官网链接:https://www.ee.columbia.edu/ln/dvmm/vso/download/sentibank.html
SentiBank Detector可以抽取图片中的形容词-名词对,之前一直看到,这次复现模型才第一次用到,上手的时候有点手足无措,因为官网在如何使用方面说的不是很清楚,但是用完发现也挺简单,这里记录一下。
官方下载的压缩包解压之后,主要包含以下文件:
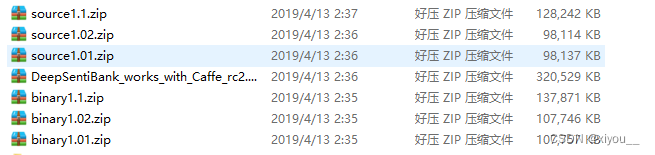
其中source1.01,1.02,1.1是source的三个版本,其中1.1为最新版本,直接解压source1.1.zip即可,binary1.01,1.02,1.1是binary的三个版本,其中1.1为最新版本,直接解压binary1.1.zip即可。两者都可以生成一张图片在1200个形容词名词对上匹配分数,binary可以直接在终端运行,source需要在MATLAB中执行。生成速度上,binary处理一张普通图片需要2min,source在修改源码之后可以达到1min处理10张照片的速度。
Binary
解压Binary1.1.zip之后,先看readme_binary.txt:
Usage: Specify image path in main.bat.
Both relative path and absolute path are accepted(relative path preferred).
Run main.m to obtain the biconcept responce of the image.
Result will be saved in ./result/imagename-biconcept.mat. It will be a 1200 length vector.
Changes in version 1.02:
Fixed bugs and improved robustness.
Changes in version 1.1:
Re-trained classifiers using Non-CC images, improved performance by about 30%.
大意就是,在main.bat文件中指定图片地址(相对地址和绝对地址都可),如:
getBiconcept test.jpg
然后双击main.bat文件执行就OK,从cmd.exe打开到执行结束大概需要两分钟,执行完成后,结果会存储在result文件夹中,命名方式是图像名-biconcept.txt和图像名-biconcept.mat,txt文件共1200行,分数对应class1200.txt中的类别。
Source
先看readme_source.txt:
Usage: getBiconcept('image path').
Both relative path and absolute path are accepted(relative path preferred).
Run main.m to obtain the biconcept responce of the image.
Result will be saved in ./result/imagename-biconcept.mat. It will be a 1200 length vector.
Changes in version 1.02:
Fixed bugs and improved robustness.
Changes in version 1.1:
Re-trained classifiers using Non-CC images, improved performance by about 30%.
首先,.m文件无法直接终端执行(也可能我操作不当一直报错,反正没成功),要下载MATLAB执行,我安装的是MATLAB_R2019a,找的是网上的破解版安装教程,安装还算顺利。
然后就可以在MATLAB界面执行.m文件了。
处理多个文件
由于给出的可执行代码都是处理一张图片的,但是使用中不可避免要处理大量图片,就不得不简单地学习了一下MATLAB的.m文件的语法,下面是我是用source文件夹下的main.m文件处理多张图片的步骤:
- 将所有要处理的图片放在一个文件夹下,并生成一个txt文件,其中包含了所有的图像连接,如images.txt:
images/1.jpg images/2.jpg … images/100.jpg - 参考博客,对源码进行修改,具体而言,就是将source1.1文件夹下
getmapping.m中的所有bitshift(i,1,samples)替换为bitshift(i,1,'uint8') - 修改mian.m文件:
% 注意每条指令后要写分号 fid = fopen('images.txt','r+'); %打开存放所有图片链接的txt文件 data = textscan(fid,'%s'); %读取文件内的所有字符串 sta=fclose(fid); %关闭文件 disp(data); %显示读取的数据,可省略 n=length(data{1}); %n为图片链接个数 for a = 1:length(data{1}) %遍历所有图片链接 disp(data{1}{a}); %显示图片链接 getBiconcept(data{1}{a}); %处理图片链接 end %getBiconcept('try.jpg') %默认的单挑指令
可能因为缺失gray2rgb.m文件而报错
gray2rgb.m:
%% 灰度图转换为彩色图
function I = gray2rgb(X)
R = redTransformer(X);
G = greenTransformer(X);
B = blueTransformer(X);
I(:,:,1) = R;
I(:,:,2) = G;
I(:,:,3) = B;
I = uint8(I);
end
%% 红色通道映射函数
function R = redTransformer(X)
R = zeros(size(X));
R(X < 128) = 30;
R(128 <= X & X < 192) = 2*X(128 <= X & X < 192)-150;
R(192 <= X) = 234;
end
%% 绿色通道映射函数
function G = greenTransformer(X)
G = zeros(size(X));
G(X < 90) = 2*X(X < 90)+40;
G(90 <= X & X < 160) = 180;
G(160 <= X) = 0;
end
%% 蓝色通道映射函数
function B = blueTransformer(X)
B = zeros(size(X));
B(X < 64) = 115;
B(64 <= X & X < 128) = 510-4*X(64 <= X & X < 128);
B(128 <= X) = 36;
end
概率到TOP5形容词名词对的转化
import os
from collections import defaultdict
import jsonlines
classes=defaultdict(str)
with open("class1200.txt","r",encoding="utf-8") as f:
lines = f.readlines()
for i,line in enumerate(lines):
classes[str(i)]=line.strip()
print(classes) #存储所有类别
with open("anps_data.txt","w",encoding="utf-8") as f:
pass
id2noun_dict={}
for root, dirs, files in os.walk("result/data"): # filename文件夹名
count=0
for file in files: # 遍历文件夹下所有文件名
if not file.endswith(".txt"):
continue
new_filepath = os.path.join(root, file) # 创建路径
id =file.split(".")[0].split("-")[0]
classdict={}
with open(new_filepath,"r",encoding="utf-8") as f:
lines = f.readlines()
for i,line in enumerate(lines):
line = float(line.strip())
classdict[str(i)]=line
classdict=sorted(classdict.items(),key=lambda x:x[1],reverse=True) #类别按照从大到小排序
# print(classdict)
classdict = classdict[:5] #获取top5类别
classlist = []
five_words = [id]
for c in classdict:
name = classes[c[0]]
score = c[1]
classlist.append((name,score))
five_words.append(name)
id2noun_dict[id] = tuple(classlist)
count+=1
# print(id)
with open("anps_clue.txt","a",encoding="utf-8") as f:
f.write(str(five_words)+"\n")
后记
即使是使用source1.1执行,图片的处理速度也是和图片的大小成正比的,所以如果需要提升处理速度,可以降低图片的分辨率。






![[Data structure]单链表 | 一文介绍线性数据结构之一的单链表(Java实现)](https://img-blog.csdnimg.cn/f4eedcae0aa84f9084a0ac893f9494e1.png)