kafka整理
一、kafka概述
kafka是apache旗下一款开源的顶级的消息队列的系统, 最早是来源于领英, 后期将其贡献给apache, 采用语言是scala.基于zookeeper, 启动kafka集群需要先启动zookeeper集群, 同时在zookeeper记录kafka相关的元数据
kafka本质上就是消息队列的中间件产品 ,kafka中消息数据是直接存储在磁盘上
kafka的特点:
- 可靠性
- 可扩展性
- 耐用性
- 高性能
二、kafka的架构图
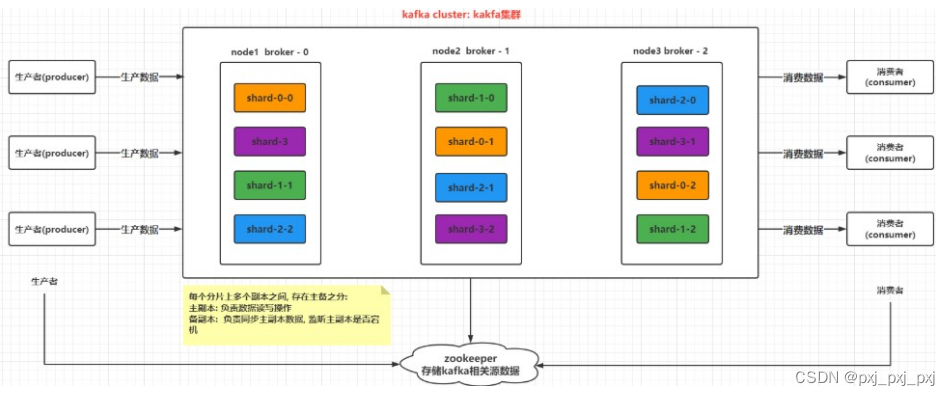
kafka cluster :kafka的集群
broker:kafka的节点
producer:生产者
consumer:消费者
topic:主题,一个逻辑容器
shard:分片,分片的数量
replicas:副本,受节点的限制,副本<=节点数
zookeeper:对kafka集群进行管理,保存kafka的元数据信息
三、安装
3.1解压
[pxj@pxj62 /opt/software]$tar -zxvf kafka_2.12-2.4.1.tgz -C /opt/app/
3.2建软连接
[pxj@pxj62 /opt/app]$ln -s kafka_2.12-2.4.1 kafka
3.3修改 server.properties
[pxj@pxj62 /opt/app/kafka/config]$vim server.properties
3.4启动与停止
前台启动:
./kafka-server-start.sh ../config/server.properties
后台启动:
nohup ./kafka-server-start.sh ../config/server.properties 2>&1 &
注意: 第一次启动, 建议先前台启动, 观察是否可以正常启动, 如果OK, ctrl +C 退出, 然后挂载到后台
启动: ./start-kafka.sh
四、shell命令操作
4.1创建top
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --create --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01 --partitions 3 --replication-factor 2
Created topic test01.
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --create --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test02 --partitions 3 --replication-factor 3
Created topic test02.
4.2 查看当前有那些topic
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --list --zookeeper pxj62:2181,pxj63:2181,pxj64:2181
test01
test02
4.3 如何查看某一个topic的详细信息
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --describe --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01
Topic: test01 PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test01 Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test01 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test01 Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --describe --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test02
Topic: test02 PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: test02 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test02 Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test02 Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --create --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test03 --partitions 3 --replication-factor 1
Created topic test03.
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --describe --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test03
Topic: test03 PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: test03 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: test03 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: test03 Partition: 2 Leader: 0 Replicas: 0 Isr: 0
4.4修改topic
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --alter --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01 --partitions 5
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --describe --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01
Topic: test01 PartitionCount: 5 ReplicationFactor: 2 Configs:
Topic: test01 Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test01 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test01 Partition: 2 Leader: 1 Replicas: 1,2 Isr: 2,1
Topic: test01 Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: test01 Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2
[pxj@pxj62 /opt/app/kafka/bin]$
注意:只能调大分片的数量, 无法调小以及无法调整副本数量
4.5删除topic
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --delete --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01
Topic test01 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-topics.sh --describe --zookeeper pxj62:2181,pxj63:2181,pxj64:2181 --topic test01
Error while executing topic command : Topic 'test01' does not exist as expected
[2023-04-09 22:36:54,129] ERROR java.lang.IllegalArgumentException: Topic 'test01' does not exist as expected
at kafka.admin.TopicCommand$.kafka$admin$TopicCommand$$ensureTopicExists(TopicCommand.scala:484)
at kafka.admin.TopicCommand$ZookeeperTopicService.describeTopic(TopicCommand.scala:390)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:67)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
[pxj@pxj62 /opt/app/kafka/bin]$
4.6模拟一个生产者. 用于生产数据到topic中
[pxj@pxj62 /opt/app/kafka/bin]$./kafka-console-producer.sh --broker-list pxj62:9092,pxj63:9092,pxj64:9092 --topic test02
>pxj
>pxj
>jps
>ll
4.7消费者接收
[pxj@pxj63 /opt/app/kafka/bin]$./kafka-console-consumer.sh --bootstrap-server pxj62:9092,pxj63:9092,pxj64:9092 --topic test02 --from-beginning
pxj
pxj
jps
ll
五、kafkaAPI
5.1生产者
package com.ccj.pxj.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Properties;
public class KafkaProducerTest {
public static void main(String[] args) {
// 1- 创建 生产者对象
// 1.1 设置生产者相关的配置
Properties props = new Properties();
props.put("bootstrap.servpackage com.ccj.pxj.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
// 1. 创建 kafka的消费者对象
//1.1: 设置消费者的配置信息
Properties props = new Properties();
props.setProperty("bootstrap.servers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定 kafka地址
props.setProperty("group.id", "test"); // 指定消费组 id
props.setProperty("enable.auto.commit", "true"); // 是否开启自动提交数据的偏移量
props.setProperty("auto.commit.interval.ms", "1000"); // 自动提交的间隔时间
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 设置key反序列类
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 设置value反序列化类
//1.2: 创建kafka消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2.设置消费者监听那些Topic
consumer.subscribe(Arrays.asList("test02"));
//3. 消费数据: 一直在消费, 只要有数据,立马进行处理操作
while (true) {
//3.1: 获取消息数据, 参数表示等待(超时)的时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long offset = record.offset(); // 偏移量信息
String key = record.key(); // 获取key
String value = record.value(); // 获取value
int partition = record.partition();// 从哪个分区读取的数据
System.out.println("偏移量:"+ offset +"; key值:"+key +";value值:"+ value +"; 分区:"+partition);
}
}
}
}
ers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定kafka的地址
props.put("acks", "all"); // 指定消息确认方案
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// key序列化类
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化类
//1.2: 构建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
//2. 发送数据
for (int i = 0; i < 10; i++) {
//2.1 构建 数据的承载对象
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test02",Integer.toString(i));
producer.send(producerRecord);
}
//3. 释放资源
producer.close();
}
}
5.2 消费者
package com.ccj.pxj.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
// 1. 创建 kafka的消费者对象
//1.1: 设置消费者的配置信息
Properties props = new Properties();
props.setProperty("bootstrap.servers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定 kafka地址
props.setProperty("group.id", "test"); // 指定消费组 id
props.setProperty("enable.auto.commit", "true"); // 是否开启自动提交数据的偏移量
props.setProperty("auto.commit.interval.ms", "1000"); // 自动提交的间隔时间
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 设置key反序列类
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 设置value反序列化类
//1.2: 创建kafka消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2.设置消费者监听那些Topic
consumer.subscribe(Arrays.asList("test02"));
//3. 消费数据: 一直在消费, 只要有数据,立马进行处理操作
while (true) {
//3.1: 获取消息数据, 参数表示等待(超时)的时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long offset = record.offset(); // 偏移量信息
String key = record.key(); // 获取key
String value = record.value(); // 获取value
int partition = record.partition();// 从哪个分区读取的数据
System.out.println("偏移量:"+ offset +"; key值:"+key +";value值:"+ value +"; 分区:"+partition);
}
}
}
}
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
偏移量:1; key值:null;value值:0; 分区:1
偏移量:2; key值:null;value值:1; 分区:1
偏移量:3; key值:null;value值:2; 分区:1
偏移量:4; key值:null;value值:3; 分区:1
偏移量:5; key值:null;value值:4; 分区:1
偏移量:6; key值:null;value值:5; 分区:1
偏移量:7; key值:null;value值:6; 分区:1
偏移量:8; key值:null;value值:7; 分区:1
偏移量:9; key值:null;value值:8; 分区:1
偏移量:10; key值:null;value值:9; 分区:1
六、kafka的核心原理
6.1kafka的分区和副本
分区:
topic可以理解为是一个大的容器(逻辑), 分片相当于将topic划分为多个小容器, 将这些小容器分布在不同的broker上, 进行分布式存储, 分片的数量不受节点数量限制
作用:
1- 提升吞吐量, 前提 kafka节点充足下
2- 解决单台节点存储有限的问题, 可以通过分片实现分布式存储
3- 提高并发能力
副本:
对topic中每一个分片构建多个副本, 从而保证数据不能丢失, 副本的数量最多与节点数量是相等, 一般来说副本为 1~3个
作用:
提升数据可靠性, 防止数据丢失
6.2kafka数据传输过程
三阶段:
第一阶段:生产者将数据生产到集群的broket端
第二阶段:broker将数据存储
第三阶段:消费者从broker端消费数据
6.3生产者如何保证数据不丢失
对于kafka,主要采用ack认证机制处理的
0:生产者只管发送到broket端,不管broker的响应
1:生产者只管发送到broket端,需要等待对应接受分片的主副本接收到数据后,给予响应,认为数据发送成功
-1:ALL;生产者只管发送到broket端,需要等待对应接受分片所有的 副本接收到数据后,给予响应认为数据发送成功
效率:0>1>-1
安全:-1>1>0
ack模式的选择:根据生产需求确定,
props.put(“acks”,''all'')
6.3如果broker端迟迟没有给予响应,如何解决
采用先等待(超时时间)再重试的策略,一般重试3次,如果重试后依然没有给予响应,此时让程序直接报错。通知相关人员处理即可
6.4宽带占用如何解决
可以引入缓存池,采用异步发送方案,生产者将数据在发送数据时候,底层会将这个数据保存到缓存池中,当池子中数据达到一批数据大小后,将达一批数据直接发送到broker,此时broker针对这一批数据给予一次性响应即可(批量发送数据)
6.5 采用批量发送数据,如果发送一批数据到broker端,broker端又没有给予响应,此时缓存池中数据满了,如何解决呢?
解决方案:
1.丢弃缓存池中数据,报异常(适用于数据不重要,或者可以重读的消息总数据)
2.在写入缓冲池的时候,需要将数据在其他的地方也持久存储一份,发送成功一批数据,将持久化地方数据删除一部分,以保证在出现此问题后,数据依然存在,下次启动的时候,优先从持久化容器中读取即可

七、安装 kafka-eagle
7.1.解压
7.2环境变量
[pxj@pxj62 /home/pxj]$vim .bashrc
export PS1='[\u@\h `pwd`]\$'
export JAVA_HOME=/usr/java/jdk1.8.0_141
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/app/hadoop
export ZOOKEEPER_HOME=/opt/app/zookeeper
export KAFKA_HOME=/opt/app/kafka
export KE_HOME=/opt/app/kafka-eagle
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${KAFKA_HOME}/bin:${KE_HOME}/bin:$PATH
[pxj@pxj62 /home/pxj]$source .bashrc
7.3配置 kafka_eagle。
使用vi打开conf目录下的system-config.propertie
[pxj@pxj62 /opt/app/kafka-eagle/conf]$vim system-config.properties
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=pxj62:2181,pxj63:2181,pxj64:2181
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
# kafka metrics, 30 days by default
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.metrics.retain=30
# kafka sqlite jdbc driver address
######################################
#kafka.eagle.driver=org.sqlite.JDBC
#kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
#kafka.eagle.username=root
#kafka.eagle.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://pxj63:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=I LOVE PXJ
7.4配置JAVA_HOME
在24行加入
export JAVA_HOME=/usr/java/jdk1.8.0_141
7.5授权运行
[pxj@pxj62 /opt/app/kafka-eagle/bin]$chmod +x ke.sh
7.6启动
[pxj@pxj62 /opt/app/kafka-eagle/bin]$./ke.sh start
7.7访问web
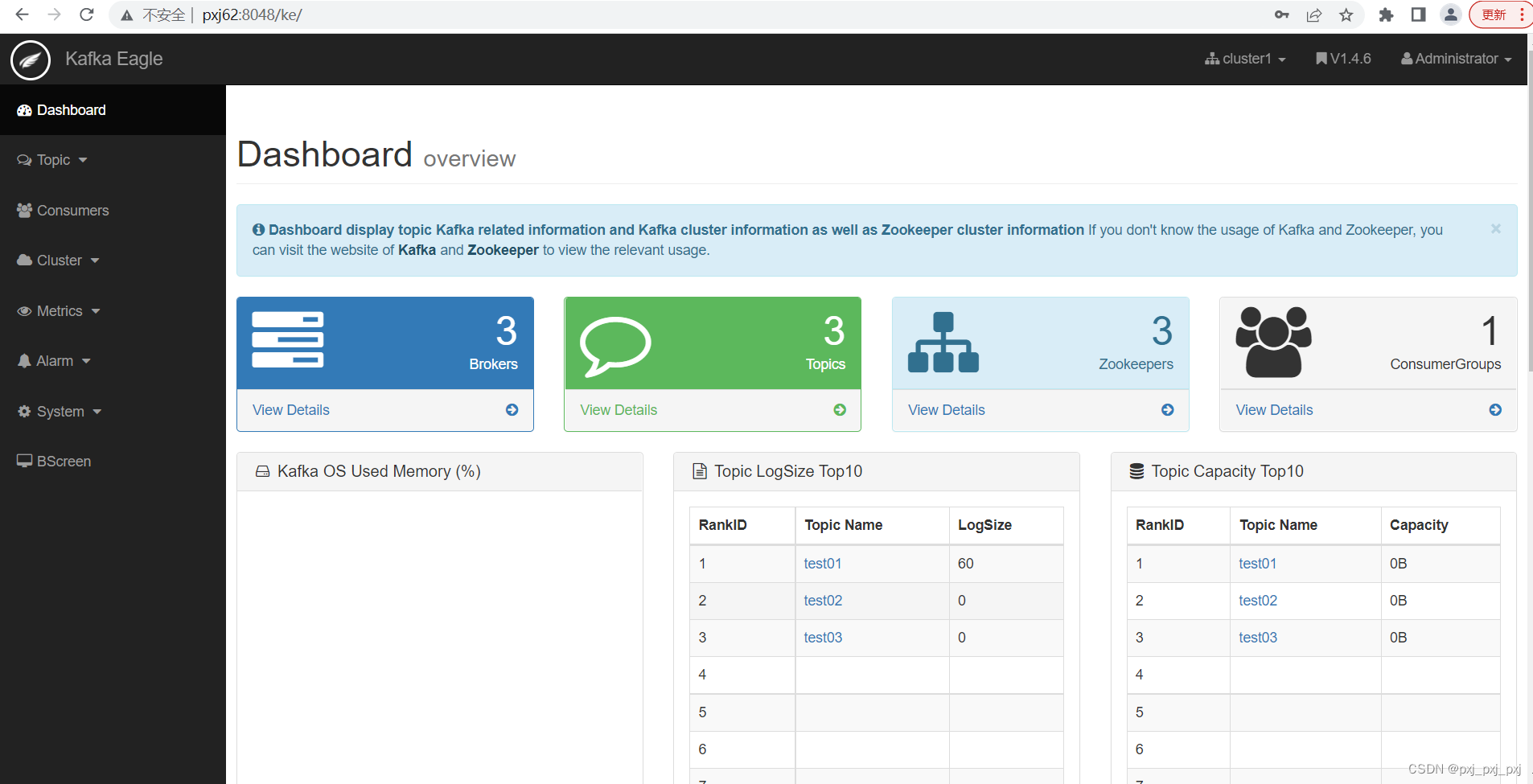
http://pxj62:8048/ke
八、同步发送
package com.ccj.pxj.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerSyncTest {
public static void main(String[] args) {
Properties props=new Properties();
props.put("bootstrap.servers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定kafka的地址
props.put("acks", "all"); // 指定消息确认方案
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// key序列化类
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化类
//构造生产者
KafkaProducer<String,String> producer = new KafkaProducer<>(props);
// 2.发送数据
for (int i = 0; i <10 ; i++) {
// 构建 数据承载对象
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test01", i+"_02");
// 使用get 其实就是同步方式, 会当发送后, 会一直等待响应, 如果长时间没有响应, 就会重试, 如果依然没有, 直接报错
// get支持自定义超时的时间
try{
producer.send(producerRecord).get();
}catch (Exception e){
e.printStackTrace();
}
}
producer.close();
}
}
九、异步发送
package com.ccj.pxj.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerAsyncTest {
public static void main(String[] args) {
// 1- 创建 生产者对象
// 1.1 设置生产者相关的配置
Properties props = new Properties();
props.put("bootstrap.servers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定kafka的地址
props.put("acks", "all"); // 指定消息确认方案
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// key序列化类
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value序列化类
//1.2: 构建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
// 2.发送数据
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test01", i+"_22");
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
// 此方法为回调函数的方式, 当进行异步发送的时候, 不管最终是成功了还是失败了, 都会回调此函数
if(e!=null){
// 说明有异常, 发送失败了
// 在此处, 编写发送失败的处理业务逻辑代码
System.err.println("发送消息失败:" +
e.getStackTrace());
}
if(metadata!=null){
if (metadata != null) {
System.out.println("异步方式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());
}
}
}
});
}
//3. 释放资源
producer.close();
}
}
十、消费者异步
package com.ccj.pxj.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerTest02 {
public static void main(String[] args) {
Properties props=new Properties();
// 1. 创建 kafka的消费者对象
//1.1: 设置消费者的配置信息
props.setProperty("bootstrap.servers", "pxj62:9092,pxj63:9092,pxj64:9092"); // 指定 kafka地址
props.setProperty("group.id", "test"); // 指定消费组 id
props.setProperty("enable.auto.commit", "false"); // 是否开启自动提交数据的偏移量
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 设置key反序列类
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 设置value反序列化类
//创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test01"));
while(true){
ConsumerRecords<String,String> records=consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long offset = record.offset(); // 偏移量信息
String key = record.key(); // 获取key
String value = record.value(); // 获取value
int partition = record.partition();// 从哪个分区读取的数据
System.out.println("偏移量:"+ offset +"; key值:"+key +";value值:"+ value +"; 分区:"+partition);
// 当消息消费完成后, 提交偏移量信息 : 一定不要丢失提交偏移量的代码. 否则 会造成大量的重复消费问题
consumer.commitSync(); // 同步提交
consumer.commitAsync(); // 异步提交
}
}
}
}
十一、broker端如何保证数据不丢失
broker主要将消息数据存储下来, 那么如何保证数据不丢失呢?
