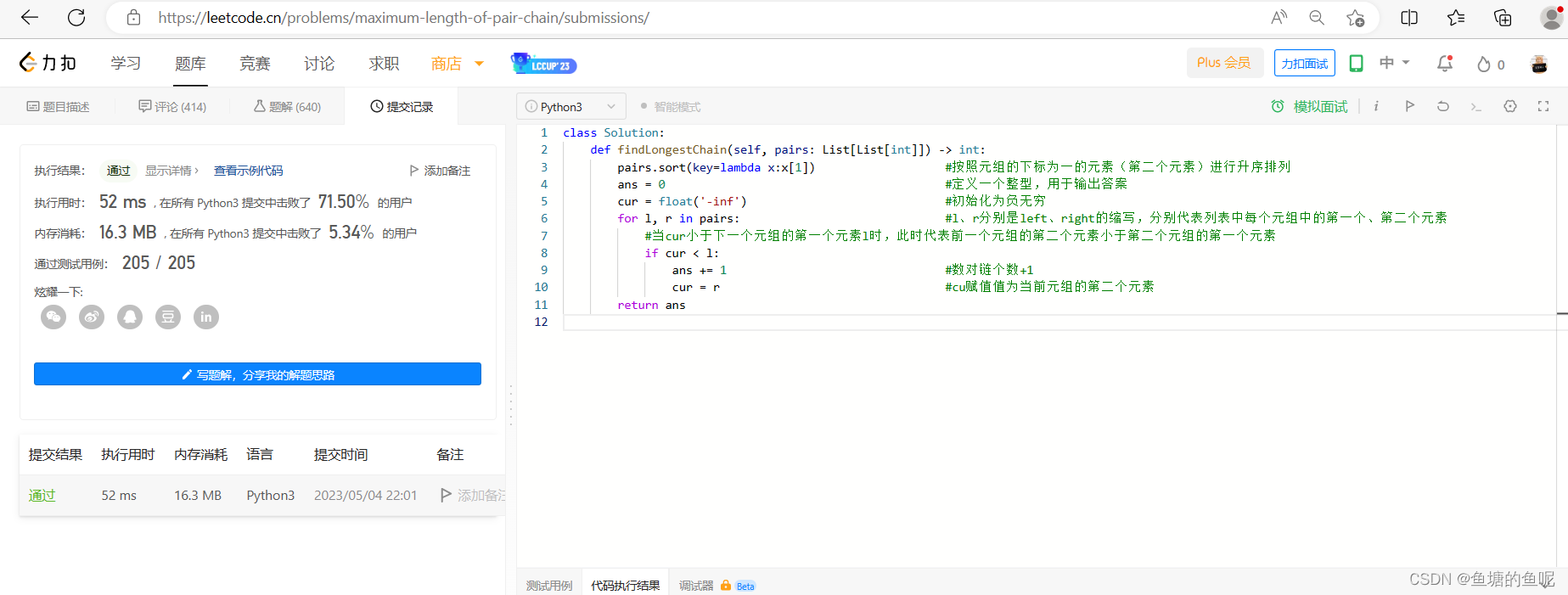
今天分享的基本上一面试就会被问的网络IO。文中涉及的代码部分不太重要,重要的是对这概念的理解。在看文章之前大家也可通过下面的思维导图看看自己是否能回答出来。

大纲
1 阻塞与非阻塞--开胃菜
-
阻塞
我们知道在调用某个函数的时候无非就是两种情况,要么马上返回,然后根据返回值进行接下来的业务处理。当在使用阻塞IO的时候,应用程序会被无情的挂起,等待内核完成操作,因为此时的内核可能将CPU时间切换到了其他需要的进程中,在我们的应用程序看来感觉被卡主(阻塞)了。
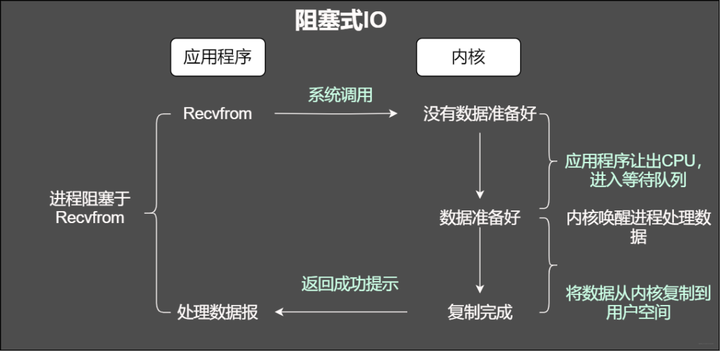
阻塞IO
传统阻塞IO模型

