作者:王斌 谢春宇 冷大炜
引言
目标检测是计算机视觉中的一个非常重要的基础任务,与常见的的图像分类/识别任务不同,目标检测需要模型在给出目标的类别之上,进一步给出目标的位置和大小信息,在CV三大任务(识别、检测、分割)中处于承上启下的关键地位。当前大火的多模态GPT4在视觉能力上只具备目标识别的能力,还无法完成更高难度的目标检测任务。而识别出图像或视频中物体的类别、位置和大小信息,是现实生产中众多人工智能应用的关键,例如自动驾驶中的行人车辆识别、安防监控应用中的人脸锁定、医学图像分析中的肿瘤定位等等。
已有的目标检测方法如YOLO系列、R-CNN系列等耳熟能详的目标检测算法在科研人员的不断努力下已经具备很高的目标检测精度与效率,但由于现有方法需要在模型训练前就定义好待检测目标的集合(闭集),导致它们无法检测训练集合之外的目标,比如一个被训练用于检测人脸的模型就不能用于检测车辆;另外,现有方法高度依赖人工标注的数据,当需要增加或者修改待检测的目标类别时,一方面需要对训练数据进行重新标注,另一方面需要对模型进行重新训练,既费时又费力。一个可能的解决方案是,收集海量的图像,并人工标注Box信息与语义信息,但这将需要极高的标注成本,而且使用海量数据对检测模型进行训练也对科研工作者提出了严峻的挑战,如数据的长尾分布问题与人工标注的质量不稳定等因素都将影响检测模型的性能表现。
发表于CVPR2021的文章OVR-CNN[1]提出了一种全新的目标检测范式:开放词集目标检测(Open-Vocabulary Detection,OVD,亦称为开放世界目标检测),来应对上文提到的问题,即面向开放世界未知物体的检测场景。OVD由于能够在无需人工扩充标注数据量的情形下识别并定位任意数量和类别目标的能力,自提出后吸引了学术界与工业界持续增长的关注,也为经典的目标检测任务带来了新的活力与新的挑战,有望成为目标检测的未来新范式。具体地,OVD技术不需要人工标注海量的图片来增强检测模型对未知类别的检测能力,而是通过将具有良好泛化性的无类别(class-agnostic)区域检测器与经过海量无标注数据训练的跨模态模型相结合,通过图像区域特征与待检测目标的描述性文字进行跨模态对齐来扩展目标检测模型对开放世界目标的理解能力。跨模态和多模态大模型工作近期的发展非常迅速,如CLIP[2]、ALIGN[3]与R2D2[4]等,而它们的发展也促进了OVD的诞生与OVD领域相关工作的快速迭代与进化。
OVD技术涉及两大关键问题的解决:1)如何提升区域(Region)信息与跨模态大模型之间的适配;2)如何提升泛类别目标检测器对新类别的泛化能力。从这个两个角度出发,下文我们将详细介绍一些OVD领域的相关工作。
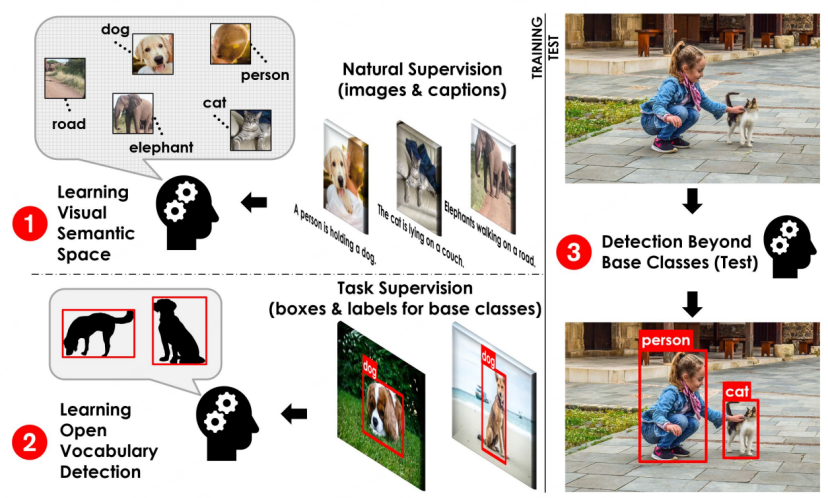
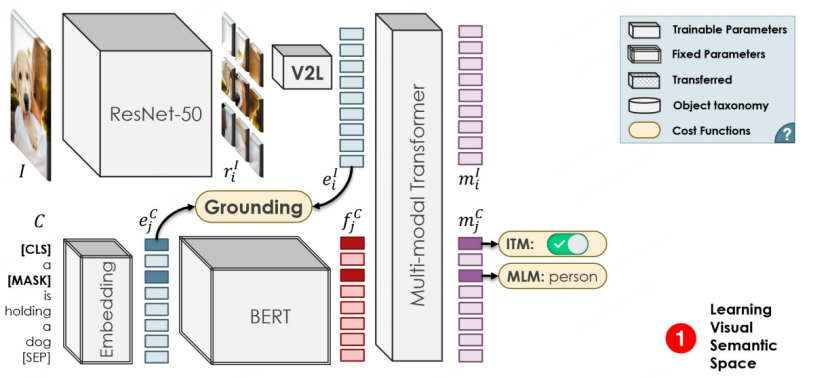
OVD基本流程示意[1]
