大家好,我是易安!
如果有人问我学习并发并发编程,最核心的技术点是什么,我一定会告诉他,管程技术。Java语言在1.5之前,提供的唯一的并发原语就是管程,而且1.5之后提供的SDK并发包,也是以管程技术为基础的。除此之外,C/C++、C#等高级语言也都支持管程。
可以这么说,管程就是解决并发问题的基石。
什么是管程
不知道你是否曾思考过这个问题:为什么Java在1.5之前仅仅提供了synchronized关键字及wait()、notify()、notifyAll()这三个看似从天而降的方法?在刚接触Java的时候,我以为它会提供信号量这种编程原语,因为操作系统原理课程告诉我,用信号量能解决所有并发问题,结果我发现不是。后来我找到了原因:Java采用的是管程技术,synchronized关键字及wait()、notify()、notifyAll()这三个方法都是管程的组成部分。而 管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。 但是管程更容易使用,所以Java选择了管程。
管程,对应的英文是Monitor,很多Java领域的同学都喜欢将其翻译成“监视器”,这是直译。操作系统领域一般都翻译成“管程”,这个是意译,而我自己也更倾向于使用“管程”。
所谓 管程,指的是管理共享变量以及对共享变量的操作过程,让他们支持并发。翻译为Java领域的语言,就是管理类的成员变量和成员方法,让这个类是线程安全的。那管程是怎么管的呢?
MESA模型
在管程的发展史上,先后出现过三种不同的管程模型,分别是:Hasen模型、Hoare模型和MESA模型。其中,现在广泛应用的是MESA模型,并且Java管程的实现参考的也是MESA模型。所以今天我们重点介绍一下MESA模型。
在并发编程领域,有两大核心问题:一个是 互斥,即同一时刻只允许一个线程访问共享资源;另一个是 同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。
我们先来看看管程是如何解决 互斥 问题的。
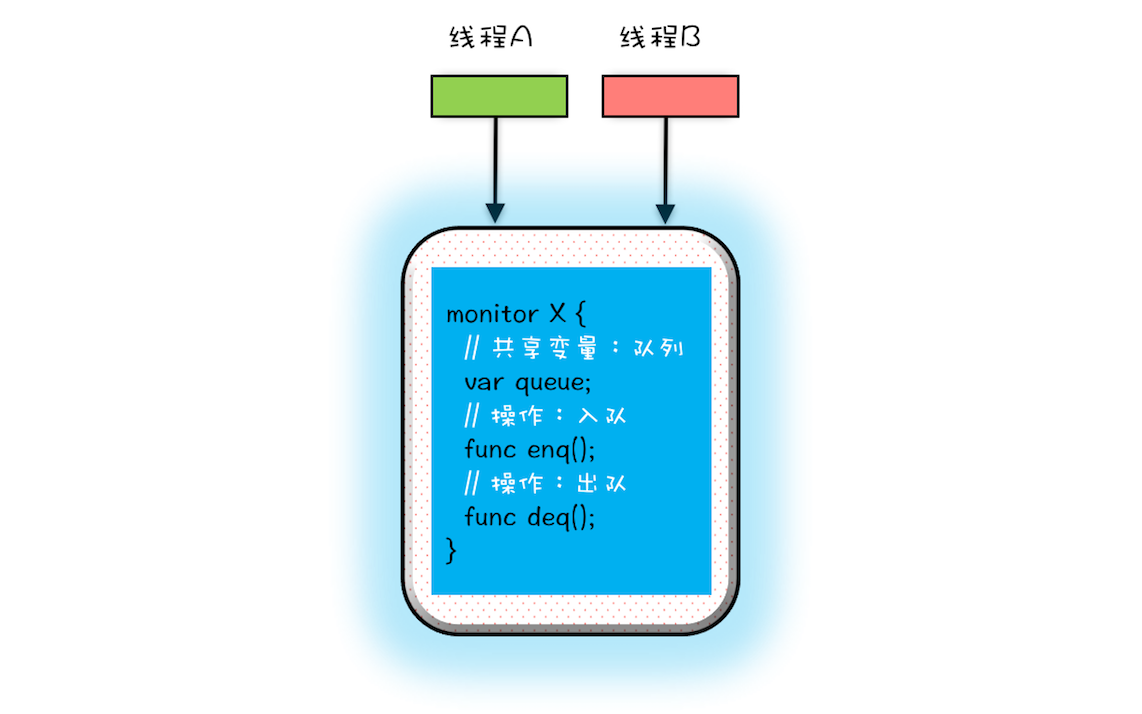
管程解决互斥问题的思路很简单,就是将共享变量及其对共享变量的操作统一封装起来。假如我们要实现一个线程安全的阻塞队列,一个最直观的想法就是:将线程不安全的队列封装起来,对外提供线程安全的操作方法,例如入队操作和出队操作。
利用管程,可以快速实现这个直观的想法。在下图中,管程X将共享变量queue这个线程不安全的队列和相关的操作入队操作enq()、出队操作deq()都封装起来了;线程A和线程B如果想访问共享变量queue,只能通过调用管程提供的enq()、deq()方法来实现;enq()、deq()保证互斥性,只允许一个线程进入管程。
不知你有没有发现,管程模型和面向对象高度契合的。估计这也是Java选择管程的原因吧。
那管程如何解决线程间的 同步 问题呢?