传统阻塞IO模型
特点:
-
通过阻塞式IO获取输入的数据
-
其中每个连接都采用独立的线程完成数据输入,业务处理以及数据返回的操作
这种方案有什么问题?
首先当并发较大的时候,需要创建大量的线程来处理连接,需要占用大量的系统资源。
连接建立完成以后,如果当前线程没有数据可读,将会阻塞在read操作上造成线程资源的浪费
鉴于上面的两个问题,通常是解决方案是啥呢?
第一种是采用IO复用的模型,所谓IO复用模型即多个连接共享一个阻塞对象,应用程序只会在一个阻塞对象上等待。当某个连接有新的数据处理,操作系统直接通知应用程序,线程从阻塞状态返回并开始业务处理
第二种方案即采用线程池复用的方式。将连接完成后的业务处理任务分配给线程,一个线程处理多个连接的业务。IO复用结合线程池的方案即Reactor模式。
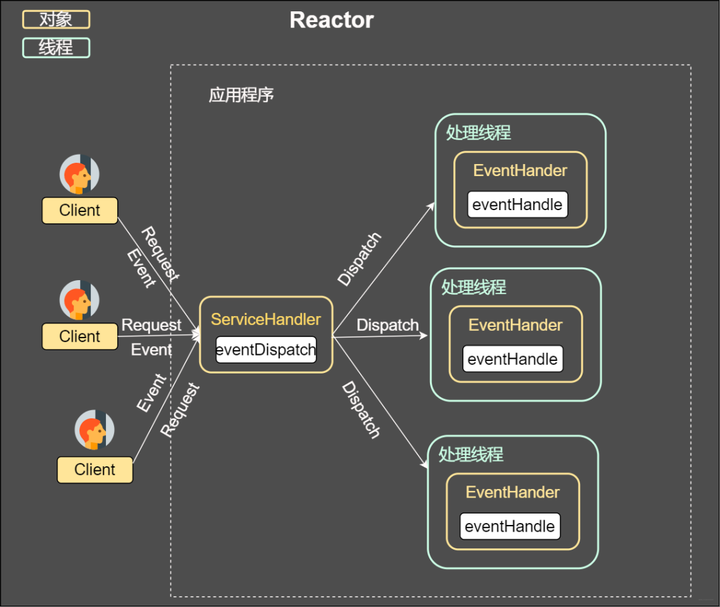
Reactor
从上图我们可以发现,通过一个或者多个请求传递给服务器,通过统一的事件管理机制进行请求分发,这种模式即事件驱动处理模式。
通常一个服务端处理网络请求的过程是啥样的?
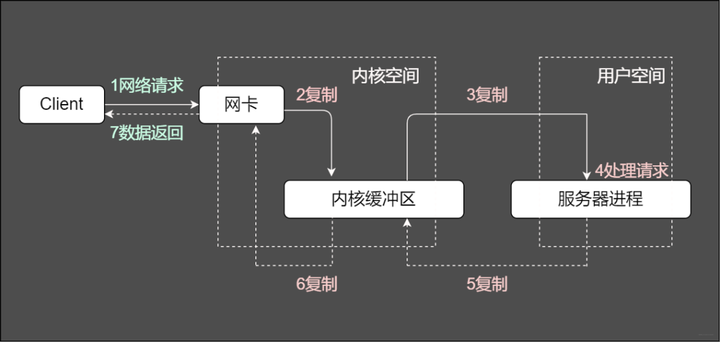
服务端处理请求的常规过程
服务端将这些请求分别同步分派给多个处理线程,即IO多路复用统一监听事件,收到事件再进行分发。那么图中重要的两个关键字是啥意思?
相关视频推荐
6种epoll的设计方法(单线程epoll、多线程epoll、多进程epoll)及每种epoll的应用场景
手把手写一次reactor,为你的web服务器增加技术点
8个方面讲解io_uring,重塑对异步io的理解
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

Reactor
在一个单独的线程运行,主要负责监听和分发事件。就仿佛我们手机设置的转接,将来自前任的电话转接给适当的联系人
Handlers
主要负责处理执行IO实际的事情。
根据Reactor的数量和处理的资源大小通常又分为单Reactor线程,单Reactor多线程,主从Reactor多线程。这部分将在文章后面进行详细阐述,先和大家一起复习几个基本概念
-
非阻塞
当使用非阻塞函数的时候,和阻塞IO类比,内核会立即返回,返回后获得足够的CPU时间继续做其他的事情。
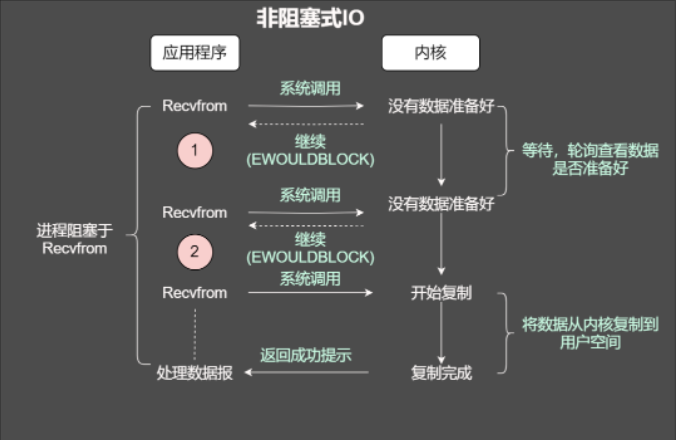
非阻塞
这样说可能有点不太好理解,试试一个例子来
小蓝经常去楼下的小卖部买烟,因为那小姐姐确实好看,即使不买去看看也饱了那种。有一天去买烟,让我等下,他去仓库看看,就一直在那里等着小姐姐回复,就仿佛阻塞在了小姐姐的店。
那么阻塞IO是个啥样子嘞?
小姐姐,今天有黄鹤楼烟没,小姐姐看看了柜台,没有,到处找也没有了,然后告诉我这周没有了,下周应该会有货,好嘛,我寂寞的小手颤抖了,其实我就是想去小姐姐家买东西,于是下周我又去问小姐姐,小姐姐果然有心,就知道我回去她家店买,直接给我留了两包黄鹤楼,就这样反反复复,和小姐姐的感情越来越好,这样就是阻塞IO的轮询,我没有被阻塞而是不断地咨询小姐姐(轮询)。
抽烟的人,经常一句话就是“这一根抽了就不抽了”,怎么能忍住一周?看来轮询效率太低,直接给小姐姐打电话:“小姐姐,烟到了麻烦通知一声,我来你家拿”,这就是IO多路复用。
感情嘛,最激烈的时期不外乎是最开始的那么两个月,不,渣男,怎么可能就两个月,感情真是越来越好,然后我就给小姐姐说:“小姐姐,我给你个地址,还有微信,到时候到货了麻烦给我寄过来”,这尼玛,不仅加了微信,还给我送到了家,这就是异步IO,至于后续的故事是怎么样的想知道?
好勒,就是写IO模型,配上线程/进程所向披靡(网络编程的核心)
非阻塞IO之读(继续查阅资料)
咱们知道套接字有个缓冲区,如果缓冲区没有数据可读,那么在非阻塞的情况下调用read就会立即返回,返回自然会有个状态,不然我们一脸懵逼,无法进行下一步。返回可能是EWOULDBLOCK或者EAGAIN出错信息。
非阻塞IO之写
刚才我们说了,有个叫做缓冲区的概念,当然也有发送缓冲区,如果发送缓冲区满了,不能容纳更多的字节,这个时候操作系统内核就会尽全力从应用程序拷贝数据到发送缓冲区并立即从write调用返回。在拷贝的过程中,可能全部拷贝了,也可能一字节也没拷贝,所以使用返回值来告诉应用程序到底有多少数据拷贝到了发送发送缓冲区,方便再次调用write,输出未完成的字节。
总结下两种方式:
阻塞IO是:拷贝-知道所有数据拷贝到发送缓冲区。
非阻塞IO是拷贝-返回-再拷贝-再返回。ok,read和write的骚操作如下图