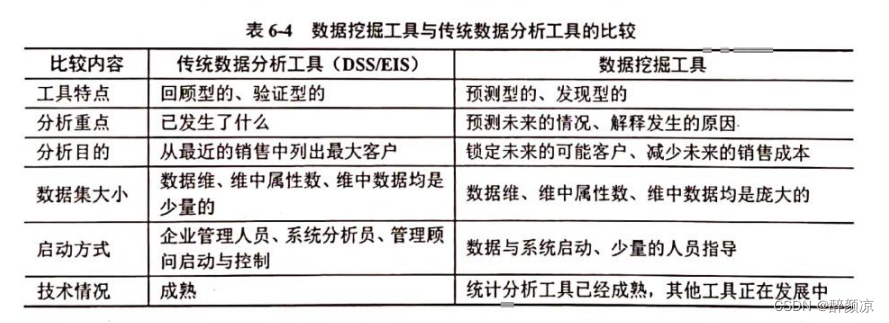
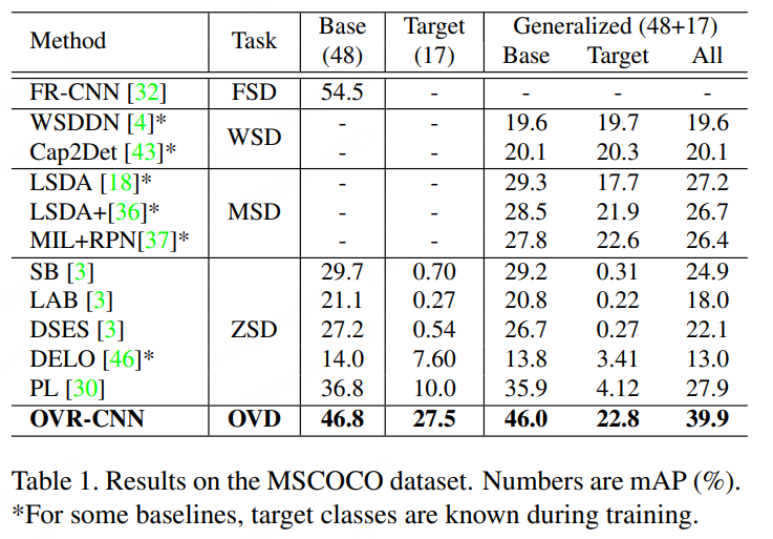
OVD的基础概念:OVD的使用主要涉及到 few-shot 和 zero-shot两大类场景,few-shot是指有少量人工标注训练样本的目标类别,zero-shot则是指不存在任何人工标注训练样本的目标类别。在常用的学术评测数据集COCO、LVIS上,数据集会被划分为Base类和Novel类,其中Base类对应few-shot场景,Novel类对应zero-shot场景。如COCO数据集包含65种类别,常用的评测设定是Base集包含48种类别,few-shot训练中只使用该48个类别。Novel集包含17种类别,在训练时完全不可见。测试指标主要参考Novel类的AP50数值进行比较。

论文地址:https://arxiv.org/pdf/2011.10678.pdf
代码地址:https://github.com/alirezazareian/ovr-cnn
OVR-CNN是CVPR2021的Oral-Paper,也是OVD领域的开山之作。它的二阶段训练范式,影响了后续很多的OVD工作。如下图所示,第一阶段主要使用image-caption pairs对视觉编码器进行预训练,其中借助BERT(参数固定)来生成词掩码,并与加载ImageNet预训练权重的ResNet50进行弱监督的Grounding匹配,作者认为弱监督会让匹配陷入局部最优,于是加入多模态Transformer进行词掩码预测来增加鲁棒性。
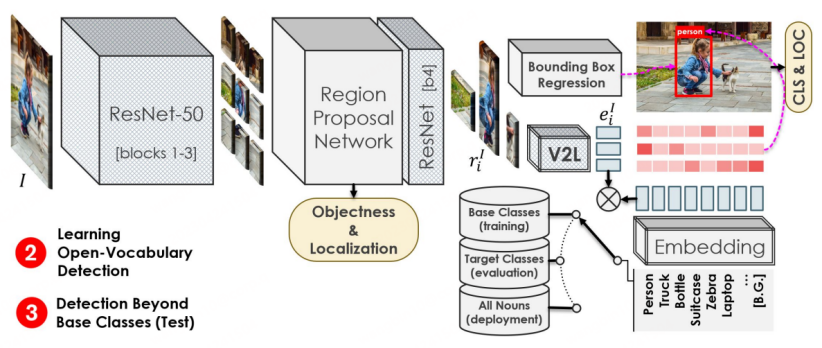
第二阶段的训练流程与Faster-RCNN类似,区别点在于,特征提取的Backbone来自于第一阶段预训练得到的ResNet50的1-3层,RPN后依然使用ResNet50的第四层进行特征加工,随后将特征分别用于Box回归与分类预测。分类预测是OVD任务区别于常规检测的关键标志,OVR-CNN中将特征输入一阶段训练得到的V2L模块(参数固定的图向量转词向量模块)得到一个图文向量,随后与标签词向量组进行匹配,对类别进行预测。在二阶段训练中,主要使用Base类对检测器模型进行框回归训练与类别匹配训练。由于V2L模块始终固定,配合目标检测模型定位能力向新类别迁移,使得检测模型能够识别并定位到全新类别的目标。
如下图所示,OVR-CNN在COCO数据集上的表现远超之前的Zero-shot目标检测算法。

论文地址:https://arxiv.org/abs/2112.09106
代码地址:https://github.com/microsoft/RegionCLIP
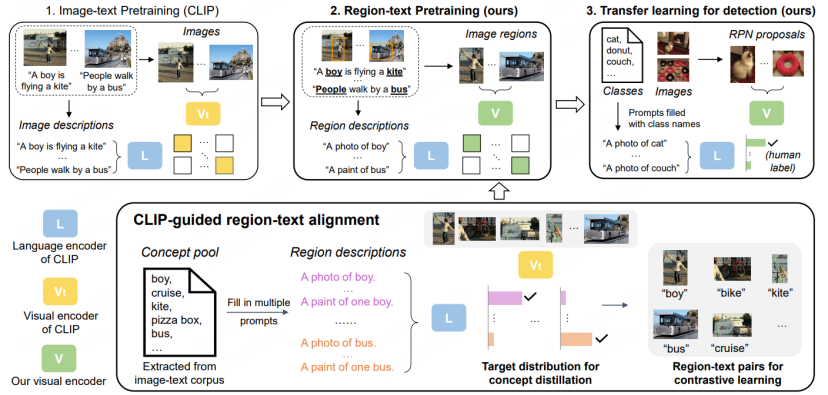
