文章目录
- 一、Oceanbase数据库简介
- 1.1 核心特性
- 1.2 系统架构
- 1.2.1 存储层
- 1.2.2 复制层
- 1.2.3 均衡层
- 1.2.4 事务层
- 1.2.4.1 原子性
- 1.2.4.2 隔离性
- 1.2.5 SQL 层
- 1.2.5.1 SQL 层组件
- 1.2.5.2 多种计划
- 1.2.6 接入层
- 二、OceanBase 数据库社区版部署
- 2.1 部署方式
- 2.2 基础环境配置
- 2.3 通过 OBD 白屏部署 OceanBase 集群
一、Oceanbase数据库简介
OceanBase 数据库是一款完全自研的企业级原生分布式数据库,在普通硬件上实现金融级高可用,首创“三地五中心”城市级故障自动无损容灾新标准,刷新 TPC-C 标准测试,单集群规模超过 1500 节点,具有云原生、强一致性、高度兼容 Oracle/MySQL 等特性。
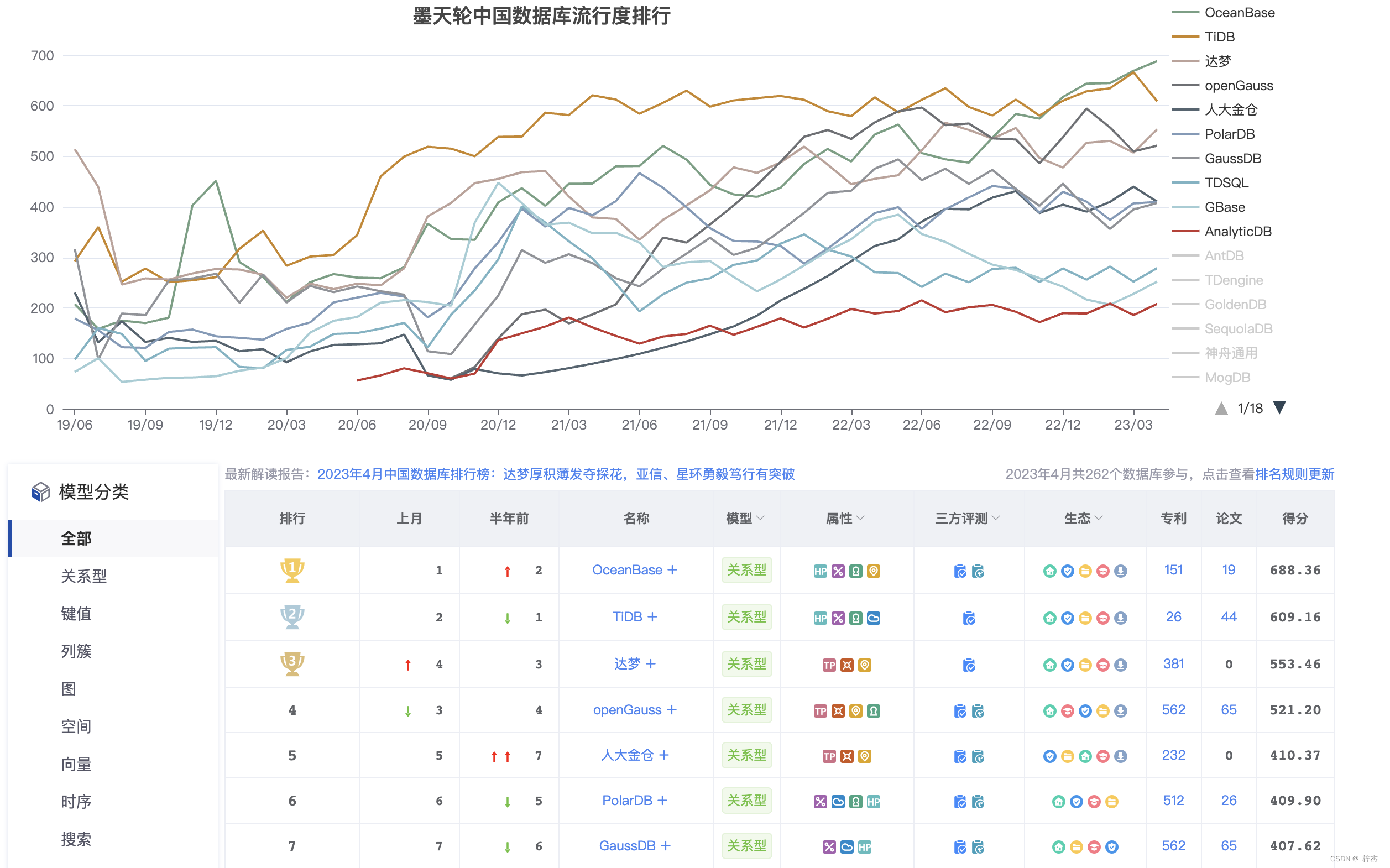
1.1 核心特性
-
高可用
独创 “三地五中心” 容灾架构方案,建立金融行业无损容灾新标准。支持同城/异地容灾,可实现多地多活,满足金融行业 6 级容灾标准(RPO=0,RTO< 8s),数据零丢失。 -
高兼容
高度兼容 Oracle 和 MySQL,覆盖绝大多数常见功能,支持过程语言、触发器等高级特性,提供自动迁移工具,支持迁移评估和反向同步以保障数据迁移安全,可支撑金融、政府、运营商等关键行业核心场景替代。 -
水平扩展
实现透明水平扩展,支持业务快速的扩容缩容,同时通过准内存处理架构实现高性能。支持集群节点超过数千个,单集群最大数据量超过 3PB,最大单表行数达万亿级。 -
低成本
基于 LSM-Tree 的高压缩引擎,存储成本降低 70% - 90%;原生支持多租户架构,同集群可为多个独立业务提供服务,租户间数据隔离,降低部署和运维成本。 -
实时 HTAP
基于“同一份数据,同一个引擎”,同时支持在线实时交易及实时分析两种场景,“一份数据”的多个副本可以存储成多种形态,用于不同工作负载,从根本上保持数据一致性。 -
安全可靠
12 年完全自主研发,代码级可控,自研单机分布式一体化架构,大规模金融核心场景 9 年可靠性验证;完备的角色权限管理体系,数据存储和通信全链路透明加密,支持国密算法,通过等保三级专项合规检测。
1.2 系统架构

OceanBase 使用通用服务器硬件,依赖本地存储,分布式部署使用的多个服务器也是对等的,没有特殊的硬件要求。OceanBase 的分布式数据库处理采用 Shared Nothing 架构,数据库内的 SQL 执行引擎具有分布式执行能力。
OceanBase 在服务器上会运行叫做 observer 的单进程程序作为数据库的运行实例,使用本地的文件存储数据和事务 Redo 日志。
