A3C算法(Asynchronous Advantage Actor-Critic)
DDPG算法之后,DeepMind对其改造,提出了效果更好的 Asynchronous Advantage Actor-Critic(A3C)算法(论文是 Asynchronous Methods for Deep Reinforcement Learning )。A3C 算法和DDPG类似,通过深度神经网络拟合 policy function 和 value function的估计。改进点在于:
- ① A3C 中有多个 agent 对网络进行异步更新,这样的做法使得样本间的相关性较低,A3C中也无需采用Experience Replay的机制,且支持在线的训练模式。
- ② A3C 有两个输出,其中一个 Softmax output 作为 policy
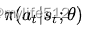 ,而另一个linear output为 value function
,而另一个linear output为 value function  。
。 - ③ A3C 中的Policy network 的评估指标采用的是上面比较了多种评估指标的论文中提到的 Advantage Function(即A值) 而不是 DDPG 中单纯的 Q 值。
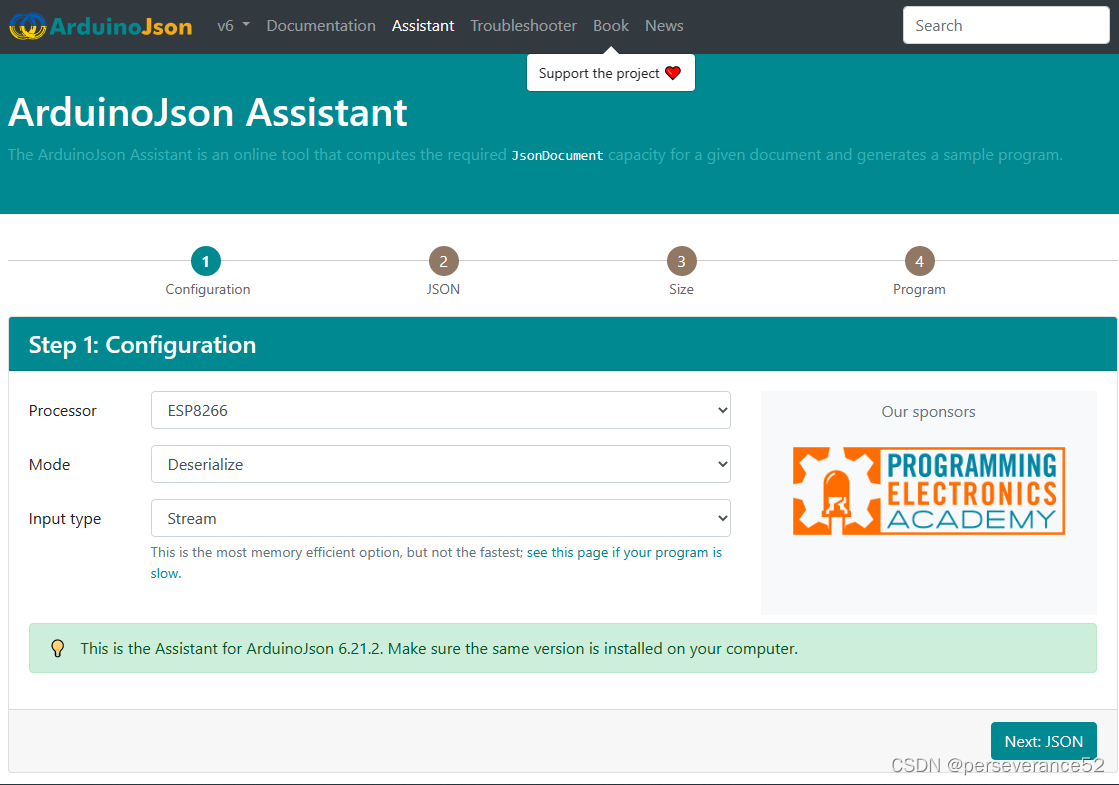
下图展示了其网络结构:

从上图可以看出输出包含2个部分,value network 的部分可以用来作为连续动作值的输出,而 policy network 可以作为离散动作值的概率输出,因此能够同时解决前面提到的2类问题。
两个网络的更新公式如下:

A3C 通过创建多个 agent,在多个环境实例中并行且异步的执行和学习,有个潜在的好处是不那么依赖于 GPU 或大型分布式系统,实际上 A3C 可以跑在一个多核 CPU 上,而工程上的设计和优化也是原始paper的一个重点。