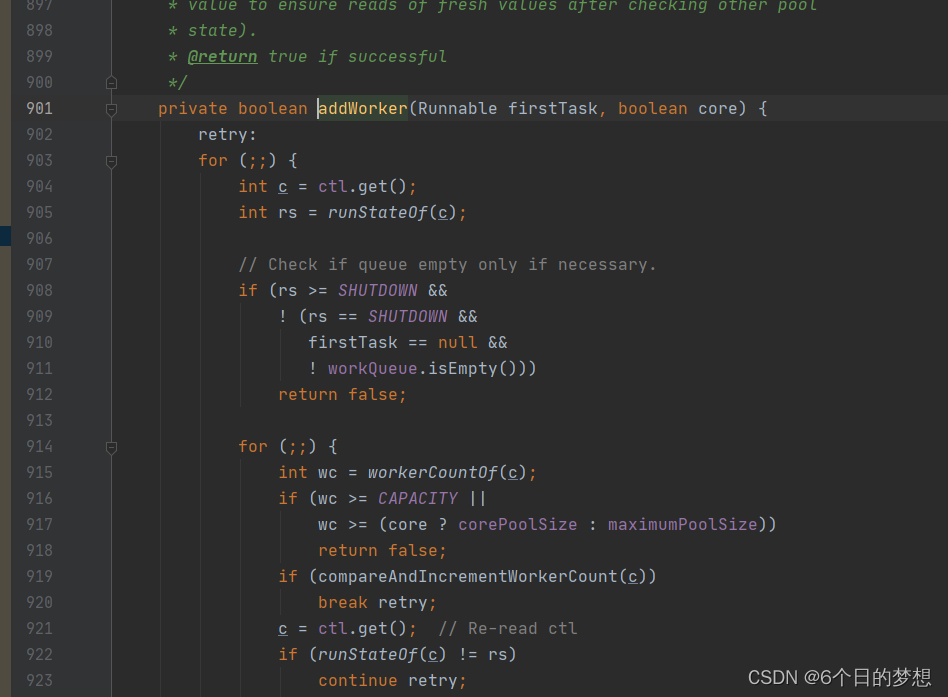
避免线程池出现队列有任务,但是没有工作线程处理。
当核心线程数是0个,任务进来后会到阻塞队列,但是没有工作线程,此时空任务的非核心线程就可以处理该任务。
3.6 在没任务时,线程池中的工作线程在干嘛?
-
如果是核心线程,默认情况下,会在阻塞队列的位置执行take方法,直到拿到任务为止。
-
如果是非核心线程,默认情况下,会在阻塞队列的位置执行poll方法,等待最大空闲时间,如果没任务,删除线程,如果有活,那就正常干。
3.7 工作线程出现异常会导致什么问题?
首先出现异常的工作线程不会影响到其他的工作线程。
-
如果任务是execute方法执行的,工作线程会将异常抛出。
-
如果任务是submit方法执行的
futureTask,工作线程会将异常捕获并保存到FutureTask里,可以基于futureTask的get得到异常信息。 -
最后线程结束。
3.8 工作线程继承AQS的目的是什么?
