文章目录
- 一、什么是窗口函数
- 二、聚合函数+OVER()函数
- 三、PARTITION BY 子句
- 四、排序函数
- 4.1 ROW_NUMBER() 函数
- 4.2 演示 RANK()、DENSE_RANK()、ROW_NUMBER() 函数的异同
- 4.3 NTILE() 函数
- 4.4 LAG() 和 LEAD() 函数
- 4.5 FIRST_VALUE() 和 LAST_VALUE() 函数
- 五、Window Frames 自定义窗口
本文将详细介绍多种窗口函数。使用窗口函数简化了数据分析工作中查询语句的书写。在没有窗口函数之前,我们需要通过定义临时变量和大量的子查询才能完成工作,而使用窗口函数实现起来更加简洁高效。
窗口函数 是数据分析工作中必须掌握的工具,在 SQL 笔试中也是高频考点
一、什么是窗口函数
窗口函数也称 OLAP 函数,OLAP 的全称是 Online Analytical Processing,可以对数据进行实时分析处理。MySQL 从 8.0 版本开始支持窗口函数。窗口函数的基本语法如下:
<窗口函数> OVER ([PARTITION BY <用于分组的列>] ORDER BY <用于排序的列>)
-- ① 窗口函数: 聚合函数中的 SUM()、AVG()、COUNT()、MAX()、MIN() 其他专用窗口函数 RANK()、DENSE_RANK()、ROW_NUMBER()
-- ② PARTITION BY:你只需将它看成GROUP BY子句,但是在窗口函数中,你要写PARTITION BY
-- ③ ORDER BY:ORDER BY和普通查询语句中的ORDER BY没什么不同。注意,输出的顺序要仔细考虑
补充:
窗口函数与数据分组类似,但是比数据分组功能更加丰富。数据分组是将组内多个数据聚合成一个值,而窗口函数除了可以将组内数据聚合成一个值,还可以保留原始的每条数据。
数据准备:
mysql> SELECT * FROM chapter11;
-- shopname: 每个店铺的名称 sales: 销量 sale_date: 销售日期
+----------+-------+-----------+
| shopname | sales | sale_date |
+----------+-------+-----------+
| A | 1 | 2020/1/1 |
| B | 3 | 2020/1/1 |
| C | 5 | 2020/1/1 |
| A | 7 | 2020/1/2 |
| B | 9 | 2020/1/2 |
| C | 2 | 2020/1/2 |
| A | 4 | 2020/1/3 |
| B | 6 | 2020/1/3 |
| C | 8 | 2020/1/3 |
+----------+-------+-----------+
9 rows in set (0.00 sec)
二、聚合函数+OVER()函数
【练习1】查看每个店铺每天的销量与这张表中全部销量的平均值之间的情况。之前的写法:
-- 全部销量的平均值其实是一个固定的值,固定的值是由查询出来的
mysql> SELECT shopname,sales,sale_date,(SELECT AVG(sales) FROM chapter11) AS avg_sales FROM chapter11;
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | avg_sales |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 5 |
| B | 3 | 2020/1/1 | 5 |
| C | 5 | 2020/1/1 | 5 |
| A | 7 | 2020/1/2 | 5 |
| B | 9 | 2020/1/2 | 5 |
| C | 2 | 2020/1/2 | 5 |
| A | 4 | 2020/1/3 | 5 |
| B | 6 | 2020/1/3 | 5 |
| C | 8 | 2020/1/3 | 5 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
【练习2】查看每个店铺每天的销量与这张表中全部销量的平均值之间的情况。聚合函数+over:
mysql> SELECT shopname,sales,sale_date, AVG(sales) OVER() AS avg_sales FROM chapter11;
-- 运行上面的代码,得到的结果与运行第一种代码完全相同
-- OVER()函数的作用: 将聚合结果显示在每条单独的记录中
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | avg_sales |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 5 |
| B | 3 | 2020/1/1 | 5 |
| C | 5 | 2020/1/1 | 5 |
| A | 7 | 2020/1/2 | 5 |
| B | 9 | 2020/1/2 | 5 |
| C | 2 | 2020/1/2 | 5 |
| A | 4 | 2020/1/3 | 5 |
| B | 6 | 2020/1/3 | 5 |
| C | 8 | 2020/1/3 | 5 |
+----------+-------+-----------+-----------+
