一、浏览器工作
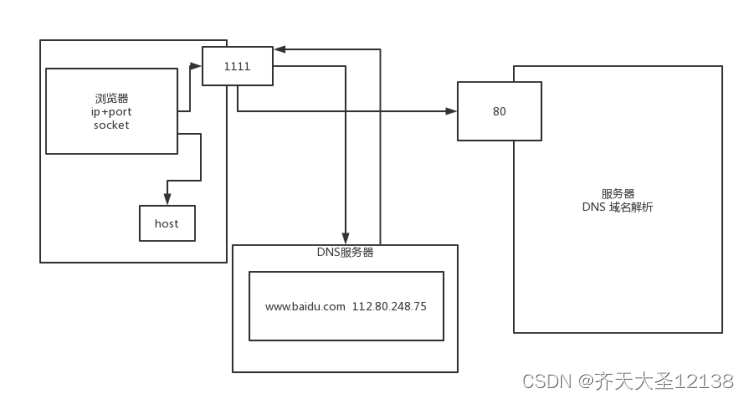
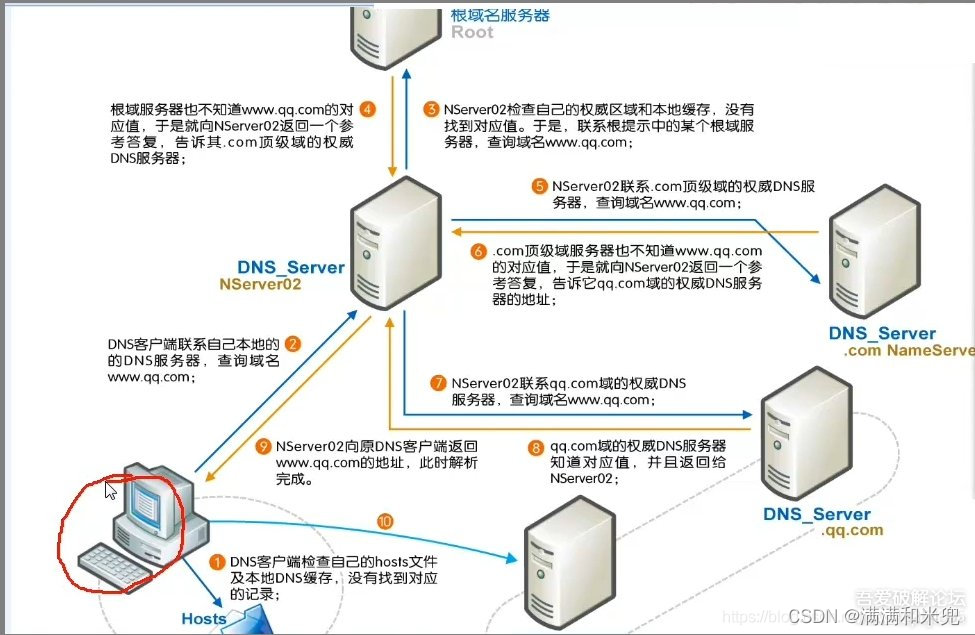
浏览器输入网址后,从DNS服务器中查找对应的IP,并返回客户端浏览器,然后通过ip地址去访问服务器。(操作系统中host文件存了一些对应的IP地址,浏览器拿到域名会先从host文件中查找ip,如果找不到才去DNS服务器找映射关系)浏览器访问服务器是为了获取资源,而服务器上存在html、css、js、图片视频等资源,所以输入网址之后,页面就出来了。
二、HTTP概述
HTTP是客户端和服务端请求和应答的标准。
三、HTTP的工作过程
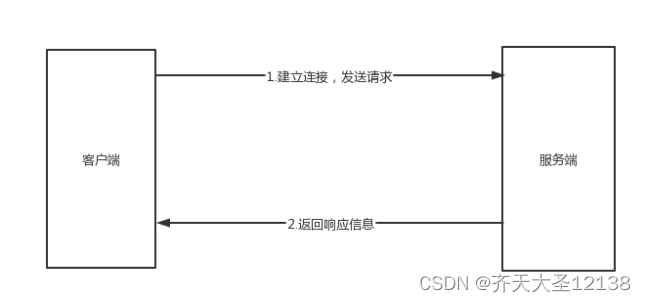
1、服务器不断监听TCP端口80。
2、客户端连接到web服务器,浏览器向服务器发送连接建立请求(请求报文,由请求行、请求头部、空行、请求数据组成)并建立TCP连接。
3、浏览器向服务器发出页面请求后,服务器返回请求的页面响应。
4、完成任务后,TCP被释放,浏览器解析html内容。
四、实验
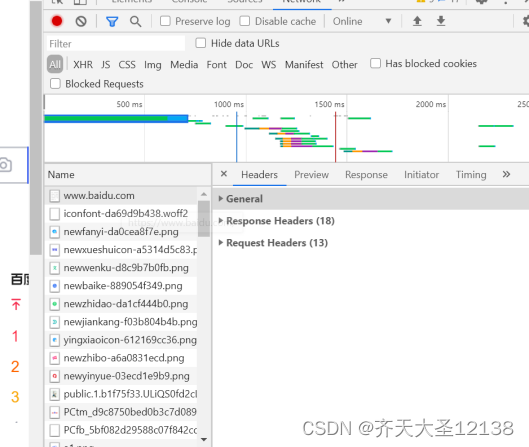
1、在浏览器打开https://www.baidu.com/
在开发者工具可以看见Requst Headers:请求头信息,Response Headers:响应头信息。