读写阻塞不同点
说了这么多,当面试官问你的时候,能不能对答如流嘞,总结如下:
-
read总是在接受缓存区有数据的时候直接返回,而不是等到应用程序哥顶的数据充满才返回。如果此时缓冲区是空的,那么阻塞模式会等待,非阻塞则会返回-1并有EWOULDBLOCK或EAGAIN错误
-
和read不太一样的是,在阻塞模式下,write只有在发送缓冲区足矣容纳应用程序的输出字节时才会返回。在非阻塞的模式下,能写入多少则写入多少,并返回实际写入的字节数
当使用fgets等待标准输入的时候,如果此时套接字有数据但不能读出。IO多路复用意味着可以将标准输入、套接字等都当做IO的一路,任何一路IO有事件发生,都将通知相应的应用程序去处理相应的IO事件,在我们看来就反复同时可以处理多个事情。这就是IO复用。

IO复用
2 select
当使用select函数的时候,先通知内核挂起进程,一旦一个或者多个IO事情发生,控制权将返回给应用程序,然后由应用程序进行IO处理。
那么IO事件都包含哪些
-
标准输入文件描述符可以读
-
已连接套接字准备好可以写
-
如果一个IO事件等待超过10秒,发生超时
select使用方法
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);-
maxfdp 表示待测试描述符基数,它的值为待测试最大描述符加1.假设当前的select的测试描述符集合为{0,1,3},那么这个时候maxfd为4,
-
随后为三个描述符集合,分别为读集合readset,写集合writeset和异常集合exceptset。它们会通知内核,当有可读可写发生的时候记得通知它们
如何设置这些描述符
int FD_ZERO(int fd, fd_set *fdset); //一个 fd_set类型变量的所有位都设为 0
int FD_CLR(int fd, fd_set *fdset); //清除某个位时可以使用
int FD_SET(int fd, fd_set *fd_set); //设置变量的某个位置位
int FD_ISSET(int fd, fd_set *fdset); //测试某个位是否被置位最后一个参数是时间
struct timeval
{
long tv_sec; /*秒 */
long tv_usec; /*微秒 */
};
-
设置为NULL,select会一直等待下去
-
设置非零值,等待固定时间后返回
-
将tv_sec和tv_usec均设置为0,表示不等待,检测完毕就返回
程序案例
#include <stdio.h>
#include <string.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/select.h>
const static int MAXLINE = 1024;
const static int SERV_PORT = 10001;
int main()
{
int i , maxi , maxfd, listenfd , connfd , sockfd ;
/*nready 描述字的数量*/
int nready ,client[FD_SETSIZE];
int n ;
/*创建描述字集合,由于select函数会把未有事件发生的描述字清零,所以我们设置两个集合*/
fd_set rset , allset;
char buf[MAXLINE];
socklen_t clilen;
struct sockaddr_in cliaddr , servaddr;
/*创建socket*/
listenfd = socket(AF_INET , SOCK_STREAM , 0);
/*定义sockaddr_in*/
memset(&servaddr , 0 ,sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(SERV_PORT);
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(listenfd, (struct sockaddr *) & servaddr , sizeof(servaddr));
listen(listenfd , 100);
/*listenfd 是第一个描述字*/
/*最大的描述字,用于select函数的第一个参数*/
maxfd = listenfd;
/*client的数量,用于轮询*/
maxi = -1;
/*init*/
for(i=0 ;i<FD_SETSIZE ; i++)
client[i] = -1;
FD_ZERO(&allset);
FD_SET(listenfd, &allset);
for (;;)
{
rset = allset;
/*只select出用于读的描述字,阻塞无timeout*/
nready = select(maxfd+1 , &rset , NULL , NULL , NULL);
if(FD_ISSET(listenfd,&rset))
{
clilen = sizeof(cliaddr);
connfd = accept(listenfd , (struct sockaddr *) & cliaddr , &clilen);
/*寻找第一个能放置新的描述字的位置*/
for (i=0;i<FD_SETSIZE;i++)
{
if(client[i]<0)
{
client[i] = connfd;
break;
}
}
/*找不到,说明client已经满了*/
if(i==FD_SETSIZE)
{
printf("Too many clients , over stack .\n");
return -1;
}
FD_SET(connfd,&allset);//设置fd
/*更新相关参数*/
if(connfd > maxfd) maxfd = connfd;
if(i>maxi) maxi = i;
if(nready<=1) continue;
else nready --;
}
for(i=0 ; i<=maxi ; i++)
{
if (client[i]<0) continue;
sockfd = client[i];
if(FD_ISSET(sockfd,&rset))
{
n = read(sockfd , buf , MAXLINE);
if (n==0)
{
/*当对方关闭的时候,server关闭描述字,并将set的sockfd清空*/
close(sockfd);
FD_CLR(sockfd,&allset);
client[i] = -1;
}
else
{
buf[n]='\0';
printf("Socket %d said : %s\n",sockfd,buf);
write(sockfd,buf,n); //Write back to client
}
nready --;
if(nready<=0) break;
}
}
}
return 0;
}但是他有个比较明显的特点就是所支持文件描述符有限,默认为1024个,随机出现poll
3 poll
鉴于select所支持的描述符有限,随后提出poll解决这个问题
还是先看声明
int poll(struct pollfd *fds, nfds_t nfds, int timeout);再看pollfd结构
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 描述符待检测的事件 */
short revents; /* returned events */
};注意下这个结构体,分别包含了文件描述符和描述符对应的事件,这事件和文件描述符紧密相结合,其中事件使用二进制掩码表示,如POLLIN代表读事件,POLLOUT代表写事件。
#define POLLIN 0x0001 /* any readable data available */
#define POLLPRI 0x0002 /* OOB/Urgent readable data */
#define POLLOUT 0x0004 /* file descriptor is writeable */从结构中可以看见还有个参数是revents,从字面意思可知事件备份。对的,相当于将poll每次检测的结果保留在revents,这样就不需要每次都重置描述符和事件。那到底有哪些事件
-
可读事件---系统内核会通知应用程序数据可读
#define POLLIN 0x0001 /* any readable data available */
#define POLLPRI 0x0002 /* OOB/Urgent readable data */
#define POLLRDNORM 0x0040 /* non-OOB/URG data available */
#define POLLRDBAND 0x0080 /* OOB/Urgent readable data */-
可写事件---系统内核会通知套接字缓冲区已经可以安排,随后使用write函数不会被堵塞
#define POLLOUT 0x0004 /* file descriptor is writeable */
#define POLLWRNORM POLLOUT /* no write type differentiation */
#define POLLWRBAND 0x0100 /* OOB/Urgent data can be written */了解函数返回值
-
小于0----表示事件发生前永远等待
-
-1---发生错误
-
0--在指定的而时间没有任何事件发生
poll和select不同之处在于,在select中,文件描述符个数随着fd_set的实现而固定,而在poll函数中,我们可以通过控制pollfd数组的大小来改变描述符的个数
案例
#include <stdio.h>
#include <string.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <poll.h>
#define INFTIM -1
#define POLLRDNORM 0x040 /* Normal data may be read. */
#define POLLRDBAND 0x080 /* Priority data may be read. */
#define POLLWRNORM 0x100 /* Writing now will not block. */
#define POLLWRBAND 0x200 /* Priority data may be written. */
#define MAXLINE 1024
#define OPEN_MAX 16 //一些系统会定义这些宏
#define SERV_PORT 10001
int main()
{
int i , maxi ,listenfd , connfd , sockfd ;
int nready;
int n;
char buf[MAXLINE];
socklen_t clilen;
struct pollfd client[OPEN_MAX];
struct sockaddr_in cliaddr , servaddr;
listenfd = socket(AF_INET , SOCK_STREAM , 0);
memset(&servaddr,0,sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(SERV_PORT);
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(listenfd , (struct sockaddr *) & servaddr, sizeof(servaddr));
listen(listenfd,10);
client[0].fd = listenfd;
client[0].events = POLLRDNORM;
for(i=1;i<OPEN_MAX;i++)
{
client[i].fd = -1;
}
maxi = 0;
for(;;)
{
nready = poll(client,maxi+1,INFTIM);
if (client[0].revents & POLLRDNORM)
{
clilen = sizeof(cliaddr);
connfd = accept(listenfd , (struct sockaddr *)&cliaddr, &clilen);
for(i=1;i<OPEN_MAX;i++)
{
if(client[i].fd<0)
{
client[i].fd = connfd;
client[i].events = POLLRDNORM;
break;
}
}
if(i==OPEN_MAX)
{
printf("too many clients! \n");
}
if(i>maxi) maxi = i;
nready--;
if(nready<=0) continue;
}
for(i=1;i<=maxi;i++)
{
if(client[i].fd<0) continue;
sockfd = client[i].fd;
if(client[i].revents & (POLLRDNORM|POLLERR))
{
n = read(client[i].fd,buf,MAXLINE);
if(n<=0)
{
close(client[i].fd);
client[i].fd = -1;
}
else
{
buf[n]='\0';
printf("Socket %d said : %s\n",sockfd,buf);
write(sockfd,buf,n); //Write back to client
}
nready--;
if(nready<=0) break; //no more readable descriptors
}
}
}
return 0;
}5 epoll
epoll 通过监控注册的多个描述字,来进行 I/O 事件的分发处理。不同于 poll 的是,epoll 不仅提供了默认的 level-triggered(条件触发)机制,还提供了性能更为强劲的edge triggered(边缘触发)机制
在The Linux Programming Interface有张图展示三种IO复用技术在面对不同文件描述符时的差异

