背景
当需要存储大量数据并需要对其进行操作时,常常需要使用到链表这种数据结构。它可以用来存储一系列的元素并支持插入、删除、遍历等操作。
概念
一般来说,链表是由若干个节点组成的,每个节点包含了两个部分的内容:存储的数据本身和指向下一个节点的指针。这种数据结构,使得每个节点都可以访问它的数据,以及它后面的节点。
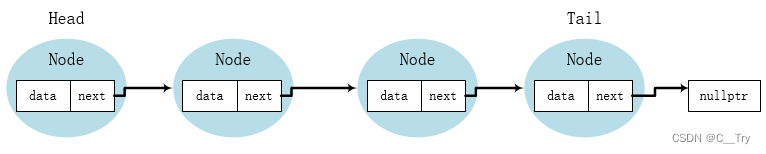
在C++中,链表可以通过定义一个节点类来实现。下面是一个简单的链表节点类的示例代码:
class Node {
public:
int data;
Node* next;
};
or
typedef struct Node {
int data;
struct Node *next;
}在上面的代码中,定义了一个名为"Node"的类(或者是结构体,下文默认使用class,操作起来类似),这个类包含了两个成员变量:一个整型数据"data"(常见的一般使用int作为存储数据的类型,也可以使用class或者struct等一些复合类型作为data),以及一个指向下一个节点的指针"next"。这样,就可以使用这个节点类来构造一个链表了。
构建链表:
构建链表时,需要定义一个头节点,它指向链表的第一个元素。头节点通常不包含实际数据,只是用来记录链表的起点。下面是一个简单的创建链表的示例代码:
Node* head = new Node(); // 定义头节点
head->next = nullptr; // 将头节点的指针指向 NULL,表示链表为空
针对链表的操作,一般有添加节点、查询节点、删除节点、遍历节点、去除重复节点以及对链表排序等操作,下文将展开:
添加节点
接下来,可以向链表中添加节点,从而构建一个有数据的链表。下面是一个向链表中添加节点的示例代码:
// 向链表尾部添加一个新节点
void addNode(Node* head, int data) {
Node* p = head;
while (p->next != nullptr) {
p = p->next;
}
Node* newNode = new Node();
newNode->data = data;
newNode->next = nullptr;
p->next = newNode;
}
在上面的代码中,定义了addNode函数,其中head是头结点的指针,data是需要插入的数据,该函数的作用是向链表的尾部添加一个新节点。在函数中,首先遍历链表,找到链表的最后一个节点,然后创建一个新的节点,将它的数据设置为传入的"data"参数,并将它添加到链表的末尾。
查询节点
这是一个查找对应节点的代码示例,假设需要查找一个值为value的节点:
Node* findNode(Node* head, int value) {
Node* p = head->next; // 从头节点的下一个节点开始遍历
while (p != nullptr) {
if (p->data == value) { // 找到了目标节点
return p;
}
p = p->next;
}
// 没有找到目标节点,返回nullptr
return nullptr;
}
删除节点
当需要在链表中查找节点或删除节点时,通常需要遍历链表,找到目标节点并进行相应的操作。下面是一个简单的删除节点的代码示例,假设需要删除的节点指针为target:
void deleteNode(Node* head, Node* target) {
Node* p = head;
while (p->next != target) { // 找到目标节点的前一个节点
p = p->next;
}
p->next = target->next; // 将前一个节点的指针指向目标节点的下一个节点
delete target; // 释放目标节点的内存
}
上面的代码中,定义了deleteNode函数,形参为一个头节点head和一个目标节点指针"target",用来删除链表中的目标节点。函数首先遍历链表,找到目标节点的前一个节点,然后将前一个节点的指针指向目标节点的下一个节点,从而删除目标节点。最后,使用"delete"操作符释放目标节点的内存空间。
去除重复节点
最简单的方式就是使用set来实现去重。还有一种比较朴实无华的方式就是使用双重循环的方式来实现去重,不需要使用哈希表。这种方法的思路是:对于每个节点,遍历它后面的所有节点,如果找到与当前节点相同的节点,则将它从链表中删除。下面是一个示例代码:
非hash去重
void removeDuplicates(Node* head) {
Node* p = head;
while (p != nullptr) {
Node* q = p->next;
Node* prev = p; // 上一个非重复节点
while (q != nullptr) {
if (p->data == q->data) {
prev->next = q->next; // 将当前节点从链表中删除
delete q;
q = prev->next; // 将指针移动到下一个节点
} else {
prev = q; // 更新上一个非重复节点
q = q->next; // 将指针移动到下一个节点
}
}
p = p->next; // 将指针移动到下一个节点
}
