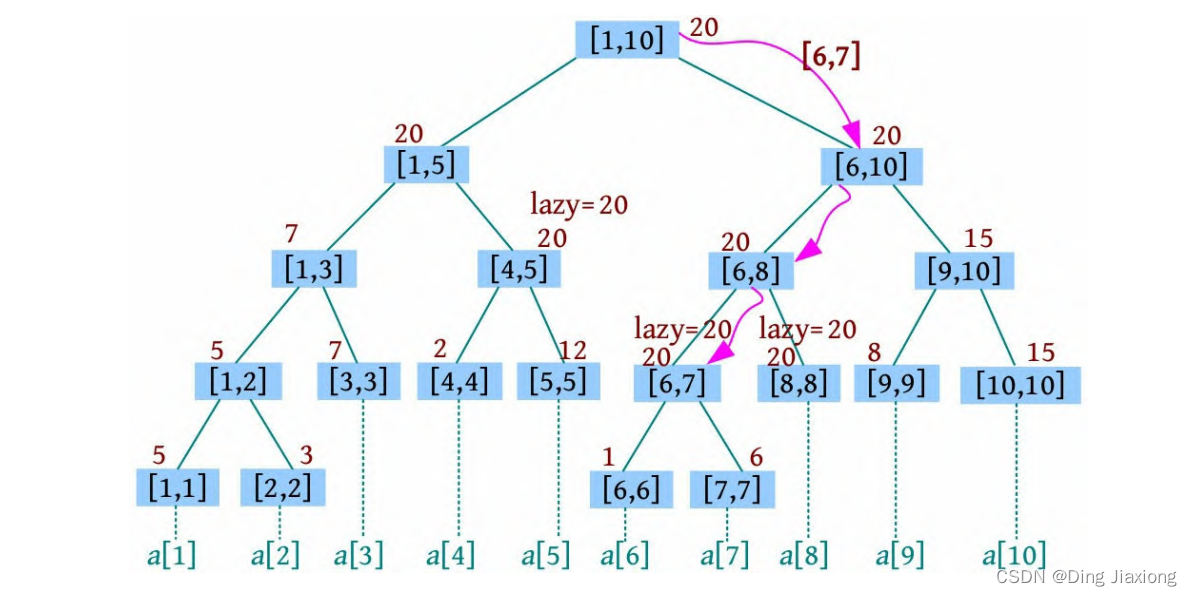
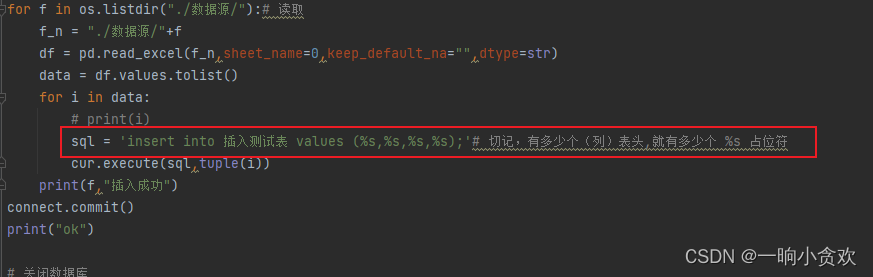
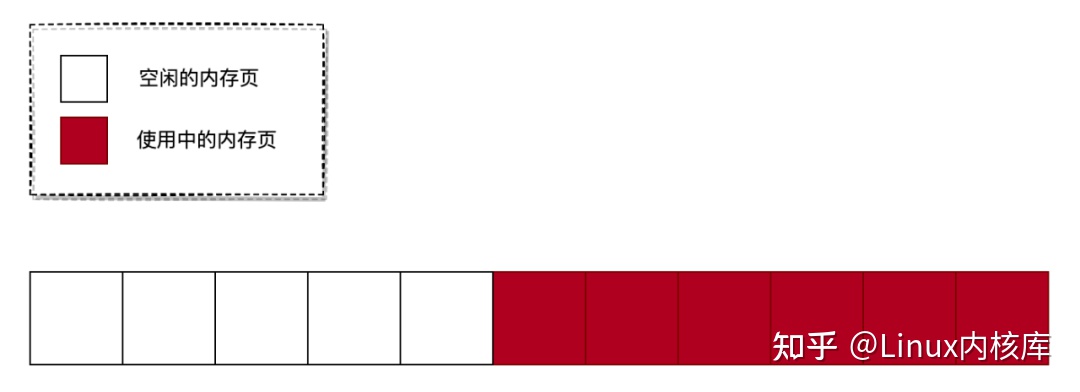
我们知道物理内存是以页为单位进行管理的,每个内存页大小默认是4K(大页除外)。申请物理内存时,一般都是按顺序分配的,但释放内存的行为是随机的。随着系统运行时间变长后,将会出现以下情况:

要解决这个问题也比较简单,只需要把空闲的内存块移动到一起即可。如下图所示:
网络上有句很有名的话:理想很美好,现实很骨感。
内存整理也是这样,看起来很简单,但实现起来就不那么简单了。因为在内存整理后,需要修正进程的虚拟内存与物理内存之间的映射关系。如下图所示:

但由于 Linux 内核有个名为 内存页反向映射 的功能,所以内存整理就变得简单起来。
接下来,我们将会分析内存碎片整理的原理与实现。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
内存碎片整理原理
内存碎片整理的原理比较简单:在内存碎片整理开始前,会在内存区的头和尾各设置一个指针,头指针从头向尾扫描可移动的页,而尾指针从尾向头扫描空闲的页,当他们相遇时终止整理。下面说说内存随便整理的过程(原理参考了内核文档):
- 初始时内存状态:

在上图中,白色块表示空闲的内存页,而红色块表示已分配出去的内存页。在初始状态时,内存中存在多个碎片。如果此时要申请 3 个地址连续的内存页,那么将会申请失败。
- 内存碎片整理扫描开始:

头部指针从头扫描可移动页,而尾部指针从从尾扫描空闲页。在整理时,将可移动页的内容复制到空闲页中。复制完成后,将可移动内存页释放即可。
- 最后结果:

经过内存碎片整理后,如果现在要申请 3 个地址连续的内存页,就能申请成功了。
内存碎片整理实现
接下来,我们将会分析内存碎片整理的实现过程。
注:本文使用的是 Linux-2.6.36 版本的内存
1. 内存碎片整理时机
当要申请多个地址联系的内存页时,如果申请失败,将会进行内存碎片整理。其调用链如下:
alloc_pages_node()