The Linux Programming Interface
从上图咱们知道即使10000个描述符的时候,常规的select和poll性能下降明显,而epoll变化不大
那么epoll是什么操作这么6?
epoll通过监控注册多个描述字进行IO事件的分发。不同poll的是,epoll不仅提供默认的level-trigger机制还提供了边缘触发机制,这里可以先思考下两者有什么区别
编程三步骤
int epoll_create(int size);就是通过它来创造实例,这个返回的值将用于后续的技能解锁,如果不需要了这个实例,则需要使用close方法来释放示例,不要占着坑不拉屎,这样很不道德。
那这个size是干撒子的嘞?它告诉内核期望监控多少个描述符,然后使用这部分的信息来初始化内核底层的数据结构,不过时代在变化,在现在高版本的实现中,不在需要这个参数,自动动态化了,高级了吧。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);创建了实例,并有了返回值来标识这个示例,是时候添加事件了,此时就是使用epoll_ctl。第一个参数epfd即是上面的返回值。第二个参数表示是准备删除事件还是监控事件,哪都有哪些选项呢

三个事件
第三个参数为注册事件的文件描述符比如一个监听字
第四个参数表示注册的事件类型,可以在这个结构体中自定义数据。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
//返回值: 成功返回的是一个大于 0 的数,表示事件的个数;返回 0 表示的是超时时间到;若出错返回 -1
epoll_wait函数和之前的select等类似,等待内核IO事件的分发。第一个参数为create返回值句柄。第二个参数回给用户空间需要处理的 I/O 事件。第三个参数为一个大于0的整数,表示epoll_wait可以返回的最大事件值。第四个参数是epoll_wait阻塞时的超时值,如果设置为-1表示不超时,如果设置为0则立即返回。
6 epoll的底层实现
这部分内容,我在之前的文章中提过且给大家分享过一篇源码笔记,大家需要的话也可以微信找我拿。
-
当我们使用epoll_fd增加一个fd的时候,内核会为我们创建一个epitem实例,讲这个实例作为红黑树的节点,此时你就可以BB一些红黑树的性质,当然你如果遇到让你手撕红黑树的大哥,在最后的提问环节就让他写写吧
-
随后查找的每一个fd是否有事件发生就是通过红黑树的epitem来操作
-
epoll维护一个链表来记录就绪事件,内核会当每个文件有事件发生的时候将自己登记到这个就绪列表,然后通过内核自身的文件file-eventpoll之间的回调和唤醒机制,减少对内核描述字的遍历,大俗事件通知和检测的效率
7 C10K问题
这里的C代表并发,10K=10000。虽然现在通过现成的框架libevent/Netty可以轻松完成这个目标,但是在二十多年前,突破这个并发量还是非常困难的。那么要同时支撑这么多用户,需要从哪些方面考虑呢
-
文件句柄
我们知道每个连接代表一个文件描述符,如果不够用,新的链接将会被丢弃并产生错误
连接数过多
在Linux中默认为1024,但是如果你是root,你可以通过/etc/sysctl.cong来修改,使得支持1w个描述符

