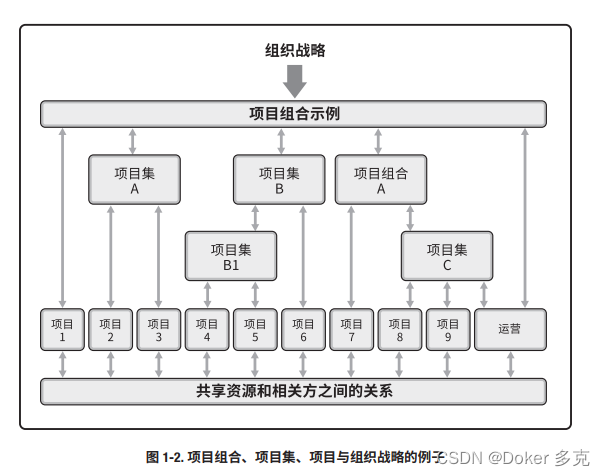
基于pytorch简单实现u-net
前言
最近在看经典的卷积网络架构,打算自己尝试复现一下,在此系列文章中,会参考很多文章,有些已经忘记了出处,所以就不贴链接了,希望大家理解。
完整的代码在最后。
本系列必须的基础
python基础知识、CNN原理知识、pytorch基础知识
本系列的目的
一是帮助自己巩固知识点;
二是自己实现一次,可以发现很多之前的不足;
三是希望可以给大家一个参考。
参考资料
来自b站大佬的项目库:
b站链接: https://space.bilibili.com/18161609
GitHub链接:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
目录结构
文章目录
- 基于pytorch简单实现u-net
- 1. 前言:
- 2. 数据集介绍与下载:
- 3. 项目流程说明:
- 4. 数据加载器:
- 5. 网络架构:
- 6. 损失函数:
- 7. 预处理方法:
- 8. 训练:
- 9. 预测:
- 10. 总结:
1. 前言:
本篇文章打算简单实现一下图像分割中的u-net网络,并讲解一下实现的流程和思路。其中,代码有很多的参考别人的地方,有些方法甚至是直接拷贝过来用的(有现成的你不用—狗头保命),特此申明一下。当然,虽然有些代码是参考的,但是自己把主要的数据加载器、网络、训练等自己实现了一次。
另外,这个实现不像之前实现分类网络,这个实现更复杂,因此代码讲解上会偏少,主要把思路理清。
2. 数据集介绍与下载:
下载
u_net主要应用于医学数据上的分割,这里使用的数据集名为DRIVE,可以从下面的链接中下载:
链接:https://pan.baidu.com/s/1YjW9wOm-sLC5oDs8T6a9bw
提取码:0b0w
介绍
图像目录结构:
├─test
│ ├─1st_manual
│ ├─2nd_manual
│ ├─images
│ └─mask
└─training
├─1st_manual
├─images
└─mask
其中:
- manual是手工划分的真实图像分隔,黑色(0)为背景,白色(255)为对象
- images是真实图像,大小都为
565*584*3,彩色的 - mask为一个蒙版,即黑色区域为不感兴趣的区域,白色区域为感兴趣的区域

3. 项目流程说明:
整体流程如下:

- 首先,定义数据加载器,加载数据,并返回image和mask(这里的mask与数据集中的mask不同,不同点在下面的4小节中介绍)
- 接着,定义网络结构、损失函数,并开始训练
- 保存训练的权重参数,用于后期的预测
**提前说明:**当你把我写的代码下载后,需要修改路径参数,因为我的数据集是放在了和项目不同的文件夹下的。
另外,我的整个项目文件夹结构为:
├─network_files
│ └─u_net.py
├─save_weights
├─utils
│ └─Loss.py
| └─transforms.py
└─My_Dataset.py
└─train,py
└─predict.py
4. 数据加载器:
这次的数据加载器实现起来很简单,主要思路如下:

其中,我们需要特别对mask进行一定的处理:

根据上述思路,可以完成代码(看注释):
import os
import torch
from torch import nn
from torch.utils.data import Dataset
from PIL import Image
import numpy as np
class My_Dataset(Dataset):
def __init__(self,root,train=True,transforms=None):
'''
:param root: 路径,比如.\data
:param train: 加载的数据集为训练还是测试集,默认为训练集
:param transforms: 预处理方法
'''
super(My_Dataset, self).__init__()
# 获取基础路径
self.flag = 'training' if train else 'test'
self.root = os.path.join(root,'DRIVE',self.flag) # .\data\DRIVE\training
# 获取所需的路径
self.img_name = [i for i in os.listdir(os.path.join(self.root,'images'))] # '21_training.tif'
self.img_list = [os.path.join(self.root,'images',i) for i in self.img_name] # .\data\DRIVE\training\images\21_training.tif
self.manual = [os.path.join(self.root,'1st_manual',i.split('_')[0])+'_manual1.gif' for i in self.img_name ] # .\data\DRIVE\training\1st_manual\21_manual1.gif
self.roi_mask = [os.path.join(self.root,'mask',i.split('_')[0]+'_'+self.flag+'_mask.gif') for i in self.img_name] # .\data\DRIVE\training\mask\21_training_mask.gif
# 初始化其它变量
self.transforms = transforms
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
# 打开图像(RGB模式)、manual(L-灰度图)、roi_mask(L-灰度图)
image = Image.open(self.img_list[idx])
manual = Image.open(self.manual[idx]).convert('L')
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
# 对图像进行处理
# 将对象设置为1,背景设置为0,不感兴趣的区域设置为255
manual = np.array(manual) / 255 # 白色(对象)为255,变为了1
roi_mask = 255 - np.array(roi_mask) # 不感兴趣区域为黑色(0),变为了255 ; 感兴趣为白色(255),变为了0
mask = np.clip(manual+roi_mask,a_min=0,a_max=255)
mask = Image.fromarray(mask) # 转为PIL,方便做预处理操作
if self.transforms is not None:
image,mask = self.transforms(image,mask)
return image,mask
5. 网络架构:
这里用b站up主的图来描述网络架构:

这里要注意几点:
- 原论文中每层双卷积后,图像尺寸都会减小,导致最后输出图像大小与输入大小不一致,这样一来,想要得到最终的分割图需要做一定的后处理。而我们这里双卷积不改变图像尺寸大小,只由下采样和上采样改变,如此一来,最终输出大小和输入大小一致,方便最后出结果。
- 下采样最后一层的双卷积,不改变图像通道数,仍然为512。是因为我们上采样用双线性插值,不改变通道数,如此一来,上采样后仍然为512,可以方便的和之前的进行拼接。
- 最终输出的通道数为2,是因为这里进行二分类,一个为背景,一个为分割对象。
基于上述结构图,可以理清实现网络架构的思路图:

可以轻松写出下面的代码:
import torch
from torch import nn
from torch.nn import functional as F
# 上采样+拼接
class Up(nn.Module):
def __init__(self,in_channels,out_channels,bilinear=True):
'''
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param bilinear: 是否采用双线性插值,默认采用
'''
super(Up, self).__init__()
if bilinear:
# 双线性差值
self.up = nn.Upsample(scale_factor=2,mode='bilinear',align_corners=True)
self.conv = doubleConv(in_channels,out_channels,in_channels//2) # 拼接后为1024,经历第一个卷积后512
else:
# 转置卷积实现上采样
# 输出通道数减半,宽高增加一倍
self.up = nn.ConvTranspose2d(in_channels,out_channels//2,kernel_size=2,stride=2)
self.conv = doubleConv(in_channels,out_channels)
def forward(self,x1,x2):
# 上采样
x1 = self.up(x1)
# 拼接
x = torch.cat([x1,x2],dim=1)
# 经历双卷积
x = self.conv(x)
return x
# 双卷积层
def doubleConv(in_channels,out_channels,mid_channels=None):
'''
:param in_channels: 输入通道数
:param out_channels: 双卷积后输出的通道数
:param mid_channels: 中间的通道数,这个主要针对的是最后一个下采样和上采样层
:return:
'''
if mid_channels is None:
mid_channels = out_channels
layer = []
layer.append(nn.Conv2d(in_channels,mid_channels,kernel_size=3,padding=1,bias=False))
layer.append(nn.BatchNorm2d(mid_channels))
layer.append(nn.ReLU(inplace=True))
layer.append(nn.Conv2d(mid_channels,out_channels,kernel_size=3,padding=1,bias=False))
layer.append(nn.BatchNorm2d(out_channels))
layer.append(nn.ReLU(inplace=True))
return nn.Sequential(*layer)
# 下采样
def down(in_channels,out_channels):
# 池化 + 双卷积
layer = []
layer.append(nn.MaxPool2d(2,stride=2))
layer.append(doubleConv(in_channels,out_channels))
return nn.Sequential(*layer)
# 整个网络架构
class U_net(nn.Module):
def __init__(self,in_channels,out_channels,bilinear=True,base_channel=64):
'''
:param in_channels: 输入通道数,一般为3,即彩色图像
:param out_channels: 输出通道数,即网络最后输出的通道数,一般为2,即进行2分类
:param bilinear: 是否采用双线性插值来上采样,这里默认采取
:param base_channel: 第一个卷积后的通道数,即64
'''
super(U_net, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.bilinear = bilinear
# 输入
self.in_conv = doubleConv(self.in_channels,base_channel)
# 下采样
self.down1 = down(base_channel,base_channel*2) # 64,128
self.down2 = down(base_channel*2,base_channel*4) # 128,256
self.down3 = down(base_channel*4,base_channel*8) # 256,512
# 最后一个下采样,通道数不翻倍(因为双线性差值,不会改变通道数的,为了可以简单拼接,就不改变通道数)
# 当然,是否采取双线新差值,还是由我们自己决定
factor = 2 if self.bilinear else 1
self.down4 = down(base_channel*8,base_channel*16 // factor) # 512,512
# 上采样 + 拼接
self.up1 = Up(base_channel*16 ,base_channel*8 // factor,self.bilinear) # 1024(双卷积的输入),256(双卷积的输出)
self.up2 = Up(base_channel*8 ,base_channel*4 // factor,self.bilinear)
self.up3 = Up(base_channel*4 ,base_channel*2 // factor,self.bilinear)
self.up4 = Up(base_channel*2 ,base_channel,self.bilinear)
# 输出
self.out = nn.Conv2d(in_channels=base_channel,out_channels=self.out_channels,kernel_size=1)
def forward(self,x):
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# 不要忘记拼接
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
out = self.out(x)
return {'out':out}
6. 损失函数:
其实,完成了数据加载、网络结构后,其实基本上已经完成了大部分内容了,因为图像分割就是像素级的分类,因此损失函数完全可以简简单单的用个交叉熵损失函数就行了。
但是,源码上不仅使用交叉熵作为损失函数,还使用了dice作为损失函数(度量两个集合的相似性)。
其中,dice_loss的计算公式为:

具体的实现,我就不多说了,因为不是重点,感兴趣的可以看看注释,不感兴趣的可以直接拿过来用:
import torch
from torch import nn
# dice : 度量两个集合的相似性
# loss
def criterion(inputs, target, loss_weight=None, num_classes: int = 2, dice: bool = True, ignore_index: int = -100):
losses = {}
for name, x in inputs.items():
# x = torch.Size([4, 2, 480, 480]) ,4为batch,2表示输出通道数,480*480表示和原图大小一样
# target = torch.Size([4, 480, 480]) 真实mask值
# ignore_index = 255,表示忽略那些不感兴趣的部分
loss = nn.functional.cross_entropy(x, target, ignore_index=ignore_index, weight=loss_weight)
if dice is True:
# 计算每个类别的dice(背景、前景),然后求均值
# 因此需要为每个类别构建一个target
dice_target = build_target(target, num_classes, ignore_index)
loss += dice_loss(x, dice_target, multiclass=True, ignore_index=ignore_index)
losses[name] = loss
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def build_target(target: torch.Tensor, num_classes: int = 2, ignore_index: int = -100):
"""build target for dice coefficient"""
dice_target = target.clone()
if ignore_index >= 0:
# 将255的区域设置为0,因为不感兴趣的不需要计算dice,因此先设置为0
ignore_mask = torch.eq(target, ignore_index)
dice_target[ignore_mask] = 0
# target转为one-hot编码形式 [1 0]表示一个类别 and [0 1]表示一个类别
dice_target = nn.functional.one_hot(dice_target, num_classes).float()
# 将255的值又填充回去
dice_target[ignore_mask] = ignore_index
else:
dice_target = nn.functional.one_hot(dice_target, num_classes).float()
# [N, H, W] -> [N, H, W, C]
return dice_target.permute(0, 3, 1, 2)
def dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6):
# 计算一个batch中所有图片某个类别的dice_coefficient
d = 0.
batch_size = x.shape[0]
# 遍历每张图片
for i in range(batch_size):
x_i = x[i].reshape(-1)
t_i = target[i].reshape(-1)
if ignore_index >= 0:
# 找出mask中不为ignore_index的区域
roi_mask = torch.ne(t_i, ignore_index)
x_i = x_i[roi_mask]
t_i = t_i[roi_mask]
inter = torch.dot(x_i, t_i)
sets_sum = torch.sum(x_i) + torch.sum(t_i)
if sets_sum == 0:
sets_sum = 2 * inter
# 计算dice
d += (2 * inter + epsilon) / (sets_sum + epsilon)
return d / batch_size
def multiclass_dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6):
"""Average of Dice coefficient for all classes"""
dice = 0.
# 遍历每个channel,计算每个类别的dice
for channel in range(x.shape[1]):
dice += dice_coeff(x[:, channel, ...], target[:, channel, ...], ignore_index, epsilon)
# 求均值
return dice / x.shape[1]
def dice_loss(x: torch.Tensor, target: torch.Tensor, multiclass: bool = False, ignore_index: int = -100):
# 在channel方向做softmax
x = nn.functional.softmax(x, dim=1)
# 选择采用的方法
fn = multiclass_dice_coeff if multiclass else dice_coeff
return 1 - fn(x, target, ignore_index=ignore_index)
7. 预处理方法:
这个文件,我是直接拷贝过来的,因为里面实现的方法功能和torchvision.transforms一致,这里之所以重新定义一次,是因为我们需要同时处理图像和mask两个值。
感兴趣的可以自己研究一下:
import numpy as np
import random
import torch
from torchvision import transforms as T
from torchvision.transforms import functional as F
# 填充
def pad_if_smaller(img, size, fill=0):
# 获取图像最短边
min_size = min(img.size)
# 如果最短边小于给定的尺寸
if min_size < size:
# 用fill值进行填充
ow, oh = img.size
padh = size - oh if oh < size else 0
padw = size - ow if ow < size else 0
img = F.pad(img, (0, 0, padw, padh), fill=fill)
return img
# 将所有预处理方法集合在一起,然后运行
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
# 随机缩放
class RandomResize(object):
def __init__(self, min_size, max_size=None):
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
size = random.randint(self.min_size, self.max_size)
# 这里size传入的是int类型,所以是将图像的最小边长缩放到size大小
image = F.resize(image, size)
# 这里的interpolation注意下,在torchvision(0.9.0)以后才有InterpolationMode.NEAREST
# 如果是之前的版本需要使用PIL.Image.NEAREST
target = F.resize(target, size, interpolation=T.InterpolationMode.NEAREST)
return image, target
# 水平翻转
class RandomHorizontalFlip(object):
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.hflip(image)
target = F.hflip(target)
return image, target
# 垂直翻转
class RandomVerticalFlip(object):
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.vflip(image)
target = F.vflip(target)
return image, target
# 随机裁剪
class RandomCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = pad_if_smaller(image, self.size)
target = pad_if_smaller(target, self.size, fill=255)
crop_params = T.RandomCrop.get_params(image, (self.size, self.size))
image = F.crop(image, *crop_params)
target = F.crop(target, *crop_params)
return image, target
# 中心裁剪
class CenterCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = F.center_crop(image, self.size)
target = F.center_crop(target, self.size)
return image, target
# 转为tensor
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
# 归一化
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target
8. 训练:
这里,简单的实现了一下训练的方法,主要的实现思路如下:

按照上述思路,可以实现代码:
from network_files.u_net import U_net
from utils import transforms as T
from My_Dataset import My_Dataset
from utils import Loss
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch import optim
# 训练的预处理方法获取
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, vflip_prob=0.5,
mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 初始化
min_size = int(0.5 * base_size)
max_size = int(1.2 * base_size)
# 随机裁剪
trans = [T.RandomResize(min_size, max_size)]
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
if vflip_prob > 0:
trans.append(T.RandomVerticalFlip(vflip_prob))
trans.extend([
T.RandomCrop(crop_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
self.transforms = T.Compose(trans)
def __call__(self, img, target):
return self.transforms(img, target)
# 获取预处理方法
def get_transform(train, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
base_size = 565
crop_size = 480
if train:
# 训练模式获取的预处理方法
return SegmentationPresetTrain(base_size, crop_size, mean=mean, std=std)
def main():
# 设置基本参数信息
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 如果GPU不够用,可以用cpu
device = torch.device('cpu')
batch_size= 4
epoch = 20
num_classes = 2 # 1(object)+1(background)
if num_classes == 2:
# 设置cross_entropy中背景和前景的loss权重(根据自己的数据集进行设置)
loss_weight = torch.as_tensor([1.0, 2.0], device=device)
else:
loss_weight = None
# 加载数据
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
train_dataset = My_Dataset('../data',train=True,transforms=get_transform(train=True, mean=mean, std=std))
val_dataset = My_Dataset('../data',train=False,transforms=get_transform(train=False, mean=mean, std=std))
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
val_loader = DataLoader(val_dataset,batch_size=batch_size,shuffle=True)
# 创建模型
model = U_net(3,num_classes) # 输入通道数,输出通道数
model.to(device)
# 定义优化器
params = [p for p in model.parameters() if p.requires_grad] # 定义需要优化的参数
sgd = optim.SGD(params,lr=0.01,momentum=0.9,weight_decay=1e-4)
# 开始训练
model.train()
for e in range(epoch):
loss_temp = 0
for i,(image,mask) in enumerate(train_loader):
image,mask = image.to(device),mask.to(device)
output = model(image)
loss = Loss.criterion(output, mask, loss_weight, num_classes=num_classes, ignore_index=255)
loss_temp += loss.item()
sgd.zero_grad()
loss.backward()
sgd.step()
print(f'第{e+1}个epoch,平均损失loss={loss_temp/(i+1)}')
# 保存权重
name = 'save_weights/u_net.pth'
torch.save(model.state_dict(),name)
if __name__ == '__main__':
main()
运行结果展示,这里就展示一下正常运行的结果,大家可以自己去运行:

9. 预测:
上面训练完后,就保存了相关的参数值,我们可以利用它来进行预测。
预测实现的思路如下:

代码如下:
import os
import time
import torch
from utils import transforms as T
import numpy as np
from PIL import Image
from network_files.u_net import U_net
def main():
# 设置基本参数,需要自己改变路径参数
classes = 1
weights_path = "./save_weights/u_net.pth"
img_path = "../data/DRIVE/test/images/03_test.tif" # ,另外可以改变预测的图像对象
roi_mask_path = "../data/DRIVE/test/mask/03_test_mask.gif"
# 这个是图像归一化的参数
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
# 获取设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建模型,输入通道数为3,输出为2
model = U_net(3,classes+1)
# 加载权重
model.load_state_dict(torch.load(weights_path))
model.to(device)
# 打开相关路径
roi_img = Image.open(roi_mask_path).convert('L')
original_img = Image.open(img_path).convert('RGB')
# 预处理
data_transform = T.Compose([T.RandomCrop(480),
T.ToTensor(),
T.Normalize(mean=mean, std=std)])
img,roi_img = data_transform(original_img,roi_img)
# 将三维的数据转为四维,因为需要添加batch这个维度
img = torch.unsqueeze(img, dim=0)
# 将roi转为array,方便后期处理
roi_img = np.array(roi_img)
model.eval() # 进入验证模式
with torch.no_grad():
# 初始化一个全黑的图像,后期将白色的添加进去,就可以得到预测的mask值
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
output = model(img.to(device))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
# 将前景对应的像素值改成255(白色)
prediction[prediction == 1] = 255
# 将不敢兴趣的区域像素设置成0(黑色)
prediction[roi_img == 0] = 0
mask = Image.fromarray(prediction)
mask.save("test_result.png")
if __name__ == '__main__':
main()
结果展示:

说明:由于预测的时候,我们将图像裁剪为了480*480,因此和真实结果看起来大小有一定的差距。
从图中,也可以看出,那些比较大的血管,基本都分割出来了,而较细微的血管,部分没有分割出来。综合来看,效果还是不错。
10. 总结:
这里只是简单的实现了u-net网络,还有很多地方可以改进,比如:
- 学习率没有调整
- 没有添加验证集部分
- 预测仅仅只是针对一张图片预测,没有实现集成的预测函数
- …
当然,代码写到这里,基本上也实现了我预期的内容了,再次感谢大佬们的开源工作,让我可以轻松copy一些代码过来。
全部代码和训练好的参数:
链接:https://pan.baidu.com/s/1Ro9MS9OnxJTUkiJLzQrcmA
提取码:e3ol











![[Gitops--8]微服务前置中间件部署](https://img-blog.csdnimg.cn/220eea8fc1e7435195cd43c13744c0ff.png)