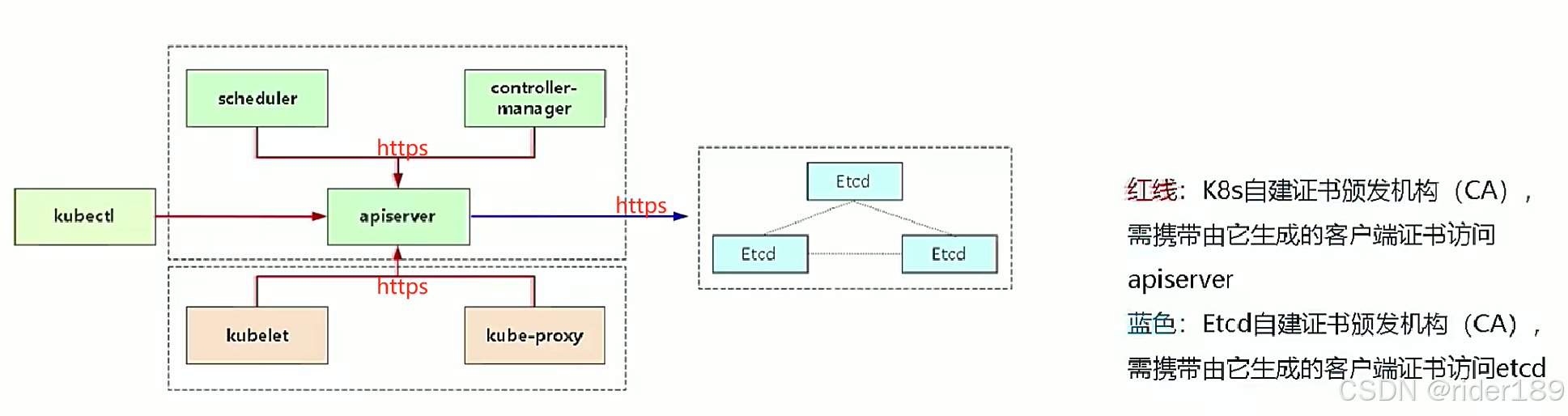
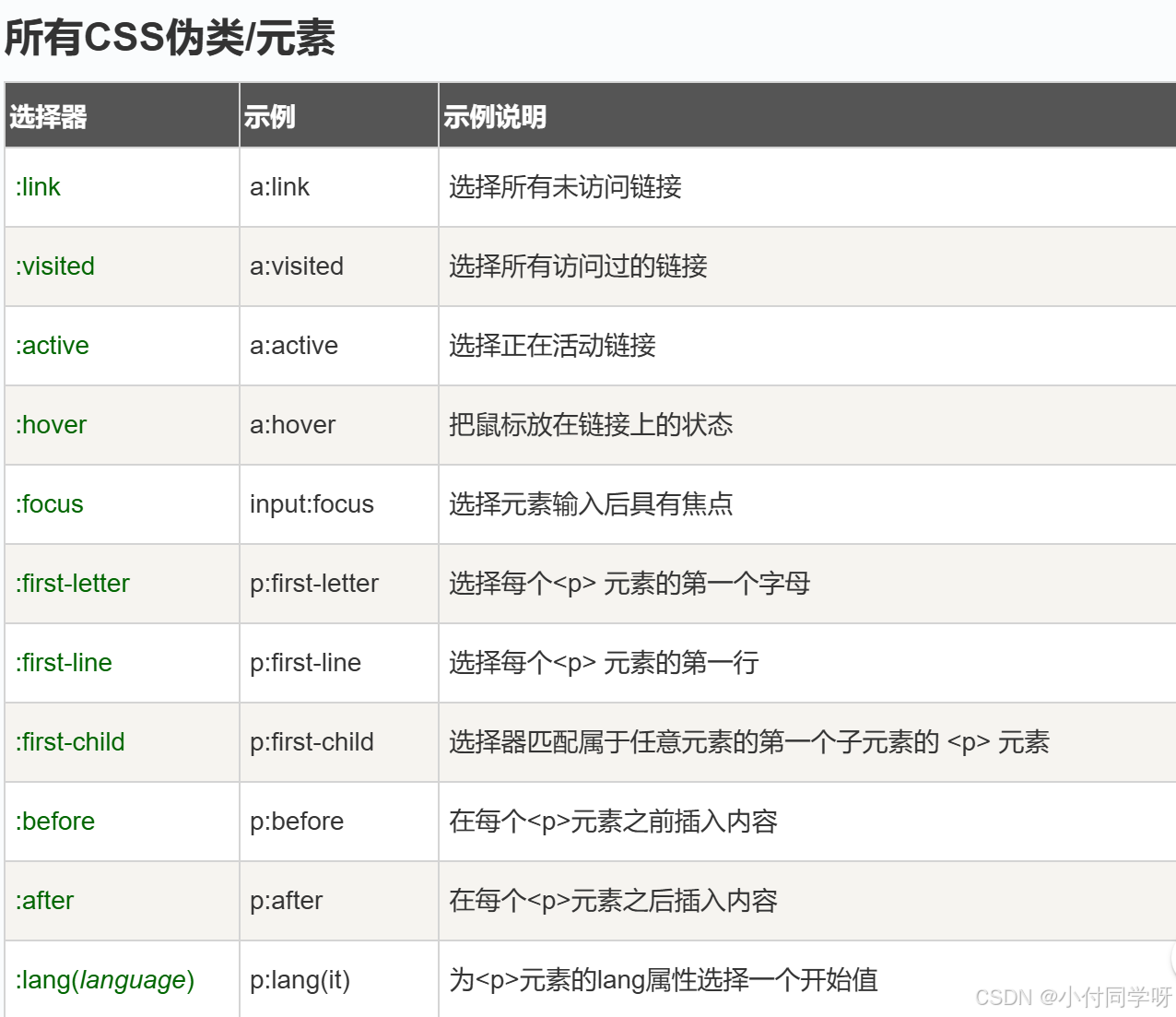
图的基本概念
- 导读
- 一、图中的树与森林
- 1.1 生成树与生成森林
- 1.1.1 生成树
- 1.1.2 生成森林
- 1.1.3 生成树、生成森林与连通分量
- 结点的关系
- 边的关系
- 1.2 有向图中的树与森林
- 1.2.1 有向树与有向森林
- 1.2.2 生产有向树与生成有向森林
- 1.2.3 有向树与生成有向树的区别
- 1.2.4 有向森林与生成有向森林的区别
- 二、权
- 三、特殊图
- 3.1 稀疏图与稠密图
- 3.2 完全图
- 3.2.1 无向完全图
- 3.2.2 有向完全图
- 结语

导读
大家好,很高兴又和大家见面啦!!!