文件句柄
-
系统内存
每个连接不是只占用链接套接字那么简单,每个链接都需要占用发送缓冲区和接收缓冲区,不信我们看看
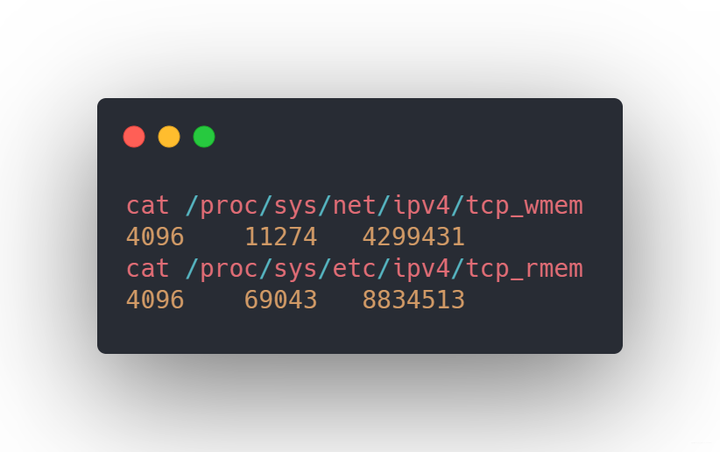
系统内存
上面三个值分别代表的是最小分配值、默认分配至和最大分配至,这样如果1w个连接需要消耗
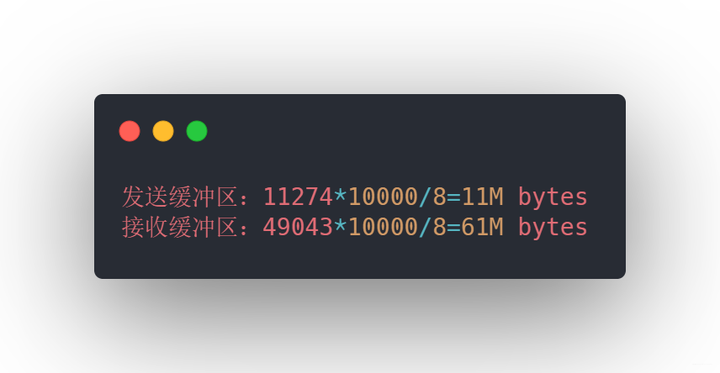
发送接收缓冲区
此时假设一个连接需要128K缓冲区,那么 1w 个连接大约需要 1.2G 应用层缓冲,所以支持w的连接不是内存的问题。
-
网络带宽
假设当前10个连接,其中每个链接传输大约1KB的数据,那么带宽需要10 * 10000 * 1KB/s * 8=80MBPS。在现在看来也是很一般了
那么如何解决C10K问题?
-
一方面需要考虑到IO,也就是上面说的阻塞IO和非阻塞IO
-
如何分配进程,线程的资源服务上w的连接
阻塞IO与进程
这个好理解,来个连接我就分配个进程(fork)去处理,这个进程处理此链接的所有IO,不管是阻塞还是非阻塞IO,多个连接也不会产生影响,毕竟进程之间有着各自的进程空间
进程是程序执行的最小单位,一个进程有着完整的地址空间,程序计数器,想要创建一个进程,使用fork即可,fork后会在父子进程中各返回一次,如果返回值为0则是子进程,随后父子进程处理各自的逻辑

fork
创建完进程执行了任务,当要离开的时候需要清理干净资源,如果退出了还将进程的相关信息留下,不回收就会变为僵尸进程。这些僵尸进程不是没人管了,会交给一个叫做 init 的进程,如果僵尸进程太多,势必会占用太多的内存空间甚至耗尽我们的系统资源。
那如果想主动的回收这些资源,怎么办呢?
处理子进程退出一般是注册一个信号处理函数,然后捕捉信号SIGCHILD信号,在信号处理函数中调用waitpid函数完成资源的回收即可。
假设此时服务端开始监听,两个客户端AB分别连接服务端,客户端A发起请求后,连接成立返回新的套接字叫做连接套接字,此时父进程派生子进程,在子进程中使用连接套接字和客户端通信,所以这个时候子进程不关心监听套接字。父进程则相反,服务交给子进程后,不再关心连接套接字,而是关心监听套接字,如下图所示

客户端A发起连接
缺点:效率不高,扩展性较差且资源占用率高
此时客户端B发来新的请求,accept返回新的已连接套接字,父进程又派生子进程
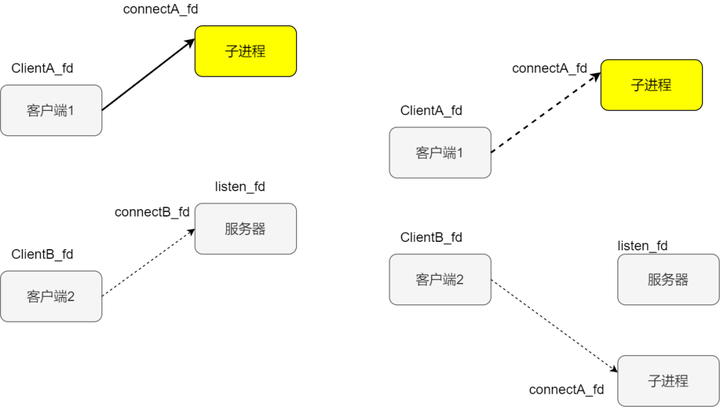
客户端B发起请求
部分实现
while (1)
{
if ((conn = accept(listenfd, (struct sockaddr *)&peeraddr, &peerlen)) < 0) //3次握手完成的序列
ERR_EXIT("accept error");
printf("recv connect ip=%s port=%d\n", inet_ntoa(peeraddr.sin_addr),
ntohs(peeraddr.sin_port));
pid = fork();
if (pid == -1)
ERR_EXIT("fork error");
if (pid == 0)
{
// 子进程
close(listenfd);
do_service(conn);
exit(EXIT_SUCCESS);
}
else
close(conn); //父进程
}缺点:效率不高,扩展性较差且资源占用率高,注意事项
-
对套接字的关闭
-
子进程的回收
阻塞IO+线程
刚才不是说进程占用资源多么,那么就是用线程呗。单进程中可以有多个线程,每个线程都有自己的上下文,包括唯一标识的线程ID 程序计数器等,同一个进程的多个线程共享整个虚拟地址空间,其中包含了代码、数据、堆。
为什么线程的上下文的开销比进程少呢
我们的代码是交给CPU执行的,程序计数器会告诉CPU代码执行到哪儿了,寄存器呢会存储当前计算的中间值,内存存放当前使用的变量,当切换到另外的计算场景的时候,需要重新载入新的值,这个时候就出现了上下文的切换
现在每个连接由一个线程处理
do{
accept connections
pthread_create for conneced connection fd
thread_run(fd)
}while(true)主线程负责监听连接请求
while (1)
{
//服务一直在运行,直到被某个操作或命令终止该进程
int recvbytes;
socklen_t length = sizeof(cliaddr);
//accept()函数让服务器接收客户的连接请求
int clientfd = accept(servfd,(struct sockaddr*)&cliaddr,&length);
if (clientfd < 0)
{
printf("error comes when call accept!\n");
break;
}
// 创建用于处理新连接的子线程
pthread_t recv_id ;
pthread_create(&recv_id, NULL, recv_msg_from_client, &clientfd);
}每个客户连接的线程函数
void* recv_msg_from_client(void* arg)
{
// 分离线程,使主线程不必等待此线程
pthread_detach(pthread_self());
int clientfd = *(int*)arg;
int recvBytes = 0;
char* recvBuf = new char[BUFFER_SIZE];
memset(recvBuf, 0, BUFFER_SIZE);
while(1)
{
if ((recvBytes=recv(clientfd, recvBuf, BUFFER_SIZE,0)) <= 0)
{
perror("recv出错!\n");
return NULL;
}
recvBuf[recvBytes]='\0';
printf("recvBuf:%s\n", recvBuf);
}
close(clientfd);
return NULL;
}可是频繁的创建线程也还是比较耗资源,这样子是不是可以使用线程池提前创建一波线程,多个连接复用它即可