9 ROWS IN SET (0.00 sec)
三、PARTITION BY 子句
【练习3】每个店铺每天的销量和表中自己店铺的所有销量的平均值进行比较。
-- 分析其实就是按照店铺进行分组,然后在组内进行平均值聚合运算
mysql> SELECT
-> cha1.shopname
-> ,cha1.sales
-> ,cha1.sale_date
-> ,cha2.avg_sales
-> FROM
-> chapter11 cha1
-> INNER JOIN
-> (SELECT
-> shopname,
-> AVG (sales) AS avg_sales
-> FROM
-> chapter11
-> GROUP BY shopname) cha2
-> ON cha1.shopname = cha2.shopname;
-- 最后会得到每个店铺每天的销量,以及该店铺自己所有销量的平均值,具体运行结果如下表所示:
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | avg_sales |
+----------+-------+-----------+-----------+
| A | 4 | 2020/1/3 | 4 |
| A | 7 | 2020/1/2 | 4 |
| A | 1 | 2020/1/1 | 4 |
| B | 6 | 2020/1/3 | 6 |
| B | 9 | 2020/1/2 | 6 |
| B | 3 | 2020/1/1 | 6 |
| C | 8 | 2020/1/3 | 5 |
| C | 2 | 2020/1/2 | 5 |
| C | 5 | 2020/1/1 | 5 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
PARTITION BY 的作用与 GROUP BY 类似,在 OVER() 函数中使用 PARTITION BY 来指明要按照哪列进行分组,然后聚合函数就会在分好的组内进行聚合运算。
【练习4】每个店铺每天的销量和表中自己店铺的所有销量的平均值进行比较。具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> AVG (sales) OVER (PARTITION BY shopname) AS avg_sales
-> FROM
-> chapter11;
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | avg_sales |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 4 |
| A | 7 | 2020/1/2 | 4 |
| A | 4 | 2020/1/3 | 4 |
| B | 3 | 2020/1/1 | 6 |
| B | 9 | 2020/1/2 | 6 |
| B | 6 | 2020/1/3 | 6 |
| C | 5 | 2020/1/1 | 5 |
| C | 2 | 2020/1/2 | 5 |
| C | 8 | 2020/1/3 | 5 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
四、排序函数
4.1 ROW_NUMBER() 函数
ROW_NUMBER() 函数用来生成每条记录对应的行数,即第几行。行数是按照数据存储的顺序进行生成的,且从 1 开始。
因为行数是按照数据存储顺序生成的,所以一般
ROW_NUMBER()函数与ORDER BY结合使用,此时的行数就表示排序,ROW_NUMBER()函数的结果中不会出现重复值,即不会出现重复的行数,如果有两个相同的值,会按照表中存储的顺序来生成行数。
【练习5】获取全表中销量的升序排列结果,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> ROW_NUMBER() OVER (ORDER BY sales) AS sales_row_number
-> FROM
-> chapter11;
+----------+-------+-----------+------------------+
| shopname | sales | sale_date | sales_row_number |
+----------+-------+-----------+------------------+
| A | 1 | 2020/1/1 | 1 |
| C | 2 | 2020/1/2 | 2 |
| B | 3 | 2020/1/1 | 3 |
| A | 4 | 2020/1/3 | 4 |
| C | 5 | 2020/1/1 | 5 |
| B | 6 | 2020/1/3 | 6 |
| A | 7 | 2020/1/2 | 7 |
| C | 8 | 2020/1/3 | 8 |
| B | 9 | 2020/1/2 | 9 |
+----------+-------+-----------+------------------+
9 rows in set (0.00 sec)
【练习6】获取各自组内的一个排名结果,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> ROW_NUMBER() OVER (PARTITION BY shopname ORDER BY sales) AS sales_row_number
-> FROM
-> chapter11;
-- 得到每个店铺在不同时间的销量对应的排名,具体运行结果如下表所示:
+----------+-------+-----------+------------------+
| shopname | sales | sale_date | sales_row_number |
+----------+-------+-----------+------------------+
| A | 1 | 2020/1/1 | 1 |
| A | 4 | 2020/1/3 | 2 |
| A | 7 | 2020/1/2 | 3 |
| B | 3 | 2020/1/1 | 1 |
| B | 6 | 2020/1/3 | 2 |
| B | 9 | 2020/1/2 | 3 |
| C | 2 | 2020/1/2 | 1 |
| C | 5 | 2020/1/1 | 2 |
| C | 8 | 2020/1/3 | 3 |
+----------+-------+-----------+------------------+
9 rows in set (0.00 sec)
【练习7】获取每个店铺销量最差的一天,具体实现代码如下:
mysql> SELECT a.shopname,a.sales,a.sale_date FROM
-> (SELECT
-> shopname,
-> sales,
-> sale_date,
-> ROW_NUMBER() OVER (PARTITION BY shopname ORDER BY sales) AS sales_row_number
-> FROM
-> chapter11) AS a WHERE a.sales_row_number=1;
+----------+-------+-----------+
| shopname | sales | sale_date |
+----------+-------+-----------+
| A | 1 | 2020/1/1 |
| B | 3 | 2020/1/1 |
| C | 2 | 2020/1/2 |
+----------+-------+-----------+
3 rows in set (0.00 sec)
4.2 演示 RANK()、DENSE_RANK()、ROW_NUMBER() 函数的异同
创建订单内容表(order_content)并插入数据,代码如下:
-- ① 创建订单内容表order_content
DROP TABLE IF EXISTS order_content;
CREATE TABLE order_content (
order_id VARCHAR (8), -- 订单号
user_id VARCHAR (8), -- 下单用户
order_price INT -- 订单金额
);
-- ② 插入数据
INSERT INTO order_content (order_id,user_id,order_price)
VALUES ('o001','u001',800)
,('o002','u001',800)
,('o003','u001',1000)
,('o004','u001',1200)
,('o005','u002',400)
,('o006','u002',1500)
,('o007','u002',2100)
,('o008','u003',900)
,('o009','u003',700)
,('o010','u003',1700);
示例代码如下:
mysql> SELECT *,
-> RANK() OVER(PARTITION BY user_id ORDER BY order_price) AS 'rank',
-> DENSE_RANK() OVER(PARTITION BY user_id ORDER BY order_price) AS 'dense_rank',
-> ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_price) AS 'row_number'
-> FROM order_content;
-- ① RANK() 函数将排序字段值相同的序号视为一样的,将后面排序字段值不相同的序号跳过相同的排名号往后排
-- ② DENSE_RANK() 函数的功能与 RANK() 函数类似,DENSE_RANK() 函数生成的序号是连续的,而RANK() 函数生成的序号有可能不连续
-- ③ ROW_NUMBER() 函数将查询出来的每一行记录生成一个序号,并依次排序且不会重复。
+----------+---------+-------------+------+------------+------------+
| order_id | user_id | order_price | rank | dense_rank | row_number |
+----------+---------+-------------+------+------------+------------+
| o001 | u001 | 800 | 1 | 1 | 1 |
| o002 | u001 | 800 | 1 | 1 | 2 |
| o003 | u001 | 1000 | 3 | 2 | 3 |
| o004 | u001 | 1200 | 4 | 3 | 4 |