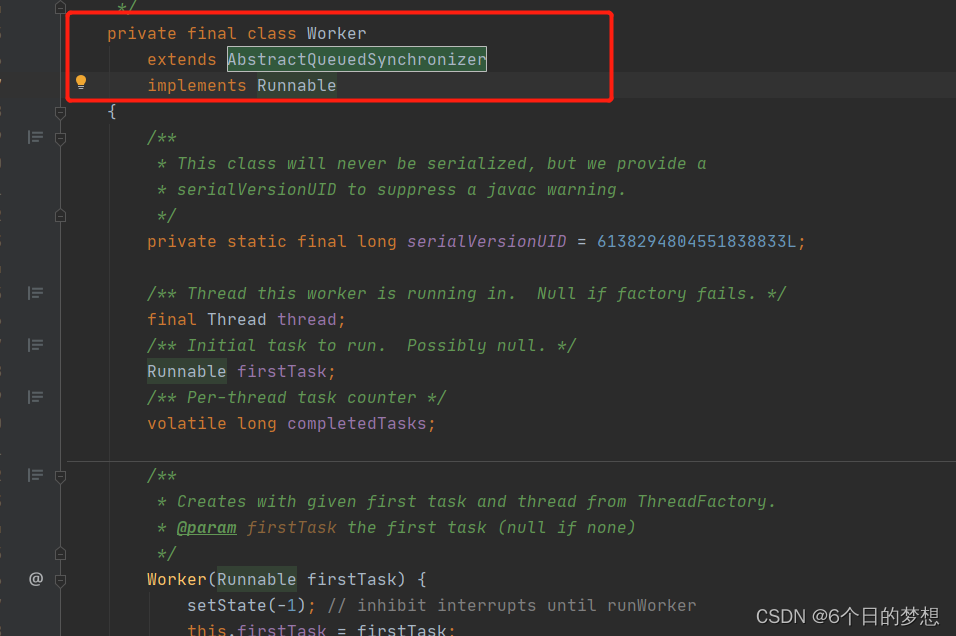
工作线程的本质,就是Worker对象。继承AQS跟shutdown和shutdownNow有关系。
-
如果是
shutdown,会中断空闲的工作线程,基于Worker实现的AQS中的state的值来判断能否中断工作线程。如果工作线程的state是0,代表空闲,可以中断,如果是1,代表正在干活。 -
如果是
shutdownNow,直接强制中断所有工作线程
3.9 核心参数怎么设置?
线程池的目的是为了减少线程频繁创建/销毁带来的资源消耗,充分发挥CPU的资源,提升整个系统的性能。不同业务的线程池参考的方式也不一样。
-
如果是CPU密集的任务,一般也就是CPU内核数 + 1的核心线程数。这样足以充分发挥CPU性能。
-
如果是IO密集的任务,因为IO的程度不一样,有的是1s,有的是1ms,有的是1分钟,所以IO密集的任务在用线程池处理时,一定要通过压测的方式,观察CPU资源的占用情况,来决定核心线程数。一般发挥CPU性能到70~80足矣。 正常2n
所以线程池的参数设置需要通过压测以及多次调整才能得出具体的。
4、CountDownLatch,Semaphore,CyclicBarrier的高频问题
4.1 CountDownLatch是啥?有啥用?底层咋实现的?
CountDownLatch本质其实就是一个计数器。在多线程并行处理业务时,需要等待其他线程处理完再做后续的合并等操作时,可以使用CountDownLatch做计数,等到其他线程出现完之后,主线程就会被唤醒。实现过程如下:
-
CountDownLatch本身就是基于AQS实现的。new CountDownLatch时,直接指定好具体的数值,这个数值会复制给state属性。 -
当子线程处理完任务后,执行countDown方法,内部就是直接给state - 1。
-
当state减为0之后,执行await挂起的线程,就会被唤醒。
public class CountDownLatchTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch count = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
int finalI = i;
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程" + finalI + "执行中");
count.countDown();
}).start();
}
count.await();
System.out.println("所有线程都执行完成了");
}
}4.2 Semaphore是啥?有啥用?底层咋实现的?
信号量,就是一个可以用于做限流功能的工具类。比如要求当前服务最多3个线程同时干活,将信号量设置为3。每个任务提交前都需要获取一个信号量,获取到就去干活,干完了,归还信号量。实现过程如下:
-
信号量也是基于AQS实现的,构建信号量时,指定信号量资源数,这个数值会复制给state属性。
-
获取信号量时,执行acquire方法,内部就是直接给
state - 1。当state为0时,新来的任务会因获取不到信号量而等待。 -
当任务执行完成后,执行release方法,释放信号量。
public class SemaphoreTest {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for (int i = 0; i < 3; i++) {
int finalI = i;
new Thread(() -> {
try {
semaphore.acquire();
System.out.println("线程" + finalI + "执行中");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}).start();
}
new Thread(() -> {
try {
long begin = System.currentTimeMillis();
semaphore.acquire();
long end = System.currentTimeMillis();
System.out.println("限流了" + (end - begin) + "ms");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}).start();
}
}4.3 main线程结束,程序会停止嘛?
-
如果main线程结束,但是还有用户线程在执行,不会结束!
-
如果main线程结束,剩下的都是守护线程,结束!