线程池
上面程序虽然可以较好地处理连接,但是如果并发较多,就会引起线程的频繁切换和销毁,怎们优化?
我们在服务端启动的时候,预先分配固定大小的多个线程,当新连接建立的时候,从连接队列中取出这个连接描述字进程处理

主线程与工作线程
细心地同学可能发现,既要从队列取数据,也会从队列写数据,会不会有混乱。是的,所以通常还会使用mutex和条件变量进行加持。
但是不是每个链接都是需要时刻服务,每次创建线程还是比较消耗资源,那就提前创建一批线程,所谓线程池,复用线程池来获取某种效率的提升

线程池
非阻塞 I/O + readiness notification + 单线程
我们的程序可以通过轮询的方式对套接字进行挨个访问,从而找出进行IO处理的套接字。

描述符少还行,如果太多,每次的循环将消耗大量的CPU时间,而且可能循环完了都没发现一个套接字可以读写。既然这样,我们直接交给操作系统,让它告诉我们哪些套接字可以读写。程序就变为这样
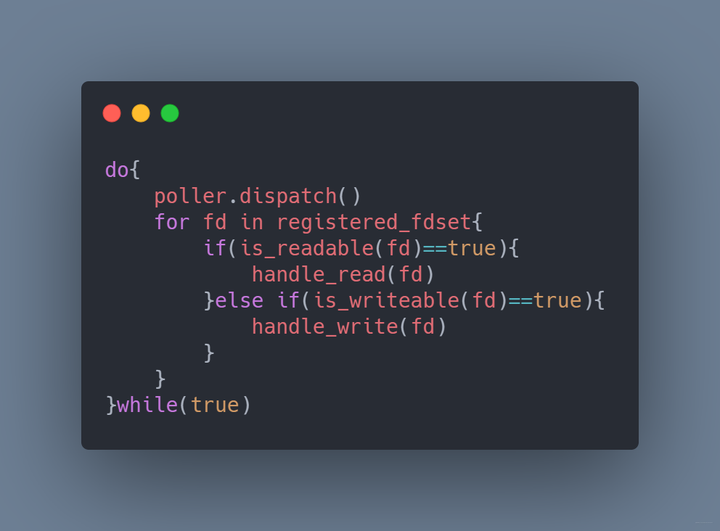
poll
我们每次dispatch就相当于对所有的套接字进行排查,这样显然效率不是很高。如果dispatch之后只提供有IO事件或者IO变化的套接字就好了,这就是epoll的设计
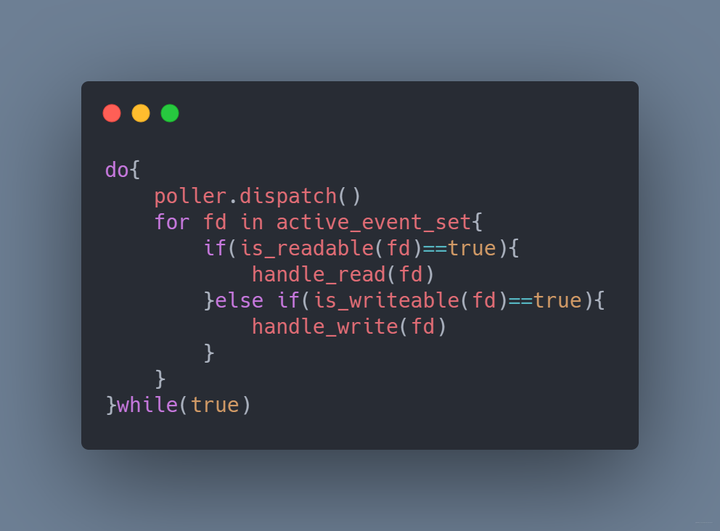
epoll
非阻塞 I/O + readiness notification + 多线程
上述几种方案都是在一个线程分发,显然没有利用当今的多核技术,我们完全可以让每个核作为一个IO分发器进行事件的分发,这其实就是reactor模式,也是后续将谈到的事件驱动。
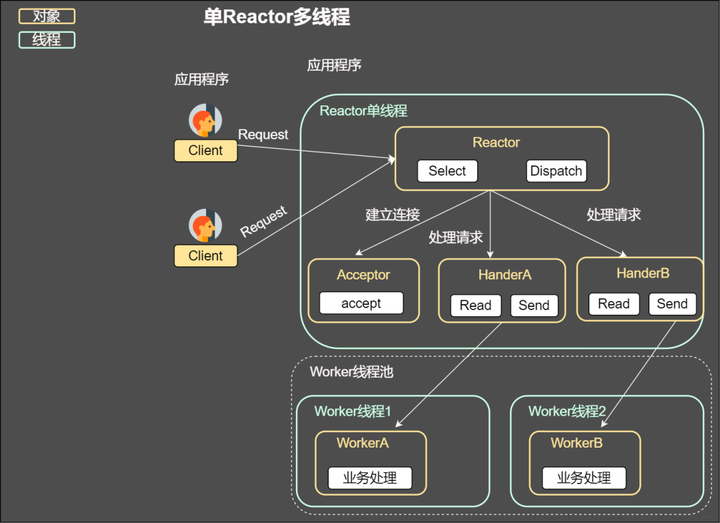
单reactor多线程
8 事件驱动
事件驱动也叫做反应堆模型或者Event loop模型,重要的是两点
-
通过poll、epoll等IO分发技术实现一个无限循环的事件分发线程
-
将所有的IO事件抽象为事件,每个事件设置回调函数
在处理大部分网络程序的时候,无外乎处理一下几个事儿
-
从套接字读取数据
-
对收到的数据进行解析
-
根据解析的内容进行计算处理
-
处理后的结果按照约定的格式编码
-
通过套接字发送出去
那么之前我们说了使用fork子进程的方式实现通信,随着客户端的增多,处理效率不高,因为fork的开销太大
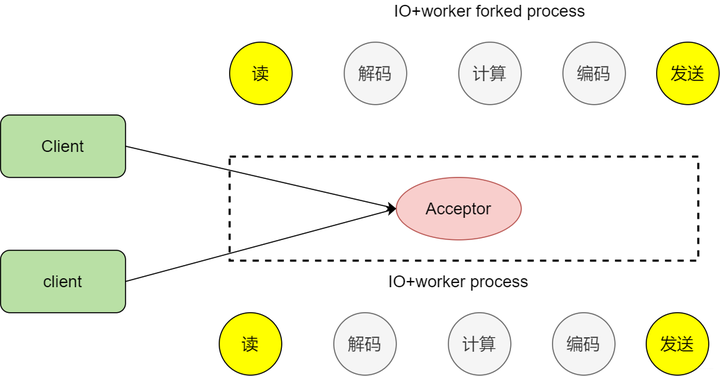