└→ __alloc_pages()
└→ __alloc_pages_nodemask()
└→ __alloc_pages_slowpath()
└→ __alloc_pages_direct_compact()
当调用 alloc_pages_node() 函数申请多个地址连续的内存页失败时,将会触发调用 __alloc_pages_direct_compact() 函数来进行内存碎片整理。我们来看看 __alloc_pages_direct_compact() 函数的实现:
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask,
unsigned int order,
struct zonelist *zonelist,
enum zone_type high_zoneidx,
nodemask_t *nodemask,
int alloc_flags,
struct zone *preferred_zone,
int migratetype,
unsigned long *did_some_progress)
{
struct page *page;
// 1. 如果申请一个内存页,那么就没有整理碎片的必要(这说明是内存不足,而不是内存碎片导致)
if (!order || compaction_deferred(preferred_zone))
return NULL;
// 2. 开始进行内存碎片整理
*did_some_progress = try_to_compact_pages(zonelist, order, gfp_mask, nodemask);
if (*did_some_progress != COMPACT_SKIPPED) {
...
// 3. 整理完内存碎片后,继续尝试申请内存块
page = get_page_from_freelist(gfp_mask, nodemask, order, zonelist,
high_zoneidx, alloc_flags, preferred_zone,
migratetype);
if (page) {
...
return page;
}
...