多副本机制 + 生产者的ack为 -1
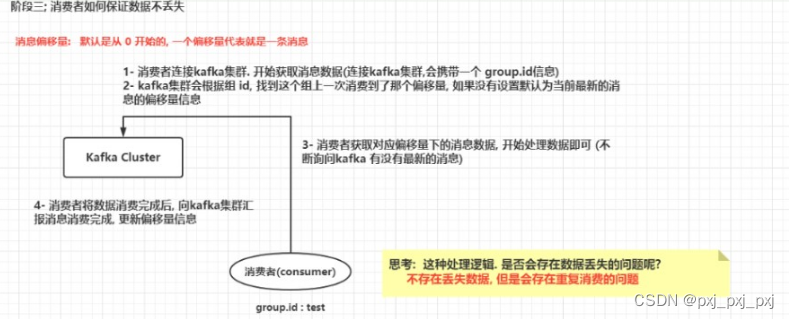
消费偏移量数据是存储在哪里呢?
在kafka的老版本(kafka 0.8x下)是存储在zookeeper中, 在新版本中消费者消息偏移量信息是存储在broker端, 通过一个topic来存储的: __consumer_offset
此topic具有50个分区, 1个副本
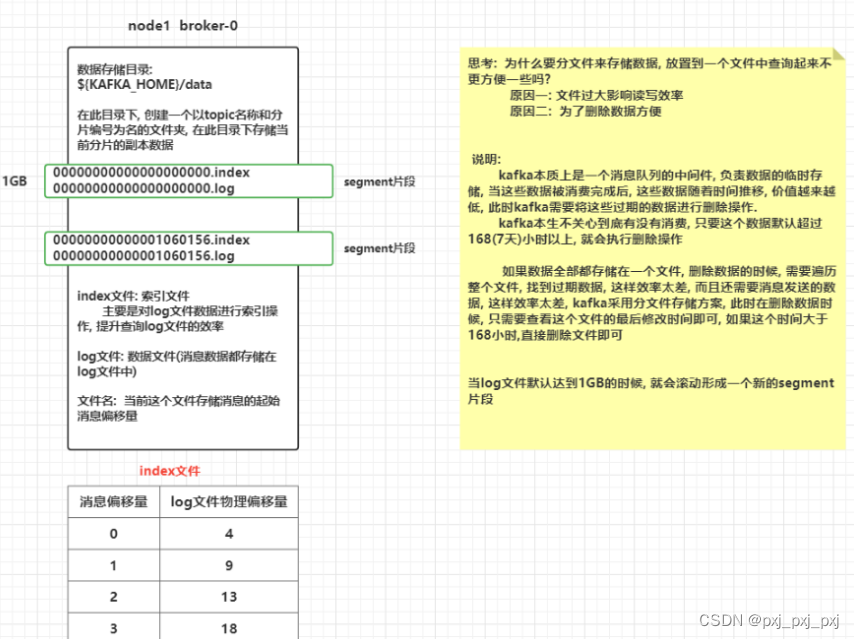
如何修改默认的过期时间呢?
# server.properties的103行位置: 默认值为 168小时
log.retention.hours=168
# 设置一个log文件的大小, 默认为: 1073741824 (1GB)
log.segment.bytes=1073741824
十二、kafka的数据查询机制

查询过程
- 先确定这条消息在那个segment片段中
- 到对应片段中找index文件, 根据offset查询消息数据在log文件的那个物理偏移量位置
- 根据从index查询到的偏移量信息, 到 log文件顺序查询(磁盘查询方式)到对应范围下数据即可
磁盘的读写分为两种读写方式: 顺序读写 和 随机读写
顺序读写效率远远高于随机读写
十三、kafka中生产者的数据分发策略
kafka生产者数据分发策略: 指的生产者在生产数据到达broker指定topic中, 最终这条数据被topic中哪一个分片接收到了, 这就是生产者分发机制
思考: 常见的分发策略
1) hash策略
2) 轮询策略
3) 指定分区策略
4) 确定每个分区范围分发
那么kafka支持那些分发策略呢?
