为什么需要Repository?
Anemic Domain Model(贫血领域模型)特征:
- 有大量的XxxDO对象:这里DO虽然有时候代表了Domain Object,但实际上仅仅是数据库表结构的映射,里面没有包含(或包含了很少的)业务逻辑;
- 服务和Controller里有大量的业务逻辑:比如校验逻辑、计算逻辑、格式转化逻辑、对象关系逻辑、数据存储逻辑等;
- 大量的Utils工具类等。
Anemic Domain Model的缺陷:
- 无法保护模型对象的完整性和一致性:因为对象的所有属性都是公开的,只能由调用方来维护模型的一致性,而这个是没有保障的;之前曾经出现的案例就是调用方没有能维护模型数据的一致性,导致脏数据使用时出现bug,这一类的bug还特别隐蔽,很难排查到。
- **对象操作的可发现性极差:**单纯从对象的属性上很难看出来都有哪些业务逻辑,什么时候可以被调用,以及可以赋值的边界是什么;比如说,Long类型的值是否可以是0或者负数?
- **代码逻辑容易重复:**比如校验逻辑、计算逻辑,都很容易出现在多个服务、多个代码块里,提升维护成本和bug出现的概率;一类常见的bug就是当贫血模型变更后,校验逻辑由于出现在多个地方,没有能跟着变,导致校验失败或失效。
- 代码的健壮性差:比如一个数据模型的变化可能导致从上到下的所有代码的变更。
充血模型中,需要严格区分的两个模型:
- 数据模型(Data Model):指业务数据该如何持久化,以及数据之间的关系,也就是传统的ER模型。只属于Infrastructure Layer
- 业务模型/领域模型(Domain Model):指业务逻辑中,相关联的数据该如何联动。只属于Domain Layer
链接了这两层的关键对象,就是Repository。
Repository的价值
在传统的数据库驱动开发中,我们会对数据库操作做一个封装,一般叫做Data Access Object(DAO)。DAO的核心价值是封装了拼接SQL、维护数据库连接、事务等琐碎的底层逻辑,让业务开发可以专注于写代码。但是在本质上,DAO的操作还是数据库操作,DAO的某个方法还是在直接操作数据库和数据模型,只是少写了部分代码。
所以,我们希望将我们的 业务逻辑 和 DB相关的操作(DAO、DB)隔离开,让我们的业务逻辑,不关心如何数据如何落库或查找
模型对象代码规范
模型类型:
3种模型的区别,Entity、Data Object (DO)和Data Transfer Object (DTO):
-
DO(数据对象)
在DDD的规范里,DO应该仅仅作为数据库物理表格的映射,不能参与到业务逻辑中。为了简单明了,DO的字段类型和名称应该和DB中的字段类型和名称一一对应。(当然,实际上也没必要一摸一样,只要你在Mapper那一层做到字段映射)
-
Entity(实体对象)
实体对象是我们正常业务应该用的业务模型,它的字段和方法应该和业务语言保持一致,和持久化方式无关。也就是说,Entity 和 DO 很可能有着完全不一样的字段命名和字段类型,甚至嵌套关系。Entity的生命周期应该仅存在于内存中,不需要可序列化和可持久化。
-
DTO(传输对象):
主要作为Application Layer 的入参和出参,比如CQRS里的Command、Query、Event,以及Request、Response等都属于DTO的范畴。DTO的价值在于适配不同的业务场景的入参和出参,避免让业务对象变成一个万能大对象。该对象需要序列化,其余两模型都不能实现序列化接口。
模型对象间的关系:
- 复杂的Entity拆分多个DO对象
- 多个关联的 Entity 合并一个 DO
- 从复杂 Entity 里抽取部分信息形成一个 DTO 列表
- 从多个 Entity 中提取信息,输出一个 DTO
模型转化器
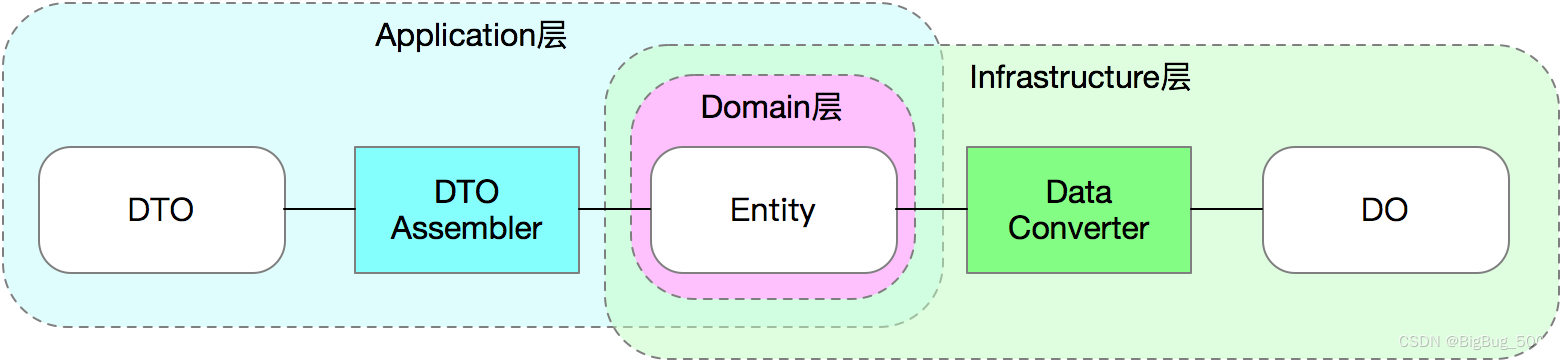
DTO Assembler:
在 Application 层,Entity 与 DTO 之间的转化器有一个标准的名称叫DTO Assembler,他的核心作用就是将1个或多个相关联的Entity转化为1个或多个DTO。
Data Converter:
在Infrastructure层,Entity 与 DO 的转化器没有一个标准名称,但是为了区分 Data Mapper(Mybatis的Mapper),我们叫这种转化器Data Converter。
带来的好处:
通过抽象出一个 Assembler/Converter 对象,把复杂的转化逻辑都收敛到一个对象中,并且可以很好的进行单元测试。