OVR-CNN中使用BERT与多模态Transfomer进行image-text pairs预训练,但随着跨模态大模型研究的兴起,科研工作者开始利用CLIP,ALIGN等更强力的跨模态大模型对OVD任务进行训练。检测器模型本身主要针对Proposals,即区域信息进行分类识别,发表于CVPR2022的RegionCLIP[5]发现当前已有的大模型,如CLIP,对裁剪区域的分类能力远低于对原图本身的分类能力,为了改进这一点,RegionCLIP提出了一个全新的两阶段OVD方案。

第一阶段,数据集主要使用CC3M,COCO-caption等图文匹配数据集进行区域级别的蒸馏预训练。具体地,
1.将原先存在于长文本中的词汇进行提取,组成Concept Pool,进一步形成一组关于Region的简单描述,用于训练。
2.利用基于LVIS预训练的RPN提取Proposal Regions,并利用原始CLIP对提取到的不同Region与准备好的描述进行匹配分类,并进一步组装成伪造的语义标签。
3.将准备好的Proposal Regions与语义标签在新的CLIP模型上进行Region-text对比学习,进而得到一个专精于Region信息的CLIP模型。
4.在预训练中,新的CLIP模型还会通过蒸馏策略学习原始CLIP的分类能力,以及进行全图级别的image-text对比学习,来维持新的CLIP模型对完整图像的表达能力。
第二阶段,将得到的预训练模型在检测模型上进行迁移学习。
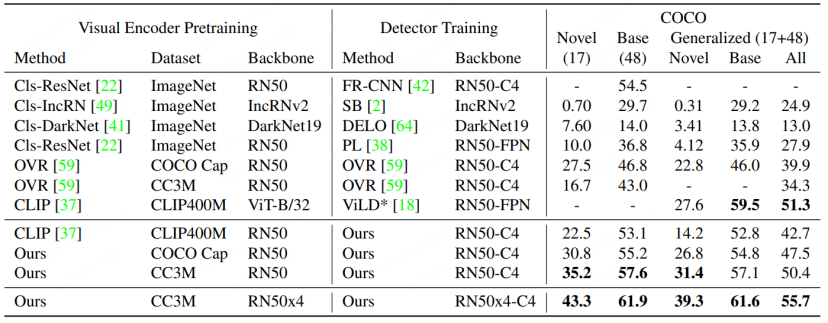
RegionCLIP进一步拓展了已有跨模态大模型在常规检测模型上的表征能力,进而取得了更加出色的性能,如下图所示,RegionCLIP相比OVR-CNN在Novel类别上取得了较大提升。RegionCLIP通过一阶段的预训练有效地的提升了区域(Region)信息与多模态大模型之间的适应能力,但CORA认为其使用更大参数规模的跨模态大模型进行一阶段训练时,训练成本将会非常高昂。

论文地址:https://arxiv.org/abs/2303.13076
代码地址:https://github.com/tgxs002/CORA
CORA[6]已被收录于CVPR2023,为了克服其所提出当前OVD任务所面临的两个阻碍,设计了一个类DETR的OVD模型。如其文章标题所示,该模型中主要包含了Region Prompting与Anchor Pre-Matching两个策略。前者通过Prompt技术来优化基于CLIP的区域分类器所提取的区域特征,进而缓解整体与区域的分布差距,后者通过DETR检测方法中的锚点预匹配策略来提升OVD模型对新类别物体定位能力的泛化性。
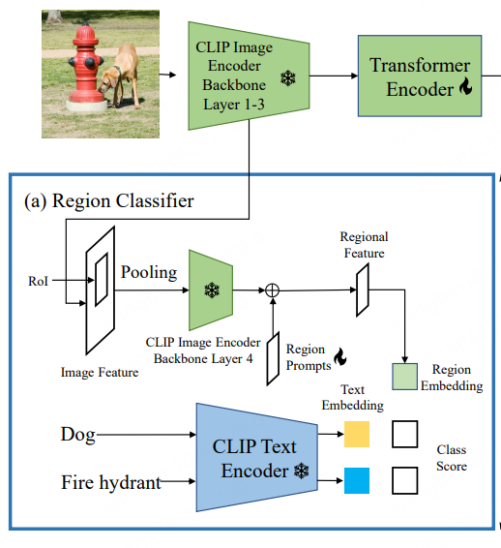