}在上面的代码中,定义了一个removeDuplicates函数,形参为一个头节点head,用于删除链表中的重复节点。函数首先定义了一个指向当前节点的指针p,然后从头节点head开始遍历整个链表。对于每个节点p,定义一个指向它后面节点的指针q,然后遍历节点p后面的所有节点。如果找到一个与节点p的值相同的节点,则将它从链表中删除。否则,将指针q移动到下一个节点,并更新上一个非重复节点的指针prev。最后,将指针p移动到下一个节点。
hash去重
#include <unordered_set> // 需要放到开头去
void removeDuplicates(Node* head) {
unordered_set<int> hash; // 哈希表,用于存储每个节点的值
Node* p = head;
Node* prev = nullptr; // 上一个非重复节点
while (p != nullptr) {
if (hash.count(p->data)) { // 如果当前节点的值在哈希表中出现过
prev->next = p->next; // 删除当前节点
delete p;
p = prev->next; // 将指针移动到下一个节点
} else {
hash.insert(p->data); // 将当前节点的值加入到哈希表中
prev = p; // 更新上一个非重复节点
p = p->next; // 将指针移动到下一个节点
}
}
}
与上述函数一样,形参为头节点head,用于删除链表中的重复节点。函数首先定义了一个unordered_set类型的哈希表(也可以使用set来实现),用于存储每个节点的值。然后,遍历整个链表,对于每个节点,判断它的值是否在哈希表中出现过。如果出现过,则删除当前节点;否则将当前节点的值加入到哈希表中,并更新上一个非重复节点的指针。
排序
此处使用冒泡排序来写一个简单的示例。首先呢链表是不能像数组那样使用下标来访问元素,但是呢,我们可以通过修改节点的指针来改变链表的顺序,从而实现链表的排序。以下是代码示例:
class Node {
public:
int data;
Node* next;
};
Node* bubbleSortList(Node* head) {
if (!head || !head->next) return head; // 链表为空或只有一个节点,直接返回
Node *cur = head, *tail = nullptr;
while (tail != head->next) { // tail 指向未排序部分的第一个节点
while (cur->next != tail) {
if (cur->data > cur->next->data) { // 如果相邻两个节点顺序不对,则交换它们的值
int temp = cur->data;
cur->data = cur->next->data;
cur->next->data = temp;
}
cur = cur->next;
}
tail = cur; // 更新 tail,向前移动一位
cur = head; // cur 重新指向链表头节点
}
return head;
}上述代码中,定义了一个名为"bubbleSortList"的函数,它接受一个链表的头节点指针。函数使用两个指针变量"cur"和"tail"来遍历链表,并对链表节点进行排序。内层循环通过比较相邻节点的值并交换它们的值,实现了冒泡排序的过程。注意,每次内层循环结束后,"tail"指向的是未排序部分的第一个节点,"cur"重新指向链表头节点。
冒泡排序的时间复杂度为O(n^2),在链表中的实现中需要更多的指针操作,因此效率相对较低。但是,冒泡排序是一种稳定的排序算法,可以保留原有相同元素之间的相对位置。
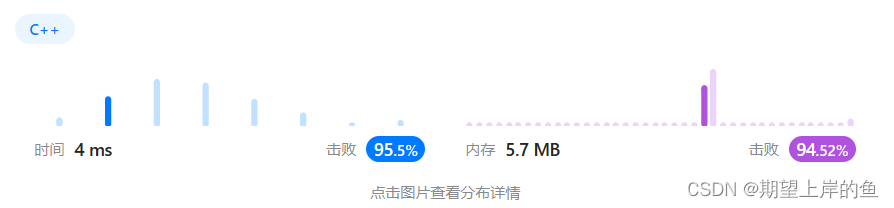
用例测试
以下是全部代码的集合,并编写了用例对功能进行了测试
#include "set.h"
#include <iostream>
#include <unordered_set>
class Node {
public:
int data;
Node* next;
};
// 向链表尾部添加一个新节点
void addNode(Node* head, int data) {
Node* p = head;
while (p->next != nullptr) {
p = p->next;
}
Node* newNode = new Node();
newNode->data = data;
newNode->next = nullptr;
p->next = newNode;
}
Node* findNode(Node* head, int value) {
Node* p = head->next; // 从头节点的下一个节点开始遍历
while (p != nullptr) {
if (p->data == value) { // 找到了目标节点
return p;
}
p = p->next;
}
// 没有找到目标节点,返回nullptr
return nullptr;
}
void deleteNode(Node* head, Node* target) {
Node* p = head;
while (p->next != target) { // 找到目标节点的前一个节点
p = p->next;
}
p->next = target->next; // 将前一个节点的指针指向目标节点的下一个节点
delete target; // 释放目标节点的内存
}