带来的问题:
- 当业务复杂时,手写 Assembler/Converter 是一件耗时且容易出bug的事情,所以业界会有多种Bean Mapping的解决方案,从本质上分为动态和静态映射。
- 动态映射根据反射动态赋值,大量的反射调用,将带来性能问题。
- 推荐使用 MapStruct(MapStruct官网),该组件通过注解,在编译时静态生成映射代码,其最终编译出来的代码和手写的代码在性能上完全一致,且有强大的注解等能力。
- 从使用复杂度角度来看,区分了DO、Entity、DTO带来了代码量的膨胀(从1个变成了3+2+N个)。但是在实际复杂业务场景下,通过功能来区分模型带来的价值是功能性的单一和可测试、可预期,最终反而是逻辑复杂性的降低。
Repository代码规范
Repository 出现的目的,是为了将 业务逻辑(软件) 与 硬件(DB、Cache、文件系统等)和 固件(与硬件强关联的软件)完全隔离开。所以为了体现出软件的特点,Repository 中需要注意以下三点:
- **接口名称不应该使用底层实现的语法:**常见的
insert、select、update、delete都属于SQL语法,使用这几个词相当于和DB底层实现做了绑定,在 Repository 为了区分开,我们使用语法如find、save(insert或update)、remove。 - **出参入参不应该使用底层数据格式:**Repository 操作的是 Entity 对象(实际上应该是Aggregate Root),不应该直接操作 DO。Repository 接口存在于 Domain 层,实现类 建议 在 Infrastructure 层。
- **应该避免所谓的“通用”Repository模式:**很多ORM框架都提供一个“通用”的Repository接口,然后框架通过注解自动实现接口,比较典型的例子是Spring Data、Entity Framework等,这种框架的好处是在简单场景下很容易通过配置实现,但是坏处是基本上无扩展的可能性(比如加定制缓存逻辑),在未来有可能还是会被推翻重做。当然,这里避免通用不代表不能有基础接口和通用的帮助类。
复杂Aggregate的save
在对一个复杂Aggregate(包含多个Entity)的 save 操作中,并不是所有 Aggregate 里的 Entity 都需要变更。
如果不知道 Aggregate 中的变更有哪些,那么只有全量更新,导致大量的无用DB操作;如果我们可以追踪到变更的 Entity,那么将可以减少很多无用的 DB 操作。
业界目前有两个主流的变更追踪方案:
- 基于Snapshot的方案:当数据从DB里取出来后,在内存中保存一份snapshot,然后在数据写入时和snapshot比较。常见的实现如Hibernate
- 基于Proxy的方案:当数据从DB里取出来后,通过weaving的方式将所有setter都增加一个切面来判断setter是否被调用以及值是否变更,如果变更则标记为Dirty。在保存时根据Dirty判断是否需要更新。常见的实现如Entity Framework。
方案对比:
| Snapshot(推荐) | Proxy | |
|---|---|---|
| 复杂程度 | 通过cache实现,使用流程较简单 | 通过代理标记实现,工具类较复杂,使用流程简单 |
| 内存消耗 | 高 | 无额外内存占用 |
| 带来的问题 | cache与DB的数据一致性问题 | 代理标记Dirty时,对复杂Aggregate的判断问题 |
Repository的迁移流程
使用 Repository 模式最大的收益就是可以彻底和底层固件解耦,让上层业务可以快速自发展。
假设传统方式下,查询数据只有如下两个类:
- OrderDO:和DB一样的数据结构
- OrderDAO:和DB交互的业务操作类
其升级流程如下:
- 生成Order实体类,初期字段可以和OrderDO保持一致
- 生成OrderDataConverter,通过MapStruct(Java Bean转换器)基本上2行代码就能完成
- 写单元测试,确保Order和OrderDO之间的转化100%正确
- 生成OrderRepository接口和实现,通过单测确保OrderRepository的正确性
- 将原有代码里使用了OrderDO的地方改为Order
- 将原有代码里使用了OrderDAO的地方都改为用OrderRepository
- 通过单测确保业务逻辑的一致性。