这个就比较复杂了,不过你可以借鉴一下我们曾经提到过的就医流程,它可以帮助你快速地理解这个问题。为进一步便于你理解,在下面,我展示了一幅MESA管程模型示意图,它详细描述了MESA模型的主要组成部分。
在管程模型里,共享变量和对共享变量的操作是被封装起来的,图中最外层的框就代表封装的意思。框的上面只有一个入口,并且在入口旁边还有一个入口等待队列。当多个线程同时试图进入管程内部时,只允许一个线程进入,其他线程则在入口等待队列中等待。这个过程类似就医流程的分诊,只允许一个患者就诊,其他患者都在门口等待。
管程里还引入了条件变量的概念,而且 每个条件变量都对应有一个等待队列, 如下图,条件变量A和条件变量B分别都有自己的等待队列。
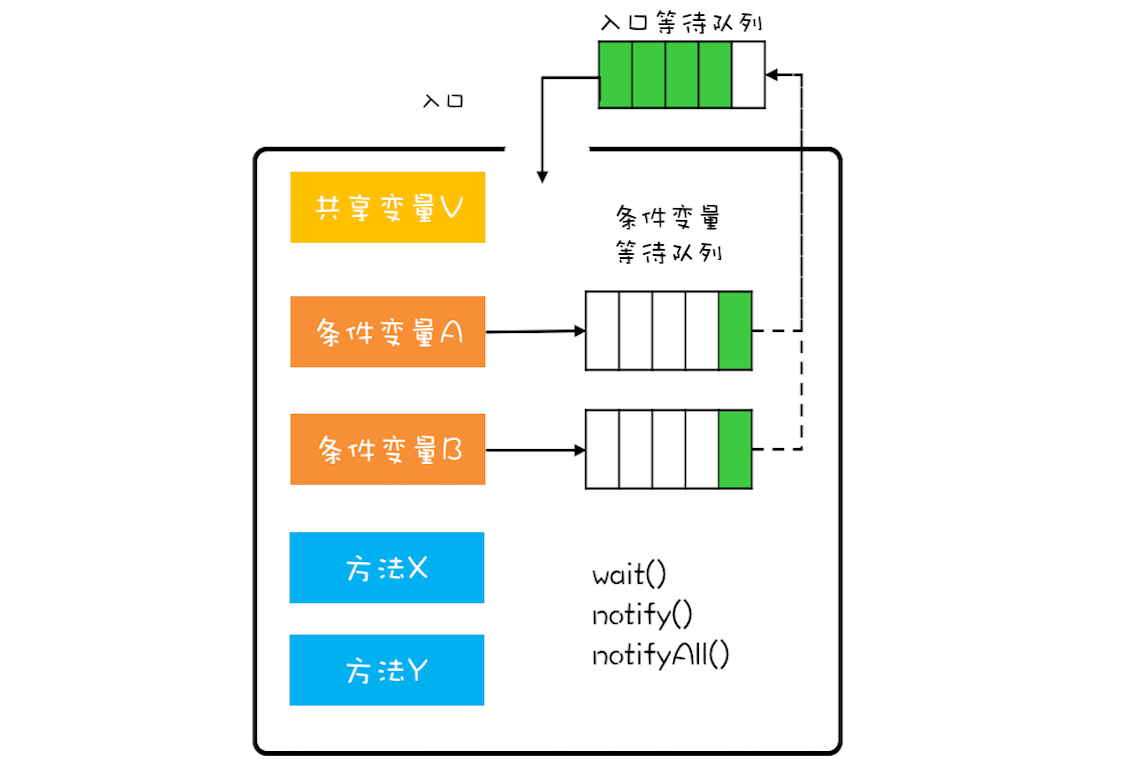
那 条件变量 和 条件变量等待队列 的作用是什么呢?其实就是解决线程同步问题。你可以结合上面提到的阻塞队列的例子加深一下理解(阻塞队列的例子,是用管程来实现线程安全的阻塞队列,这个阻塞队列和管程内部的等待队列没有关系,本文中 一定要注意阻塞队列和等待队列是不同的)。
假设有个线程T1执行阻塞队列的出队操作,执行出队操作,需要注意有个前提条件,就是阻塞队列不能是空的(空队列只能出Null值,是不允许的), 阻塞队列不空 这个前提条件对应的就是管程里的条件变量。 如果线程T1进入管程后恰好发现阻塞队列是空的,那怎么办呢?等待啊,去哪里等呢?就去条件变量对应的 等待队列 里面等。此时线程T1就去“队列不空”这个条件变量的等待队列中等待。这个过程类似于大夫发现你要去验个血,于是给你开了个验血的单子,你呢就去验血的队伍里排队。线程T1进入条件变量的等待队列后,是允许其他线程进入管程的。这和你去验血的时候,医生可以给其他患者诊治,道理都是一样的。
再假设之后另外一个线程T2执行阻塞队列的入队操作,入队操作执行成功之后, “阻塞队列不空”这个条件对于线程T1来说已经满足了,此时线程T2要通知T1,告诉它需要的条件已经满足了。当线程T1得到通知后,会从等待队列 里面出来,但是出来之后不是马上执行,而是重新进入到 入口等待队列 里面。这个过程类似你验血完,回来找大夫,需要重新分诊。
条件变量及其等待队列我们讲清楚了,下面再说说wait()、notify()、notifyAll()这三个操作。前面提到线程T1发现“阻塞队列不空”这个条件不满足,需要进到对应的 等待队列 里等待。这个过程就是通过调用wait()来实现的。如果我们用对象A代表“阻塞队列不空”这个条件,那么线程T1需要调用A.wait()。同理当“阻塞队列不空”这个条件满足时,线程T2需要调用A.notify()来通知A等待队列中的一个线程,此时这个等待队列里面只有线程T1。至于notifyAll()这个方法,它可以通知等待队列中的所有线程。
