文章目录
- 一、CUDA Stream
- API
- 实战
- CUDA Stream和 Serial执行的对比:
- PCIE和NVLINK
- CUDA Stream 多流的收益和上限
- CUDA Kernel合并
- CUDA7中的Per-Thread编译选项
- 二、Event
- 三、NVVP
- 四、知识点四
一、CUDA Stream
CUDA Stream是GPU上task的执行队列,所有CUDA操作比如Kernel Function,内存拷贝等都是在stream上执行的
CUDA Stream有两种
- 隐式流,也叫默认流或者NULL流
所有的CUDA操作默认运行在隐式流里。隐式流里的GPU task和CPU端计算是同步的。
举例:𝑛= 1这行代码,必须等上面三行都执行完,才会执行它
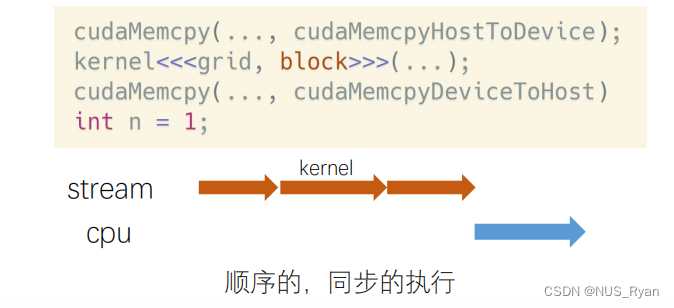
2.显式流:显式申请的流
显式流中的GPU Task和CPU计算是同步的。不同显式流内的GPU Task执行也是顺序执行的。

API
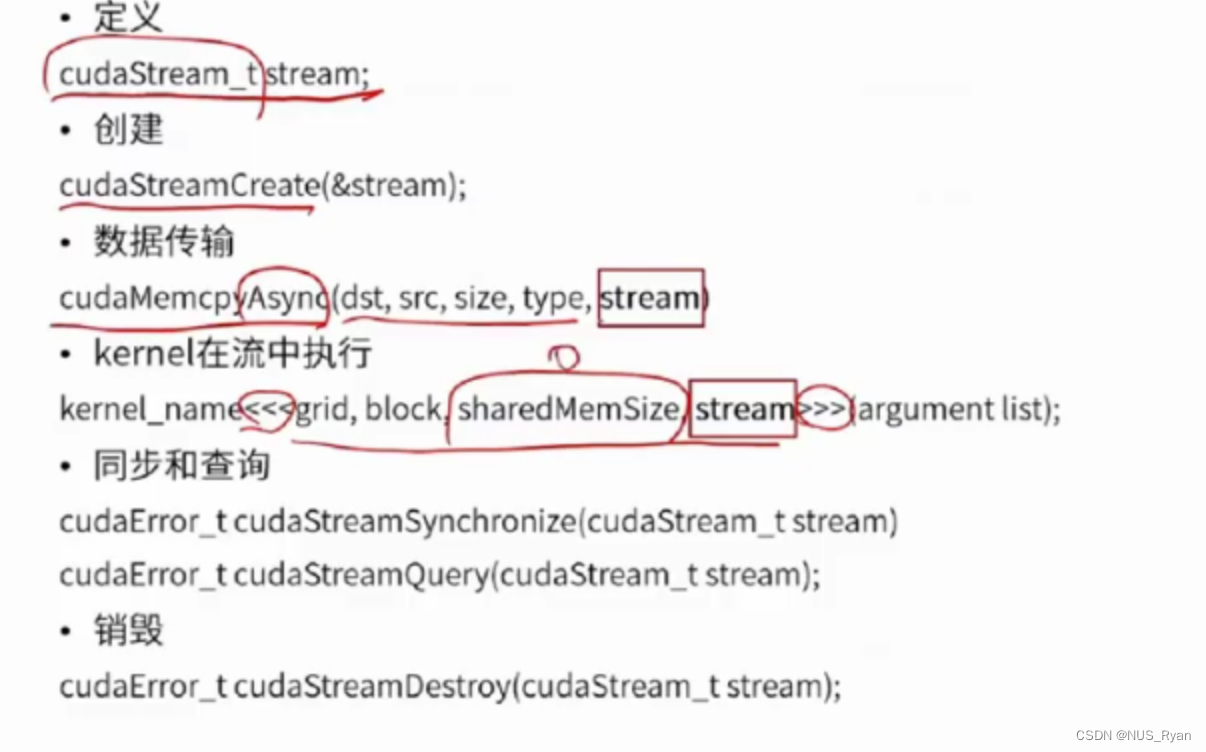
实战

在CUDA流(CUDA streams)中,使用cudaMemcpyAsync()是为了实现数据传输和内核执行的并行操作,从而提高GPU的计算性能。在CUDA编程中,流是一系列按顺序执行的操作,这些操作在不同的流之间可能会并行执行。这意味着,如果有多个CUDA流,那么可以同时执行多个流中的操作(前提是它们不会相互干扰或竞争硬件资源)。
cudaMemcpyAsync()是异步的数据传输函数,相较于同步版本cudaMemcpy(),它不会阻塞主机(CPU)线程的执行。当cudaMemcpyAsync()被调用时,它将数据传输操作加入到指定的CUDA流中,并允许主机线程继续执行后续操作。这样可以让主机线程在数据传输执行过程中同时执行其他任务。
使用cudaMemcpyAsync()可以实现以下优势:
隐藏数据传输和计算之间的延迟:当数据传输在一个流中进行时,可以在另一个流中执行计算内核。这样,在计算内核执行的同时,可以传输下一批数据,从而最大程度地利用GPU资源。
优化多流并行:通过将数据传输和计算内核放入不同的流中,可以充分利用GPU上的多个SM(Streaming Multiprocessors),从而实现更好的计算性能。
更高效的主机和设备之间的通信:由于cudaMemcpyAsync()是非阻塞的,主机线程可以在数据传输过程中执行其他任务,提高整体性能。
需要注意的是,使用cudaMemcpyAsync()时,要确保分配的内存是分页锁定(pinned)内存,因为异步数据传输仅在分页锁定内存上有效。可以使用cudaMallocHost()或cudaHostAlloc()函数为主机分配分页锁定内存。
CUDA Stream和 Serial执行的对比:

PCIE和NVLINK
1.NVLINK:NVLINK是NVIDIA开发的一种高性能、高带宽的GPU之间的互连技术。它为GPU之间提供了更高的通信带宽和更低的延迟,相较于传统的PCIe接口,NVLINK的性能更为出色。NVLINK主要用于高性能计算(HPC)以及深度学习等需要大量计算资源和高速数据传输的领域。NVLINK可以实现GPU之间的数据共享,以及在多个GPU上运行并行任务时的协同计算。
2.PCIe(Peripheral Component Interconnect Express):PCIe是一种常用的串行计算机扩展总线标准,用于连接主板上的各种设备,如GPU、网络卡和其他I/O设备。PCIe具有良好的向后兼容性,已成为许多计算设备通信的事实标准。然而,相对于NVLINK,PCIe的带宽较低,延迟较高。
CUDA Stream 多流的收益和上限
在许多情况下,使用多CUDA流(CUDA Streams)可以提高GPU的计算效率。CUDA流是一种并行计算机制,使得多个任务可以在GPU上同时运行。这些任务可能是计算任务,也可能是数据传输任务。通过使用多流,可以在某些任务等待数据时执行其他任务,从而实现任务间的流水线并行。同时,一个Stream中的一个Kernel无法充分利用GPU的算力,多流可以充分利用GPU的算力。
然而,并不是说CUDA流越多越好。创建过多的流可能导致系统资源竞争,如内存、带宽和计算单元,反而降低性能。最佳的CUDA流数量取决于硬件配置和应用程序特性。通常,需要进行实验以找到最佳的流数量,以实现最高的性能和资源利用率。
CUDA Kernel合并
CUDA Kernel函数合并(Kernel Fusion)是一种优化技术,它将多个原子操作或计算任务合并到一个更大的、更高效的Kernel函数中。这种技术可以减少内存访问次数、降低延迟,从而提高GPU的计算性能和资源利用率。通常,要在不影响程序正确性的前提下,将多个Kernel合并成一个。
下面我们以两个简单的矩阵操作为例:矩阵加法和矩阵乘以标量。原始的Kernel函数分别如下:
__global__ void matrixAddKernel(float* A, float* B, float* C, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int index = y * width + x;
C[index] = A[index] + B[index];
}
}
__global__ void matrixScalarMulKernel(float* A, float scalar, float* B, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int index = y * width + x;
B[index] = A[index] * scalar;
}