| o005 | u002 | 400 | 1 | 1 | 1 |
| o006 | u002 | 1500 | 2 | 2 | 2 |
| o007 | u002 | 2100 | 3 | 3 | 3 |
| o009 | u003 | 700 | 1 | 1 | 1 |
| o008 | u003 | 900 | 2 | 2 | 2 |
| o010 | u003 | 1700 | 3 | 3 | 3 |
+----------+---------+-------------+------+------------+------------+
10 rows in set (0.00 sec)
4.3 NTILE() 函数
NTILE() 函数主要用于对整张表的数据进行切片分组,默认是在对表不进行任何操作之前进行切片分组,比如,现在 chapter11 这张表有 9 行数据,要分成 3 组,那么就是第 1~3 行为一组、第 4~6 行为一组、第 7~9 行为一组。我们将 chapter11 表切分成 3 组,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> NTILE (3) OVER () AS cut_group
-> FROM
-> chapter11;
-- 对全表在不进行任何操作的情况下,按照从前往后分成若干组这种操作的一个使用场景就是针对全表进行随机分组
-- NTILE (3) 函数里面的3可以改成任何值
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | cut_group |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 1 |
| B | 3 | 2020/1/1 | 1 |
| C | 5 | 2020/1/1 | 1 |
| A | 7 | 2020/1/2 | 2 |
| B | 9 | 2020/1/2 | 2 |
| C | 2 | 2020/1/2 | 2 |
| A | 4 | 2020/1/3 | 3 |
| B | 6 | 2020/1/3 | 3 |
| C | 8 | 2020/1/3 | 3 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
【练习8】针对组内进行切片分组。
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> NTILE (3) OVER (PARTITION BY shopname) AS cut_group
-> FROM
-> chapter11;
-- 运行上面代码,会在每个组shopname内进行分组,将各自组内的所有记录再切片分成三组
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | cut_group |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 1 |
| A | 7 | 2020/1/2 | 2 |
| A | 4 | 2020/1/3 | 3 |
| B | 3 | 2020/1/1 | 1 |
| B | 9 | 2020/1/2 | 2 |
| B | 6 | 2020/1/3 | 3 |
| C | 5 | 2020/1/1 | 1 |
| C | 2 | 2020/1/2 | 2 |
| C | 8 | 2020/1/3 | 3 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
【练习9】按照指定顺序进行切片分组。比如:在各个组内按照销量进行升序排列以后再进行切片分组,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> NTILE (3) OVER (PARTITION BY shopname ORDER BY sales) AS cut_group
-> FROM
-> chapter11;
-- 运行上面的代码,会先按照shopname列进行分组,然后在组内按照销量进行升序排列,最后进行切片分组,具体运行结果如下表所示:
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | cut_group |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 1 |
| A | 4 | 2020/1/3 | 2 |
| A | 7 | 2020/1/2 | 3 |
| B | 3 | 2020/1/1 | 1 |
| B | 6 | 2020/1/3 | 2 |
| B | 9 | 2020/1/2 | 3 |
| C | 2 | 2020/1/2 | 1 |
| C | 5 | 2020/1/1 | 2 |
| C | 8 | 2020/1/3 | 3 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
4.4 LAG() 和 LEAD() 函数
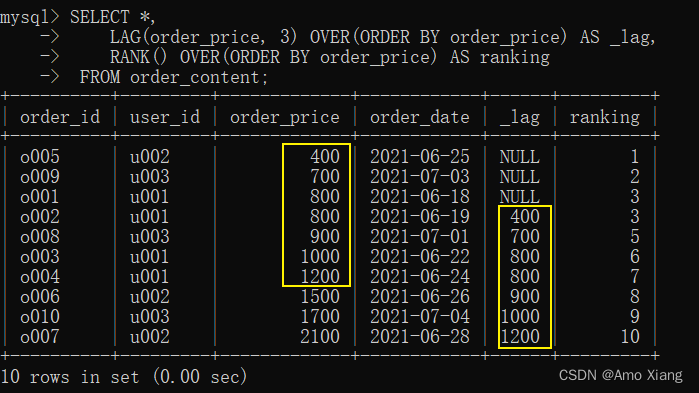
① lag() 函数:让数据向后移动。ps: 返回当前字段前n行的数据,示例代码如下:
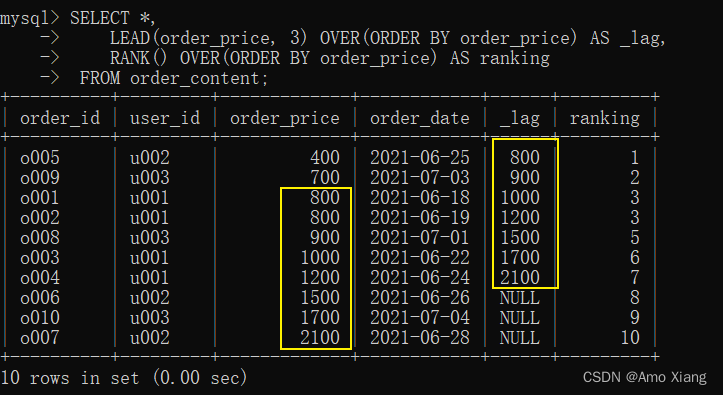