这里我还是来一段代码再次说明一下吧。下面的代码用管程实现了一个线程安全的阻塞队列(再次强调:这个阻塞队列和管程内部的等待队列没关系,示例代码只是用管程来实现阻塞队列,而不是解释管程内部等待队列的实现原理)。阻塞队列有两个操作分别是入队和出队,这两个方法都是先获取互斥锁,类比管程模型中的入口。
-
对于阻塞队列的入队操作,如果阻塞队列已满,就需要等待直到阻塞队列不满,所以这里用了 notFull.await();。 -
对于阻塞出队操作,如果阻塞队列为空,就需要等待直到阻塞队列不空,所以就用了 notEmpty.await();。 -
如果入队成功,那么阻塞队列就不空了,就需要通知条件变量:阻塞队列不空 notEmpty对应的等待队列。 -
如果出队成功,那就阻塞队列就不满了,就需要通知条件变量:阻塞队列不满 notFull对应的等待队列。
public class BlockedQueue<T>{
final Lock lock =
new ReentrantLock();
// 条件变量:队列不满
final Condition notFull =
lock.newCondition();
// 条件变量:队列不空
final Condition notEmpty =
lock.newCondition();
// 入队
void enq(T x) {
lock.lock();
try {
while (队列已满){
// 等待队列不满
notFull.await();
}
// 省略入队操作...
//入队后,通知可出队
notEmpty.signal();
}finally {
lock.unlock();
}
}
// 出队
void deq(){
lock.lock();
try {
while (队列已空){
// 等待队列不空
notEmpty.await();
}
// 省略出队操作...
//出队后,通知可入队
notFull.signal();
}finally {
lock.unlock();
}
}
}
在这段示例代码中,我们用了Java并发包里面的Lock和Condition,如果你看着吃力,也没关系,后面我们还会详细介绍,这个例子只是先让你明白条件变量及其等待队列是怎么回事。需要注意的是: await()和前面我们提到的wait()语义是一样的;signal()和前面我们提到的notify()语义是一样的。
wait()的正确姿势
但是有一点,需要再次提醒,对于MESA管程来说,有一个编程范式,就是需要在一个while循环里面调用wait()。 这个是MESA管程特有的。
while(条件不满足) {
wait();
}
Hasen模型、Hoare模型和MESA模型的一个核心区别就是当条件满足后,如何通知相关线程。管程要求同一时刻只允许一个线程执行,那当线程T2的操作使线程T1等待的条件满足时,T1和T2究竟谁可以执行呢?
-
Hasen模型里面,要求notify()放在代码的最后,这样T2通知完T1后,T2就结束了,然后T1再执行,这样就能保证同一时刻只有一个线程执行。 -
Hoare模型里面,T2通知完T1后,T2阻塞,T1马上执行;等T1执行完,再唤醒T2,也能保证同一时刻只有一个线程执行。但是相比Hasen模型,T2多了一次阻塞唤醒操作。 -
MESA管程里面,T2通知完T1后,T2还是会接着执行,T1并不立即执行,仅仅是从条件变量的等待队列进到入口等待队列里面。这样做的好处是notify()不用放到代码的最后,T2也没有多余的阻塞唤醒操作。但是也有个副作用,就是当T1再次执行的时候,可能曾经满足的条件,现在已经不满足了,所以需要以循环方式检验条件变量。
notify()何时可以使用
还有一个需要注意的地方,就是notify()和notifyAll()的使用,前面章节,我曾经介绍过, **除非经过深思熟虑,否则尽量使用notifyAll()**。那什么时候可以使用notify()呢?需要满足以下三个条件:
-
所有等待线程拥有相同的等待条件; -
所有等待线程被唤醒后,执行相同的操作; -
只需要唤醒一个线程。
比如上面阻塞队列的例子中,对于“阻塞队列不满”这个条件变量,其等待线程都是在等待“阻塞队列不满”这个条件,反映在代码里就是下面这3行代码。对所有等待线程来说,都是执行这3行代码, 重点是 while 里面的等待条件是完全相同的。
while (阻塞队列已满){
// 等待队列不满
notFull.await();
}
所有等待线程被唤醒后执行的操作也是相同的,都是下面这几行:
// 省略入队操作...
// 入队后,通知可出队
notEmpty.signal();
同时也满足第3条,只需要唤醒一个线程。所以上面阻塞队列的代码,使用signal()是可以的。
并发包中的管程
Java SDK并发包内容很丰富,包罗万象,但是我觉得最核心的还是其对管程的实现。因为理论上利用管程,你几乎可以实现并发包里所有的工具类。在并发编程领域,有两大核心问题:一个是 互斥,即同一时刻只允许一个线程访问共享资源;另一个是 同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。 Java SDK并发包通过Lock和Condition两个接口来实现管程,其中Lock用于解决互斥问题,Condition用于解决同步问题。
你也许听过,在Java的1.5版本中,synchronized性能不如SDK里面的Lock,但1.6版本之后,synchronized做了很多优化,将性能追了上来,所以1.6之后的版本又有人推荐使用synchronized了。那性能是否可以成为“重复造轮子”的理由呢?显然不能。因为性能问题优化一下就可以了,完全没必要“重复造轮子”。
在处理死锁问题时,我们有一个 破坏不可抢占条件 方案,但是这个方案synchronized没有办法解决。原因是synchronized申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。但我们希望的是:
对于“不可抢占”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
如果我们重新设计一把互斥锁去解决这个问题,那该怎么设计呢?我觉得有三种方案。
-
能够响应中断。synchronized的问题是,持有锁A后,如果尝试获取锁B失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁A。这样就破坏了不可抢占条件了。 -
支持超时。如果线程在一段时间之内没有获取到锁,不是进入阻塞状态,而是返回一个错误,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。 -
非阻塞地获取锁。如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
这三种方案可以全面弥补synchronized的问题。到这里相信你应该也能理解了,这三个方案就是“重复造轮子”的主要原因,体现在API上,就是Lock接口的三个方法。详情如下:
// 支持中断的API
void lockInterruptibly()
throws InterruptedException;
// 支持超时的API
boolean tryLock(long time, TimeUnit unit)
throws InterruptedException;
// 支持非阻塞获取锁的API
boolean tryLock();
如何保证可见性
Java SDK里面Lock的使用,有一个经典的范例,就是 try{}finally{},需要重点关注的是在finally里面释放锁。这个范例无需多解释,你看一下下面的代码就明白了。但是有一点需要解释一下,那就是可见性是怎么保证的。你已经知道Java里多线程的可见性是通过Happens-Before规则保证的,而synchronized之所以能够保证可见性,也是因为有一条synchronized相关的规则:synchronized的解锁 Happens-Before 于后续对这个锁的加锁。那Java SDK里面Lock靠什么保证可见性呢?例如在下面的代码中,线程T1对value进行了+=1操作,那后续的线程T2能够看到value的正确结果吗?
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public void addOne() {
// 获取锁
rtl.lock();
try {
value+=1;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}
答案必须是肯定的。 Java SDK里面锁 的实现非常复杂,这里我就不展开细说了,但是原理还是需要简单介绍一下:它是 利用了volatile相关的Happens-Before规则。Java SDK里面的ReentrantLock,内部持有一个volatile 的成员变量state,获取锁的时候,会读写state的值;解锁的时候,也会读写state的值(简化后的代码如下面所示)。也就是说,在执行value+=1之前,程序先读写了一次volatile变量state,在执行value+=1之后,又读写了一次volatile变量state。根据相关的Happens-Before规则:
-
顺序性规则:对于线程T1,value+=1 Happens-Before 释放锁的操作unlock(); -
volatile变量规则:由于state = 1会先读取state,所以线程T1的unlock()操作Happens-Before线程T2的lock()操作; -
传递性规则:线程 T1的value+=1 Happens-Before 线程 T2 的 lock() 操作。
class SampleLock {
volatile int state;
// 加锁
lock() {
// 省略代码无数
state = 1;
}
// 解锁
unlock() {
// 省略代码无数
state = 0;
}
}
可重入锁
如果你细心观察,会发现我们创建的锁的具体类名是ReentrantLock,这个翻译过来叫 可重入锁。 所谓可重入锁,顾名思义,指的是线程可以重复获取同一把锁。例如下面代码中,当线程T1执行到 ① 处时,已经获取到了锁 rtl ,当在 ① 处调用 get()方法时,会在 ② 再次对锁 rtl 执行加锁操作。此时,如果锁 rtl 是可重入的,那么线程T1可以再次加锁成功;如果锁 rtl 是不可重入的,那么线程T1此时会被阻塞。
除了可重入锁,可能你还听说过可重入函数,可重入函数怎么理解呢?指的是线程可以重复调用?显然不是,所谓 可重入函数,指的是多个线程可以同时调用该函数,每个线程都能得到正确结果;同时在一个线程内支持线程切换,无论被切换多少次,结果都是正确的。多线程可以同时执行,还支持线程切换,这意味着什么呢?线程安全啊。所以,可重入函数是线程安全的。
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public int get() {
// 获取锁
rtl.lock(); ②
try {
return value;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
public void addOne() {
// 获取锁
rtl.lock();
try {
value = 1 + get(); ①
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}
公平锁与非公平锁
在使用ReentrantLock的时候,你会发现ReentrantLock这个类有两个构造函数,一个是无参构造函数,一个是传入fair参数的构造函数。fair参数代表的是锁的公平策略,如果传入true就表示需要构造一个公平锁,反之则表示要构造一个非公平锁。
//无参构造函数:默认非公平锁
public ReentrantLock() {
sync = new NonfairSync();
}
//根据公平策略参数创建锁
public ReentrantLock(boolean fair){
sync = fair ? new FairSync()
: new NonfairSync();
}
在前面我们谈到入口等待队列,锁都对应着一个等待队列,如果一个线程没有获得锁,就会进入等待队列,当有线程释放锁的时候,就需要从等待队列中唤醒一个等待的线程。如果是公平锁,唤醒的策略就是谁等待的时间长,就唤醒谁,很公平;如果是非公平锁,则不提供这个公平保证,有可能等待时间短的线程反而先被唤醒。
用锁的最佳实践
用锁虽然能解决很多并发问题,但是风险也是挺高的。可能会导致死锁,也可能影响性能。这方面有是否有相关的最佳实践呢?有,还很多。但是我觉得最值得推荐的是并发大师Doug Lea《Java并发编程:设计原则与模式》一书中,推荐的三个用锁的最佳实践,它们分别是:
永远只在更新对象的成员变量时加锁 永远只在访问可变的成员变量时加锁 永远不在调用其他对象的方法时加锁
这三条规则,前两条估计你一定会认同,最后一条你可能会觉得过于严苛。但是我还是倾向于你去遵守,因为调用其他对象的方法,实在是太不安全了,也许“其他”方法里面有线程sleep()的调用,也可能会有奇慢无比的I/O操作,这些都会严重影响性能。更可怕的是,“其他”类的方法可能也会加锁,然后双重加锁就可能导致死锁。
并发问题,本来就难以诊断,所以你一定要让你的代码尽量安全,尽量简单,哪怕有一点可能会出问题,都要努力避免。
下面我们谈谈另外一个话题:Dubbo如何用管程实现异步转同步?
Java 语言内置的管程里只有一个条件变量,而Lock&Condition实现的管程是支持多个条件变量的,这是二者的一个重要区别。刚刚我们讲了Java SDK并发包里的Lock有别于synchronized隐式锁的三个特性:能够响应中断、支持超时和非阻塞地获取锁。而Java SDK并发包里的Condition, 实现了管程模型里面的条件变量。
在很多并发场景下,支持多个条件变量能够让我们的并发程序可读性更好,实现起来也更容易。例如,实现一个阻塞队列,就需要两个条件变量。
那如何利用两个条件变量快速实现阻塞队列呢?
一个阻塞队列,需要两个条件变量,一个是队列不空(空队列不允许出队),另一个是队列不满(队列已满不允许入队)
public class BlockedQueue<T>{
final Lock lock =
new ReentrantLock();
// 条件变量:队列不满
final Condition notFull =
lock.newCondition();
// 条件变量:队列不空
final Condition notEmpty =
lock.newCondition();
// 入队
void enq(T x) {
lock.lock();
try {
while (队列已满){
// 等待队列不满
notFull.await();
}
// 省略入队操作...
//入队后,通知可出队
notEmpty.signal();
}finally {
lock.unlock();
}
}
// 出队
void deq(){
lock.lock();
try {
while (队列已空){
// 等待队列不空
notEmpty.await();
}
// 省略出队操作...
//出队后,通知可入队
notFull.signal();
}finally {
lock.unlock();
}
}
}
这里你需要注意,Lock和Condition实现的管程, **线程等待和通知需要调用await()、signal()、signalAll()**,它们的语义和wait()、notify()、notifyAll()是相同的。但是不一样的是,Lock&Condition实现的管程里只能使用前面的await()、signal()、signalAll(),而后面的wait()、notify()、notifyAll()只有在synchronized实现的管程里才能使用。如果一不小心在Lock&Condition实现的管程里调用了wait()、notify()、notifyAll(),那程序可就彻底玩儿完了。
Java SDK并发包里的Lock和Condition不过就是管程的一种实现而已,管程你已经很熟悉了,那Lock和Condition的使用自然是小菜一碟。下面我们就来看看在知名项目Dubbo中,Lock和Condition是怎么用的。不过在开始介绍源码之前,我还先要介绍两个概念:同步和异步。
同步与异步
什么时同步和异步? 通俗点来讲就是调用方是否需要等待结果,如果需要等待结果,就是同步;如果不需要等待结果,就是异步。
比如在下面的代码里,有一个计算圆周率小数点后100万位的方法 pai1M(),这个方法可能需要执行俩礼拜,如果调用 pai1M() 之后,线程一直等着计算结果,等俩礼拜之后结果返回,就可以执行 printf("hello world") 了,这个属于同步;如果调用 pai1M() 之后,线程不用等待计算结果,立刻就可以执行 printf("hello world"),这个就属于异步。
// 计算圆周率小说点后100万位
String pai1M() {
//省略代码无数
}
pai1M()
printf("hello world")
同步,是Java代码默认的处理方式。如果你想让你的程序支持异步,可以通过下面两种方式来实现:
-
调用方创建一个子线程,在子线程中执行方法调用,这种调用我们称为异步调用; -
方法实现的时候,创建一个新的线程执行主要逻辑,主线程直接return,这种方法我们一般称为异步方法。
Dubbo源码分析
其实在编程领域,异步的场景还是挺多的,比如TCP协议本身就是异步的,我们工作中经常用到的RPC调用, 在TCP协议层面,发送完RPC请求后,线程是不会等待RPC的响应结果的。可能你会觉得奇怪,平时工作中的RPC调用大多数都是同步的啊?这是怎么回事呢?
其实很简单,一定是有人帮你做了异步转同步的事情。例如目前知名的RPC框架Dubbo就给我们做了异步转同步的事情,那它是怎么做的呢?下面我们就来分析一下Dubbo的相关源码。
对于下面一个简单的RPC调用,默认情况下sayHello()方法,是个同步方法,也就是说,执行service.sayHello(“dubbo”)的时候,线程会停下来等结果。
DemoService service = 初始化部分省略
String message =
service.sayHello("dubbo");
System.out.println(message);
如果此时你将调用线程dump出来的话,会是下图这个样子,你会发现调用线程阻塞了,线程状态是TIMED_WAITING。本来发送请求是异步的,但是调用线程却阻塞了,说明Dubbo帮我们做了异步转同步的事情。通过调用栈,你能看到线程是阻塞在DefaultFuture.get()方法上,所以可以推断:Dubbo异步转同步的功能应该是通过DefaultFuture这个类实现的。
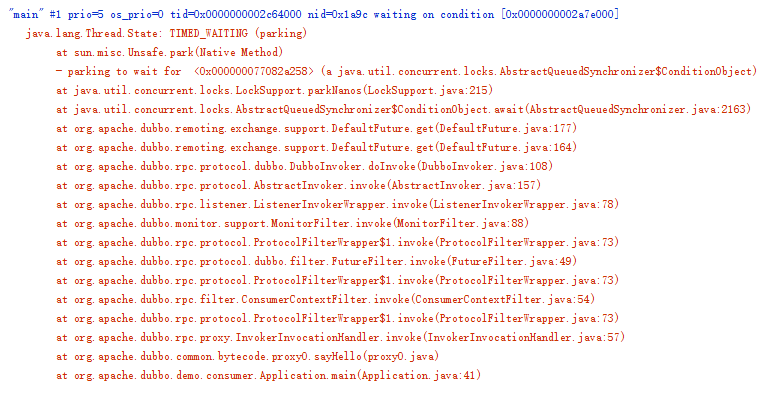
调用栈信息
不过为了理清前后关系,还是有必要分析一下调用DefaultFuture.get()之前发生了什么。DubboInvoker的108行调用了DefaultFuture.get(),这一行很关键,我稍微修改了一下列在了下面。这一行先调用了request(inv, timeout)方法,这个方法其实就是发送RPC请求,之后通过调用get()方法等待RPC返回结果。
public class DubboInvoker{
Result doInvoke(Invocation inv){
// 下面这行就是源码中108行
// 为了便于展示,做了修改
return currentClient
.request(inv, timeout)
.get();
}
}
DefaultFuture这个类是很关键,我把相关的代码精简之后,列到了下面。不过在看代码之前,你还是有必要重复一下我们的需求:当RPC返回结果之前,阻塞调用线程,让调用线程等待;当RPC返回结果后,唤醒调用线程,让调用线程重新执行。不知道你有没有似曾相识的感觉,这不就是经典的等待-通知机制吗?这个时候想必你的脑海里应该能够浮现出管程的解决方案了。有了自己的方案之后,我们再来看看Dubbo是怎么实现的。
// 创建锁与条件变量
private final Lock lock
= new ReentrantLock();
private final Condition done
= lock.newCondition();
// 调用方通过该方法等待结果
Object get(int timeout){
long start = System.nanoTime();
lock.lock();
try {
while (!isDone()) {
done.await(timeout);
long cur=System.nanoTime();
if (isDone() ||
cur-start > timeout){
break;
}
}
} finally {
lock.unlock();
}
if (!isDone()) {
throw new TimeoutException();
}
return returnFromResponse();
}
// RPC结果是否已经返回
boolean isDone() {
return response != null;
}
// RPC结果返回时调用该方法
private void doReceived(Response res) {
lock.lock();
try {
response = res;
if (done != null) {
done.signal();
}
} finally {
lock.unlock();
}
}
调用线程通过调用get()方法等待RPC返回结果,这个方法里面,你看到的都是熟悉的“面孔”:调用lock()获取锁,在finally里面调用unlock()释放锁;获取锁后,通过经典的在循环中调用await()方法来实现等待。
当RPC结果返回时,会调用doReceived()方法,这个方法里面,调用lock()获取锁,在finally里面调用unlock()释放锁,获取锁后通过调用signal()来通知调用线程,结果已经返回,不用继续等待了。
至此,Dubbo里面的异步转同步的源码就分析完了,有没有觉得还挺简单的?最近这几年,工作中需要异步处理的越来越多了,其中有一个主要原因就是有些API本身就是异步API。例如websocket也是一个异步的通信协议,如果基于这个协议实现一个简单的RPC,你也会遇到异步转同步的问题。现在很多公有云的API本身也是异步的,例如创建云主机,就是一个异步的API,调用虽然成功了,但是云主机并没有创建成功,你需要调用另外一个API去轮询云主机的状态。如果你需要在项目内部封装创建云主机的API,你也会面临异步转同步的问题,因为同步的API更易用。
总结
管程是一个解决并发问题的模型,你可以参考医院就医的流程来加深理解。理解这个模型的重点在于理解条件变量及其等待队列的工作原理。
Java参考了MESA模型,语言内置的管程(synchronized)对MESA模型进行了精简。MESA模型中,条件变量可以有多个,Java语言内置的管程里只有一个条件变量。具体如下图所示。
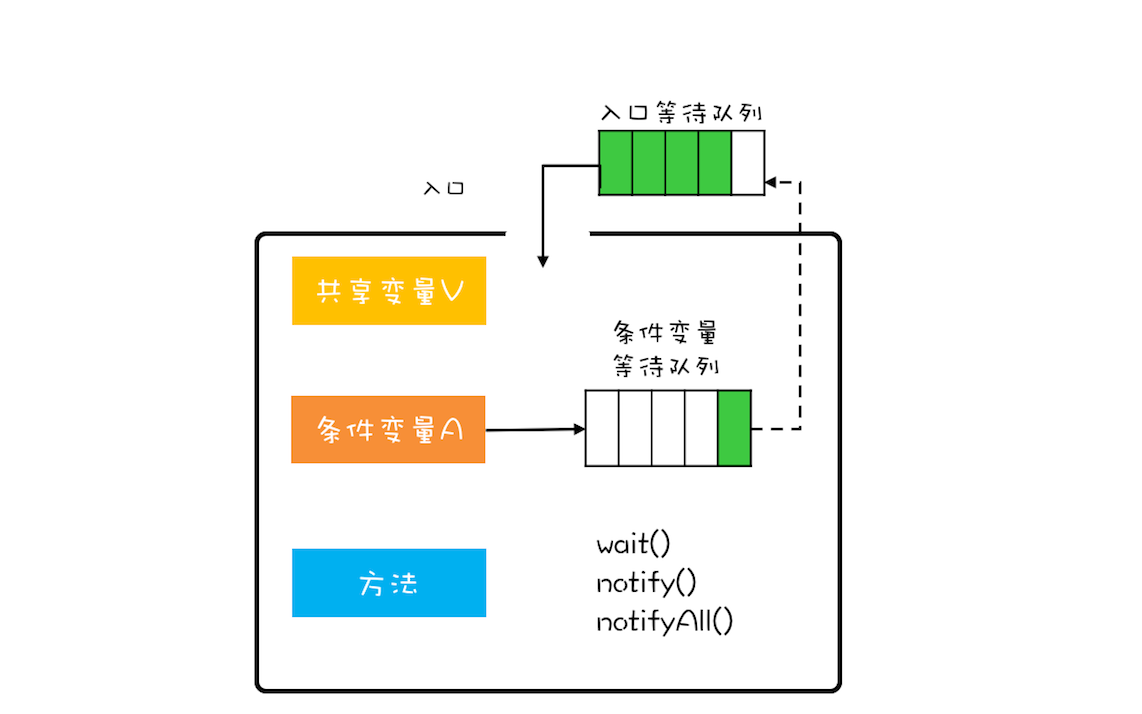
Java内置的管程方案(synchronized)使用简单,synchronized关键字修饰的代码块,在编译期会自动生成相关加锁和解锁的代码,但是仅支持一个条件变量;而Java SDK并发包实现的管程支持多个条件变量,不过并发包里的锁,需要开发人员自己进行加锁和解锁操作。
并发编程里两大核心问题——互斥和同步,都可以由管程来帮你解决。学好管程,理论上所有的并发问题你都可以解决,并且很多并发工具类底层都是管程实现的,所以学好管程,就是相当于掌握了并发编程的基石。
Java SDK 并发包里的Lock接口里面的每个方法,你可以感受到,都是经过深思熟虑的。除了支持类似synchronized隐式加锁的lock()方法外,还支持超时、非阻塞、可中断的方式获取锁,这三种方式为我们编写更加安全、健壮的并发程序提供了很大的便利。
除了并发大师Doug Lea推荐的三个最佳实践外,你也可以参考一些诸如:减少锁的持有时间、减小锁的粒度等业界广为人知的规则,其实本质上它们都是相通的,不过是在该加锁的地方加锁而已。
本文由 mdnice 多平台发布