1) 粘性分区策略(老版本(2.4以前): 轮询)
2) hash取模策略
3) 指定分区策略
4) 自定义分区
如何设置分发策略呢? 与 ProducerRecord 和 DefaultPartitioner关系很大
1) 粘性分区策略(老版本(2.4以前): 轮询)
# 当生成数据时候, 使用这个只需要传递value发送方案, 底层走的 粘性分区策略(老版本(2.4以前): 轮询)
public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}
# 为什么这么说呢? 原因是 DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
# 当 key为null的时候, 执行 stickyPartitionCache (粘性分区)
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
2) hash取模策略
# 当发送数据的时候, 如果传递 k 和 v , 默认使用 hash取模分区方案, 根据key进行hash取模
public ProducerRecord(String topic, K key, V value) {
this(topic, null, null, key, value, null);
}
# 为什么这么说呢? 原因是 DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
# 当 key为null的时候, 执行 stickyPartitionCache (粘性分区)
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
# 当key不为null的时候, 获取topic的所有分区, 然后根据key进行hash取模
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
3) 指定分区策略
# 当发送数据的时候, 需要明确指出给那个partition发送数据 : ProducerRecord构造
# 分片是从0开始的, 如果是三个分片: 0 1 2
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
此时这种分发策略 与 defaultPartitions 没有关系了
4) 自定义分区策略: (抄. 官方源码DefaultPartitioner)
4.1) 创建一个类, 实现Partitioner 接口
4.2) 重写接口中的partition方法, 返回值表示分区的编号
4.3) 按照业务逻辑实现方法中分区方案
4.4) 告知给kafka, 使用新的分区方案当生产者开始发送数据, 如果只传递了value的数据, 此时kafka会采用粘性分区策略, 首先会先随机的选择一个分区, 然后尽可能的黏上这个分区, 将这一批数据全部写入到这一个分区中, 当下次请求再来的时候, 重新在随机选择一个分区(如果间隔时间比较短, 大概率会黏住上一个分区), 再黏住这个分区, 将数据写入到这个分区下, 这种分区方案称为粘性分区策略
粘性分区是kafka2.4.x及以上版本支持的一种全新的分区策略 在2.4以下的版本中, 采用的轮询方案
老版本轮询:
当生产者准备好一批数据后, 将这一批数据写入到某一个topic中, 如果采用轮询方案, 需要将这一批数据分为多个小批次, 分别对应不同的分片,将各个小批次的数据发送给对应的分片下即可, 而这种操作需要额外在一批数据上再次进行分批处理, 导致生产效率下降, 所以说在新版本中, 将其替换为粘性分区
参数: partitioner.class :
默认值: org.apache.kafka.clients.producer.internals.DefaultPartitioner
通过生产者的properties对象, 重新设置一下partitioner.class 参数即可
什么是粘性分区策略:
当生产者开始发送数据, 如果只传递了value的数据, 此时kafka会采用粘性分区策略, 首先会先随机的选择一个分区, 然后尽可能的黏上这个分区, 将这一批数据全部写入到这一个分区中, 当下次请求再来的时候, 重新在随机选择一个分区(如果间隔时间比较短, 大概率会黏住上一个分区), 再黏住这个分区, 将数据写入到这个分区下, 这种分区方案称为粘性分区策略
粘性分区是kafka2.4.x及以上版本支持的一种全新的分区策略 在2.4以下的版本中, 采用的轮询方案
老版本轮询:
当生产者准备好一批数据后, 将这一批数据写入到某一个topic中, 如果采用轮询方案, 需要将这一批数据分为多个小批次, 分别对应不同的分片,将各个小批次的数据发送给对应的分片下即可, 而这种操作需要额外在一批数据上再次进行分批处理, 导致生产效率下降, 所以说在新版本中, 将其替换为粘性分区
十四、kafka的负载均衡机制

如果使用kafka模拟点对点 和 发布订阅 方式
点对点: 一个消费只能被一个消费者所接收
让所有监听这个topic的消费者都属于同一个消费者组内即可
发布订阅: 一个消息可以被多个消费者所接收
让所有监听这个topic的消费者都属于不同的消费者组内即可