OceanBase 集群部署需要配置可用区(Zone),由若干个服务器组成。可用区是一个逻辑概念,表示集群内具有相似硬件可用性的一组节点,它在不同的部署模式下代表不同的含义。例如,当整个集群部署在同一个数据中心(IDC)内的时候,一个可用区的节点可以属于同一个机架,同一个交换机等。当集群分布在多个数据中心的时候,每个可用区可以对应于一个数据中心。
用户存储的数据在分布式集群内部可以存储多个副本,用于故障容灾,也可以用于分散读取压力。在一个可用区内部数据只有一个副本,不同的可用区可以存储同一个数据的多个副本,副本之间由共识协议保证数据的一致性。
OceanBase 内置多租户特性,每个租户对于使用者是一个独立的数据库,一个租户能够在租户级别设置租户的分布式部署方式。租户之间 CPU、内存和 IO 都是隔离的。
OceanBase的数据库实例内部由不同的组件相互协作,这些组件从底层向上由存储层、复制层、均衡层、事务层、SQL 层、接入层组成。
1.2.1 存储层
存储层以一张表或者一个分区为粒度提供数据存储与访问,每个分区对应一个用于存储数据的Tablet(分片),用户定义的非分区表也会对应一个 Tablet。
Tablet 的内部是分层存储的结构,总共有 4 层。DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 L0 SSTable。L0 SSTable 个数达到阈值后会将多个 L0 SSTable 合并成一个 L1 SSTable。在每天配置的业务低峰期,系统会将所有的 MemTable、L0 SSTable 和 L1 SSTable 合并成一个 Major SSTable。
每个 SSTable 内部是以 2MB 定长宏块为基本单位,每个宏块内部由多个不定长微块组成。
Major SSTable 的微块会在合并过程中用编码方式进行格式转换,微块内的数据会按照列维度分别进行列内的编码,编码规则包括字典/游程/常量/差值等,每一列压缩结束后,还会进一步对多列进行列间等值/子串等规则编码。编码能对数据大幅压缩,同时提炼的列内特征信息还能进一步加速后续的查询速度。
在编码压缩之后,还可以根据用户指定的通用压缩算法进行无损压缩,进一步提升数据压缩率。
1.2.2 复制层
复制层使用日志流(LS、Log Stream)在多副本之间同步状态。每个 Tablet 都会对应一个确定的日志流,DML 操作写入 Tablet 的数据所产生的 Redo 日志会持久化在日志流中。日志流的多个副本会分布在不同的可用区中,多个副本之间维持了共识算法,选择其中一个副本作为主副本,其他的副本皆为从副本。Tablet 的 DML 和强一致性查询只在其对应的日志流的主副本上进行。
通常情况下,每个租户在每台机器上只会有一个日志流的主副本,可能存在多个其他日志流的从副本。租户的总日志流个数取决于 Primary Zone 和 Locality 的配置。
日志流使用自研的 Paxos 协议将 Redo 日志在本服务器持久化,同时通过网络发送给日志流的从副本,从副本在完成各自持久化后应答主副本,主副本在确认有多数派副本都持久化成功后确认对应的 Redo 日志持久化成功。从副本利用 Redo 日志的内容实时回放,保证自己的状态与主副本一致。
日志流的主副本在被选举成为主后会获得租约(Lease),正常工作的主副本在租约有效期内会不停的通过选举协议延长租约期。主副本只会在租约有效时执行主的工作,租约机制保证了数据库异常处理的能力。
复制层能够自动应对服务器故障,保障数据库服务的持续可用。如果出现少于半数的从副本所在服务器出现问题,因为还有多于半数的副本正常工作,数据库的服务不受影响。如果主副本所在服务器出现问题,其租约会得不到延续,待其租约失效后,其他从副本会通过选举协议选举出新的主副本并授予新的租约,之后即可恢复数据库的服务。
1.2.3 均衡层
新建表和新增分区时,系统会按照均衡原则选择合适的日志流创建 Tablet。当租户的属性发生变更,新增了机器资源,或者经过长时间使用后,Tablet 在各台机器上不再均衡时,均衡层通过日志流的分裂和合并操作,并在这个过程中配合日志流副本的移动,让数据和服务在多个服务器之间再次均衡。
当租户有扩容操作,获得更多服务器资源时,均衡层会将租户内已有的日志流进行分裂,并选择合适数量的 Tablet 一同分裂到新的日志流中,再将新日志流迁移到新增的服务器上,以充分利用扩容后的资源。当租户有缩容操作时,均衡层会把需要缩减的服务器上的日志流迁移到其他服务器上,并和其他服务器上已有的日志流进行合并,以缩减机器的资源占用。
当数据库长期使用后,随着持续创建删除表格,并且写入更多的数据,即使没有服务器资源数量变化,原本均衡的情况可能被破坏。最常见的情况是,当用户删除了一批表格后,删除的表格可能原本聚集在某一些机器上,删除后这些机器上的 Tablet 数量就变少了,应该把其他机器的 Tablet 均衡一些到这些少的机器上。均衡层会定期生成均衡计划,将 Tablet 多的服务器上日志流分裂出临时日志流并携带需要移动的 Tablet,临时日志流迁移到目的服务器后再和目的服务器上的日志流进行合并,以达成均衡的效果。
1.2.4 事务层
事务层保证了单个日志流和多个日志流DML操作提交的原子性,也保证了并发事务之间的多版本隔离能力。
1.2.4.1 原子性
一个日志流上事务的修改,即使涉及多个 Tablet,通过日志流的 write-ahead log 可以保证事务提交的原子性。事务的修改涉及多个日志流时,每个日志流会产生并持久化各自的write-ahead log,事务层通过优化的两阶段提交协议来保证提交的原子性。
事务层会选择一个事务修改的一个日志流产生协调者状态机,协调者会与事务修改的所有日志流通信,判断 write-ahead log 是否持久化,当所有日志流都完成持久化后,事务进入提交状态,协调者会再驱动所有日志流写下这个事务的 Commit 日志,表示事务最终的提交状态。当从副本回放或者数据库重启时,已经完成提交的事务都会通过 Commit 日志确定各自日志流事务的状态。
宕机重启场景下,宕机前还未完成的事务,会出现写完 write-ahead log 但是还没有Commit 日志的情况,每个日志流的 write-ahead log 都会包含事务的所有日志流列表,通过此信息可以重新确定哪个日志流是协调者并恢复协调者的状态,再次推进两阶段状态机,直到事务最终的 Commit 或 Abort 状态。
1.2.4.2 隔离性
GTS 服务是一个租户内产生连续增长的时间戳的服务,其通过多副本保证可用性,底层机制与上面复制层所描述的日志流副本同步机制是一样的。
每个事务在提交时会从 GTS 获取一个时间戳作为事务的提交版本号并持久化在日志流的write-ahead log 中,事务内所有修改的数据都以此提交版本号标记。
每个语句开始时(对于 Read Committed 隔离级别)或者每个事务开始时(对于Repeatable Read 和 Serializable 隔离级别)会从 GTS 获取一个时间戳作为语句或事务的读取版本号。在读取数据时,会跳过事务版本号比读取版本号大的数据,通过这种方式为读取操作提供了统一的全局数据快照。
1.2.5 SQL 层
SQL 层将用户的 SQL 请求转化成对一个或多个 Tablet 的数据访问。
1.2.5.1 SQL 层组件
SQL 层处理一个请求的执行流程是:Parser、Resolver、Transformer、Optimizer、Code Generator、Executor。
Parser 负责词法/语法解析,Parser 会将用户的 SQL 分成一个个的 “Token”,并根据预先设定好的语法规则解析整个请求,转换成语法树(Syntax Tree)。
Resolver 负责语义解析,将根据数据库元信息将 SQL 请求中的 Token 翻译成对应的对象(例如库、表、列、索引等),生成的数据结构叫做 Statement Tree。
Transformer 负责逻辑改写,根据内部的规则或代价模型,将 SQL 改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer 的工作方式是在原Statement Tree 上做等价变换,变换的结果仍然是一棵 Statement Tree。
Optimizer(优化器)为 SQL 请求生成最佳的执行计划,需要综合考虑 SQL 请求的语义、对象数据特征、对象物理分布等多方面因素,解决访问路径选择、联接顺序选择、联接算法选择、分布式计划生成等问题,最终生成执行计划。
Code Generator(代码生成器)将执行计划转换为可执行的代码,但是不做任何优化选择。
Executor(执行器)启动 SQL 的执行过程。
在标准的 SQL 流程之外,SQL 层还有 Plan Cache 能力,将历史的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程。配合 Fast-parser 模块,仅使用词法分析对文本串直接参数化,获取参数化后的文本及常量参数,让 SQL 直接命中 Plan Cache,加速频繁执行的 SQL。
1.2.5.2 多种计划
SQL 层的执行计划分为本地、远程和分布式三种。本地执行计划只访问本服务器的数据。远程执行计划只访问非本地的一台服务器的数据。分布式计划会访问超过一台服务器的数据,执行计划会分成多个子计划在多个服务器上执行。
SQL 层并行化执行能力可以将执行计划分解成多个部分,由多个执行线程执行,通过一定的调度的方式,实现执行计划的并行处理。并行化执行可以充分发挥服务器 CPU 和 IO 处理能力,缩短单个查询的响应时间。并行查询技术可以用于分布式执行计划,也可以用于本地执行计划。
1.2.6 接入层
obproxy 是 OceanBase 数据库的接入层,负责将用户的请求转发到合适的 OceanBase 实例上进行处理。
obproxy 是独立的进程实例,独立于 OceanBase 的数据库实例部署。obproxy 监听网络端口,兼容 MySQL 网络协议,支持使用 MySQL 驱动的应用直接连接 OceanBase。
obproxy 能够自动发现 OceanBase 集群的数据分布信息,对于代理的每一条 SQL 语句,会尽可能识别出语句将访问的数据,并将语句直接转发到数据所在服务器的 OceanBase 实例。
obproxy 有两种部署方式,一种是部署在每一个需要访问数据库的应用服务器上,另一种是部署在与 OceanBase 相同的机器上。第一种部署方式下,应用程序直接连接部署在同一台服务器上的 obproxy,所有的请求会由 obproxy 发送到合适的 OceanBase 服务器。第二种部署方式下,需要使用网络负载均衡服务将多个 obproxy 聚合成同一个对应用提供服务的入口地址。
二、OceanBase 数据库社区版部署
2.1 部署方式
快速部署
- 对于非原生支持的操作系统(比如 MAC 和 Windows),建议使用 Docker 镜像的方式进行部署;
- 对于原生支持的操作系统(Linux 系列,具体见支持的操作系统列表),建议使用 OBD 进行部署;
标准部署 - 对于线下环境,建议使用 OBD 进行标准部署
- 对于 kubernetes 环境,建议使用 ob-operator 的方式部署;
在生产环境中,需要进行标准化部署,本文
2.2 基础环境配置
软硬件要求参考官方文档:https://www.oceanbase.com/docs/common-oceanbase-database-cn-10000000001692940
所有的机器使用相同的软硬件配置
设置无密码 SSH 登录
配置ntp始终
配置 limits.conf
在 /etc/security/limits.conf 配置文件中添加以下内容:
root soft nofile 655350
root hard nofile 655350
* soft nofile 655350
* hard nofile 655350
* soft stack 20480
* hard stack 20480
* soft nproc 655360
* hard nproc 655360
* soft core unlimited
* hard core unlimited
配置 sysctl.conf
在 /etc/sysctl.conf 配置文件中添加以下内容:
# for oceanbase
## 修改内核异步 I/O 限制
fs.aio-max-nr=1048576
## 网络优化
net.core.somaxconn = 2048
net.core.netdev_max_backlog = 10000
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.ip_local_port_range = 3500 65535
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_fin_timeout = 15
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_slow_start_after_idle=0
vm.swappiness = 0
vm.min_free_kbytes = 2097152
# 此处为 OceanBase 数据库的 data 目录
kernel.core_pattern = /data/core-%e-%p-%t
其中,kernel.core_pattern 中的 /data 为 OceanBase 数据库的 data 目录。如果您只是测试,您可以只设置 fs.aio-max-nr=1048576。
sysctl -p
关闭防火墙和 SELinux
关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
systemctl status firewalld
关闭 SELinux
执行以下命令,打开 /etc/selinux/config 配置文件:
vi /etc/selinux/config
在 /etc/selinux/config 配置文件中修改对应配置项为以下内容:
SELINUX=disabled
执行以下命令或重启服务器,使更改生效:
setenforce 0
执行以下命令,查看更改是否生效:
sestatus
关闭透明大页
echo never > /sys/kernel/mm/transparent_hugepage/enabled
关闭防火墙和 SELinux
systemctl disable firewalld
systemctl stop firewalld
systemctl status firewalld
在 /etc/selinux/config 配置文件中修改对应配置项为以下内容:
SELINUX=disabled
执行以下命令或重启服务器,使更改生效:
setenforce 0
执行以下命令,查看更改是否生效:
sestatus
创建用户
#创建账户 admin
useradd -U admin -d /home/admin -s /bin/bash
mkdir -p /home/admin
chown -R admin:admin /home/admin
passwd admin
在/etc/sudoers添加如下内容:
# %wheel ALL=(ALL) NOPASSWD: ALL
admin ALL=(ALL) NOPASSWD: ALL
修改集群相关文件所属用户
#数据盘,数据盘用来存储基线数据,路径由配置参数 data_dir 指定。在您首次启动 OceanBase 集群时,${data_dir}/sstable 将自动创建。数据盘的大小由 datafile_disk_percentage/datafile_size 参数决定。
chown -R admin:admin /data/ob_data
#事务日志盘,事务日志盘的路径由配置参数 redo_dir 指定。建议您将事务日志盘的大小设置为 OceanBase 数据库内存的 3 倍到 4 倍及以上。事务日志盘包含多个固定大小的文件。这些文件位于安装目录 ${redo_dir}/{clog,ilog,slog} 下。您可以根据您的需要自动创建和清除事务日志。事务日志达到磁盘总量的 80% 时,将触发自动清除。但是,只有在事务日志对应的内存数据已经合并融至基线数据中时,事务日志才能被删除。在相同数据量的情况下,事务日志的大小约为内存数据大小的三倍。因此事务日志盘所需空间上限与两次合并后的数据总量成正比。经验公式:事务日志文件大小 = 增量数据内存上限的 3~4 倍。
chown -R admin:admin /data/ob_redo
#OceanBase 数据库安装盘,OceanBase 数据库安装盘的路径由配置参数 home_path 指定。建议您为 OceanBase 数据库安装盘预留至少 200 G 空间以保存 7 天及以上的日志。OceanBase 数据库的 RPM 包安装目录位于 ${home_path} 下。其中,基线数据文件和事务日志文件会通过软链接分别指向独立的数据盘和事务日志盘。OceanBase 数据库的运行日志位于 ${home_path}/log 下。运行日志会不断增长,并且 OceanBase 数据库无法自动删除运行日志,因此您需要定时删除运行日志。
chown -R admin:admin /data/ob_base
安装java
yum install java-1.8.0-openjdk -y
备注:
下载 OceanBase 4.1,请访问:https://www.oceanbase.com/softwarecenter
OceanBase 4.1 版本技术文档:https://www.oceanbase.com/docs/common-oceanbase-database-cn-10000000001698791)
2.3 通过 OBD 白屏部署 OceanBase 集群
#中控机
#下载并安装 all-in-one
https://www.oceanbase.com/softwarecenter
tar -xzf oceanbase-all-in-one-*.tar.gz
cd oceanbase-all-in-one/bin/
./install.sh
source ~/.oceanbase-all-in-one/bin/env.sh
#启动前端
obd web
进行配置

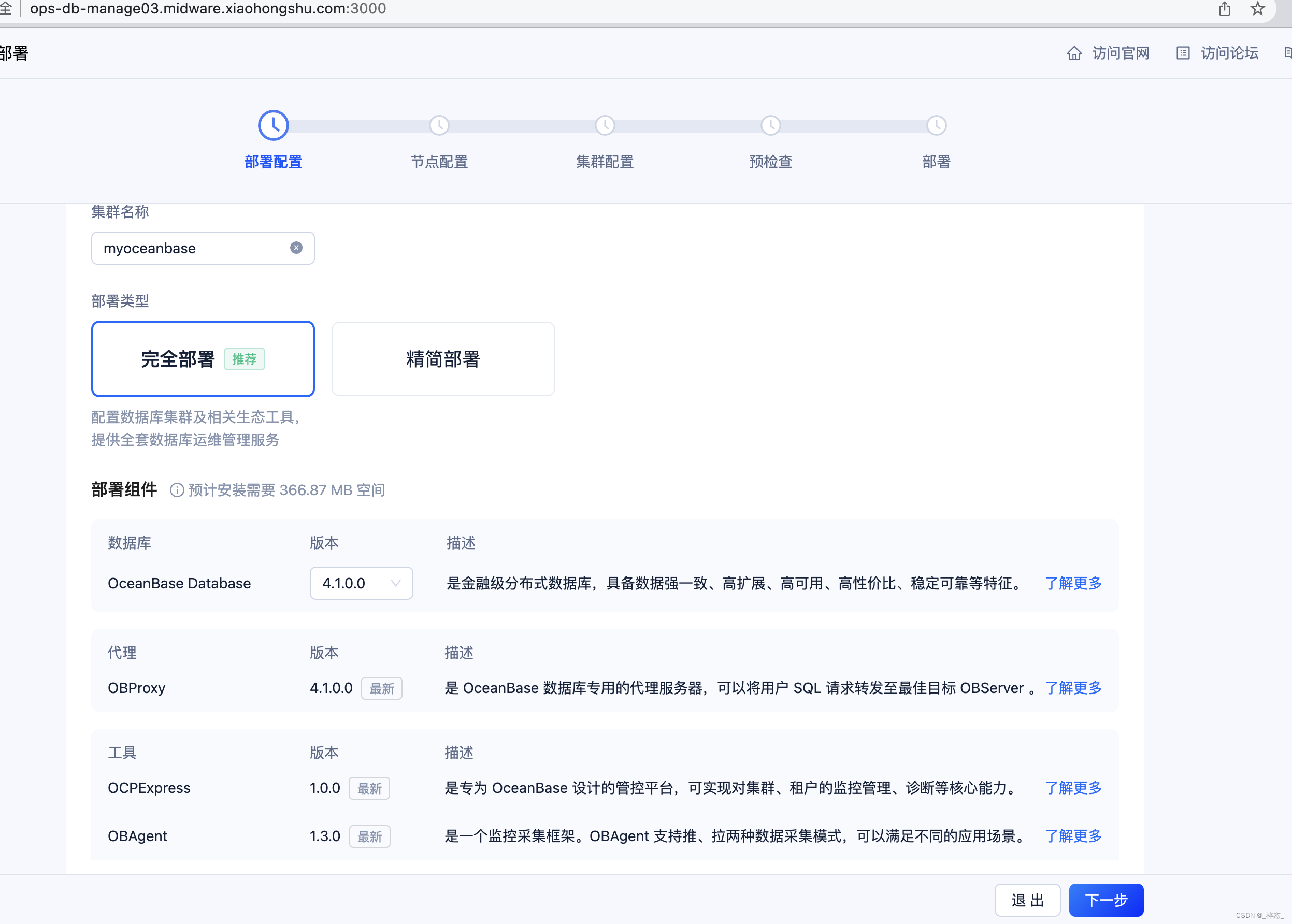
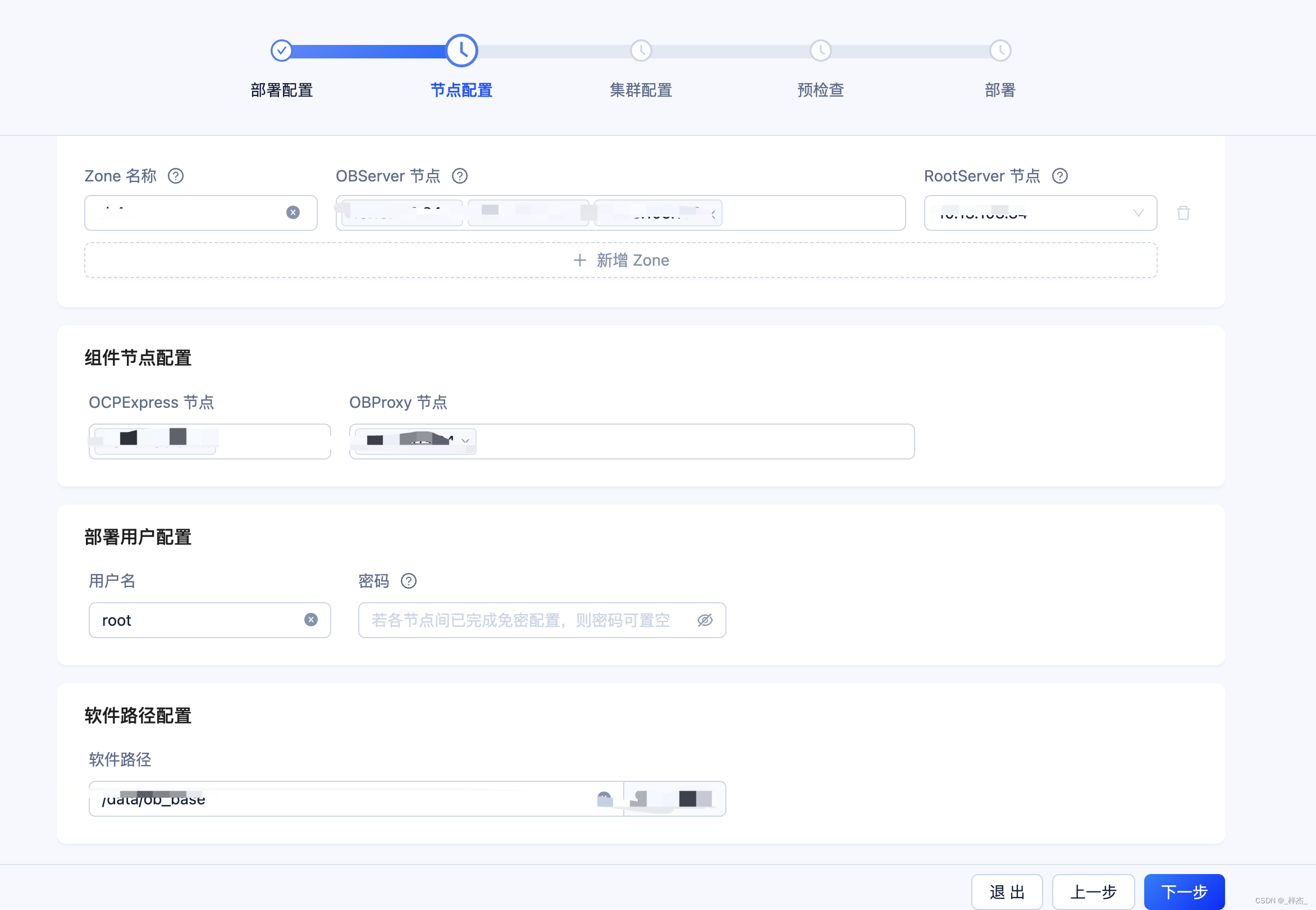
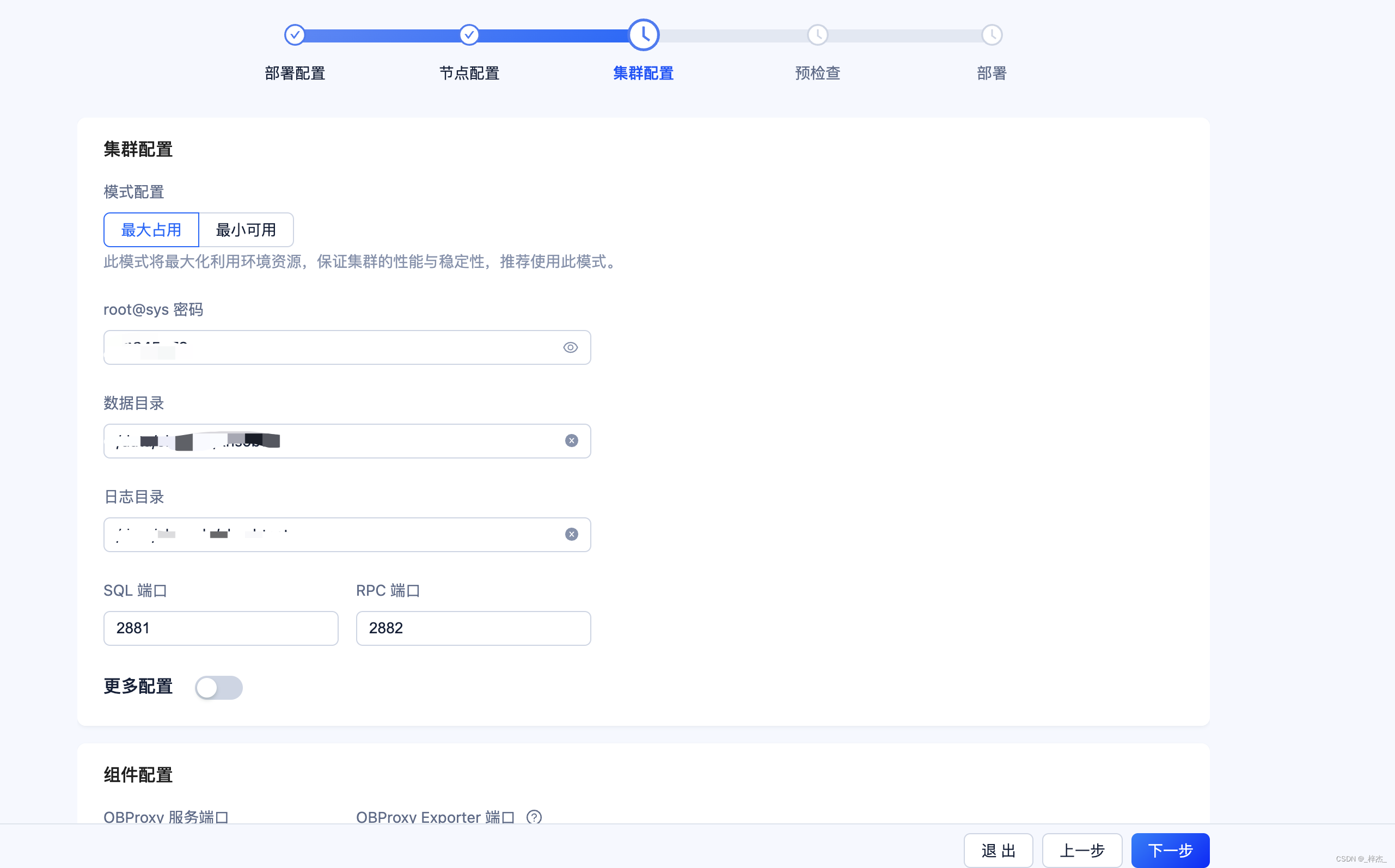
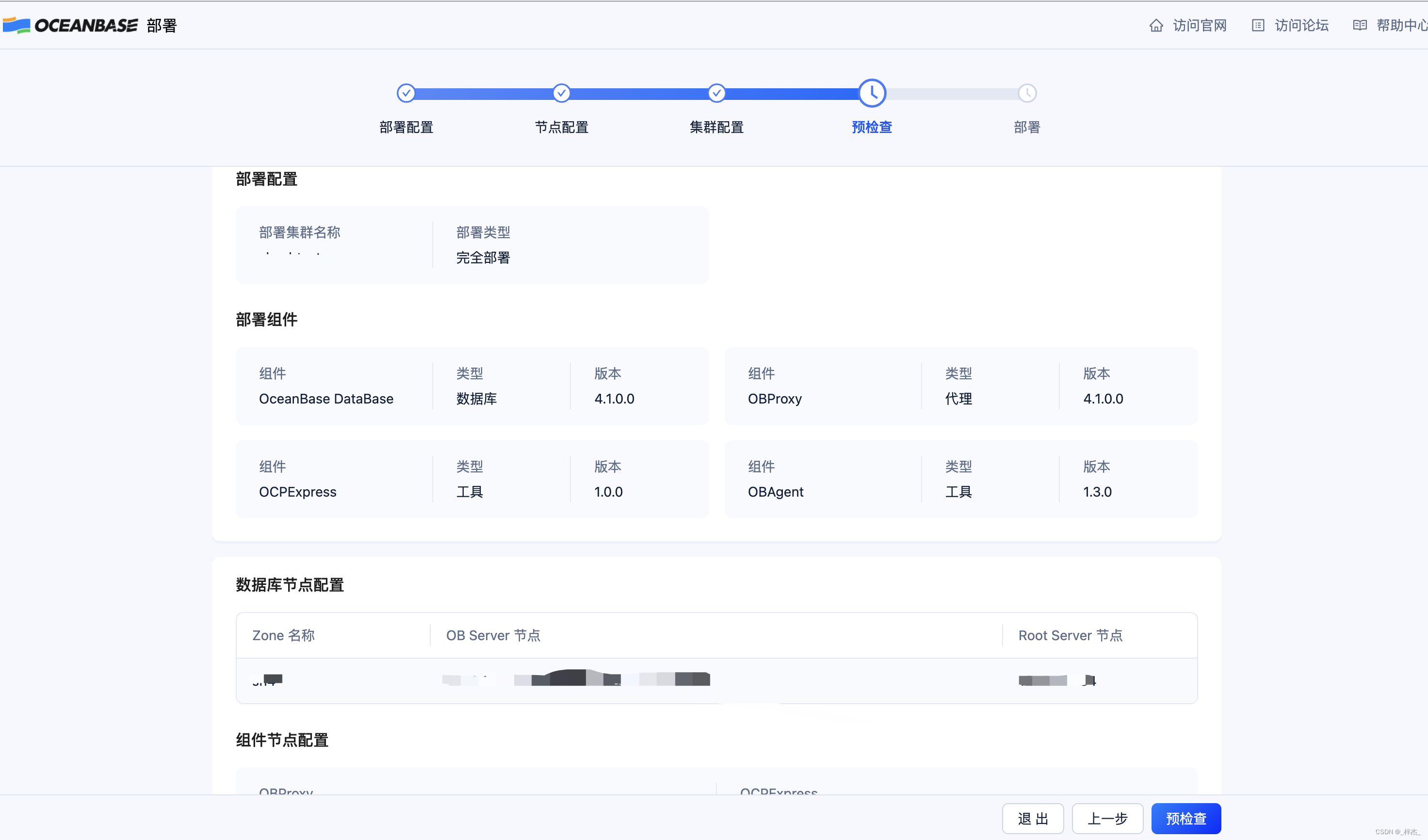
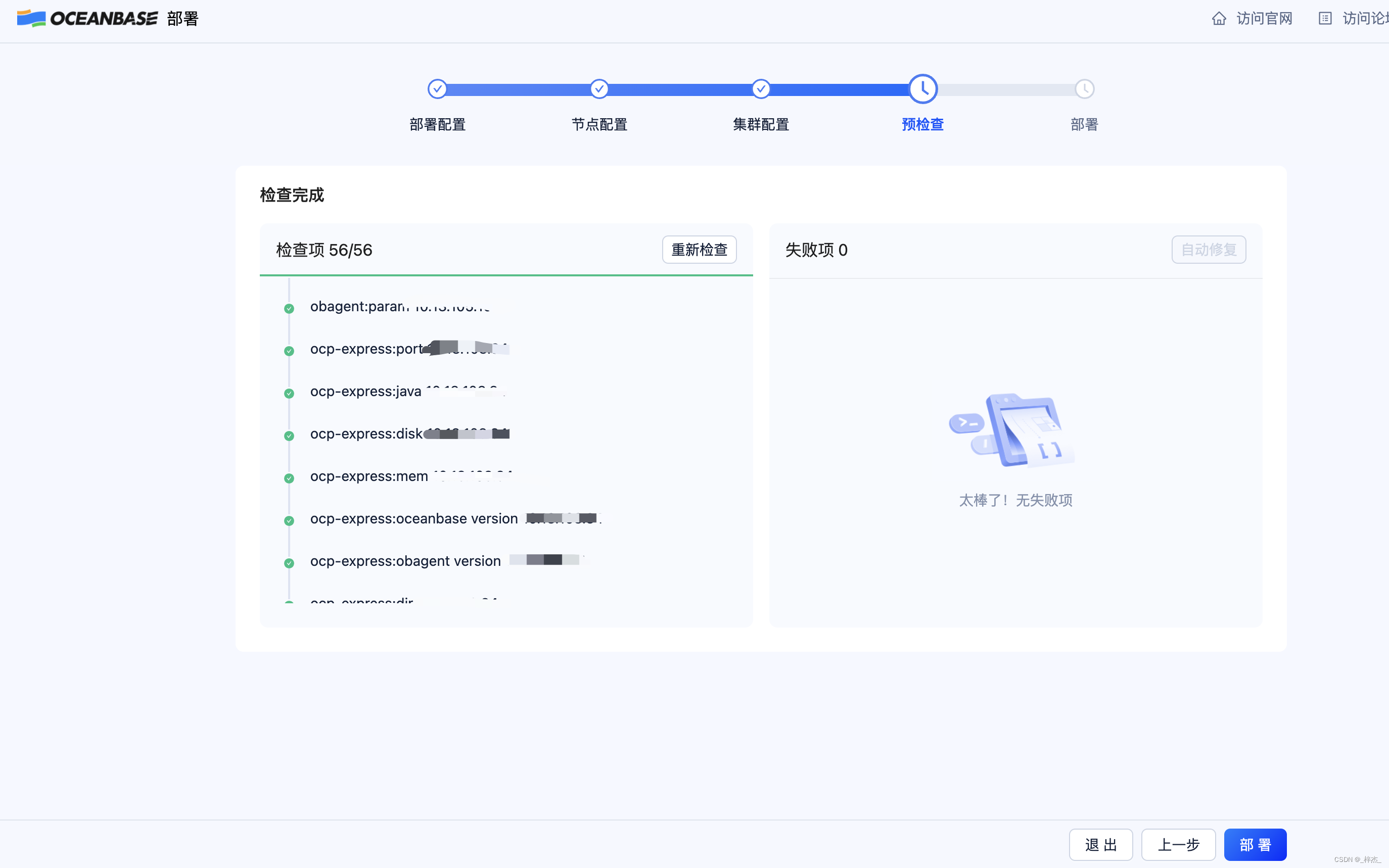
预检查
部署



# 查看集群列表
obd cluster list
# 查看集群状态,以部署名为 myoceanbase 为例
obd cluster display xxx
# 停止运行中的集群,以部署名为 myoceanbase 为例
obd cluster stop xxx
# 销毁已部署的集群,以部署名为 myoceanbase 为例
obd cluster destory xxx







![P3029 [USACO11NOV]Cow Lineup S 双指针 单调队列](https://img-blog.csdnimg.cn/6af1894944f542299edaa735404b58a3.png)
![[MAUI]模仿iOS应用多任务切换卡片滑动的交互实现](https://img-blog.csdnimg.cn/6fca7de1f85646dc894e72f43390f317.gif)





![[网络原理] HTTP协议](https://img-blog.csdnimg.cn/0165697193564bd7ae9aefb62d133e0a.png)