fork
为什么说事件驱动是一种高性能,高并发的模式?
既然这么牛皮,当然有它的特点。举个例子,来成都一个月,印象特别深刻却是到处都是咖啡馆,点一杯咖啡坐着一边喝一边看妹子,服务员小姐姐也不会找我,只有当我去续杯的时候,再找小姐姐勾搭(触发事件了),小姐姐满足了我的需求,我就接着边喝咖啡边看其他小姐姐,这就是事件驱动。看个图
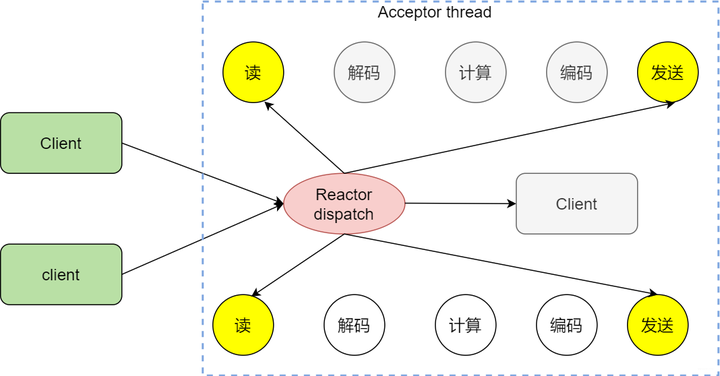
事件驱动
为了模式整体的效率,不能因为处理业务逻辑导致IO事件处理的效率下降,所以我们决定将注入XML文件的解析,数据库的查找等工作放在其他线程中,所谓将这些工作和反应堆线程解耦。让这个反应堆只处理IO相关任务,业务逻辑这些操作分成小任务放在线程池中让其他空闲的线程处理。处理完后再交给反应堆,然后发送出去
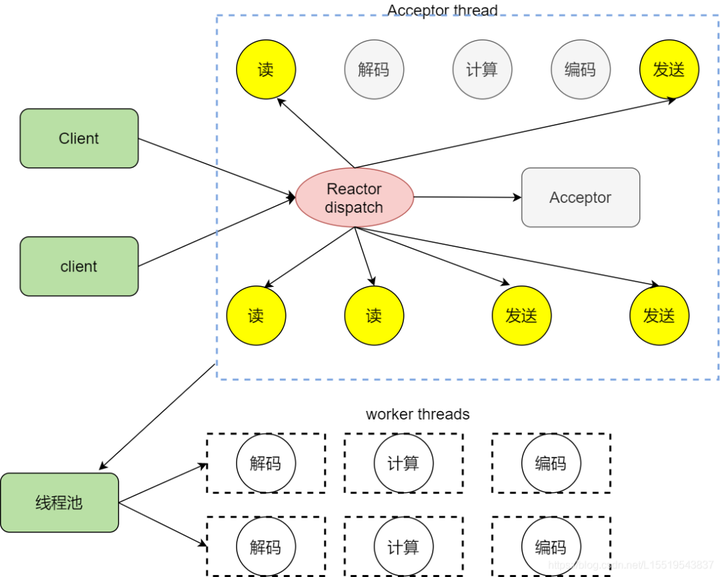
拆分业务逻辑
主从Reactor
ok,咱们已经知道使用Reactor反应堆的方式同时分发Acceptor上的连接建立事件,但是我们还是没有完全实现解耦,这个Reactor线程既要分发连接建立,还要分发已经建立连接的IO,如果太多的客户请求是不是会处理不过来,那么能不能让其分离嘞
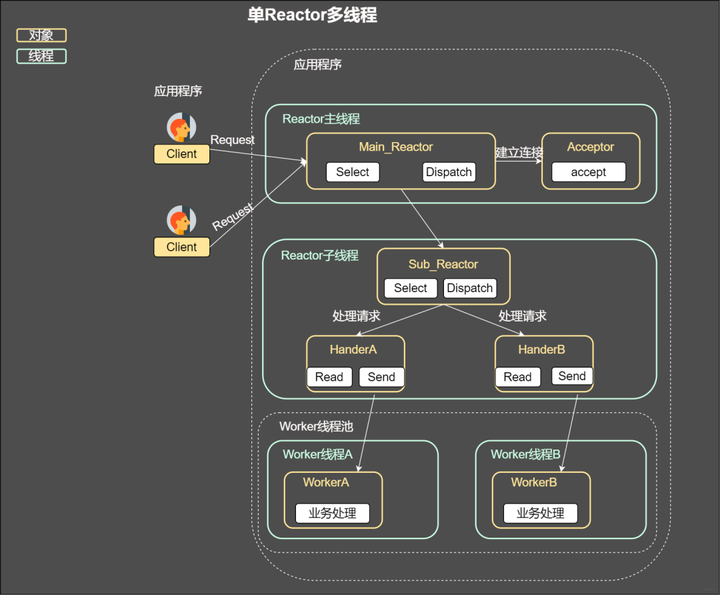
主从reactor
我们看看主从reactor的方式,思路很清晰,主reactor主负责分发Acceptor连接建立,然后已经联机的IO事件交给sub-reactor,这个sub-reactor的数量可以根据CPU的核数来定。
假设咱们是一个四核的CPU,设置sub-reactor为4.这个时候4个反应堆同时干活,是不是增强了IO分发处理的效率,因为多核操作,也大大的减少并发处理的锁开销。
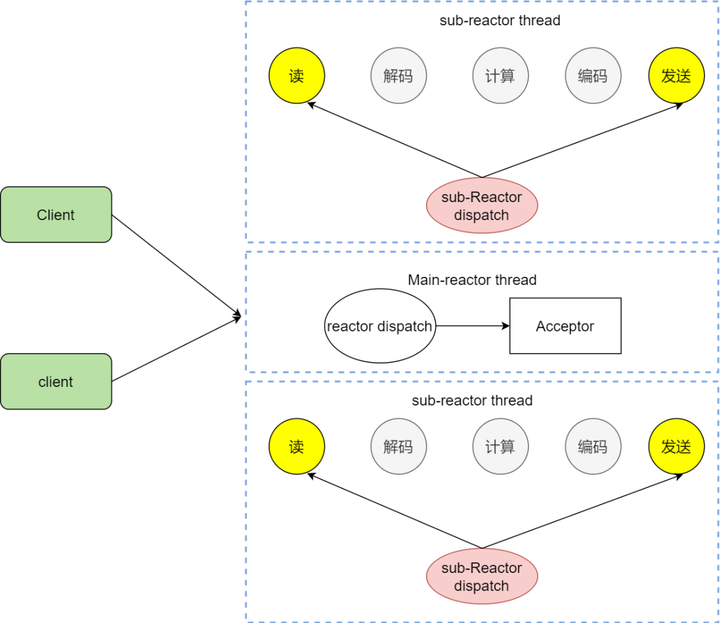
多reactor
epoll
上面说了poll的reactor反应堆模式,和poll相比,epoll可谓更加高效的事件机制。
如何切换到epoll呢
在lib/event_loop.c中的event_loop_init_with_name中,可以发现通过宏EPOLL_ENABEL来决定使用哪一个
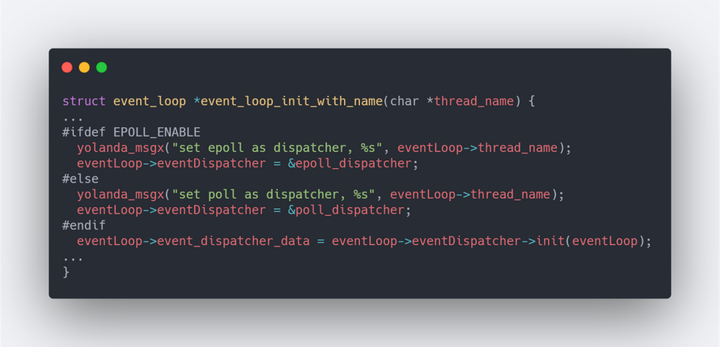
EPOLL_ENABEL
然后我们在根目录中查看CMakeLists.txt文件,如果系统中有epoll_create就会自动开启EPOLL_ENALE,如果没有则采用默认的poll作为事件分发机制。
