1.哈希
1.1 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- **搜索元素 **
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
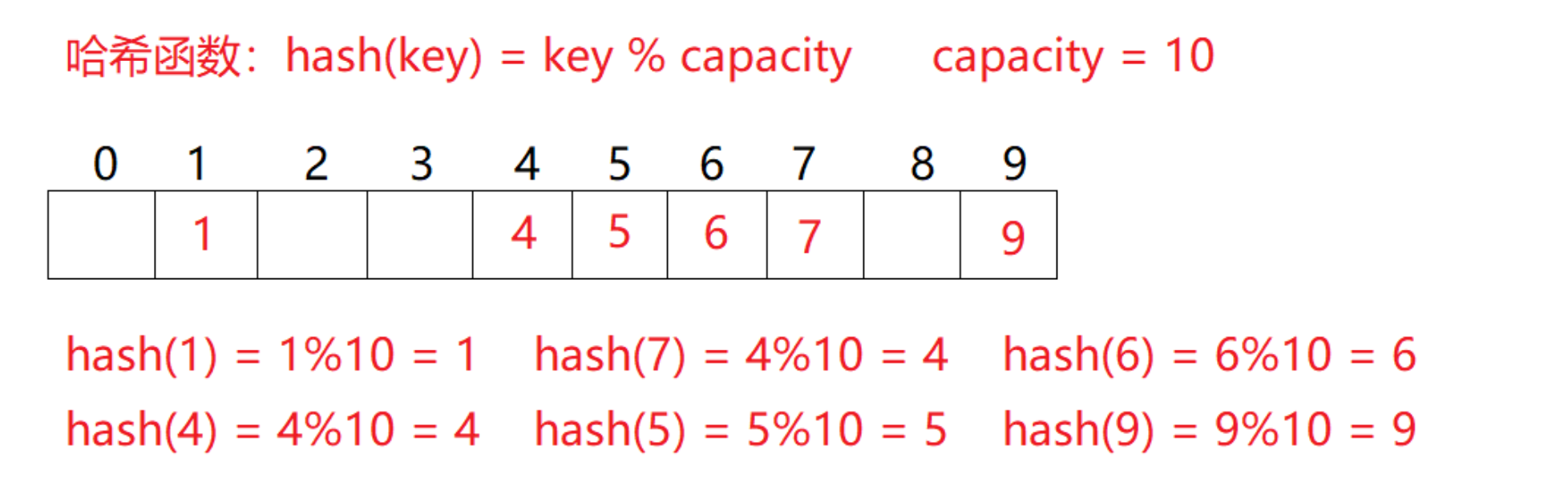
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
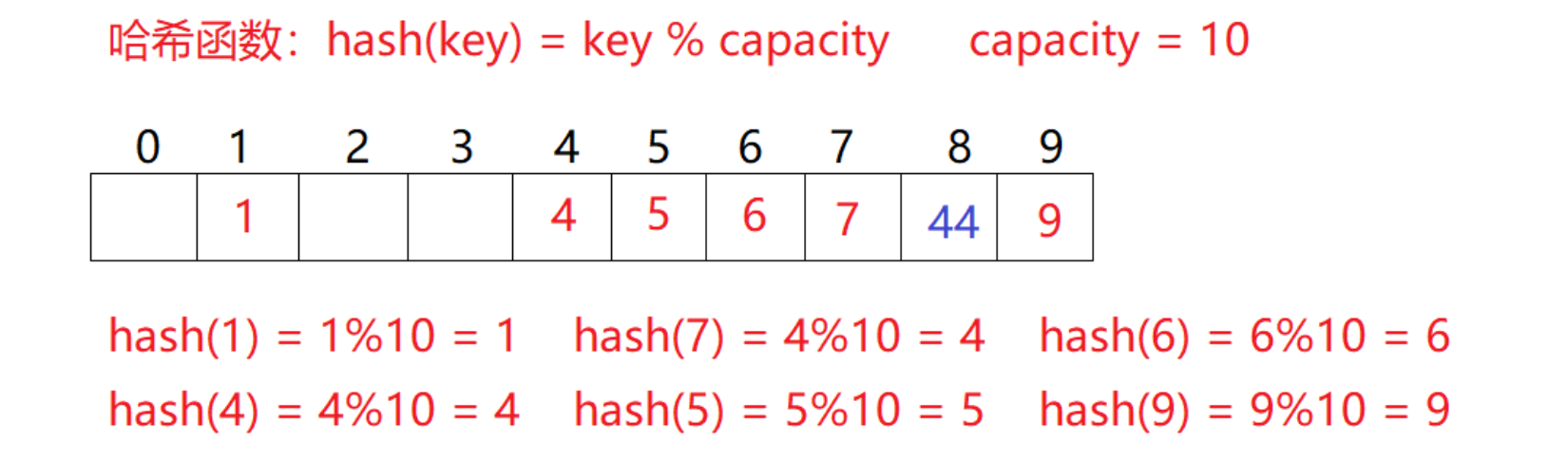
但是同样存在一定的问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?
很明显,hash(44)=44%10=4,那么就会和4发生冲突,而这样的问题就叫做哈希冲突
1.2 哈希冲突
对于两个数据元素的关键字 k i k_i ki和 k j k_j kj(i != j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) ==Hash( k j k_j kj),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
发生哈希冲突该我们该如何进行处理呢?
这就要引入一个概念:哈希函数
1.3 哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
- 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
- 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
- 位运算法(Bitwise Hashing)
对 key 进行位运算,比如使用异或运算或与运算等,得到的结果作为索引。该方法适用于 key 是二进制数的情况。
- 字符串哈希函数
对于字符串类型的 key,常见的哈希函数有 BKDR Hash、DJB Hash、FNV Hash 等。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
1.4 哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
1.4.1 闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
- 线性探测
比如1.1中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
-
插入
-
通过哈希函数获取待插入元素在哈希表中的位置
-
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
-
-
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素
// 哈希表每个空间给个标记 // EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除 enum State{EMPTY, EXIST, DELETE};
线性探测的实现
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
template<class K>
class HashFunc//仿函数
{
public:
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>//对string类型特化
class HashFunc<string>
{
public:
size_t operator()(const string& str)
{
size_t hash = 0;
for (auto e : str)
{
hash *= 131;
hash += e;
}
return hash;
}
};
namespace hdm
{
enum State
{
EMPTY,//空
DELETE,//删除
EXIST,//存在
};
template<class K,class V>
class HashData
{
public:
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K,class V,class Hash=HashFunc<K>>
class HashTable
{
public:
typedef HashData<K, V> Data;
HashTable():_n(0),_tables(10){}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
return false;
if (_n * 10 / _tables.size() >= 7)//负载因子大于0.7就扩容--下面有解释
{
//扩容
HashTable<K, V> newTable;
newTable._tables.resize(_tables.size() * 2);
for (auto e : _tables)
{
if (e._state == EXIST)
{
newTable.Insert(e._kv);
}
}
_tables.swap(newTable._tables);
}
size_t hashi = Hash()(kv.first) % _tables.size();
while (_tables[hashi]._state == EXIST)
{
//线性探测
++hashi;
hashi %= _tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n;
return true;
}
Data* Find(const K&key)
{
size_t hashi = Hash()(key) % _tables.size();
size_t starti=hashi;
while (_tables[hashi]._state != EMPTY)
{
if (_tables[hashi]._state == EXIST
&& _tables[hashi]._kv.first == key)
{
return &_tables[hashi];
}
++hashi;
hashi %= _tables.size();
if(hashi==start)//防止极端情况下,没有空的位置,大部分是DELETE和EXIST,最多让它走一圈
break;
}
return nullptr;
}
bool Erase(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
while (_tables[hashi]._state == EXIST)
{
if (_tables[hashi]._kv.first == key)
{
_tables[hashi]._state = DELETE;
return true;
}
++hashi;
hashi %= _tables.size();
}
return false;
}
private:
vector<Data> _tables;
size_t _n;
};
//
///测试代码
void TestHT1()
{
HashTable<int, int> ht;
int a[] = { 18, 8, 7, 27, 57, 3, 38, 18 };
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(17, 17));
ht.Insert(make_pair(5, 5));
cout << ht.Find(7) << endl;
cout << ht.Find(8) << endl;
ht.Erase(7);
cout << ht.Find(7) << endl;
cout << ht.Find(8) << endl;
}
void TestHT2()
{
string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
//HashTable<string, int, HashFuncString> countHT;
HashTable<string, int> countHT;
for (auto& e : arr)
{
HashData<string, int>* ret = countHT.Find(e);
if (ret)
{
ret->_kv.second++;
}
else
{
countHT.Insert(make_pair(e, 1));
}
}
HashFunc<string> hf;
cout << hf("abc") << endl;
cout << hf("bac") << endl;
cout << hf("cba") << endl;
cout << hf("aad") << endl;
}
}
思考:哈希表什么情况下进行扩容?如何扩容?

线性探测优点:实现非常简单,
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解呢?
-
二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i =1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
对于1.1中如果要插入44,产生冲突,使用解决后的情况为:
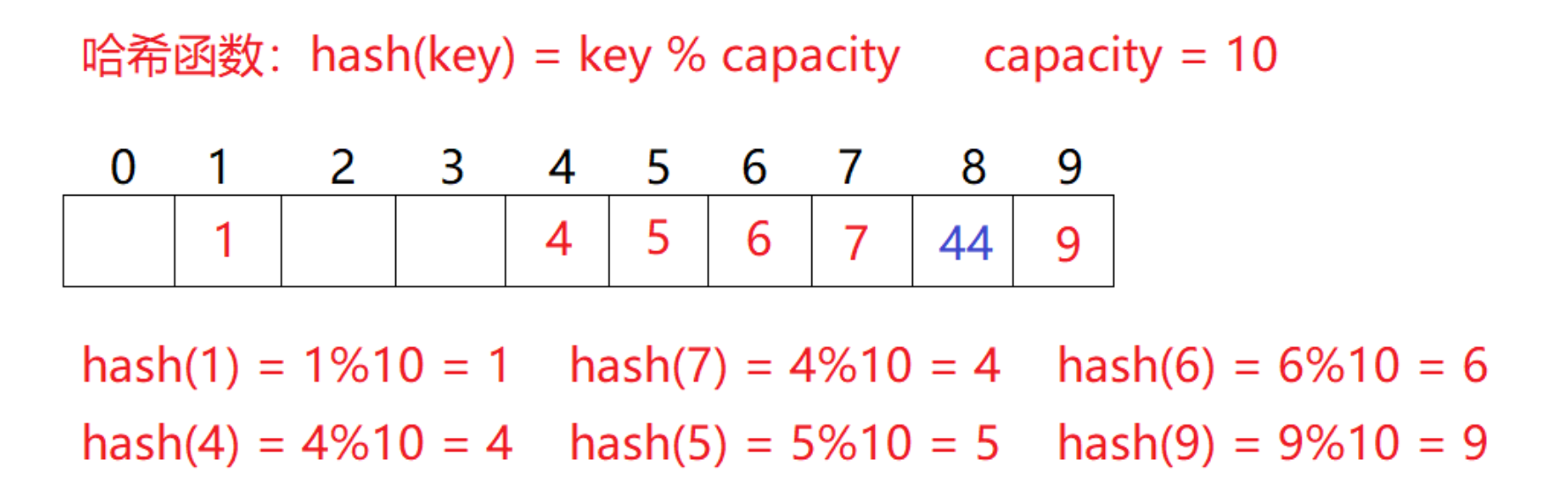
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
-
闭散列的思考
-
只能存储key为整形的元素,其他类型怎么解决? –合理利用仿函数
// 哈希函数采用处理余数法,被模的key必须要为整形才可以处理,此处提供将key转化为整形的方法 // 整形数据不需要转化 template<class T> class DefHashF { public: size_t operator()(const T& val) { return val; } }; // key为字符串类型,需要将其转化为整形 class Str2Int { public: size_t operator()(const string& s) { const char* str = s.c_str(); unsigned int seed = 131; // 31 131 1313 13131 131313 unsigned int hash = 0; while (*str) { hash = hash * seed + (*str++); } return (hash & 0x7FFFFFFF); } }; // 为了实现简单,此哈希表中我们将比较直接与元素绑定在一起 template<class V, class HF> class HashBucket { // …… private: size_t HashFunc(const V& data) { return HF()(data.first) % _ht.capacity(); } };
-
-
除留余数法,最好模一个素数,如何每次快速取一个类似两倍关系的素数?