4.4 CyclicBarrier原理
CyclicBarrier源码相对CountDownLatch真是简单了不少,就是简单了利用了一下ReentrantLock+Condition组合。
下面简单总结一下 : 通过构造方法new CyclicBarrier(N)给count属性赋值为N。
每个线程来了之后先获取栅栏的锁,对count进行-1操作,代表当前线程已经到达了栅栏。
调用Condition的await方法将当前线程挂起,await会释放独占锁。每个线程都会对count减1。
当count减为0的时候。说明最后一个线程到达了栅栏。由最后这个线程执行Condition.signalAll方法唤醒所有挂起的线程。
线程重新获取到锁后。发现所有线程都已经到达了栅栏,才能继续执行,CyclicBarrier.await方法返回。
public class CyclicBarrierExample1 {
private static CyclicBarrier barrier = new CyclicBarrier(5);//5个线程要同步等待
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for(int i = 0; i < 10; i++) {
final int threadNum = i;
Thread.sleep(1000);
exec.execute(() -> {
try {
race(threadNum);
}catch (Exception e) {
log.error("exception",e);
}
});
}
}
public static void race(int threadNum) throws Exception{
Thread.sleep(100);
log.info("{} is ready",threadNum);
barrier.await();
log.info("{} is continue",threadNum);
}
}5、CopyOnWriteArrayList的高频问题
5.1 CopyOnWriteArrayList是如何保证线程安全的?有什么缺点吗?
CopyOnWriteArrayList写数据时,是基于ReentrantLock保证原子性的。写数据时,会复制一个副本写入,写入成功后,才会写入到CopyOnWriteArrayList中的数组,保证读数据时,不要出现数据不一致的问题。
缺点就是:如果数据量比较大时,每次写入数据,都需要复制一个副本,对空间的占用太大了。如果数据量比较大,不推荐使用CopyOnWriteArrayList。
适合写操作要求保证原子性,读操作保证并发,并且数据量不大的场景。
6、ConcurrentHashMap(JDK1.8)的高频问题
6.1 HashMap为啥线程不安全?
-
JDK1.7里有环(扩容时)。
-
并发添加数据时会覆盖,数据可能丢失。
-
在记录元素个数和HashMap写的次数时,记录不准确。
-
数据迁移,扩容,也可能会丢失数据。
6.2 ConcurrentHashMap如何保证线程安全的?
-
尾插
-
写入数组时,基于CAS保证安全;插入链表或红黑树时,基于synchronized保证安全。
-
这里
ConcurrentHashMap是采用LongAdder实现的技术,底层还是CAS。 -
ConcurrentHashMap扩容时,基于CAS保证数据迁移不出现并发问题。
6.3 ConcurrentHashMap构建好,数组就创建出来了吗?如果不是,如何保证初始化数组的线程安全?
ConcurrentHashMap是懒加载的机制,而且大多数的框架组件都是懒加载的~
