这是基于胡伟武老师的计算机体系结构课程所总结出来的框架,希望能让没有学习该课程的人可以去了解计算机是怎么造的,而对于学习这门课程的人可以在学习课程之前对整体框架有一个初步的认知。
如果不想看文字的话,可以看视频哦!
目录
- 01与晶体管
- 基本结构
- 计算流程
- 提升速度的结构
- 静态流水
- 动态流水
- 多发射
- 转移猜测
- cache
- TLB
- 总体架构
01与晶体管
计算机是一个很伟大的发明,他将我们的信息进行传播、处理甚至自动地完成我们的工作。那么他里面到底是怎么运作的呢?我们先来说说输入的信息,
计算机中所要的信息,比如说图像,文字和声音等,在计算机内部转化为成各种的编码,比a SCL码等,最终都会转化成二进制。他其实是一种表达方式,我们各种输入都会抽象地映射到二进制中。
就好像英人采用英语作为母语,我们采用中文作为母语。他都是人们定好的一种规则,他们之间可以相互转化。而二进制就是计算机的一种语言,那么我们需要将信息都进行转化,他才能读懂。转化规则(或者说编码)本质其实就是一个映射表。
为什么要用二进制,因为他最常见,更重要的是计算机最基本组成的晶体管能通过电压高低所造成的电路通断去表达二进制。高电压代表1,低电压代表0。而在其他领域,在量子计算机中,他用的是能级的高低来表示二进制,而超导体的工艺也通过的是磁通量的有无去表达01。
计算机就是用来计算,我刚刚说的晶体管其实是计算部分表达01,但是我们需要对计算的东西也用二进制进行存储,这部分其实是采用电容,如果电容重游电荷,那就代表1,如果没有电荷则代表0。
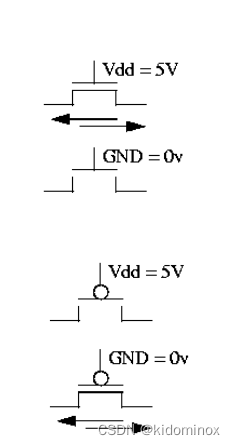
在初中物理我们学过最简单的灯泡点亮电路,需要一个开关来控制,但是他本身很大,那我们需要做更加复杂的任务,那么就需要我们去拿更小的物质去作为电路通断的基本单元,而这个基本单元就是晶体管,主要在计算机中是cmos管,cmos管分为nmos管和pmos管,我们可以看到,nmos管给予高电压的时候是通路,低电压的时候则短路,而pmos管则相反,这跟里面所掺杂的材质相反而导致的电流流向相反所致。
基本结构
那么小小的晶体管跟我们计算机有什么关系呢?
就像我们计算也是从最简单的加减法说起,而我们的逻辑计算也是从最简单的与或非开始,如果大家学过数电的话,应该很熟悉,不熟悉的话可以按照类似加减法的基础单元去理解。
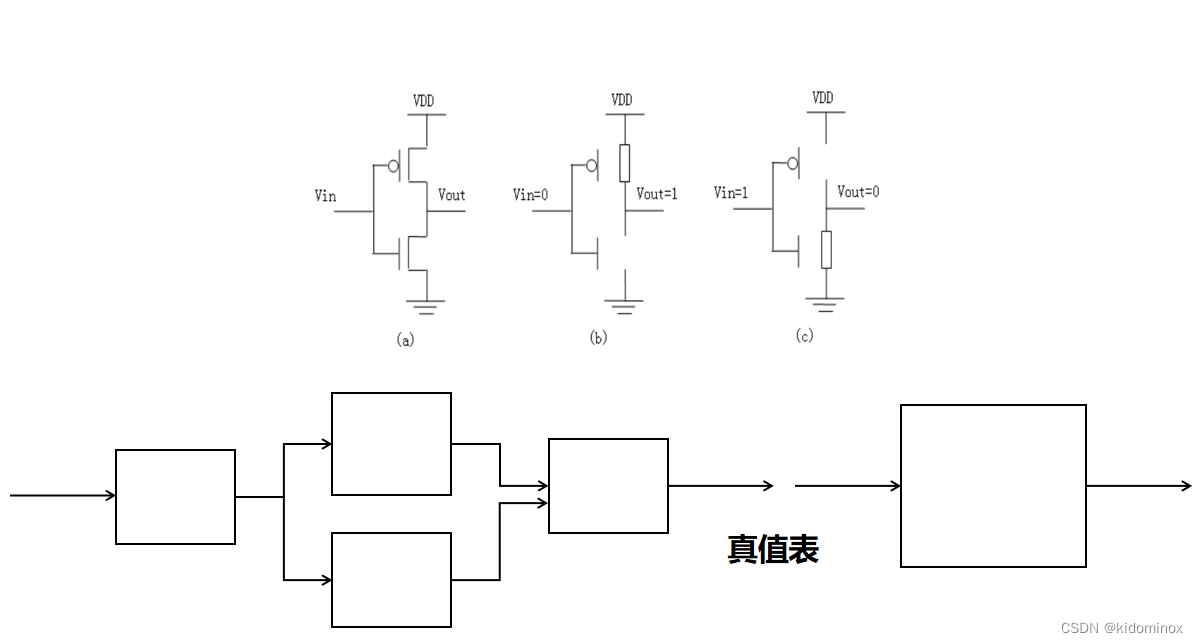
图中所示呢,就代表的是一个相反器,也是一个基础单元,我们发现他只需要一个p极管和n极管就能够达成相反功能。
同理啊,其他的基础单元或者其他功能模块也是由cmos管去组合实现。
更加抽象化,我们可以把它包装成一个输入为一条线,以及它中间的某一个黑盒子,然后会输出一个它的模块
那么我们就可以从小小的模块去不断去堆加,然后变成一个大模块,然后从大模块再继续构成更加复杂的逻辑,然后再封装,成一个更大模块,然后层层叠加去构建我们所理想中的逻辑结构。
怎么去封装成一个黑盒子呢?我们可以发现假设他这个盒子是我们上面所说的一个相反器,当我们遍历它的输入和对应输出的时候,我们叫做增值表,比如说我们把所有他可能的情况都列举出来,然后去知道他的输入对应的输出是什么样子的,
这样的话我们就可以把它封装成一个封成模块,然后以增值表去表达这个模块,这个模块就可以用到更加复杂的逻辑中去,其实现在目前硬件也是这样子,就是他会很成熟的提供各种各样的模块,然后我们需要去看各种模块的功能。然后去啊完成我们各种硬件结构。
计算流程
我们将上面的加法器,我们可以又把它弄成一个黑盒子,这里是一个移位加法器,给他数据他就一定会计算吗?我们发现他由一个控制端来告诉他我要不要把这些数据进行一个计算?这就涉及到了就是指令哦,他的集合是指令集,就是包含了我们可能会给出的指令的所有可能集合,然后我们会通过各种情况给予特定的指令去编译,编辑指令,我的理解成他要哪一些控制端是进行一个高电压,然后一些低控制端,然后控制端是低电压是零,比如说这个指令它是一个加法的运算的,那么在这个加法器中,他的控制端就是会变成一,那么在乘法器这边,他控制端那就是零类似的
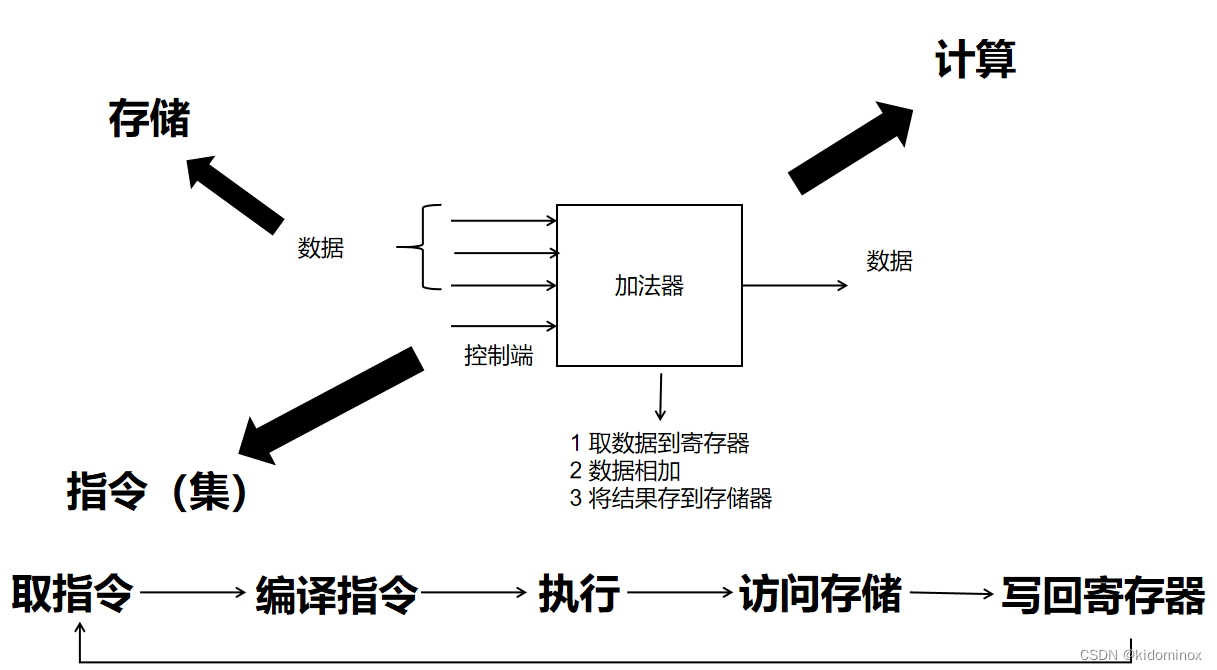
在图中我标注了存储、指令和计算,存储是数据和指令存放的地方,运算就是加法器这个模块,这是冯诺依曼结果,存储和计算分离。指令就是代码,通过指令去告诉计算机怎么做。
而我们计算机一直在做的事就是反复的执行这样的一个流水,但是这一个任务可能会进行上千条指令,这样依次 串行执行十分缓慢,因此体系结构还从不同方面去怎么去提高自条流水的速度。
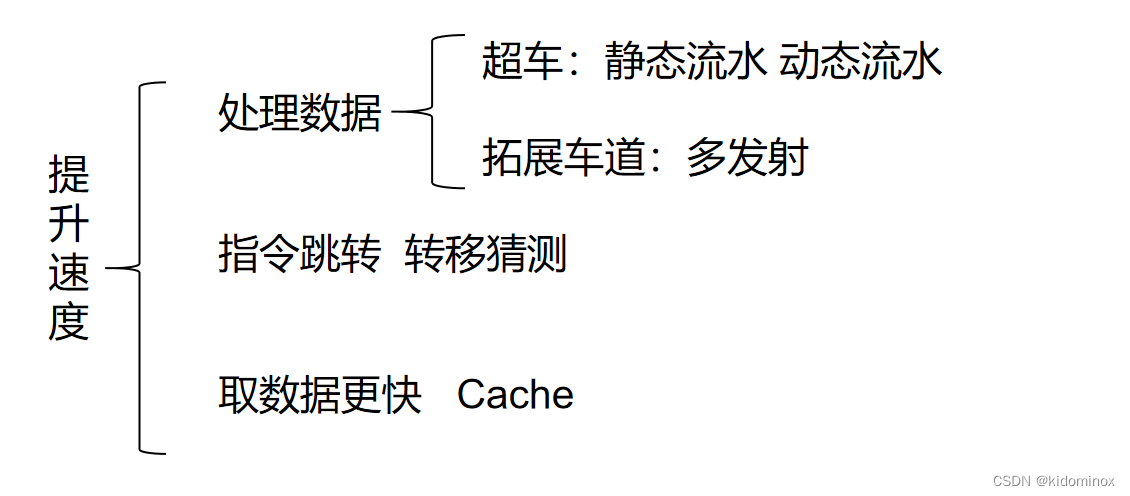
提升速度的结构
静态流水
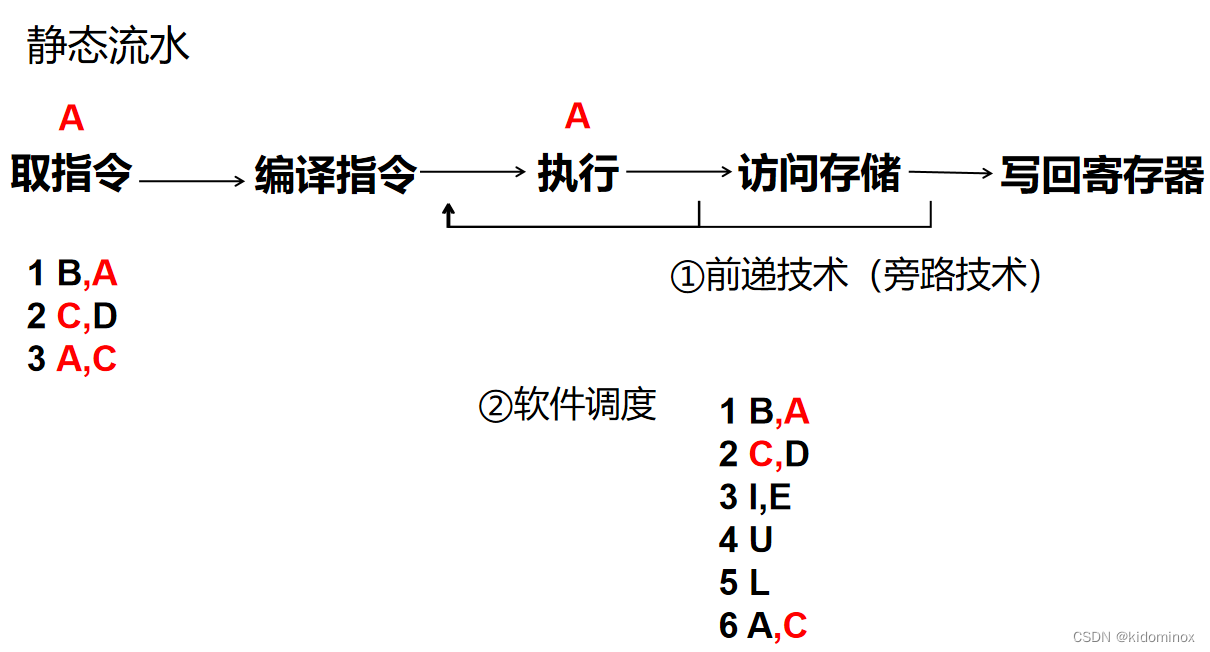
每一拍其实一条指令,能够做一个事,当第一条指令来到执行的时候,第三条指令才到取指令这里,然后我们发现,第三条指定他需要拿到a的信息,然后a的信息的话,但是他还没执行完,他还没有写回到寄存器中,比如说哦,我还不知道你计算的最新的结果,那我就要拿你这个最新的结果去算,那怎么办呢?我们就需要在他原地等等待,等到他拿到了最新的数据的时候告诉我,然后我才能够去。
为了减少等待的拍数,在第四步、第三步结束的时候,又给了一条电路线,让他引到第二步来,也就是第二步的时候,就能够告诉我第四步和第三步的新的数据
而软件调度则是用软程序员的方式,去让他更改程序指令的顺序,让他们离得更远,因此的话就是在执行的第六条a的时候,他其实a第一条的a他已经走完了整个流水线,所以他已经就能够知道编译的时候,我就能知道a的最新数据是什么?
动态流水
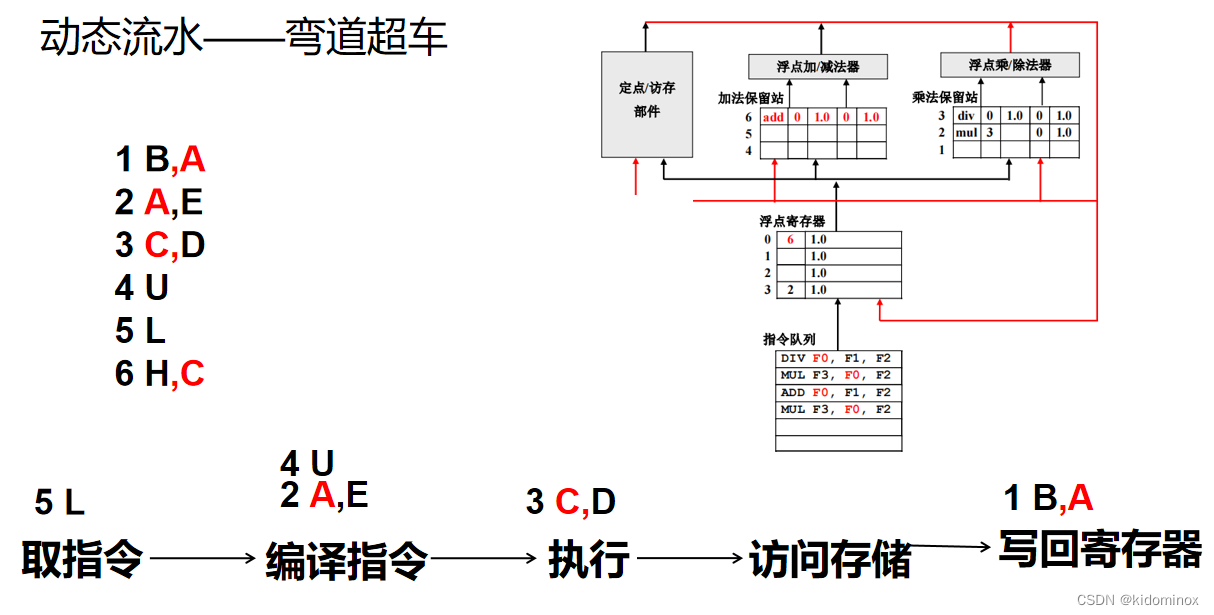
动态流水线的就是他能够弯道超车,就是他不在一个执行依次的去执行指令。
将就在硬件中多了一个然后再开辟一个模块叫做保留站,然后让还没有得到结果还没有能拿到新数据的指令让他在里面等,关键在于比他慢的且数据准备好的指令他能够不被堵塞,继续往前走。
我们看下面这条流水线的时候,发现当地条指令已经到写回寄存器的时候,第二条指令他还在编译指令第二步这里,然后第三条指令已经绕过了第二条指令,他已经开始执行了,达到一个这样的效果,这样的话就是能够避免中间这直行和存储访问,第四步一直等待。没有数据处理的一个状况。
多发射
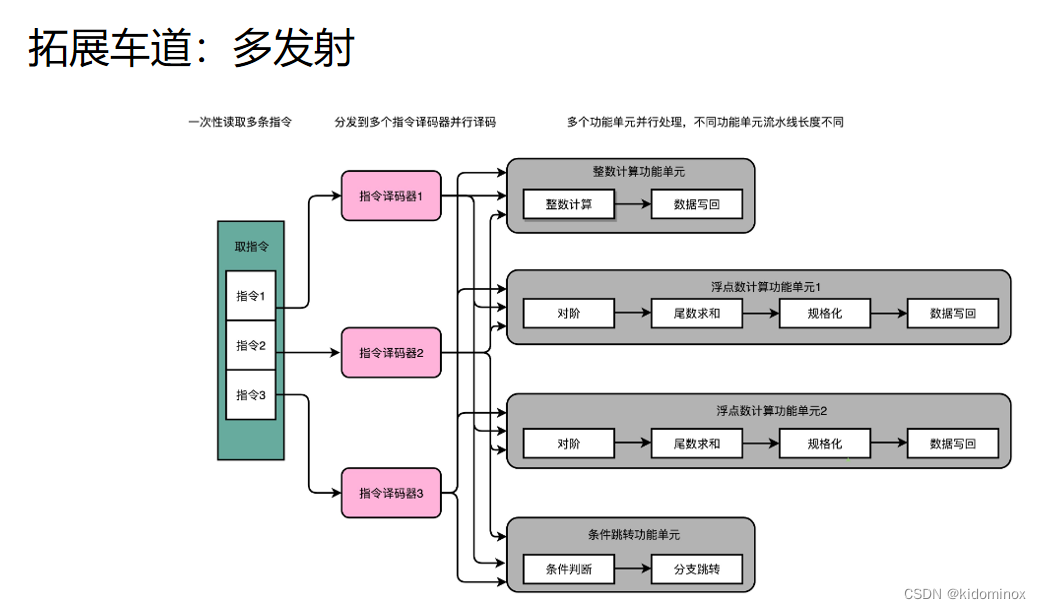
那除了超车,我们还可就是拓宽车道,使得处理计算的速度能够更快 大家都知道一个工厂里,如果只有一个人做一条产业线的话,是很慢,如果是多个人一条做这条产业线,那是不是就可能很快?因此的话,我们就用了多发射,也就是说,把上面的流水增加了多条流水线,但是有一个重要的点也是要顾及到,刚才所说的数据的相关性,因此在多发射的时候也要时时刻刻的检查,就是你在并行的道路的指令上是否也相关,以免发生一些新的指令拿不到最新的数据,这样的一个逻辑上的错误。
转移猜测

逻辑上我们会产生很多一些指令跳转,比如说比如说如果你做这个事,会发生A后果,如果你不做这样的事,你又会发生B后果,但是这个后果呢?他只有在执行的时候才会知道,才能够知道你要去哪里去取指令,那么我就需要无缘无故就必须要多等2拍去让他知道结果,才能够让我知道下一步应该去哪去指令,因此的话我们就再跳转类似的指令中加入了转移猜测,去提高他的速度
为什么能够用猜测这种方式?因为任务很多时候具有规律,比如说啊,我需要去一个房间拿一个苹果十次,那这样子的话,就是我不断去房间跳转拿苹果,这个其实是历史性的,那我们能不能就定义说?如果你前一次就是跳转的话,那我这次就跳转,
那这样的话,你如果循环十次的话,那只需要在一开始进入的时候不成功,那么出去的时候也预测失误,那这样子的话,我预测的准确率就是80%,也就是说我80%的指令能够不用等这一排,我就猜测我一定去那里拿地址,然后去让流水线走起来,20%则猜测错误,需要加上20%预测错误的时间成本,就需要把这条猜测错误的后续给删除掉,然后重新跳转到我们正确的指令
但是总体上来看,有这个猜测来说,还是能够加快我们的流水线计算,因为哦,我们在很多的一些逻辑事件中都是有一定的规律的
就刚才说的规律,有可能是周期反复,也有可能是指令间之间的相关,就是比如说我去了一个地方,那么我一定不会去另一个地方,那么我知道我去了第一个地方,那下一个地方,我就知道他一定是不去的,那么这样也是一种猜测。
cache
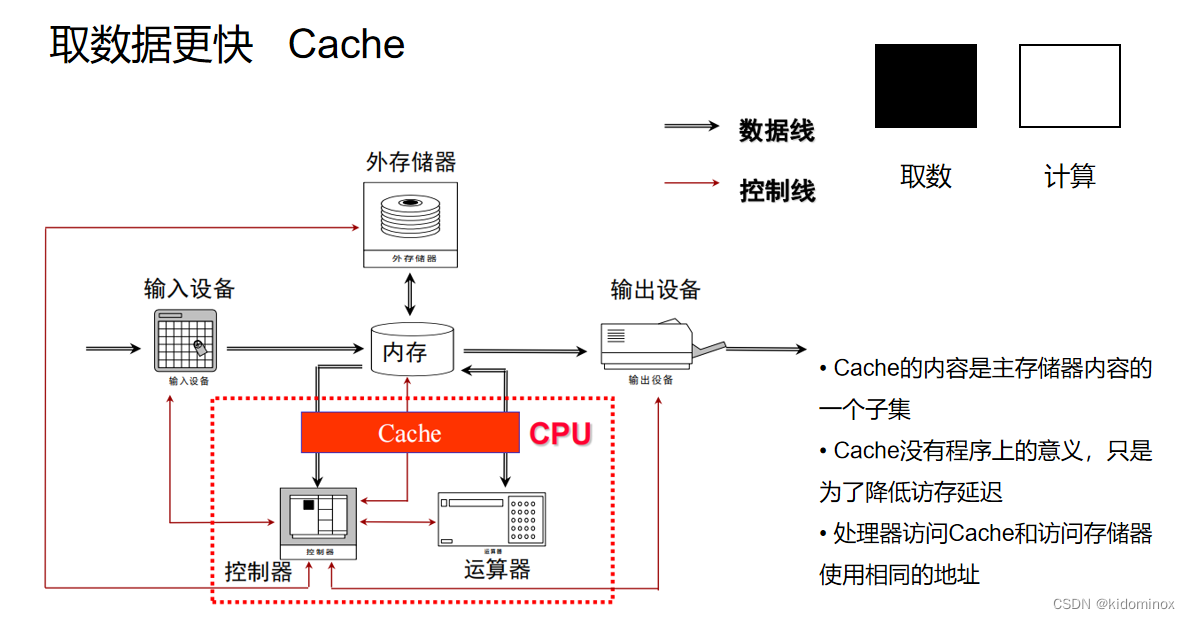
怎么去取数据更快呢?这里用case的一个技术,通过我之前的那个流水线的加速之后,我发现计算这方面他倒是很快了,但是在取数据这方面他很耗时,确实很长就会导致就是一直在取数据,取数这块,他一直耗着,但是计算那边已经很快的算好了,他就空闲了,那么怎么把这些空闲的时间利用上呢
因此,我们就需要在取数这方面进行一个优化,让他跟计算的时间能够相平衡,才能够把短板补上
而我们在这里,我们就采用了一个数据取数的一个过程,我们一般取数的话,我们都会用存储器内存去一个取数据,但是内存,存储器有一个规律
如果存储的越空间越大的话,他的访问速度会越慢 我们在计算机还是需要这些很大的存储数据,才能够满足我们的需求,那怎么办呢?我们就在CPU内部,再加一个更小的一个啊,存储空叫做cache,其实他其实是存储器里面的一个子集,而不是一个单纯额外的存储空间
是通过研究发现,有时候一些任务的时候,他会重复的去拿存储器中相同的数据,那么这些反复的数据我们就把它放到cache里面,然后这cache的话他就能够让CPU更快的拿取这些相同的数据,有些不常见的数据的话则放到更大的储存储内存里面,然后需要的话我们才去从把它从内存调到cache里面。
如果一个CPU,他需要拿100次4 KB的相同数据,那么那这4 KB的数据那我就的它加入到cache里面,那这样的话,我每次CPU都是只从cache里面去拿着4 KB的数据,但他就比之前的在内存中拿数据会快,如果不频繁的数据,那我就浪费点时间去内存拿数据就好了
TLB
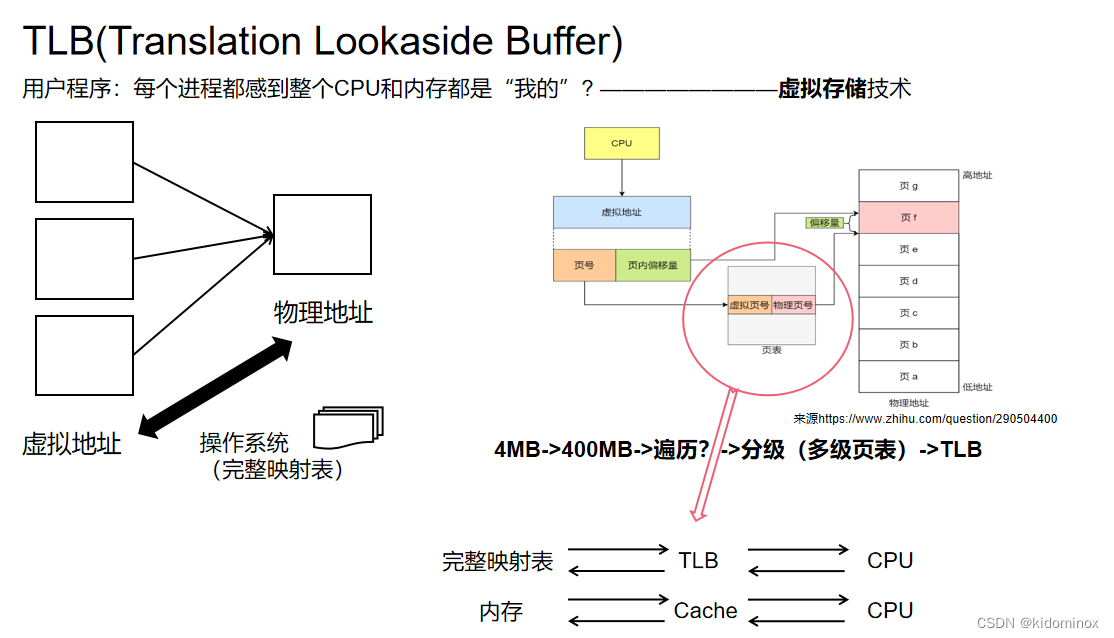
为了清晰的讲之后的整个计算机框架,我在这里再讲一个叫TLB的一个东西
他其实与操作系统相关。在日常中,我们发现我们电脑其实可以命名多个用户进行使用了,然后在那用户过程中的时候,我们发现好像这个cpu和内存都是我的,我都可以随便的用,当然这也是我们在日常生活中哦,存储盘会大于我们的需求的情况下,因此他们之间不会相互的影响
他其实就是一种虚拟存储技术,操作系统的构建了一个虚拟地址,每个进程都有自己的虚拟地址空间,然后操作系统他就会把这些虚拟地址去映射到磁盘上物理地址空间,那这份的映射表就由操作系统保存,而且也是由操作系统维护
那么CPU呢?它是需要将虚拟地址进行一个映射,映射成物理地址来进行寻址拿数据,但是假设一个程序,他所构建的虚拟空间映射物理空间的这张表页表是4M的话,那么,如果有100个程序在运行的话,那就是有400M,我们CPU再去拿到一个虚拟地址去映射到物理地址之后,那是不是就得去遍历这400M?如果把它放在一个大表里面的话,那他就需要去遍历这400M的映射表,然后去找到对应的物理地址,这是特别的耗时的,因此之后呢,就有人去提出了分级,但是就多了几道转换的工序,这就降低了低级转换的速度。这不是我们所需要的,我们就是要提高它的速度,因此呢,我就想你不能像Cache一样,弄一个更小的子集叫TLB,去存储我们的页表项。
所以呢,在CPU在进行虚拟物理地址转换的时候,他会先去查TLB,如果没有找到的话,再去查操作系统所保存的完整映射表。来提高它的速度。
总体架构
我们就把计算机体系结构的内容基本上讲完了,我们从一开始五级流水线,我们可以知道整个计算机在做计算的时候他是怎么流程。然后下面这张图是计算机的架构,他在五级流水基础上加上我们刚才说的提升他的速度一些结构,然后去组成了整个计算机架构。
具体可以看视频描述,或者大家通过上文也对这张图也有了清晰了解。














![P3029 [USACO11NOV]Cow Lineup S 双指针 单调队列](https://img-blog.csdnimg.cn/6af1894944f542299edaa735404b58a3.png)
![[MAUI]模仿iOS应用多任务切换卡片滑动的交互实现](https://img-blog.csdnimg.cn/6fca7de1f85646dc894e72f43390f317.gif)