}
合并后的kernel函数为:
__global__ void fusedMatrixOpsKernel(float* A, float* B, float scalar, float* C, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int index = y * width + x;
C[index] = (A[index] + B[index]) * scalar;
}
}
在这个例子中,我们将矩阵加法和标量乘法合并为一个Kernel函数。这样可以减少内存访问次数,因为在原始的两个Kernel中,我们需要先将矩阵加法的结果存储在全局内存中,然后再从全局内存中读取该结果以进行标量乘法。而在合并后的Kernel中,我们不需要在全局内存中存储中间结果,从而节省了内存带宽和计算时间。
再举一个例子,如右图所示: 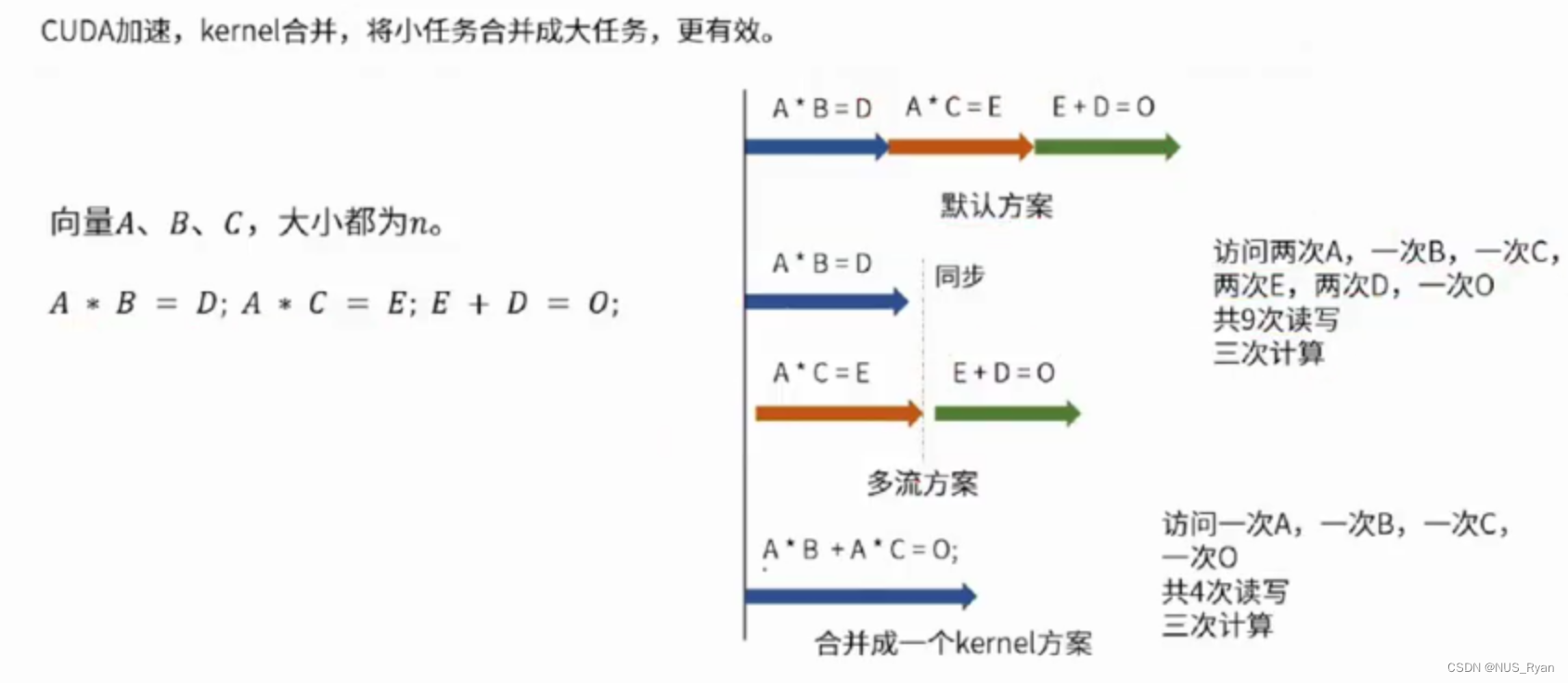
注意到默认方案和多流方案都需要访问两次A,一次B,一次C,两次E,两次D,一次O一共九次读写。而合并Kernel之后,只需要访问一次A,一次B,一次C,一次O一共四次读写,三次计算。
CUDA7中的Per-Thread编译选项
在给定代码中:
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
int main()
{
const int num_streams = 8;
cudaStream_t streams[num_streams];
float *data[num_streams];
for (int i = 0; i < num_streams; i++) {
cudaStreamCreate(&streams[i]);
cudaMalloc(&data[i], N * sizeof(float));
// launch one worker kernel per stream
kernel<<<1, 64, 0, streams[i]>>>(data[i], N);
// launch a dummy kernel on the default stream
kernel<<<1, 1>>>(0, 0);
}
cudaDeviceReset();
return 0;
}
我们在显式流中插入了默认流,如果使用如下nvcc命令编译的话:
nvcc ./stream_test.cu -o stream_legacy
结果将会是:

原因在这篇博文中已经有所阐述: https://developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
因此,我们需要使用这样的命令进行编译: nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread