文章目录
- 【小样本分割 2020 TPAMI 】PFENet
- 1. 简介
- 1.1 问题
- 1) 高级特征误用造成的泛化损失
- 2) 查询样本和空间样本之间的空间不一致
- 1.2 方法
- 2. 网络
- 2.1 整体架构
- 2.2 先验掩膜生成
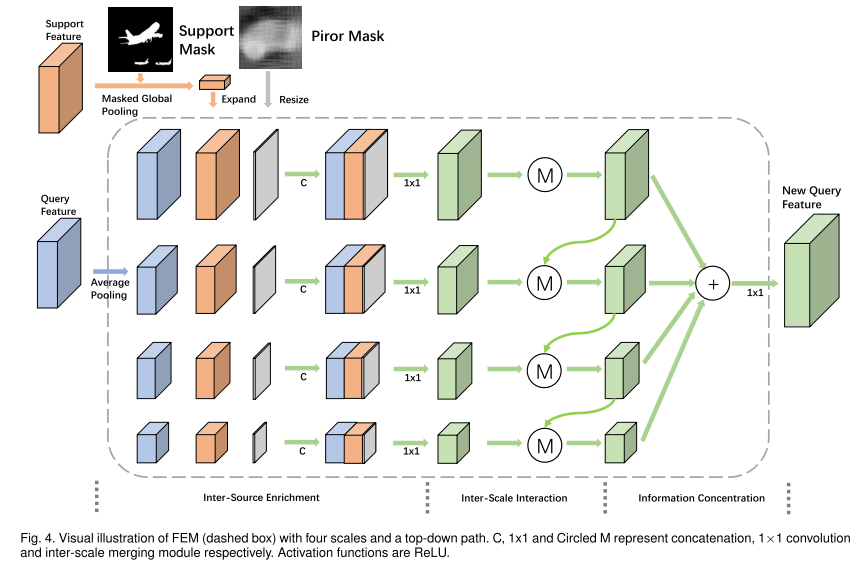
- 2.3 FEM模块
- 3. 代码
【小样本分割 2020 TPAMI 】PFENet
论文题目:Prior Guided Feature Enrichment Network for Few-Shot Segmentation
中文题目:先验引导的特征富集网络的小样本语义分割
论文链接:https://arxiv.org/abs/2008.01449
论文代码:https://github.com/Jia-Research-Lab/PFENet/
论文团队:香港中文大学
发表时间:2020年8月
DOI:
引用:Tian Z, Zhao H, Shu M, et al. Prior guided feature enrichment network for few-shot segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2020, 44(2): 1050-1065.
引用数:219【截止时间:2023年5月1号】
1. 简介
小样本分割的挑战:现有的小样本分割方法普遍存在
高级特征误用造成的泛化损失以及查询样本与支持样本的空间不一致等问题。
1.1 问题
1) 高级特征误用造成的泛化损失
CANet的实验表明,使用
中层特征比使用高层特征,实验性能更好。在小样本模型的特征处理过程中简单地添加高级特征会导致性能下降。
- CANet论文的理由:中层特征是由看不见的类共享的对象部分组成,可能蕴含着未知类别的特征。
- 本文认为的理由:
- 高层特征中包含的语义信息比中间层特征更class-specific(特定于类),所以高层特征更有可能使模型对未见类的泛化能力产生负面影响。
- 高层特征直接提供语义信息,在识别属于训练类别的像素和减少训练损失上的贡献大于中层特征,从而导致对训练类的偏爱。
因此,在小样本设置中利用语义信息的方式并不简单。与以前的方法不同,我们使用ImageNet预先训练的查询的高级特征,并支持图像为模型生成“先验”。这些先验有助于模型更好地识别查询图像中的目标。
由于先前的生成过程是无训练的,因此生成的模型不会失去对看不见的类的泛化能力,尽管在训练过程中频繁使用看到的类的高级信息。
2) 查询样本和空间样本之间的空间不一致
现有大多方法利用掩膜全局平均池化从训练图像中提取类别向量。但是,因为查询图像中的目标可能会比支持样本大得多或小得多,或者姿态相差很大,所以使用全局平均池化会导致空间信息不一致。
由于样本有限,每个支持
对象的比例和姿态可能与其查询目标存在很大差异,我们称之为空间不一致性。
1.2 方法
针对高层特征误用导致的泛化损失问题 —— 先验泛化方法
利用查询和支持图像的高层特征来生成模型的“先验值”(无需训练)
- 先验信息有助于模型更好地识别查询图像;
- 高层特征是从预先训练的ImageNet中得到的,
- 所以生成先验的过程并没有增加额外的训练过程,所以生成的模型不会失去对未见类的泛化能力。极大地提高了预测精度,保持了高泛化性
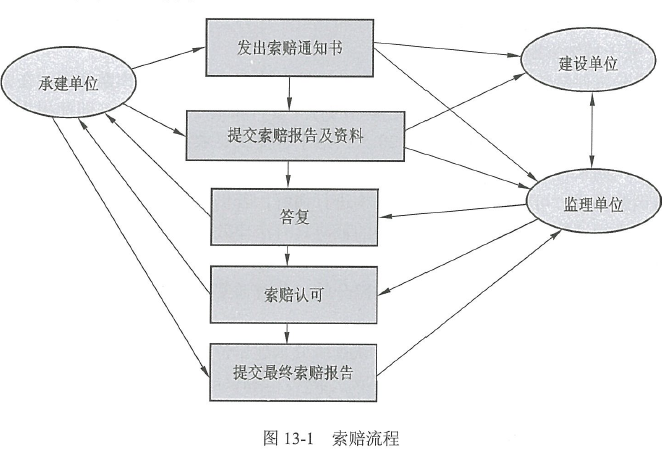
针对支持和查询样本空间不一致问题 —— FEM方法
通过整合支持特征和先验信息,利用条件化的跨尺度信息交互自适应地丰富查询特征
水平地交互查询特征与每个尺度中的支持特征和先验掩码
垂直利用层次关系,通过自顶向下的信息路径,从精细特征中提取必要信息,丰富粗特征图
水平和垂直优化后,收集不同尺度的特征,形成新的查询特征
2. 网络
2.1 整体架构
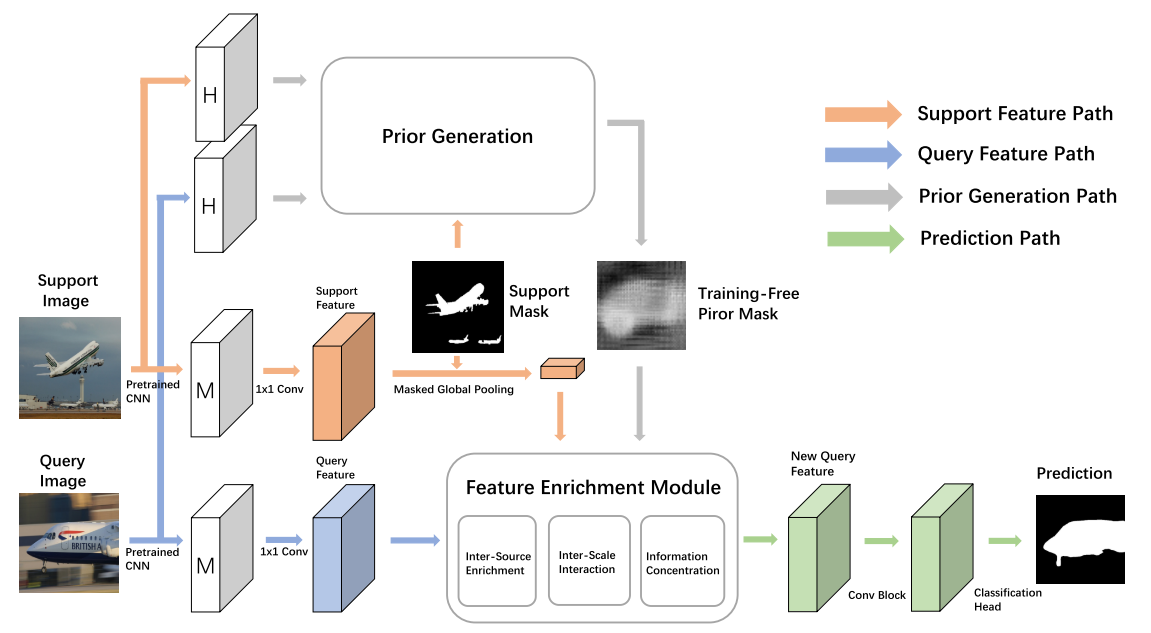
- 通过预训练的CNN,分别得到支持图像和查询图像的高层特征和中层特征。
- 利用中层特征生成查询和支持特征。
- 利用高层特征生成先验掩膜。
- 特征富集模块(FEM)利用支持特征和先验掩膜丰富查询特征。
- 损失函数: L = σ n ∑ i = 1 n L 1 i + L 2 , \mathcal{L}=\dfrac{\sigma}{n}\sum_{i=1}^n\mathcal{L}_1^i+\mathcal{L}_2, L=nσ∑i=1nL1i+L2,不同空间大小在New Query feature上的损失 + 最后的预测损失
2.2 先验掩膜生成
目的:将高层特征转化为先验掩膜(prior mask)
- 先验掩膜:像素属于目标类的概率。具体来说,揭示查询特征和支持特征之间像素级的对应关系。掩膜上的一个高值像素表明对应的查询像素与支持特征中的至少一个像素具有高对应关系。所以此像素很可能处于查询图像的目标区域。
- 此处的支持特征背景被设为0,所以查询特征的像素与支持特征上的背景没有对应关系。
设
I
Q
,
I
S
I_Q,I_S
IQ,IS表示输入查询和支持图像,