CLIP 原始视觉编码器的整体图像特征与区域特征之间存在分布差距,进而导致检测器的分类精度较低(这一点与RegionCLIP的出发点类似)。因此,CORA提出Region Prompting来适应CLIP图像编码器,提高对区域信息的分类性能。具体地,首先通过CLIP编码器的前3层将整幅图像编码成一个特征映射,然后由RoI Align生成锚点框或预测框,并将其合并成区域特征。随后由 CLIP 图像编码器的第四层进行编码。为了缓解CLIP 图像编码器的全图特征图与区域特征之间存在分布差距,设置了可学习的Region Prompts并与第四层输出的特征进行组合,进而生成最终的区域特征用来与文本特征进行匹配,匹配损失使用了朴素的交叉熵损失,且训练过程中与CLIP相关的参数模型全都冻结。
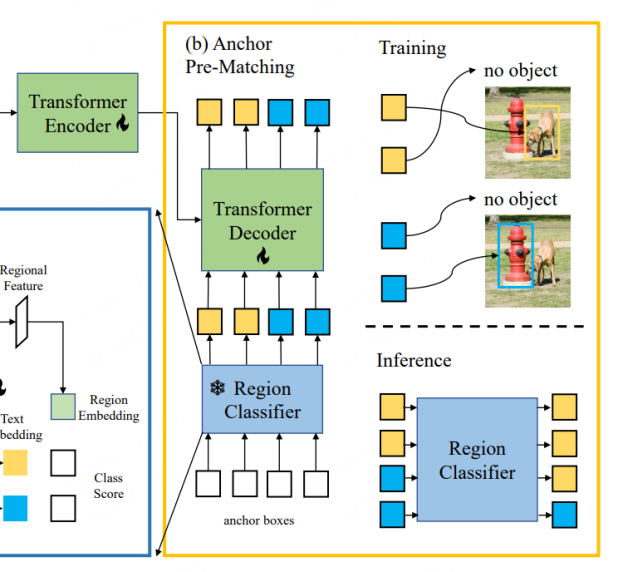
CORA是一个类DETR的检测器模型,类似于DETR,其也使用了锚点预匹配策略来提前生成候选框用于框回归训练。具体来说,锚点预匹配是将每个标签框与最接近的一组锚点框进行匹配,以确定哪些锚点框应该被视为正样本,哪些应该被视为负样本。这个匹配过程通常是基于 IoU(交并比)进行的,如果锚点框与标签框的 IoU 超过一个预定义的阈值,则将其视为正样本,否则将其视为负样本。CORA表明该策略能够有效提高对新类别定位能力的泛化性。
但是使用锚点预匹配机制也会带来一些问题,比如只有在至少有一个锚点框与标签框形成匹配时,才可正常进行训练。否则,该标签框将被忽略,同时阻碍模型的收敛。进一步,即使标签框获得了较为准确的锚点框,由于Region Classifier的识别精度有限,进而导致该标签框仍可能被忽略,即标签框对应的类别信息没有与基于CLIP训练的Region Classifier形成对齐。因此,CORA用CLIP-Aligned技术利用CLIP的语义识别能力,与预训练ROI的定位能力,在较少人力情形下对训练数据集的图像进行重新标注,使用这种技术,可以让模型在训练中匹配更多的标签框。

相比于RegionCLIP,CORA在COCO数据集上进一步提升了2.4的AP50数值。
总结与展望
OVD技术不仅与当前流行的跨/多模态大模型的发展紧密联系,同时也承接了过去科研工作者对目标检测领域的技术耕耘,是传统AI技术与面向通用AI能力研究的一次成功衔接。OVD更是一项面向未来的全新目标检测技术,可以预料到的是,OVD可以检测并定位任意目标的能力,也将反过来推进多模态大模型的进一步发展,有希望成为多模态AGI发展中的重要基石。当下,多模态大模型的训练数据来源是网络上的海量粗糙信息对,即文本图像对或文本语音对。若利用OVD技术对原本粗糙的图像信息进行精准定位,并辅助预测图像的语义信息来筛选语料,将会进一步提升大模型预训练数据的质量,进而优化大模型的表征能力与理解能力。