② lead() 函数:让数据向前移动。ps: 返回当前字段后n行的数据,示例代码如下:
【示例】获取每个店铺本次销量与它前一次销量之差,只需要把该店铺的销量数据全部向后移动1行,这样本次销量数据就与前一次销量数据处于同一行,然后就可以直接做差进行比较了,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> LAG(sales, 1) OVER (PARTITION BY shopname ORDER BY sale_date) lag_value
-> FROM
-> chapter11;
-- 对全表数据按照shopname列进行分组,然后在组内按照销售日期进行排序
-- 将每个店铺的本次销量与它的前一次销量进行比较,所以需要再将分组排序后的数据整体向后移动1行
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | lag_value |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | NULL |
| A | 7 | 2020/1/2 | 1 |
| A | 4 | 2020/1/3 | 7 |
| B | 3 | 2020/1/1 | NULL |
| B | 9 | 2020/1/2 | 3 |
| B | 6 | 2020/1/3 | 9 |
| C | 5 | 2020/1/1 | NULL |
| C | 2 | 2020/1/2 | 5 |
| C | 8 | 2020/1/3 | 2 |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
【示例】获取每个店铺本次销量与它后一次销量之差,只需要把该店铺的销量数据全部向前移动1行即可,这样本次销量数据就与后一次销量数据处于同一行,然后就可以直接做差进行比较了,在代码实现上,只需要把上面代码中的lag换成lead即可,具体如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> LEAD(sales, 1) OVER (PARTITION BY shopname ORDER BY sale_date) lag_value
-> FROM
-> chapter11;
+----------+-------+-----------+-----------+
| shopname | sales | sale_date | lag_value |
+----------+-------+-----------+-----------+
| A | 1 | 2020/1/1 | 7 |
| A | 7 | 2020/1/2 | 4 |
| A | 4 | 2020/1/3 | NULL |
| B | 3 | 2020/1/1 | 9 |
| B | 9 | 2020/1/2 | 6 |
| B | 6 | 2020/1/3 | NULL |
| C | 5 | 2020/1/1 | 2 |
| C | 2 | 2020/1/2 | 8 |
| C | 8 | 2020/1/3 | NULL |
+----------+-------+-----------+-----------+
9 rows in set (0.00 sec)
4.5 FIRST_VALUE() 和 LAST_VALUE() 函数
FIRST_VALUE() 和 LAST_VALUE() 顾名思义,就是第一个值和最后一个值,但又不是完全意义上的第一个或最后一个,而是截至当前行的第一个或最后一个。
【示例】获取每个店铺的最早销售日期和截至当前最后一次销售日期,通过这两个指标来反映店铺的营业时间,可以直接借助FIRST_VALUE()和LAST_VALUE()函数,具体实现代码如下:
mysql> SELECT
-> shopname,
-> sales,
-> sale_date,
-> FIRST_VALUE(sale_date) OVER (PARTITION BY shopname ORDER BY sale_date) AS first_date,
-> LAST_VALUE(sale_date) OVER (PARTITION BY shopname ORDER BY sale_date) AS last_date
-> FROM
-> chapter11;
+----------+-------+-----------+------------+-----------+
| shopname | sales | sale_date | first_date | last_date |
+----------+-------+-----------+------------+-----------+
| A | 1 | 2020/1/1 | 2020/1/1 | 2020/1/1 |
| A | 7 | 2020/1/2 | 2020/1/1 | 2020/1/2 |
| A | 4 | 2020/1/3 | 2020/1/1 | 2020/1/3 |
| B | 3 | 2020/1/1 | 2020/1/1 | 2020/1/1 |
| B | 9 | 2020/1/2 | 2020/1/1 | 2020/1/2 |
| B | 6 | 2020/1/3 | 2020/1/1 | 2020/1/3 |
| C | 5 | 2020/1/1 | 2020/1/1 | 2020/1/1 |
