目录
一、常见的聚合函数
二、GROUP BY 的使用
三、HAVING 的使用,过滤数据
四、SQL底层的执行原理
五、练习
一、常见的聚合函数
1.概念
聚合函数作用于一组数据,并对一组数据返回一个值。

2.聚合函数的类型
AVG(),SUM(),MAX(),MIN(),COUNT()
3. AVG(),SUM():数值
①查询员工表的平均工资以及员工表的总工资
select avg(salary) "avg",sum(salary) "sum"
from employees②对于字符串结果是0
4. MAX(),MIN():数值,字符串,日期
①查询员工表的最高的工资和最低的工资
select max(salary) "max", min(salary) "min"
from employees
②对于字符串来说,可以查找到首字母最大的名字,最小的名字
select max(last_name) "max", min(last_name) "min"
from employees

5. COUNT()
①作用:计算指定的字段的个数
②count(*),count(1),count(字段名)的区别?
- count(*)和count(1)能查询表中有多少条记录。
- count(字段名)查询该字段名下非空的记录。
- ③
-
SELECT count(*),count(1),count(commission_pct) FROM employees
6.查询员工表的平均奖金率。
-
avg(commission_pct)=sum(commission_pct)/count(commission_pct) 只计算员工有奖金的,除以有奖金的总人数。所以avg(commission_pct)是错误的。应该除以总人数SUM(commission_pct)/count(*)正确
-
7. count(*),count(1),count(非空字段名)哪个效率高。
-
①如果使用的MyISAM的存储引擎,三者效率相同都是O(1) 引擎内部有一计数器在维护着行数
②如果使用的InnoDB的存储引擎,三个效率count(*) = count(1) > count(非空字段名)
count(*),count(1)直接读行数,复杂度是O(n), innodb真的要去数一遍。但好于具体的count(列名)
-
二、GROUP BY 的使用
-
1.基本使用
-

2.求员工表各个部门的平均工资,每个部门的总工资
-
SELECT department_id,AVG(salary),SUM(salary) FROM employees GROUP BY department_id
-
3.查询每个部门的各个工种的平均工资,总工资
-

SELECT department_id,job_id,AVG(salary),SUM(salary) FROM employees GROUP BY department_id,job_id 或 SELECT department_id,job_id,AVG(salary),SUM(salary) FROM employees GROUP BY job_id,department_id
4.select出现的分组的字段必须在GROUP BY中
-
SELECT department_id,job_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id
错误的!
-
5. WITH ROLLUP计算查询出的所有记录的总和,不能跟order by一起使用
-
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id WITH ROLLUP
-
三、HAVING 的使用,过滤数据

条件:
- 行已经被分组;
- 使用了聚合函数;
- 满足HAVING 子句中条件的分组将被显示;
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用;
1.查询各个部门中最高的工资比10000高的部门有哪些
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id HAVING MAX(salary)>10000 ;
2.过滤条件使用聚合函数(max)必须使用having来替换where
3.查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
方式1(效率高)
select department_id,max(salary)
from employees
where department_id in (10,20,30,40)
group by department_id having max(salary)>10000
方式2
select department_id,max(salary)
from employees
group by department_id having max(salary)>10000 and department_id in (10,20,30,40)
4.where和having的对比
①过滤条件有聚合函数用having
②过滤条件没有聚合函数having和where都可以。但是推荐where。因为having是先连接后筛选,where是先筛选后连接。Where效率高。

四、SQL底层的执行原理
1.select语句的完整结构
select 字段名
from 表名
left/right join 表2 on 多表的连接条件
where 查询条件
group by 分组字段 having 查询条件
order by 排序字段 asc/desc
limit 位置,偏移量
2.sql语句执行顺序

五、练习
#1.where子句可否使用组函数进行过滤?
不能,组函数是使用having过滤
#2.查询公司员工工资的最大值,最小值,平均值,总和
select max(salary),min(salary),avg(salary),sum(salary)
from employees
#3.查询各job_id的员工工资的最大值,最小值,平均值,总和
select job_id,max(salary),min(salary),avg(salary),sum(salary)
from employees
group by job_id
#4.查询各个job_id的员工人数
select job_id,count(*)
from employees
group by job_id
# 5.查询员工最高工资和最低工资的差距 (DIFFERENCE)
select max(salary)-min(salary) "DIFFERENCE"
from employees
# 6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
select manager_id,min(salary)
from employees
where manager_id is not null
group by manager_id having min(salary)>=6000

# 7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
select d.department_name,d.location_id,count(employee_id) "pepole_count",avg(salary)
from employees e
right join departments d on e.department_id = d.department_id
group by department_name,location_id
order by avg(salary) desc

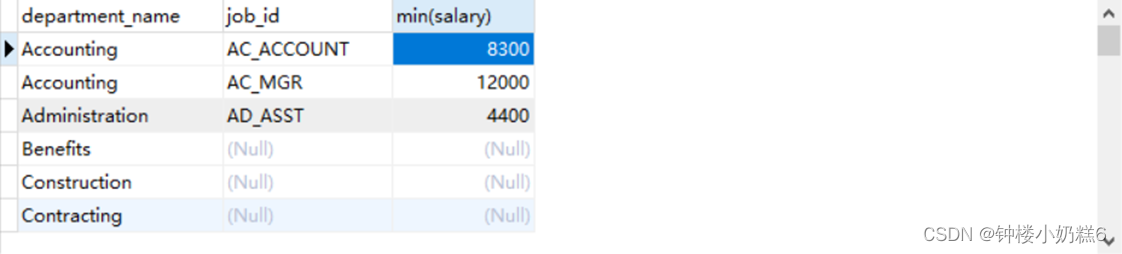
#8.查询每个工种、每个部门的部门名、工种名和最低工资
select d.department_name,e.job_id,min(salary)
from employees e
right join departments d on e.department_id = d.department_id
group by d.department_name,e.job_id







![Mac电脑配置李沐深度学习环境[pytorch版本]使用vscode](https://img-blog.csdnimg.cn/0d6b06cc705442afa2290ef104e56e8a.png)