2、在wireshark中抓包看见请求数据包(箭头向右的是请求,箭头向左的是响应)
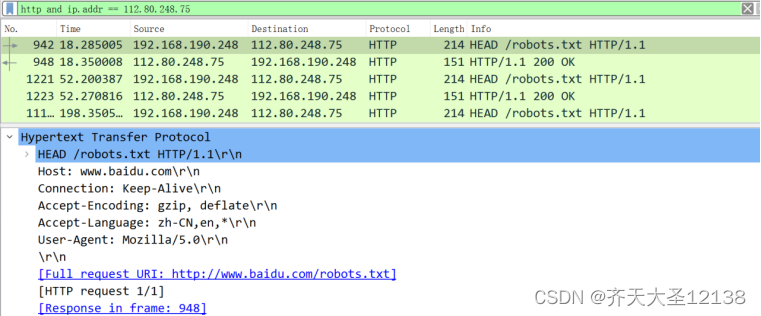
(HEAD是http请求方法之一,向服务器发出指定资源的请求,Keep-Alive,保持连接特性)
① 方法字段为HEAD
② URI字段为www.baidu.com表明该浏览器正在请求对象www.baidu.com
③ HTTP版本字段为 HTTP/1.1,表明浏览器本次发起http请求时使用的http协议版本
④ 请求行的后继行为首部行:
Host:客户端指定自己想访问的http服务器的域名/IP 地址和端口号,也就是www.baidu.com
User-Agent:mozilla首部行用来指明用户代理,即向服务器发送请求的浏览器为mozilla
3、响应数据包
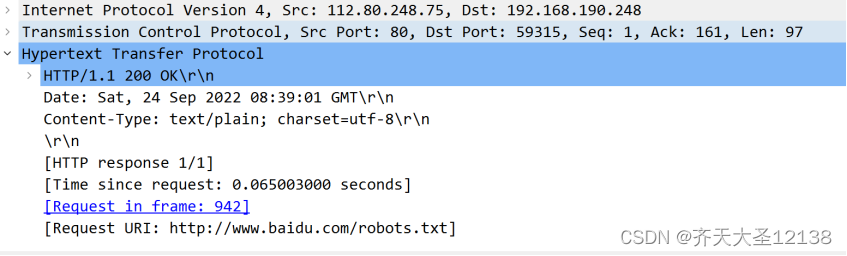
(第一行为初始状态行,含三个字段:协议字段、状态码和相应状态信息。200 ok 表示找到资源或者接受到返回的信息)
后继的首部行中:
Date:行表示服务器产生并发送该响应报文的时间和日期;2020.9.24
Content-Type:定义网络文件的类型和网页的编码
之后的就是实体体,为报文的主要部分


![[笔记]Windows使用OpenVpn构建虚拟局域网](https://img-blog.csdnimg.cn/28791cf1b47845f2bc1b833387101236.png)