//void removeDuplicates(Node* head) {
// Node* p = head;
// while (p != nullptr) {
// Node* q = p->next;
// Node* prev = p; // 上一个非重复节点
// while (q != nullptr) {
// if (p->data == q->data) {
// prev->next = q->next; // 将当前节点从链表中删除
// delete q;
// q = prev->next; // 将指针移动到下一个节点
// } else {
// prev = q; // 更新上一个非重复节点
// q = q->next; // 将指针移动到下一个节点
// }
// }
// p = p->next; // 将指针移动到下一个节点
// }
//}
void removeDuplicates(Node* head) {
std::unordered_set<int> hash; // 哈希表,用于存储每个节点的值
Node* p = head;
Node* prev = nullptr; // 上一个非重复节点
while (p != nullptr) {
if (hash.count(p->data)) { // 如果当前节点的值在哈希表中出现过
prev->next = p->next; // 删除当前节点
delete p;
p = prev->next; // 将指针移动到下一个节点
} else {
hash.insert(p->data); // 将当前节点的值加入到哈希表中
prev = p; // 更新上一个非重复节点
p = p->next; // 将指针移动到下一个节点
}
}
}
Node* bubbleSortList(Node* head) {
if (!head || !head->next) return head; // 链表为空或只有一个节点,直接返回
Node *cur = head, *tail = nullptr;
while (tail != head->next) { // tail 指向未排序部分的第一个节点
while (cur->next != tail) {
if (cur->data > cur->next->data) { // 如果相邻两个节点顺序不对,则交换它们的值
int temp = cur->data;
cur->data = cur->next->data;
cur->next->data = temp;
}
cur = cur->next;
}
tail = cur; // 更新 tail,向前移动一位
cur = head; // cur 重新指向链表头节点
}
return head;
}
void printList(Node* head) {
Node* p = head;
while (p != nullptr) {
std::cout << p->data << " ";
p = p->next;
}
std::cout << std::endl;
}
int main() {
Node* head = new Node(); // 定义头节点
head->next = nullptr; // 将头节点的指针指向 nullptr,表示链表为空
addNode(head, 5);
addNode(head, 3);
addNode(head, 9);
addNode(head, 1);
addNode(head, 7);
std::cout << "Before sorting: ";
printList(head);
if (findNode(head, 9)) {
std::cout << "Found 9 in the list" << std::endl;
}
Node *target = findNode(head, 3);
if (target != nullptr) {
deleteNode(head, target);
std::cout << "After removing 3: ";
printList(head);
}
bubbleSortList(head);
std::cout << "After sorting: ";
printList(head);
return 0;
}
//int a[5] {1, 2, 3, 4, 5}, b[5] = {1, 3, 6, 7, 8};
//int x1[2] = {1, 2}, x2[5] {1, 2, 3};
//bool bl;
//Set c(a, 5);
//Set d(b, 5);
//Set e(x1, 5);
//Set f(x2, 5);
//
//Set g;
//std::cout << "Set c: "; c.display();
//std::cout << "Set d: "; d.display();
//
//g = c + d;
//std::cout << "Set g: "; g.display();








![[架构之路-176]-《软考-系统分析师》-17-嵌入式系统分析与设计 -1- 实时性(任务切换时间、中断延迟时间、中断响应时间)、可靠性、功耗、体积、成本](https://img-blog.csdnimg.cn/f73c83a0b3df47f7abd1efc69d050b1c.png)