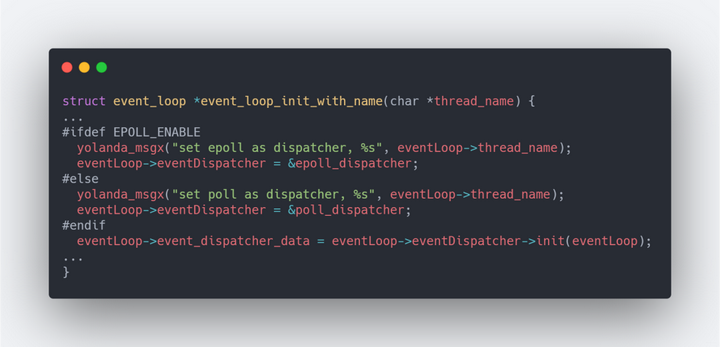
EPOLL_ENALE
这还没完,我们需要让编译器知道这个宏,所以需要让CMake往config.h文件写入这个宏的最终值。
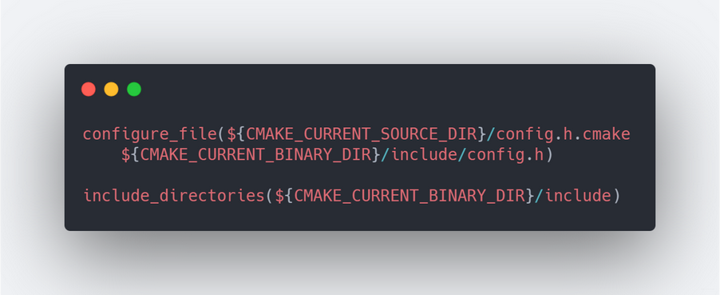
配置config.h
那么,为啥epoll的性能就比poll更好呢
-
首先poll和select,在使用之前需要一个感兴趣的事件集合,系统内核通过它构建相应的数据结构并注册,epoll却不是,它会维护一个全局的事件集合,通过epoll的句柄操作这个集合,操作系统内核不需要每次重新扫描整个集合
-
使用poll或者select的时候,应用程序需要扫描整个感兴趣的事件集合并找出活动的事件,如果请求量过大,扫描一次花费的时间就太长。而epoll不是,epoll直接返回活动的事件,减少大量的扫描时间。
那么边缘触发与条件触发到底是啥意思
-
如果某个套接字有1000个字节需要读,两个方案都会产生read ready notification,如果应用程序只读了500字节,就会陷入等待,对于条件触发就不一样,它会因为还有500字节而不断地产生read ready notification
异步IO
用程序告知内核启动某个操作,并让内核在整个操作(包括将数据从内核拷贝到应用程序的缓冲区)完成后通知应用程序。那么和信号驱动有啥不一样?

异步IO
信号驱动IO试内核通知应用程序什么时候启动一个IO操作。而异步IO模型是由内核通知应用程序啥时候完成。
异步IO的主要优点是充分的利用DMA特性。缺点是,如果要完成真正的异步IO,对于操作系统的压力较大,需要做大量的工作。
现在我们已经知道了阻塞IO 非阻塞IO,以及通过select epoll poll等IO多路复用并结合线程池的方案实现高性能的网络框架。但是还有个与之相对应叫做proactor的网络驱动模式,两者有什么区别?
在windows中这一套完整的支持套接字的异步编程接口叫做IOCP,和Reactor模式一样之处在于,也存在一个无限循环的event loop线程的,但是不同于Reactor模式,这个线程不负责处理IO调用,只是负责在对应的read,write操作完成的情况下,分发完成事件道不同的处理函数。简单的一句话总结即Reactor模式基于待完成的IO事件,而Proactor模式基于已完成的IO事件。