}
return NULL;
}
__alloc_pages_direct_compact() 函数是内存碎片整理的入口,其主要完成 3 个步骤:
- 先判断申请的内存块是否只有一个内存页,如果是,那么就没有整理碎片的必要(这说明是内存不足,而不是内存碎片导致)。
- 如果需要进行内存碎片整理,那么调用 try_to_compact_pages() 函数进行内存碎片整理。
- 整理完内存碎片后,调用 get_page_from_freelist() 函数继续尝试申请内存块。
2. 内存碎片整理过程
由于内存碎片整理的具体实现在 try_to_compact_pages() 函数中进行,所以我们继续来看看 try_to_compact_pages() 函数的实现:
unsigned long
try_to_compact_pages(struct zonelist *zonelist, int order, gfp_t gfp_mask,
nodemask_t *nodemask)
{
...
// 1. 遍历所有内存区(由于内核会把物理内存分成多个内存区进行管理)
for_each_zone_zonelist_nodemask(zone, z, zonelist, high_zoneidx, nodemask) {
...
// 2. 对内存区进行内存碎片整理
status = compact_zone_order(zone, order, gfp_mask);
...
}
return rc;
}
可以看出,try_to_compact_pages() 函数最终会调用 compact_zone_order() 函数来进行内存碎片整理。我们只能进行来分析 compact_zone_order() 函数:
static unsigned long
compact_zone_order(struct zone *zone, int order, gfp_t gfp_mask)
{
struct compact_control cc = {
.nr_freepages = 0,
.nr_migratepages = 0,
.order = order,
.migratetype = allocflags_to_migratetype(gfp_mask),
.zone = zone,
};
INIT_LIST_HEAD(&cc.freepages);
INIT_LIST_HEAD(&cc.migratepages);
return compact_zone(zone, &cc);
}
到这里,我们还没有看到内存碎片整理的具体实现(调用链可真深啊 ^_^!),compact_zone_order() 函数也是构造了一些参数,然后继续调用 compact_zone() 来进行内存碎片整理:
static int compact_zone(struct zone *zone, struct compact_control *cc)
{
...
while ((ret = compact_finished(zone, cc)) == COMPACT_CONTINUE) {
...
// 1. 收集可移动的内存页列表
if (!isolate_migratepages(zone, cc))
continue;
...
// 2. 将可移动的内存页列表迁移到空闲列表中
migrate_pages(&cc->migratepages, compaction_alloc, (unsigned long)cc, 0);
...
}
...
return ret;
}
在 compact_zone() 函数里,我们终于看到内存碎片整理的逻辑了。compact_zone() 函数主要完成 2 个步骤:
- 调用 isolate_migratepages() 函数收集可移动的内存页列表。
- 调用 migrate_pages() 函数将可移动的内存页列表迁移到空闲列表中。
这两个函数非常重要,我们分别来分析它们是怎么实现的。
isolate_migratepages() 函数
isolate_migratepages() 函数用于收集可移动的内存页列表,我们来看看其实现:
static unsigned long
isolate_migratepages(struct zone *zone, struct compact_control *cc)
{
unsigned long low_pfn, end_pfn;
struct list_head *migratelist = &cc->migratepages;
...
// 1. 扫描内存区所有的内存页
for (; low_pfn < end_pfn; low_pfn++) {
struct page *page;
...
// 2. 通过内存页的编号获取内存页对象
page = pfn_to_page(low_pfn);
...
// 3. 判断内存页是否可移动内存页,如果不是可移动内存页,那么就跳过
if (__isolate_lru_page(page, ISOLATE_BOTH, 0) != 0)
continue;
// 4. 将内存页从 LRU 队列中删除
del_page_from_lru_list(zone, page, page_lru(page));
// 5. 添加到可移动内存页列表中
list_add(&page->lru, migratelist);
...
cc->nr_migratepages++;
...
}
...
return cc->nr_migratepages;
}
isolate_migratepages() 函数主要完成 5 个步骤,分别是:
- 扫描内存区所有的内存页(与内存碎片整理原理一致)。
- 通过内存页的编号获取内存页对象。
- 判断内存页是否可移动内存页,如果不是可移动内存页,那么就跳过。
- 将内存页从 LRU 队列中删除,这样可避免被其他进程回收这个内存页。
- 添加到可移动内存页列表中。
当完成这 5 个步骤后,内核就收集到可移动的内存页列表。
migrate_pages() 函数
migrate_pages() 函数负责将可移动的内存页列表迁移到空闲列表中,我们来分析一下其实现过程:
int migrate_pages(struct list_head *from, new_page_t get_new_page,
unsigned long private, int offlining)
{
...
for (pass = 0; pass < 10 && retry; pass++) {
retry = 0;
// 1. 遍历可移动内存页列表
list_for_each_entry_safe(page, page2, from, lru) {
...
// 2. 将可移动内存页迁移到空闲内存页中
rc = unmap_and_move(get_new_page, private, page, pass > 2, offlining);
switch(rc) {
case -ENOMEM:
goto out;
case -EAGAIN:
retry++;
break;
case 0:
break;
default:
nr_failed++;
break;
}
}
}
...
return nr_failed + retry;
}
migrate_pages() 函数的逻辑很简单,主要完成 2 个步骤:
- 遍历可移动内存页列表,这个列表就是通过 isolate_migratepages() 函数收集的可移动内存页列表。
- 调用 unmap_and_move() 函数将可移动内存页迁移到空闲内存页中。
可以看出,具体的内存迁移过程在 unmap_and_move() 函数中实现。我们来看看 unmap_and_move() 函数的实现:
static int
unmap_and_move(new_page_t get_new_page, unsigned long private,
struct page *page, int force, int offlining)
{
...
// 1. 从内存区中找到一个空闲的内存页
struct page *newpage = get_new_page(page, private, &result);
...
// 2. 解开所有使用了当前可移动内存页的进程的虚拟内存映射(涉及到内存页反向映射)
try_to_unmap(page, TTU_MIGRATION|TTU_IGNORE_MLOCK|TTU_IGNORE_ACCESS);
skip_unmap:
// 3. 将可移动内存页的数据复制到空闲内存页中
if (!page_mapped(page))
rc = move_to_new_page(newpage, page, remap_swapcache);
...
return rc;
}
由于 unmap_and_move() 函数的实现比较复杂,所以我们对其进行了简化。可以看出,unmap_and_move() 函数主要完成 3 个工作:
- 从内存区中找到一个空闲的内存页。根据内存碎片整理算法,会从内存区最后开始扫描,找到合适的空闲内存页。
- 由于将可移动内存页迁移到空闲内存页后,进程的虚拟内存映射将会发生变化。所以,这里要调用 try_to_unmap() 函数来解开所有使用了当前可移动内存页的映射。
- 调用 move_to_new_page() 函数将可移动内存页的数据复制到空闲内存页中。在 move_to_new_page() 函数中,还会重新建立进程的虚拟内存映射,这样使用了当前可移动内存页的进程就能够正常运行。
至此,内存碎片整理的过程已经分析完毕。
不过细心的读者可能发现,在文中并没有分析重新构建虚拟内存映射的过程。是的,因为重新构建虚拟内存映射要涉及到 内存页反向映射 的知识点,后续的文章会介绍这个知识点,所以这里就不作详细分析了。
总结
从上面的分析可知,内存碎片整理 是为了解决:在申请多个地址连续的内存页时,空闲内存页数量充足,但还是分配失败的情况。
但由于内存碎片整理需要消耗大量的 CPU 时间,所以我们在申请内存时,可以通过指定 __GFP_WAIT 标志位(不等待)来避免内存碎片整理过程。


![[附源码]SSM计算机毕业设计学校缴费系统JAVA](https://img-blog.csdnimg.cn/e487e282f76948d388ca739d61f57c83.png)