| C | 2 | 2020/1/2 | 2020/1/1 | 2020/1/2 |
| C | 8 | 2020/1/3 | 2020/1/1 | 2020/1/3 |
+----------+-------+-----------+------------+-----------+
9 rows in set (0.00 sec)
【示例】FIRST_VALUE():返回当前第一个值。示例代码如下:
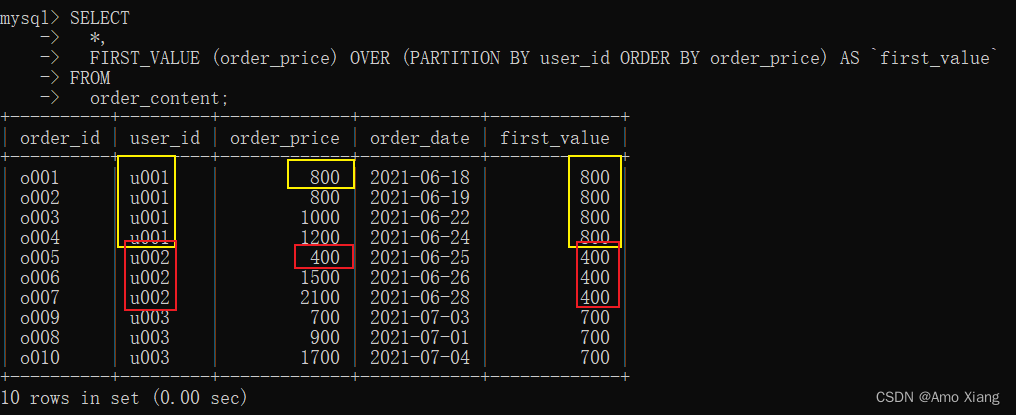
【示例】LAST_VALUE():返回当前最后一个值。示例代码如下:
mysql> SELECT
-> *,
-> LAST_VALUE (order_price) OVER (PARTITION BY user_id ORDER BY order_price) AS `last_value`
-> FROM
-> order_content;
+----------+---------+-------------+------------+------------+
| order_id | user_id | order_price | order_date | last_value |
+----------+---------+-------------+------------+------------+
| o001 | u001 | 800 | 2021-06-18 | 800 |
| o002 | u001 | 800 | 2021-06-19 | 800 |
| o003 | u001 | 1000 | 2021-06-22 | 1000 |
| o004 | u001 | 1200 | 2021-06-24 | 1200 |
| o005 | u002 | 400 | 2021-06-25 | 400 |
| o006 | u002 | 1500 | 2021-06-26 | 1500 |
| o007 | u002 | 2100 | 2021-06-28 | 2100 |
| o009 | u003 | 700 | 2021-07-03 | 700 |
| o008 | u003 | 900 | 2021-07-01 | 900 |
| o010 | u003 | 1700 | 2021-07-04 | 1700 |
+----------+---------+-------------+------------+------------+
10 rows in set (0.00 sec)
PS: 当前最后一个值即当前值,所以 order_price 和 last_value 字段的值相同。
【示例】NTH_VALUE():返回有序行的第n小的值。示例代码如下:
mysql> SELECT
-> *,
-> NTH_VALUE (order_price, 3) OVER (PARTITION BY user_id ORDER BY order_price) AS `nth_value`
-> FROM
-> order_content;
-- NTH_VALUE()函数返回了每个分区第3小的数据,所以NTH_VALUE()函数通常用来求排在第n位的数据。
-- 例如: 查询部门薪资排在第2位的员工信息,而返回排在第n位的数据只需要在order by 之后添加desc
+----------+---------+-------------+------------+-----------+
| order_id | user_id | order_price | order_date | nth_value |
+----------+---------+-------------+------------+-----------+
| o001 | u001 | 800 | 2021-06-18 | NULL |
| o002 | u001 | 800 | 2021-06-19 | NULL |
| o003 | u001 | 1000 | 2021-06-22 | 1000 |
| o004 | u001 | 1200 | 2021-06-24 | 1000 |
| o005 | u002 | 400 | 2021-06-25 | NULL |
| o006 | u002 | 1500 | 2021-06-26 | NULL |
| o007 | u002 | 2100 | 2021-06-28 | 2100 |
| o009 | u003 | 700 | 2021-07-03 | NULL |
| o008 | u003 | 900 | 2021-07-01 | NULL |
| o010 | u003 | 1700 | 2021-07-04 | 1700 |
+----------+---------+-------------+------------+-----------+
10 rows in set (0.00 sec)
五、Window Frames 自定义窗口
可以以当前行为基准,精确的自定义要选取的数据范围。例如:想选取当前行的前三行和后三行一共7行数据进行统计,相当于自定义一个固定大小的窗口,当当前行移动的时候,窗口也会随之移动
看下面的例子,我们选中了当前行的前两行和后两行,一共5行数据
定义窗口的语法:
-- 定义 window frames 有两种方式: ROWS 和 RANGE ,具体语法如下:
<window function> OVER (...