在上一篇中,我们系统梳理了图论基础概念——顶点度、路径计算、结点距离、子图划分与连通性判定,为理解复杂图结构打下根基。
本篇将聚焦图论核心骨架:树与森林。通过对比无向图与有向图中的生成树规则,结合可视化案例解析极小连通子图的设计逻辑,带您掌握权值网络、完全图等延伸概念的数学本质。
无论您是算法竞赛选手还是网络分析研究者,此文都将成为您突破图结构认知瓶颈的关键指南。
一、图中的树与森林
1.1 生成树与生成森林
在无向图中存在两个特有的概念:
- 生成树:生成树指的是在连通图中包含所有顶点的一个极小连通子图。
- 生成森林:生成森林指的是在非连通图中,所有连通分量的生成树的集合。
1.1.1 生成树
生成树是连通图中的概念,它具有以下特点:
- 树中的顶点数量 = 图中的顶点数量
- 树中边的数量 = 树中的顶点数量 - 1
- 树中无环
这里我们以下面这个连通图 G G G 为例:
在图 G G G 中,当我们去掉边集 E ′ = { ( a , b ) , ( b , c ) , ( a , c ) } E' = \{(a, b), (b, c), (a, c)\} E′={(a,b),(b,c),(a,c)} 中的其中任意一条边,此时的子图 G ′ G' G′ 还能够继续保持连通性,这里我们以去掉边 ( a , b ) (a, b) (a,b) 为例:
该子图 G ′ G' G′ 就是 G G G 的一棵生成树。对于生成树而言,边的数量既不能增加,也不能减少:
- 当我们再去掉任意一条边时,该连通图就变成了一个非连通图;
- 当我们再加上一条边时,该连通图中就会出现环;
1.1.2 生成森林
生成森林是非连通图中的概念,它是由非连通图的所有连通分量的生成树组成,这里我们以下图 G G G 为例:
在这个非连通图中,它有两个联通分量:
- 连通分量
G
1
=
(
V
1
,
E
1
)
G_1 = (V_1, E_1)
G1=(V1,E1) :
- V 1 = { a , b , c , d } V_1 = \{a, b, c, d\} V1={a,b,c,d}
- E 1 = { ( a , b ) , ( b , c ) , ( c , d ) , ( d , a ) } E_1 = \{(a, b), (b, c), (c, d), (d, a)\} E1={(a,b),(b,c),(c,d),(d,a)}
- 连通分量
G
2
=
(
V
2
,
E
2
)
G_2 = (V_2, E_2)
G2=(V2,E2) :
- V 2 = { e } V_2 = \{e\} V2={e}
- E 2 = { ∅ } E_2 = \{\varnothing\} E2={∅}
其对应的生成森林为:
1.1.3 生成树、生成森林与连通分量
结点的关系
在无向图中,根据是否存在非连通的结点,我们可以将无向图分为两类:
- 连通图:无向图中所有的顶点都相互连通
- 非连通图:无向图中存在非连通的顶点
不管是连通图还是非连通图,它们都存在各自的连通分量:
- 连通图:连通图的连通分量只有一个,就是它本身
- 非连通图:非连通图的连通分量的数量与互不相交的最大连通子图数量相同
在连通图中,其子图能够以最少的边确保所有结点的连通性时,该子图就是连通图的最小连通子图,也称为生成树;
在非连通图中,每个连通分量的最小连通子图就构成了生成森林;
现在我们不难发现,最小连通子图,即生成树只存在于连通图中,而生成森林只存在于非连通图中。因此我们可以得到一个结论:
- 生成树的结点数量 = 连通图的顶点数量 = 连通图的连通分量的顶点数量
- 生成森林的结点数量 = 非连通图的顶点数量 = 非连通图的所有连通分量的顶点数量
在非连通图中,单棵生成树的顶点数量与该树对应的连通分量的顶点数量相等,但是不等于该非连通图的顶点数量。这个一定要谨记!!!