基于CAS来保证初始化线程安全的,这里不但涉及到了CAS去修改sizeCtl的变量去控制线程初始化数据的原子性,同时还使用了DCL,外层判断数组未初始化,中间基于CAS修改sizeCtl,内层再做数组未初始化判断。
所谓的懒加载机制就是可以规定指定的对象不在启动时立即创建,而是在后续第一次用到时才创建
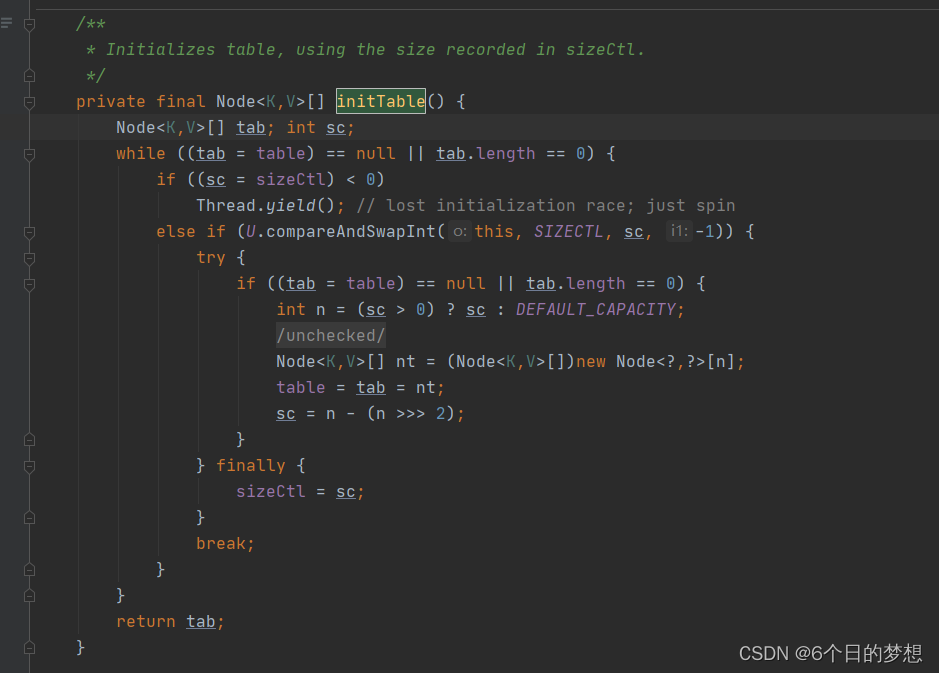
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
表初始化和调整大小控件。当为负值时
able正在初始化或调整大小:-1用于初始化,
else-(1+活动的调整大小线程的数量)。否则
当table为null时,保留要使用的初始表大小
创建,或默认为0。初始化后,保持
用于调整表大小的下一个元素计数值。
*/
private transient volatile int sizeCtl;6.4 为什么负载因子是0.75,为什么链表长度到8转为红黑树?
负载因子是0.75从两个方面去解释。为啥不是0.5,为啥不是1?
0.5:如果负载因子是0.5,数据添加一半就开始扩容了
-
优点:hash碰撞少,查询效率高。
-
缺点:扩容太频繁,而且空间利用率低。
1:如果负载因子是1,数据添加到数组长度才开始扩容
-
优点:扩容不频繁,空间利用率可以的。
-
缺点:hash冲突会特别频繁,数据挂到链表上,影响查询效率,甚至链表过长生成红黑树,导致写入的效率也收到影响。
0.75就可以说是一个居中的选择,两个方面都兼顾了。
再就是泊松分布,在负载因子是0.75时,根据泊松分布得出,链表长度达到8的概率是非常低的,源码中的标识是0.00000006,生成红黑树的概率特别低。虽然ConcurrentHashMap引入了红黑树,但是红黑树对于写入的维护成本更高,能不用就不用,HashMap源码的注释也描述了,要尽可能规避红黑树。
6.5put操作太频繁的场景,会造成扩容时期put的阻塞 ?
一般情况下不会造成阻塞。
-
如果在put操作时,发现当前索引位置并没有数据时,正常把数据落到老数组上。
-
如果put操作时,发现当前位置数据已经被迁移到了新数组,这时无法正常插入,去帮助扩容,快速结束扩容操作,并且重新选择索引位置查询
6.6 ConcurrentHashMap何时扩容,扩容的流程是什么?
-
ConcurrentHashMap中的元素个数,达到了负载因子计算的阈值,那么直接扩容 -
当调用putAll方法,查询大量数据时,也可能会造成直接扩容的操作,大量数据是如果插入的数据大于下次扩容的阈值,直接扩容,然后再插入
-
数组长度小于64,并且链表长度大于等于8时,会触发扩容
6.7 ConcurrentHashMap的计数器如何实现的?
这里是基于LongAdder的机制实现,但是并没有直接用LongAdder的引用,而是根据LongAdder的原理写了一个相似度在80%以上的代码,直接使用。
LongAdder使用CAS添加,保证原子性,其次基于分段锁,保证并发性。
6.8 ConcurrentHashMap的读操作会阻塞嘛?
无论查哪,都不阻塞。
-
查询数组:查看元素是否在数组,在就直接返回。
-
查询链表:在链表next,next查询即可。
-
扩容时:如果当前索引位置是-1,代表当前位置数据全部都迁移到了新数组,直接去新数组查询,不管有没有扩容完。
-
查询红黑树:转换红黑树时,不但有一个红黑树,还会保留一个双向链表,此时会查询双向链表,不让读线程阻塞。
看到并发包中的实现类,采用了大量的数据结构, 主要是数组,链表(单链表/双链表)、二叉堆、平衡树、红黑树、队列。


![[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling](https://img-blog.csdnimg.cn/d8775c50461f401e962e16833c5b9d0a.png)