M
S
M_S
MS表示二进制支持掩码,
F
\mathcal{F}
F表示骨干网络,并且
X
Q
,
X
S
X_Q,X_S
XQ,XS表示高级查询和支持特征。
X
Q
=
F
(
I
Q
)
,
X
S
=
F
(
I
S
)
⊙
M
S
,
X_Q=\mathcal{F}(I_Q),\quad X_S=\mathcal{F}(I_S)\odot M_S,
XQ=F(IQ),XS=F(IS)⊙MS,
计算查询特征
X
Q
X_Q
XQ和
X
S
X_S
XS每个像素间的余弦相似度。
c
o
s
(
x
q
,
x
s
)
=
x
q
T
x
s
∥
x
q
∥
∥
x
s
∥
q
,
s
∈
{
1
,
2
,
.
.
.
,
h
w
}
cos(x_q,x_s)=\dfrac{x_q^Tx_s}{\|x_q\|\|x_s\|}\quad q,s\in\{1,2,...,hw\}
cos(xq,xs)=∥xq∥∥xs∥xqTxsq,s∈{1,2,...,hw}
取所有支持像素中最大相似度作为响应值
c
q
c_q
cq
c
q
=
max
s
∈
{
1
,
2
,
.
.
.
,
h
w
}
(
c
o
s
(
x
q
,
x
s
)
)
,
C
Q
=
[
c
1
,
c
2
,
.
.
.
,
c
h
w
]
∈
R
h
w
×
1
.
\begin{array}{rcl}c_q&=&\max_{s\in\{1,2,...,hw\}}(cos(x_q,x_s)),\\ C_Q&=&[c_1,c_2,...,c_{hw}]\in\mathbb{R}^{hw\times1}.\end{array}
cqCQ==maxs∈{1,2,...,hw}(cos(xq,xs)),[c1,c2,...,chw]∈Rhw×1.
归一化处理。
Y
Q
=
Y
Q
−
min
(
Y
Q
)
max
(
Y
Q
)
−
min
(
Y
Q
)
+
ϵ
.
Y_Q=\dfrac{Y_Q-\min(Y_Q)}{\max(Y_Q)-\min(Y_Q)+\epsilon}.
YQ=max(YQ)−min(YQ)+ϵYQ−min(YQ).
2.3 FEM模块
输入:查询特征、支持特征、先验掩膜
输出:新的查询特征
分为三个过程:Inter-Source Enrichment、Inter-Scale Interaction、Information Concentration。
3. 代码
参考资料
(2条消息) 【小样本分割】PFENet_Herbst_Loch的博客-CSDN博客