-- ...代表了之前我们介绍的例如 PARTITION BY 子句
ORDER BY <order_column>
[ROWS|RANGE] <window frame extent>
-- 先理解ROWS语法
-- ① 通用写法 ROWS BETWEEN lower_bound AND upper_bound
上限(upper_bund) 和 下限(lower_bound) 的取值为如下5种情况:
-- ① UNBOUNDED PRECEDING – 对上限无限制
-- ② PRECEDING – 当前行之前的第n行 (n 填入具体数字如: 5 PRECEDING)
-- ③ CURRENT ROW – 仅当前行
-- ④ FOLLOWING –当前行之后的第 n 行 (n 填入具体数字如: 5 FOLLOWING)
-- ⑤ UNBOUNDED FOLLOWING – 对下限无限制
重新创建 order_content 表,增加一列下单日期的字段 order_date,代码如下:
mysql> DROP TABLE IF EXISTS order_content;
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE TABLE order_content (
-> order_id VARCHAR (8),
-> user_id VARCHAR (8),
-> order_price INT,
-> order_date DATE
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO order_content (
-> order_id,
-> user_id,
-> order_price,
-> order_date
-> )
-> VALUES
-> ('o001', 'u001', 800, '2021-06-18'),
-> ('o002', 'u001', 800, '2021-06-19'),
-> ('o003', 'u001', 1000, '2021-06-22'),
-> ('o004', 'u001', 1200, '2021-06-24'),
-> ('o005', 'u002', 400, '2021-06-25'),
-> ('o006', 'u002', 1500, '2021-06-26'),
-> ('o007', 'u002', 2100, '2021-06-28'),
-> ('o008', 'u003', 900, '2021-07-01'),
-> ('o009', 'u003', 700, '2021-07-03'),
-> ('o010', 'u003', 1700, '2021-07-04');
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
更新的 order_content 表如下所示:
mysql> SELECT * FROM order_content;
+----------+---------+-------------+------------+
| order_id | user_id | order_price | order_date |
+----------+---------+-------------+------------+
| o001 | u001 | 800 | 2021-06-18 |
| o002 | u001 | 800 | 2021-06-19 |
| o003 | u001 | 1000 | 2021-06-22 |
| o004 | u001 | 1200 | 2021-06-24 |
| o005 | u002 | 400 | 2021-06-25 |
| o006 | u002 | 1500 | 2021-06-26 |
| o007 | u002 | 2100 | 2021-06-28 |
| o008 | u003 | 900 | 2021-07-01 |
| o009 | u003 | 700 | 2021-07-03 |
| o010 | u003 | 1700 | 2021-07-04 |
+----------+---------+-------------+------------+
10 rows in set (0.00 sec)
【练习10】再次演示聚合函数作为窗口函数的情况,代码如下:
mysql> SELECT
-> *,
-> AVG (order_price) OVER (PARTITION BY user_id ORDER BY order_date) AS current_avg
-> FROM
-> order_content;
-- 按照 user_id 字段进行分区/分组 然后根据 order_date 字段排序
-- ps: current_avg 字段代表当前分区中起始位置到当前位置的order_price平均值 例如: u001的current_avg字段-->800=(800+800)/2
-- 950=(800+800+1000+1200)/4