这个点比较绕,我们还是以图为例,更加直观的来理解;
这里有一个图 G = ( V , E ) G = (V, E) G=(V,E) ,其中:
- 顶点集 V = { a , b , c , d , e , f , g , h } V = \{a, b, c, d, e, f, g, h\} V={a,b,c,d,e,f,g,h}
- 边集 E = { ( a , b ) , ( a , c ) , ( a , d ) , ( b , c ) , ( c , d ) , ( e , f ) , ( f , g ) , ( g , e ) } E = \{(a, b), (a, c), (a, d), (b, c), (c, d), (e, f), (f, g), (g, e) \} E={(a,b),(a,c),(a,d),(b,c),(c,d),(e,f),(f,g),(g,e)}
图中存在3个连通分量:
- 连通分量
G
1
=
(
V
1
,
E
1
)
G_1 = (V_1, E_1)
G1=(V1,E1) :
- V 1 = { a , b , c , d } V_1 = \{a, b, c, d\} V1={a,b,c,d}
- E 1 = { ( a , b ) , ( a , c ) , ( a , d ) , ( b , c ) , ( c , d ) } E_1 = \{(a, b), (a, c), (a, d), (b, c), (c, d)\} E1={(a,b),(a,c),(a,d),(b,c),(c,d)}
该连通分量对应生成树为:
当然,该连通分量的生成树有很多课,这里我们只选取了其中一棵;
- 连通分量
G
2
=
(
V
2
,
E
2
)
G_2 = (V_2, E_2)
G2=(V2,E2) :
- V 2 = { e , f , g } V_2 = \{e, f, g\} V2={e,f,g}
- E 2 = { ( e , f ) , ( f , g ) , ( g , e ) } E_2 = \{(e, f), (f, g), (g, e)\} E2={(e,f),(f,g),(g,e)}
该连通分量对应生成树为:
当然,该连通分量的生成树有很多课,这里我们只选取了其中一棵;
- 连通分量
G
3
=
(
V
3
,
E
3
)
G_3 = (V_3, E_3)
G3=(V3,E3) :
- V 3 = { h } V_3 = \{h\} V3={h}
- E 3 = { ∅ } E_3 = \{\varnothing\} E3={∅}
该连通分量对应的生成树有且仅有一棵:
可以看到该非连通图中,每个连通分量所对应的生成树的结点数量都与该连通分量的顶点数量相同;
由这三棵树组成的生成森林为:
该生成森林的结点数量与该非连通图的顶点数量相同。
因此我们就可以得到非连通图的生成树、生成森林、连通分量与图的顶点数量之间的关系:
- 单棵生成树的结点数量 = 其连通分量的顶点数量 < 非连通图的顶点数量
- 生成森林的结点数量 = 非连通图的顶点数量 > 任一连通分量的顶点数量
由于在图中不存在空图的情况,对于非连通图来说,其顶点数量一定大于任一连通分量的顶点数量。
边的关系
生成树中边的数量是需要满足图连通性的最少数量,即,当顶点为 n n n 时,对应边的数量为 n − 1 n -1 n−1
生成森林中,每棵子树的边都满足生成树的条件,即,原图有 n n n 个顶点,有 m m m 棵生成树时,那么对应的边的数量则为 n − m n - m n−m;
在连通分量中,每个连通分量的边的数量都是当前图中保持连通的最大边的数量,即,当非连通图中有 n n n 条边,那么该图所对应的所有连通分量的边的数量之和为 n n n;
认识了无向图中的树与森林,接下来我们就来看一下有向图所对应的树与森林;
1.2 有向图中的树与森林
1.2.1 有向树与有向森林
在有向图中,也存在两个特有的概念:
- 有向树:有向树指的是一个顶点的入度为0,其余顶点的入度均为1的有向图。
- 有向森林:有向森林指的是由多个互不相交的有向树组成的集合。
需要注意的是这里的有向图不是特指的强连通图,而是任一有向图,并且在图中只要存在满足有向树的子图,就可以是一棵有向树,如下所示:
在这个有向图中,就存在多棵有向树,如:
当然,该图对应的有向树远不止这些,我们只是例举了这三棵树。其中只要是互不相交的有向树就能构成一个有向森林,而这例举的三棵树都不想交,因此它们就可以构成一个有向森林:
但是我们需要重点关注的是有向图中的生成有向树与生成有向森林:
1.2.2 生产有向树与生成有向森林
生成有向树:生成有向树指的是有向图中的所有顶点,存在一个顶点的入度为0、其余顶点的入度均为1且无环的子图;
生成有向森林:生成有向森林指的是有向图中互不相交的且包含原图所有顶点的生成有向树组成的集合;
在生成有向树中,有几个特点:
- 包含该有向图中的所有顶点
- 从根结点出发,可以到达原图中的任一结点
- 从根结点出发,到任一结点有且仅有一条路径
- 无环
在生成有向森林中,有几个特点:
- 所有的子树的顶点之和 = 原图中的顶点数量
- 每棵子树都是一棵生成有向树
- 每棵子树都不与其它任一子树相交
下面我们还是通过图示来理解:
还是这个有向图,它存在两个不相交的有向子图:
- 有向子图
G
1
=
(
V
1
,
E
1
)
G_1 = (V_1, E_1)
G1=(V1,E1)
- V 1 = { a , b , c , d } V_1 = \{a, b, c, d\} V1={a,b,c,d}
- E 1 = { < a , b > , < b , a > , < b , c > , < c , d > , < d , a > } E_1 = \{<a, b>, <b, a>, <b, c>, <c, d>, <d, a>\} E1={<a,b>,<b,a>,<b,c>,<c,d>,<d,a>}
其对应的生成子树为:
- 有向子图
G
2
=
(
V
2
,
E
2
)
G_2 = (V_2, E_2)
G2=(V2,E2)
- V 2 = { e } V_2 = \{e\} V2={e}
- E 2 = { ∅ } E_2 = \{\varnothing\} E2={∅}
其对应的生成子树为:
该有向图 G G G 对应的生成有向森林为:
在这个森林中有两棵子树,并且这两棵子树都是对应子图的生成有向树;
1.2.3 有向树与生成有向树的区别
在有向图中,有向树与生成有向树是有很多相同的点:
- 无环:两种有向树都满足无环的条件
- 连通:从根结点出发,都能通过有向边到达树中的其它任一结点
- 路径唯一:从根结点出发,到任一结点的路径存在且唯一
- 入度约束:根结点的入度为0,除根结点外,其余结点的入度均为1
但是这二者也有一些不同之处:
- 顶点数量不同
- 有向树中,并没有对顶点数量进行约束,即,只要是有向图中的子图且满足有向树的特性,就可以得到一棵有向树;
- 生成有向树中,对顶点数量进行了约束,必须包含原图中的所有顶点
- 连通性不同
- 有向树不要求原图中所有顶点都必须连通,即,原图中的单个顶点即可构成一棵有向树;
- 生成有向树则要求原图中必须存在一个根结点能够通过有向边访问到其他所有的结点;
根据有向树与生成有向树之间的差异,二者所组成的森林也同样存在差异:
1.2.4 有向森林与生成有向森林的区别
相同点
- 组成结构相同
- 有向森林:由多棵不相交的有向树组成
- 生成有向森林:由多棵不相交的生成有向树组成
有向森林与生成有向森林的其它相同点实际上就是有向树与生成有向树之间的相同点,这我就不再赘述;
不同点
- 顶点要求不同
- 有向森林:森林中的结点总数可以比原图的顶点总数少
- 生成有向森林:森林中的结点总数必须与原图的顶点总数相等
- 与原图关系不同
- 有向森林:森林中的子树只需要原图中的子图满足有向树的条件即可
- 生成有向森林:森林中的子树一定是对应有向图的生成有向树,且子树的数量与原图中互不相交的子图的数量相同
二、权
权值:权值指的是图中的每条边上标明的具有某种意义的数值;
带权图:带权图指的是图中的边上带有权值的图,也称为网;
带权路径长度:带权路径长度指的是路径上所有边的权值之和
在哈夫曼树中我们就接触了权值与带权路径长度的概念,现在我们又再一次与它们相遇了,这里我们直接通过图来进行说明:
在上图中每条边上都被赋予了一个值,这些值就是边的权值。
而像上图这样边上被赋予了权值的图就是带权图,也可以将其称为网
从结点a到结点d的路径有两条:
- 路径1: a − − > b − − > c − − > d a-->b-->c-->d a−−>b−−>c−−>d,该路径上的权值之和为 1 + 2 + 3 = 6 1 + 2 + 3 = 6 1+2+3=6
- 路径2: a − − > d a-->d a−−>d,该路径上的权值之和为 1 1 1
不管是路径1还是路径2,其路径上的权值之和就是该路径的带权路径长度。
三、特殊图
3.1 稀疏图与稠密图
稀疏图:稀疏图指的是边的数量很少的图;
稠密图:稠密图指的是边的数量很多的图;
稀疏图与稠密图时相对而言的,一般情况下,当图 G = ( V , E ) G = (V, E) G=(V,E) 满足 ∣ E ∣ < ∣ V ∣ l o g 2 ∣ V ∣ |E| < |V|log_2|V| ∣E∣<∣V∣log2∣V∣ 时,可以将图 G G G 视为稀疏图;反之,为稠密图。
稀疏图与稠密图的概念,我们仅做了解即可,不必过于深究,这里就不再展开。
3.2 完全图
完全图又称为简单完全图,因此我们不考虑多重图。
所谓的完全图,实际上指的是一个图中任意两个结点之间都相互邻接,即:
- 在有向图中,任意两个结点直接都存在两条弧 < a , b > <a, b> <a,b> 与 < b , a > <b, a> <b,a>
- 在无向图中,任意两个结点之间都存在一条边 ( a , b ) (a, b) (a,b)
我们可以通过边的数量来判断一个图是否为完全图,而对于有向图和无向图而言,其边的数量的判断是不一致的,下面我们就分别来看一下两种图中如何判断是否为完全图
3.2.1 无向完全图
对于无向图,边的取值范围 ∣ E ∣ ∈ [ 0 , n ( n − 1 ) 2 ] |E| \in [0, \frac{n(n-1)}2] ∣E∣∈[0,2n(n−1)] ,当无向图的边的数量为 n ( n − 1 ) 2 \frac{n(n-1)}2 2n(n−1) 时,则该无向图称为无向完全图:
上图中,边的数量满足 ∣ E ∣ = 3 × ( 3 − 1 ) 2 = 3 |E| = \frac{3 × (3 - 1)}{2} = 3 ∣E∣=23×(3−1)=3这就是一个无向完全图。
在上图中,边的数量 ∣ E ∣ = 4 < 4 × ( 4 − 1 ) 2 = 6 |E| = 4 < \frac{4 × (4 - 1)}{2} = 6 ∣E∣=4<24×(4−1)=6 因此这不是一个完全图。
3.2.2 有向完全图
在有向图中,边的取值范围 ∣ E ∣ ∈ [ 0 , n ( n − 1 ) ] |E| \in [0, n(n-1)] ∣E∣∈[0,n(n−1)] ,当无向图的边的数量为 n ( n − 1 ) n(n-1) n(n−1) 时,则该有图称为有向完全图:
上图中,边的数量满足 ∣ E ∣ = 2 × ( 2 − 1 ) = 2 |E| = 2 × (2 - 1) = 2 ∣E∣=2×(2−1)=2这就是一个有向完全图。
在上图中,边的数量 ∣ E ∣ = 3 < 3 × ( 3 − 1 ) = 6 |E| = 3 < 3 × (3 - 1) = 6 ∣E∣=3<3×(3−1)=6 因此这不是一个完全图。
结语
从生成树的边数公式到有向森林的分解逻辑,本文深入剖析了图论中树形结构的核心原理。
这些知识是学习图算法(如Kruskal、Prim)的必经之路,更为社交网络层级分析、交通拓扑优化提供理论支撑。
如果本文助您理清知识脉络:
✅ 点击关注,追踪后续《图的存储及基本操作》深度解析
✅ 点赞支持,鼓励更多原创技术内容
✅ 收藏备用,构建算法知识体系
✅ 转发分享,与同行共探图论奥秘
下期剧透:邻接矩阵如何用二维数组高效描述图结构?稠密图存储的时空代价如何权衡?我们将在下一篇揭晓答案!您的每一次互动,都是我们打磨精品的动力源泉!🔥




![[ICLR 2025]Biologically Plausible Brain Graph Transformer](https://i-blog.csdnimg.cn/direct/0a5fd0c5509a47d1a980a2b2d0453c66.png)



![STM32单片机入门学习——第13节: [6-1] TIM定时中断](https://i-blog.csdnimg.cn/direct/f5783eecb6be4d7e8b448cd4312d3be7.png)