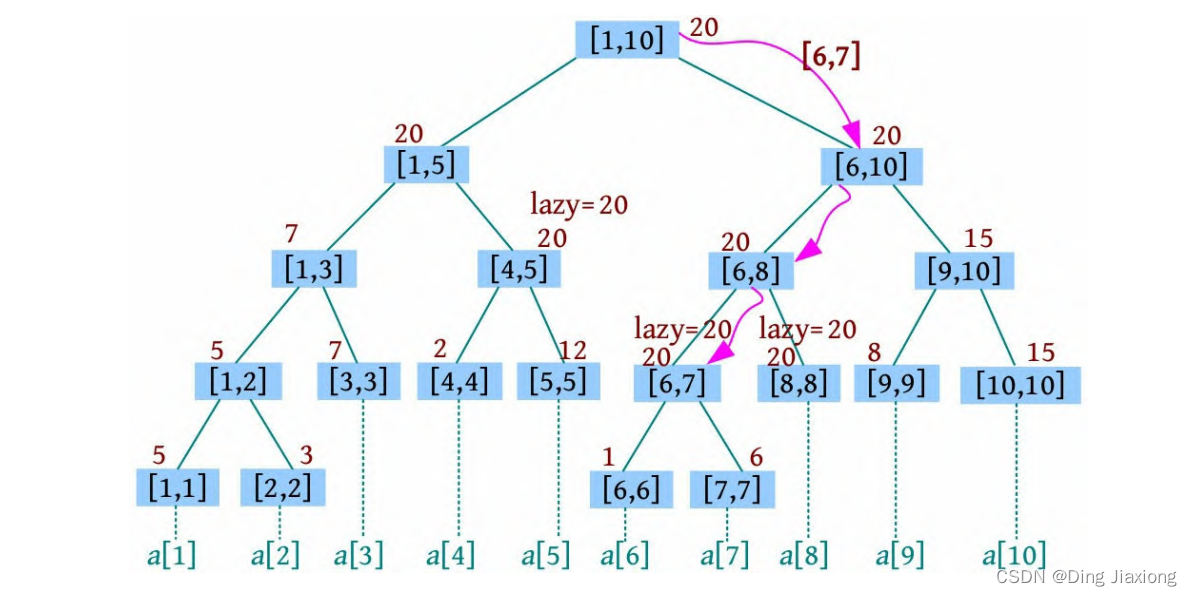
针对传统下的三元组抽取提出的一种方法,在NYT和webNLG数据集上,再次刷新榜单。
本来对这个结果不是很确定,但作者公布了源码,we can reformulate it .
很少在看到这种文章了吧。
Core idea
换了一种解释思路。
从entity-entity的interaction和entity-relation的interaction两种角度提出的模型结构。
根据entity-entity和entity-relation两种关系得到triple。

Model structure
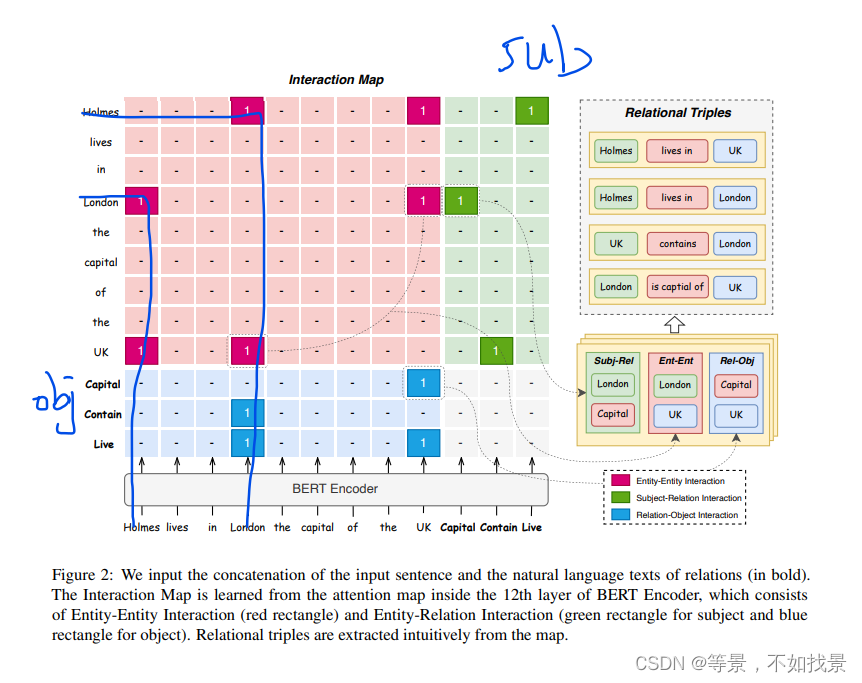
在句子尾部拼接上具体的关系类型,然后,通过bert 的内在注意力机制则可以建立token和token之间的交互关系,(这其实就是一个table filling task),通过二分类问题,将每个格子内填充具体的值,表明两者之间是否存在关系。
粉色是entity-entity之间的交互,蓝色是object和relation之间的交互,绿色是subject和relation之间的交互。
根据这三种交互关系,可以得到最终的triples.
loss function
损失函数时通过binary_cross_entropy loss 计算的。
N+M:N是original sentence,M是relation classes。

Experiments
在NYT 和webNLG上的效果较佳。
- Effect of the Unified Representation
我们使用BERT的占位符[unused]来表示表1中标记为UniRel_unused的关系。与无意义的标签ID一样,[unused]标记的嵌入在微调阶段被随机初始化,没有增加从预训练中学到的有意义的语义信息。我们可以看到,在没有统一表示的情况下,两个数据集的所有评价指标都出现了性能下降,这表明语义信息对关系型三元组提取的重要性。
- Effect of the Unified Interaction
为了研究统一交互的影响,我们将关系序列从输入句中取出,以单独的方式对两种交互进行建模,在表1中表示为UniRel_separate。具体来说,**我们首先用同一个BERT编码器分别得到输入句子和关系的自然语言文本的序列嵌入。然后,我们应用两个转换层来获得查询和两个嵌入的连接的关键。**最后,通过对查询和密钥进行点制作,输出交互图。






![[附源码]SSM计算机毕业设计学校缴费系统JAVA](https://img-blog.csdnimg.cn/e487e282f76948d388ca739d61f57c83.png)