inline unsigned long __stl_next_prime(unsigned long n) { static const int __stl_num_primes = 28; static const unsigned long __stl_prime_list[__stl_num_primes] = { 53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593, 49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741, 3221225473, 4294967291 }; for (int i = 0; i < __stl_num_primes; ++i) { if (__stl_prime_list[i] > n) { return __stl_prime_list[i]; } } return __stl_prime_list[__stl_num_primes - 1]; }
1.4.2 开散列
- 开散列概念
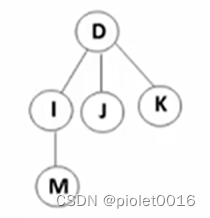
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
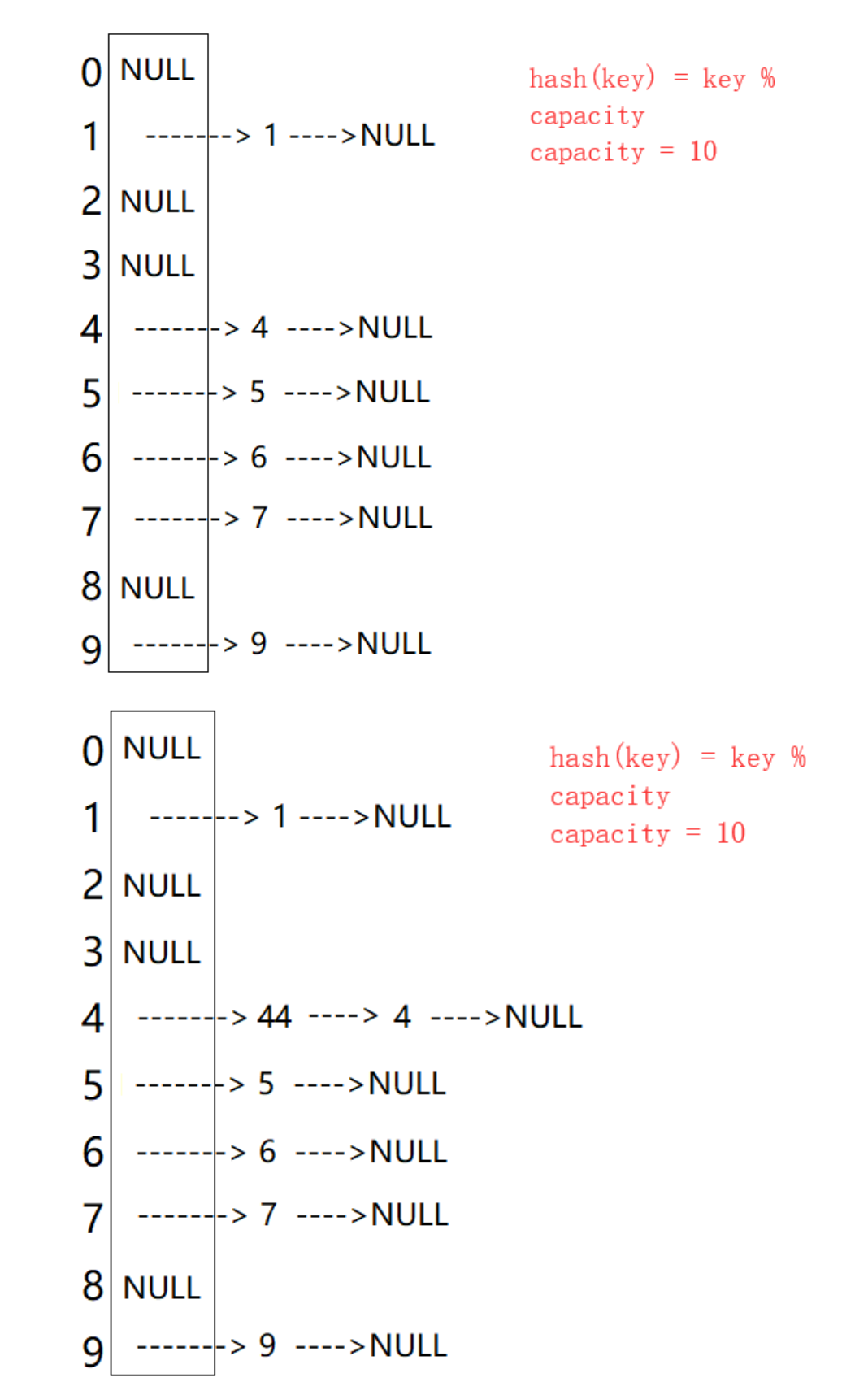
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素
- **开散列实现 **
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
template<class K>
class HashFunc//
{
public:
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>//对string类型特化
class HashFunc<string>
{
public:
size_t operator()(const string& str)
{
size_t hash = 0;
for (auto e : str)
{
hash *= 131;
hash += e;
}
return hash;
}
};
namespace buckethash
{
template<class K,class V>
class HashNode
{
public:
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K,V>& kv)
:_kv(kv),_next(nullptr)
{}
};
template<class K,class V,class Hash=HashFunc<K> >
class HashTable
{
public:
typedef HashNode<K, V> Node;
HashTable()
:_n(0),_tables(10)
{}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
return false;
if (_tables.size() ==_n)
{
//扩容
//传统方式---有新建节点的开销
//HashTable newHT;
//newHT._tables.resize(_tables.size() * 2);
//for (auto e : _tables)
//{
// Node* cur = e;
// while (cur)
// {
// newHT.Insert(cur->_kv);
// cur = cur->_next;
// }
//}
//_tables.swap(newHT._tables);
HashTable newHT;
newHT._tables.resize(_tables.size() * 2);
for (int i=0;i<_tables.size();++i)
{
Node* cur = _tables[i];
while (cur)
{
//重新计算哈希值,直接把节点连过去,减少新建节点的开销
Node* next = cur->_next;
size_t hashi = Hash()(cur->_kv.first) % newHT._tables.size();
cur->_next = newHT._tables[hashi];
newHT._tables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newHT._tables);
}
size_t hashi = Hash()(kv.first) % _tables.size();
Node* newnode = new Node(kv);//
newnode->_next = _tables[hashi];//直接将原来的值连接在新节点的后面
_tables[hashi] = newnode;//新节点当新的头
++_n;
return true;
}
Node* Find(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
return cur;
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == key)
{
if (prev == nullptr)
_tables[hashi] = cur->_next;
else
prev->_next = cur->_next;
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _tables;
size_t _n;//有效元素个数
};
//测试代码
void TestHT1()
{
HashTable<int, int> ht;
int a[] = { 18, 8, 7, 27, 57, 3, 38, 18,17,88,38,28 };
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(1, 1));
ht.Insert(make_pair(11,11));
ht.Insert(make_pair(5, 5));
ht.Erase(17);
ht.Erase(57);
}
void TestHT2()
{
string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
HashTable<string, int> countHT;
for (const auto& e : arr)
{
auto it = countHT.Find(e);
if (it)
{
it->_kv.second++;
}
else
{
countHT.Insert(make_pair(e, 1));
}
}
}
}
- **开散列增容 **
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
-
闭散列的思考
-
只能存储key为整形的元素,其他类型怎么解决?
跟上面闭散列表一样的解决策略
-
-
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <=0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
2. unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中只对unordered_map和unordered_set进行介绍,unordered_multimap和unordered_multiset可查看文档介绍。
2.1 unordered_map
2.1.1 unordered_map的文档介绍
unordered_map文档说明
unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与
其对应的value。在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此
键关联。键和映射值的类型可能不同。在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内
找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭
代方面效率较低。unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问
value。它的迭代器至少是前向迭代器。
2.1.2 unordered_map的接口说明
- unordered_map的构造
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的unordered_map对象 |
- unordered_map的容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
- unordered_map的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
- unordered_map的元素访问
| 函数声明 | 功能介绍 |
|---|---|
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,将key对应的value返回。
- 后续更多的详细接口建议观看在线文档说明unordered_map文档说明
2.2 unordered_set
参考文档说明
2.3 底层结构
unordered 系列容器的高效性主要在于它们的底层实现方式,即哈希表。
哈希表通过将键映射到槽位的索引上,将元素存储在一个数组中。由于哈希函数在大多数情况下都能够在常数时间内计算出键的哈希值,因此,哈希表可以在常数时间内进行插入、查找、删除等操作。
虽然存在哈希冲突时,查找、插入、删除操作的时间复杂度可能会退化为线性时间复杂度 O(n),但是在实际情况中,这种情况并不会经常发生,因此,哈希表在绝大多数情况下可以保证高效的操作。
此外,unordered 系列容器还采用了一些优化机制,如链表和红黑树的结合使用,可以保证在出现哈希冲突时,查找、插入、删除操作都可以在对数时间内完成。另外,unordered 系列容器还将空间的使用优化到了极致,相比于 map 和 set 等容器,unordered 系列容器快速地分配和释放内存,减少了动态内存分配带来的开销,加速了内存使用的效率。
综上所述,unordered 系列容器的高效性主要归功于哈希表这一底层结构的优秀设计,以及一些算法、数据结构的优化和空间使用的优化。
3. 模拟实现
3.1 哈希表的改造
- 模板参数列表的改造
// K:关键码类型
// V: 不同容器V的类型不同,如果是unordered_map,V代表一个键值对,如果是unordered_set, V 为 K
// KeyOfValue: 因为V的类型不同,通过value取key的方式就不同,详细见unordered_map / set的实现
// HF: 哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能取模
template<class K, class V, class KeyOfValue, class HF = DefHashF<T> >
class HashBucket;
- 增加迭代器操作
// 为了实现简单,在哈希桶的迭代器类中需要用到hashBucket本身,
template<class K, class V, class KeyOfValue, class HF>
class HashBucket;
// 注意:因为哈希桶在底层是单链表结构,所以哈希桶的迭代器不需要--操作
template <class K, class V, class KeyOfValue, class HF>
struct HBIterator
{
typedef HashBucket<K, V, KeyOfValue, HF> HashBucket;
typedef HashBucketNode<V>* PNode;
typedef HBIterator<K, V, KeyOfValue, HF> Self;
HBIterator(PNode pNode = nullptr, HashBucket* pHt = nullptr);
Self& operator++()
{
// 当前迭代器所指节点后还有节点时直接取其下一个节点
if (_pNode->_pNext)
_pNode = _pNode->_pNext;
else
{
// 找下一个不空的桶,返回该桶中第一个节点
size_t bucketNo = _pHt->HashFunc(KeyOfValue()(_pNode -> _data)) + 1;
for (; bucketNo < _pHt->BucketCount(); ++bucketNo)
{
if (_pNode = _pHt->_ht[bucketNo])
break;
}
}
return *this;
}
Self operator++(int);
V& operator*();
V* operator->();
bool operator==(const Self& it) const;
bool operator!=(const Self& it) const;
PNode _pNode; // 当前迭代器关联的节点
HashBucket* _pHt; // 哈希桶--主要是为了找下一个空桶时候方便
};
具体完整的代码
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
template<class K>
class HashFunc//哈希函数
{
public:
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>//对string类型特化
class HashFunc<string>
{
public:
size_t operator()(const string& str)
{
size_t hash = 0;
for (auto e : str)
{
hash *= 131;
hash += e;
}
return hash;
}
};
namespace Close_Hash
{
enum State
{
EMPTY,
DELETE,
EXIST,
};
template<class K,class V>
class HashData
{
public:
pair<K, V> _kv;
State _state = EMPTY;
};
namespace buckethash
{
template<class T>
class HashNode
{
public:
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data),_next(nullptr)
{}
};
template<class K, class T, class KeyofT, class Hash = HashFunc<K>>
class HashTable;
//为什么const迭代器没有复用?---因为在构造的时候,const对象对应的this也是cosnt的,这就导致const迭代器在构造的时候给成const的指针,但是非const的时候,是不需要const指针的,这就注定要不能复用
//注:非const迭代器---Node* _node,HashTable* _ht;
// const迭代器--- const Node* _node,const HashTable* _ht;
template<class K,class T,class KeyofT,class Hash=HashFunc<K>>
class hash_iterator
{
public:
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyofT, Hash> HT;
typedef hash_iterator<K, T, KeyofT, Hash> Self;
hash_iterator(Node* node,HT* ht)
:_node(node),_ht(ht)
{}
Self operator++()
{
Node* cur = _node;
if (cur->_next)//不是桶的最后一个节点
{
cur = cur->_next;
}
else//桶的最后一个节点
{
//需要重新计算哈希映射的位置
size_t hashi = Hash()(KeyofT()(cur->_data)) % _ht->_tables.size()+1;
while(hashi< _ht->_tables.size()
&&_ht->_tables[hashi]==nullptr)//找当前桶的下一个不为空的桶
{++hashi;}
if (hashi < _ht->_tables.size())
cur = _ht->_tables[hashi];
else
cur = nullptr;
}
_node = cur;
return *this;
}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& it)const
{
return it._node != _node;
}
bool operator==(const Self& it)const
{
return it._node == _node;
}
HT* _ht;
Node* _node;
};
template<class K, class T, class KeyofT, class Hash = HashFunc<K>>
class hash_const_iterator
{
public:
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyofT, Hash> HT;
typedef hash_const_iterator<K, T, KeyofT, Hash> Self;
typedef hash_iterator<K, T, KeyofT, Hash> iterator;
hash_const_iterator(const Node* node, const HT* ht)
:_node(node), _ht(ht)
{}
hash_const_iterator(const iterator&it)
:_node(it._node),_ht(it._ht)
{}
Self operator++()
{
const Node* cur = _node;
if (cur->_next)//不是桶的最后一个节点
{
cur = cur->_next;
}
else//桶的最后一个节点
{
//需要重新计算哈希映射的位置
size_t hashi = Hash()(KeyofT()(cur->_data)) % _ht->_tables.size() + 1;
while (hashi < _ht->_tables.size()
&& _ht->_tables[hashi] == nullptr)//找当前桶的下一个不为空的桶
{
++hashi;
}
if (hashi < _ht->_tables.size())
cur = _ht->_tables[hashi];
else
cur = nullptr;
}
_node = cur;
return *this;
}
const T& operator*()
{
return _node->_data;
}
const T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& it)const
{
return it._node != _node;
}
bool operator==(const Self& it)const
{
return it._node == _node;
}
const HT* _ht;
const Node* _node;
};
template<class K, class T, class KeyofT, class Hash >
class HashTable
{
public:
typedef HashNode<T> Node;
typedef hash_iterator<K, T, KeyofT, Hash> iterator;
typedef hash_const_iterator<K, T, KeyofT, Hash> const_iterator;
friend class iterator;
friend class const_iterator;
HashTable()
:_n(0),_tables(__stl_next_prime(10))
{}
iterator begin()
{
Node* cur = nullptr;
for (auto e : _tables)
{
cur = e;
if (cur != nullptr)
break;
}
return iterator(cur, this);
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin()const
{
Node* cur = nullptr;
for (auto e : _tables)
{
cur = e;
if (cur != nullptr)
break;
}
return const_iterator(cur, this);
}
const_iterator end()const
{
return const_iterator(nullptr, this);
}
std::pair<iterator,bool> Insert(const T& data)
{
Node* cur = Find(KeyofT()(data));
if (cur)
return make_pair(iterator(cur,this),false);
if (_tables.size() ==_n)
{
//扩容
//传统方式---有新建节点的开销
//HashTable newHT;
//newHT._tables.resize(_tables.size() * 2);
//for (auto e : _tables)
//{
// Node* cur = e;
// while (cur)
// {
// newHT.Insert(cur->_kv);
// cur = cur->_next;
// }
//}
//_tables.swap(newHT._tables);
HashTable newHT;
newHT._tables.resize(__stl_next_prime(_tables.size()));
for (int i=0;i<_tables.size();++i)
{
Node* cur = _tables[i];
while (cur)
{
//重新计算哈希值,直接把节点连过去,减少新建节点的开销
Node* next = cur->_next;
size_t hashi = Hash()(KeyofT()(cur->_data)) % newHT._tables.size();
cur->_next = newHT._tables[hashi];
newHT._tables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newHT._tables);
}
size_t hashi = Hash()(KeyofT()(data)) % _tables.size();
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode,this),true);
}
Node* Find(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (KeyofT()(cur->_data) == key)
return cur;
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (Hash()(cur->_data) == key)
{
if (prev == nullptr)
_tables[hashi] = cur->_next;
else
prev->_next = cur->_next;
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
bool empty()const
{
return _n == 0;
}
size_t size()const
{
return _n;
}
private:
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (int i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return __stl_prime_list[__stl_num_primes - 1];
}
private:
vector<Node*> _tables;
size_t _n;
};
}
3.2 unordered_map
因为已经实现好了哈希表的改造,直接进行封装即可
#pragma once
#include "HashTable.h"
using namespace buckethash;
namespace hdm
{
template<class K,class V>
struct KeyofT
{
const K& operator()(const std::pair<K, V>& kv)
{
return kv.first;
}
};
template<class K,class V>
class unordered_map
{
public:
typedef typename HashTable<K, std::pair<const K, V>, KeyofT<K, V> >::iterator iterator;
typedef typename HashTable<K, std::pair<const K, V>, KeyofT<K, V> >::const_iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin()const
{
return _ht.begin();
}
const_iterator end()const
{
return _ht.end();
}
std::pair<iterator, bool> insert(const std::pair<K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K&key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
private:
HashTable<K, std::pair<const K, V>, KeyofT<K,V> > _ht;
};
/
//测试代码区
void Func(const unordered_map<string, int>& countMap)
{
for (const auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
}
void test_unordered_map()
{
string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
unordered_map<string, int> countMap;
for (auto& e : arr)
{
countMap[e]++;
}
unordered_map<string, int>::const_iterator it= countMap.begin();
//it->second++;
for (const auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
Func(countMap);
}
}
3.3 unordered_set
同样也是对哈希表进行封装既可
#pragma once
#include "HashTable.h"
using namespace buckethash;
namespace hdm
{
template<class K>
struct KeyofK
{
const K& operator()(const K& key)
{
return key;
}
};
template<class K>
class unordered_set
{
public:
typedef typename HashTable<K, K, KeyofK<K>>::const_iterator iterator;
typedef typename HashTable<K, K, KeyofK<K>>::const_iterator const_iterator;
std::pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin()const
{
return _ht.begin();
}
const_iterator end()const
{
return _ht.end();
}
private:
HashTable<K, K, KeyofK<K>> _ht;
};
///
//测试代码区
void test_unordered_set()
{
unordered_set<int> us;
us.insert(13);
us.insert(3);
us.insert(23);
us.insert(5);
us.insert(5);
us.insert(6);
us.insert(15);
us.insert(223342);
us.insert(22);
//for (int i = 0; i < 100; i++)
//{
// us.insert(i);
//}
unordered_set<int>::const_iterator it = us.begin();
while (it != us.end())
{
cout << *it << " ";
++it;
//(*it)++;
}
cout << endl;
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
}
}
4. 哈希应用
4.1 位图
4.1.1 位图概念
假如给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
-
遍历,时间复杂度O(N)
-
排序(O(NlogN)),利用二分查找: logN
-
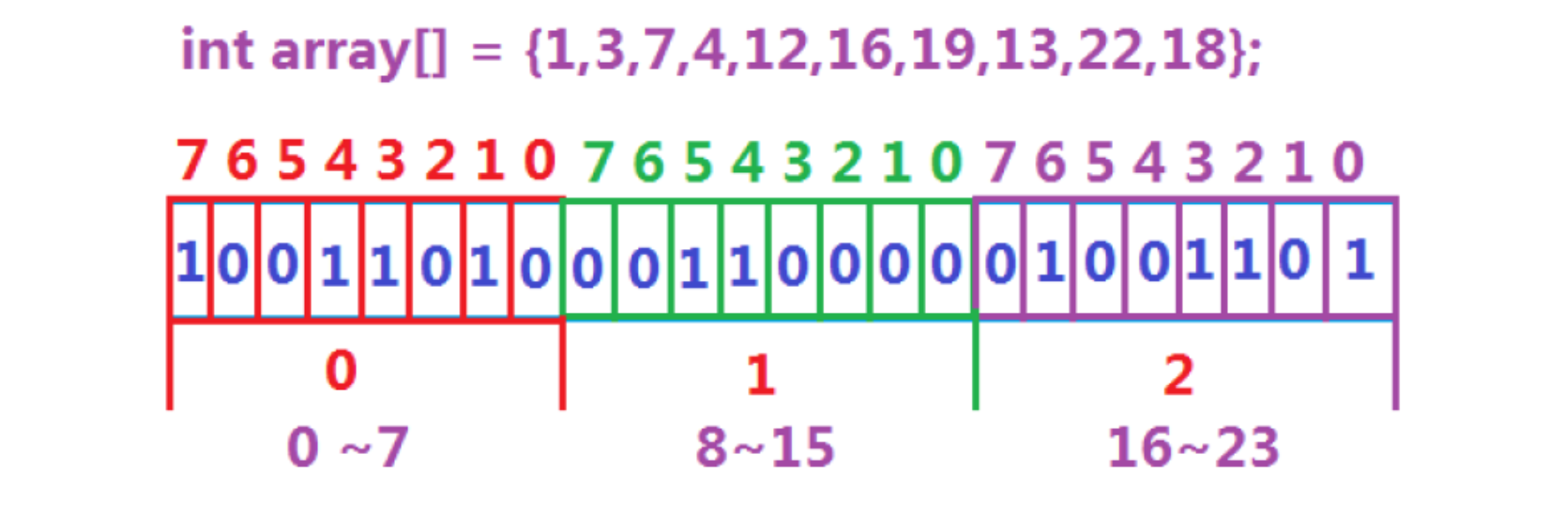
位图解决
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。比如:
-
位图概念
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
4.1.2 位图的实现
#pragma once
#include <vector>
using namespace std;
template<size_t N>
class bitset
{
public:
bitset()
:_bit((N >> 3)+1,0)
{}
// 将x对应比特位置1
void set(size_t x)
{
size_t index = x / 8;
size_t pos = x % 8;
_bit[index] |= (1 << pos);
}
//将x对应比特位置0
void reset(size_t x)
{
size_t index = x / 8;
size_t pos = x % 8;
_bit[index] &= ~(1 << pos);
}
// 检测位图中x是否为1
bool test(size_t x)
{
size_t index = x / 8;
size_t pos = x % 8;
return _bit[index] & (1 << pos);
}
private:
vector<char> _bit;
};
4.1.3 位图的应用
位图(BitMap)是一种常用的数据结构,它可以用一个bit位来表示某种状态或某种数据。位图可以用来节省存储空间和提高算法效率,常见的应用场景包括:
去重:位图可以记录某个元素是否出现过,通过将某个元素所对应的 bit 置为 1,如果后续再遇到该元素,只需要查看该元素所对应的 bit 是否已经被置为 1 即可判断该元素是否已经出现过。
排序:位图也可以用来进行排序,仍然可以将某个元素对应的 bit 置为 1,而访问整个位图时,只需按照 bit 的位置遍历即可,这样就可以在 O(n) 的时间内完成排序。
压缩:当处理大量需要存储的数据时,位图可以将一个整数所占用的 4 字节或 8 字节转为占用 1 bit,从而大幅度提高内存的使用效率。
快速查找某个数据是否在一个集合中
操作系统中磁盘块标记
除了上述的应用场景外,位图还可以用于网络爬虫中对 URL 的去重处理,对布隆过滤器、图像处理等领域也有广泛的应用。
4.2 布隆过滤器
4.2.1 布隆过滤器提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
4.2.2布隆过滤器概念
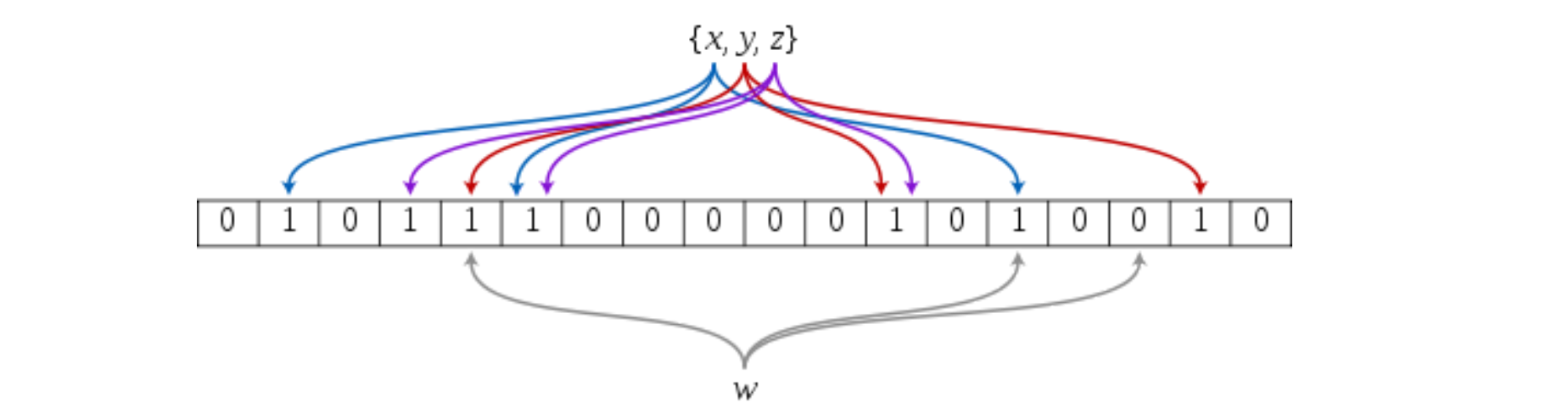
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
原帖地址
4.2.3 布隆过滤器的插入

例如向布隆过滤器中插入:“baidu”
需要使用多个不同的哈希函数生成**多个哈希值,**并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
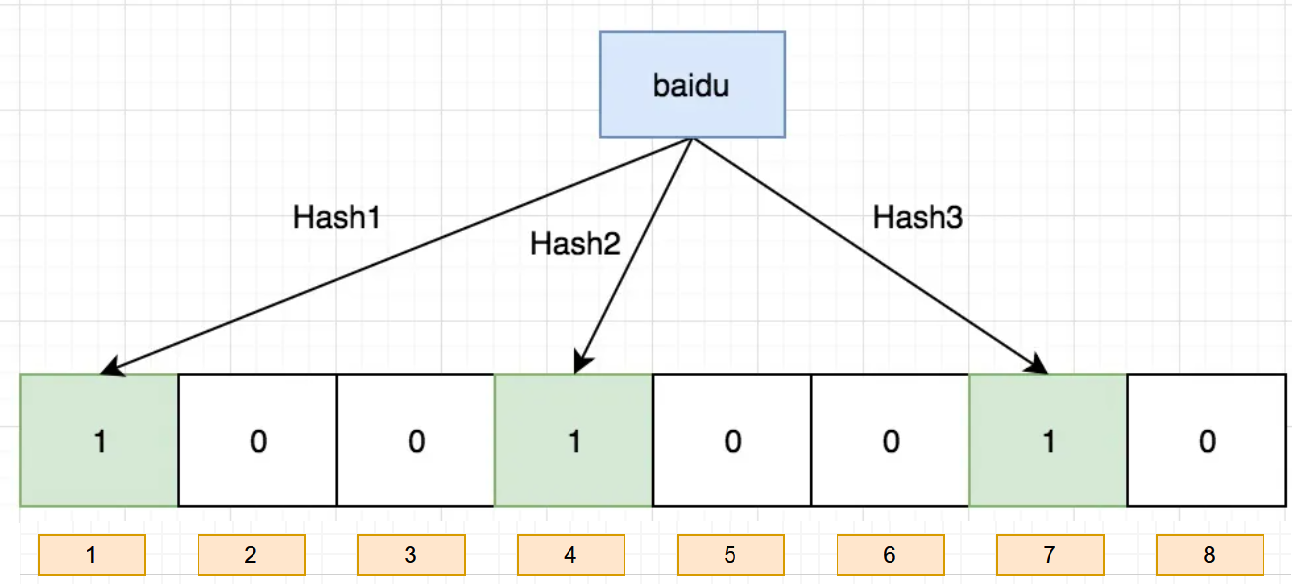
现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
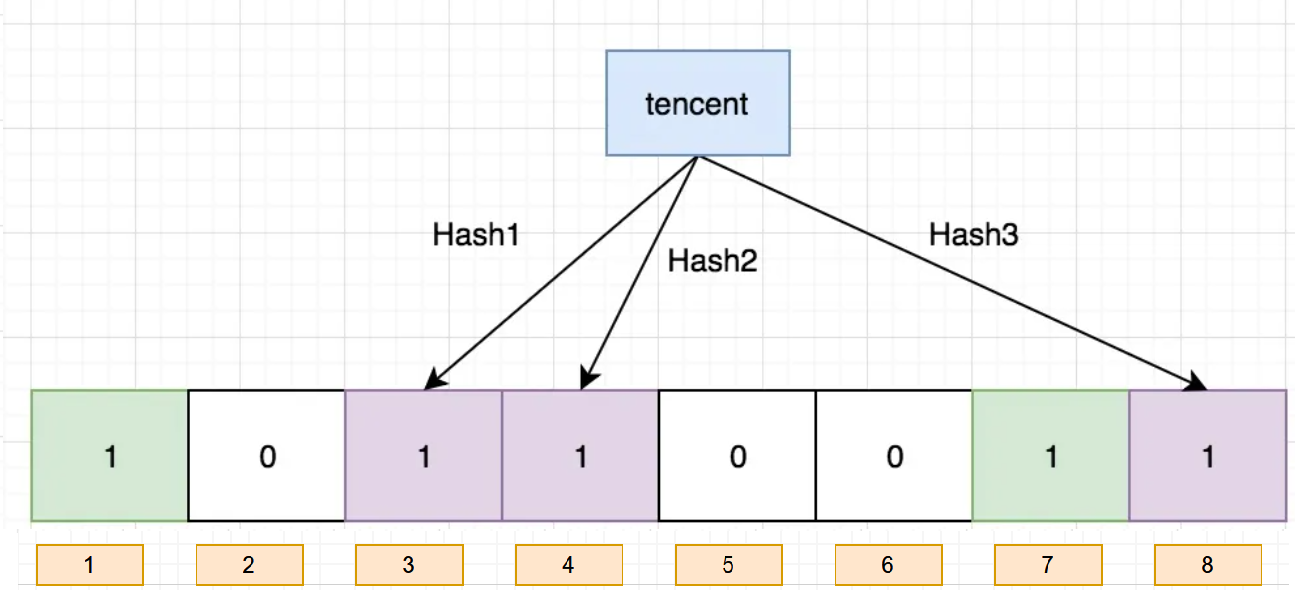
4.2.4 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
4.2.5 布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
无法确认元素是否真正在布隆过滤器中
存在计数回绕
4.2.6 布隆过滤器优点
增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
哈希函数相互之间没有关系,方便硬件并行运算
布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
使用同一组散列函数的布隆过滤器可以进行交、并、差运算
4.2.7 布隆过滤器缺陷
有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
不能获取元素本身
一般情况下不能从布隆过滤器中删除元素
如果采用计数方式删除,可能会存在计数回绕问题
4.2.8 布隆过滤器实现
各种哈希函数对比
-
如何选择哈希函数个数和布隆过滤器长度
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数
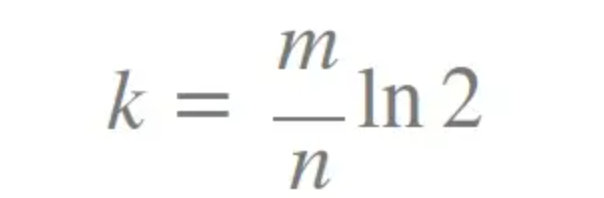
#pragma once
#include <bitset>
#include <string>
using namespace std;
namespace hdm
{
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N,
class K = string,
size_t x = 5,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void set(const K& key)
{
size_t hash1 = HashFunc1()(key) % (N * x);
size_t hash2 = HashFunc2()(key) % (N * x);
size_t hash3 = HashFunc3()(key) % (N * x);
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool test(const K& key)
{
size_t hash1 = HashFunc1()(key) % (N * x);
if (_bs.test(hash1) == 0)
return false;
size_t hash2 = HashFunc2()(key) % (N * x);
if (_bs.test(hash2) == 0)
return false;
size_t hash3 = HashFunc3()(key) % (N * x);
if (_bs.test(hash3) == 0)
return false;
return true;//可能存在误判
}
// 不支持删除,删除可能会影响其他值
void reset(const K& key);
private:
std::bitset<N* x> _bs;
};
///
//测试
void test_bloomfilter1()
{
string str[] = { "猪八戒", "孙悟空", "沙悟净", "唐三藏", "白龙马1","1白龙马","白1龙马" };
BloomFilter<10> bf;
for (auto& str : str)
{
bf.set(str);
}
for (auto& s : str)
{
cout << bf.test(s) << endl;
}
cout << endl;
srand(time(0));
for (const auto& s : str)
{
cout << bf.test(s + to_string(rand())) << endl;
}
}
void test_bloomfilter2()
{
srand(time(0));
const size_t N = 100000;
BloomFilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集,但是不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += std::to_string(999999 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "zhihu.com";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
}//namespace end