+----------+---------+-------------+------------+-------------+
| order_id | user_id | order_price | order_date | current_avg |
+----------+---------+-------------+------------+-------------+
| o001 | u001 | 800 | 2021-06-18 | 800.0000 |
| o002 | u001 | 800 | 2021-06-19 | 800.0000 |
| o003 | u001 | 1000 | 2021-06-22 | 866.6667 |
| o004 | u001 | 1200 | 2021-06-24 | 950.0000 |
| o005 | u002 | 400 | 2021-06-25 | 400.0000 |
| o006 | u002 | 1500 | 2021-06-26 | 950.0000 |
| o007 | u002 | 2100 | 2021-06-28 | 1333.3333 |
| o008 | u003 | 900 | 2021-07-01 | 900.0000 |
| o009 | u003 | 700 | 2021-07-03 | 800.0000 |
| o010 | u003 | 1700 | 2021-07-04 | 1100.0000 |
+----------+---------+-------------+------------+-------------+
10 rows in set (0.00 sec)
-- 第二种写法:
mysql> SELECT
-> *,
-> AVG (order_price) OVER (
-> PARTITION BY user_id
-> ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING
-> AND current ROW
-> ) AS current_avg
-> FROM
-> order_content;
+----------+---------+-------------+------------+-------------+
| order_id | user_id | order_price | order_date | current_avg |
+----------+---------+-------------+------------+-------------+
| o001 | u001 | 800 | 2021-06-18 | 800.0000 |
| o002 | u001 | 800 | 2021-06-19 | 800.0000 |
| o003 | u001 | 1000 | 2021-06-22 | 866.6667 |
| o004 | u001 | 1200 | 2021-06-24 | 950.0000 |
| o005 | u002 | 400 | 2021-06-25 | 400.0000 |
| o006 | u002 | 1500 | 2021-06-26 | 950.0000 |
| o007 | u002 | 2100 | 2021-06-28 | 1333.3333 |
| o008 | u003 | 900 | 2021-07-01 | 900.0000 |
| o009 | u003 | 700 | 2021-07-03 | 800.0000 |
| o010 | u003 | 1700 | 2021-07-04 | 1100.0000 |
+----------+---------+-------------+------------+-------------+
10 rows in set (0.00 sec)
-- 简写: ROWS BETWEEN UNBOUNDED PRECEDING AND current ROW --> ROWS UNBOUNDED PRECEDING 与上述结果执行是一致的
SELECT
*,
AVG(order_price) OVER (PARTITION BY user_id ORDER BY order_date ROWS UNBOUNDED PRECEDING) AS current_avg
FROM
order_content;
SUM()、MIN()、MAX() 函数的使用方法相同,此处不再赘述。
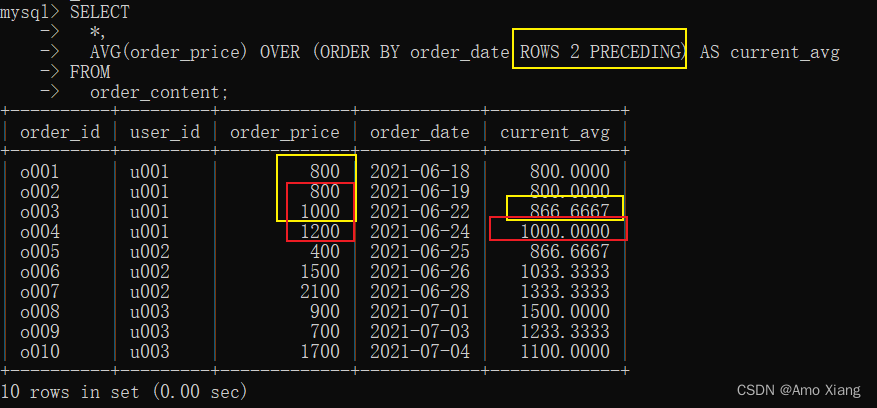
【练习11】将当前行和它前面的两行划为一个窗口,AVG()函数作用在这3行上面,并将求出的结果展示在右侧。
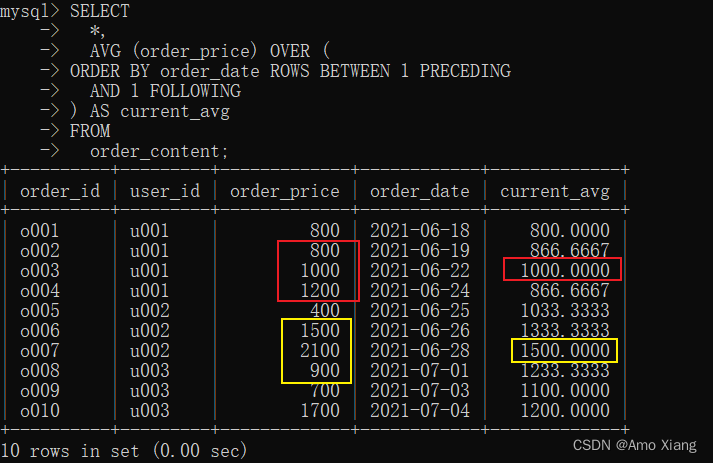
【练习12】将当前行和它前面的一行至后面一行划分为一个窗口,AVG()函数作用在这3行上面,并将求出的结果展示在右侧。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!