一个很好的例子便是SAM(Segment Anything)[7],SAM不仅让科研工作者们看到了通用视觉大模型未来方向,也引发了很多思考。值得注意的是,OVD技术可以很好地接入SAM,来增强SAM的语义理解能力,自动地生成SAM需要的box信息,从而进一步解放人力。同样的对于AIGC(人工智能生成内容),OVD技术同样可以增强与用户之间的交互能力,如当用户需要指定一张图片的某一个目标进行变化,或对该目标生成一句描述的时候,可以利用OVD的语言理解能力与OVD对未知目标检测的能力实现对用户描述对象的精准定位,进而实现更高质量的内容生成。当下OVD领域的相关研究蓬勃发展,OVD技术对未来通用AI大模型能够带来的改变值得期待。
号外
为了推动OVD研究在国内的普及和发展,360人工智能研究院联合中国图象图形学学会举办了2023开放世界目标检测竞赛,目前竞赛正在火热报名中。竞赛可以帮助大家找到OVD方向的研究同好,与他们切磋交流,并能接触实际业务场景数据,体验OVD技术在实际生产中的优势与魅力,欢迎报名和转发。
参考文献
[1] Zareian A, Rosa K D, Hu D H, et al. Open-vocabulary object detection using captions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 14393-14402.
[2] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748-8763.
[3] Li J, Selvaraju R, Gotmare A, et al. Align before fuse: Vision and language representation learning with momentum distillation[J]. Advances in neural information processing systems, 2021, 34: 9694-9705.
[4] Xie C, Cai H, Song J, et al. Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework[J]. arXiv preprint arXiv:2205.03860, 2022.
[5] Zhong Y, Yang J, Zhang P, et al. Regionclip: Region-based language-image pretraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16793-16803.
[6] Wu X, Zhu F, Zhao R, et al. CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching[J]. arXiv preprint arXiv:2303.13076, 2023.
[7] Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.